博文
视觉强化学习方法研究综述
|
引用本文
王荣荣, 程玉虎, 王雪松. 视觉强化学习方法研究综述. 自动化学报, 2026, 52(3): 381−410 doi: 10.16383/j.aas.c250422
Wang Rong-Rong, Cheng Yu-Hu, Wang Xue-Song. Overview of visual reinforcement learning methods. Acta Automatica Sinica, 2026, 52(3): 381−410 doi: 10.16383/j.aas.c250422
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c250422
关键词
强化学习,视觉表征,视觉强化学习,智能体
摘要
视觉作为强化学习智能体感知环境的主要途径, 能够提供丰富的细节信息, 从而支持智能体实现更复杂、精准的决策. 然而, 视觉数据的高维特性易导致信息冗余与样本效率低下, 成为强化学习应用中的关键挑战. 如何在有限交互数据中高效提取关键视觉表征, 提升智能体决策能力, 已成为当前研究热点. 为此, 系统梳理视觉强化学习方法, 依据核心思想与实现机制, 将其归纳为五类: 图像增强型、模型增强型、任务辅助型、知识迁移型以及离线视觉强化学习, 深入分析各类方法的研究进展及代表性工作的优势与局限. 同时, 综述DMControl、DMControl-GB、DCS和RL-ViGen四大主流基准平台, 总结视觉强化学习在机器人控制、自动驾驶以及多模态大模型等典型场景中的应用实践. 最后, 结合当前研究瓶颈, 探讨未来发展趋势与潜在研究方向, 以期为该领域提供清晰的技术脉络与研究参考.
文章导读
在人工智能领域, 强化学习(reinforcement learning, RL)[1]关注的是智能体在环境中采取动作以获得最大化累积奖励的过程. 近年来, 随着计算机技术的飞速发展, 强化学习在游戏[2]、机器人自主决策[3]、视觉导航[4]、智能交通系统[5]等领域取得突破性进展. 我国高度重视强化学习的发展: 2017年《国务院关于印发新一代人工智能发展规划的通知》[6]首次将强化学习列为算法创新的重点方向; 2024年颁布的 《国家人工智能产业综合标准化体系建设指南(2024版)》[7]进一步明确提出, 要规范机器学习中的强化学习技术标准, 以及以通用大模型为核心的智能体实例和智能体基本功能、应用架构等技术要求, 具体涵盖智能体强化学习、多任务分解、推理、提示词工程等多个标准. 这些政策部署不仅印证了强化学习在技术创新中的战略地位, 更凸显了其作为国家科技发展重要基石的现实意义.
传统的强化学习方法, 如深度Q学习[8]、柔性Actor-Critic学习[9]以及近端策略优化[10]等, 通常依赖人工精心设计的状态输入来引导智能体的学习过程. 然而, 在现实世界中, 大约80%的信息是通过视觉途径获取的[11]. 视觉作为感知外部环境的主要方式之一, 不仅提供海量且高维度的输入数据, 还蕴含环境的丰富细节. 因此, 将视觉信息融入到强化学习框架中, 能够使智能体基于视觉感知做出更为复杂和精准的决策. 基于这一理念, 视觉强化学习[12] (visual reinforcement learning, VRL)逐渐成为人工智能领域的研究热点. 该技术强调利用视觉输入来指导智能体的决策过程, 其核心优势在于能够直接从高维、丰富的图像数据中提取环境特征, 使智能体在面临视觉复杂的任务时能够有效地学习和执行相应的策略.
然而, 从高维视觉输入中学习有效策略仍面临诸多挑战. 高维视觉数据通常包含大量与任务无关的冗余信息或噪声, 如何从中准确提取与决策密切相关的关键特征, 构建低维且具有表征力的状态信息, 成为亟待突破的核心难题. 与此同时, 样本效率低下的问题也严重制约着实际应用的发展: 在高维输入下进行策略学习往往依赖海量的环境交互数据, 而现实场景中数据采集成本高昂、交互过程缓慢, 这一矛盾显著限制了模型的训练效率和应用可行性. 因此, 在交互数据有限的条件下, 如何提升智能体从高维视觉输入中提取关键信息的能力, 以实现其在复杂视觉环境中的高效与稳健决策, 已成为当前研究的热点与难点.
本文旨在对视觉强化学习方法进行全面而深入的综述. 首先, 通过阐述该领域的基本概念与问题描述, 为后续内容的展开奠定理论基础. 在此基础上, 系统梳理视觉强化学习方法的发展脉络, 重点归纳并分析五类主流技术路线: 图像增强型、模型增强型、任务辅助型、知识迁移型以及离线视觉强化学习方法, 深入剖析各类方法的技术原理、代表性成果、适用场景以及各自的优缺点. 随后, 介绍当前广泛使用的四种基准测试平台, 为方法的评估提供支撑. 此外, 本文还探讨视觉强化学习在机器人控制、自动驾驶、多模态大模型等前沿领域的实际应用案例, 展示其应用价值与发展潜力. 最后, 总结当前研究中存在的问题和挑战, 并对未来的研究方向进行展望, 以期为该领域的研究者提供有益参考.
本文与文献[12]、文献[13]均为视觉强化学习领域的综述性论文. 为更清晰地呈现本文的独特价值, 表1从覆盖范围、分类框架、基准平台和应用场景四个维度, 将本文与上述两篇文献进行系统比较. 文献[12]主要聚焦于图像增强型视觉强化学习, 重点关注无模型在线场景, 其分类框架围绕增强数据的生成方式以及对增强数据的利用两个角度展开, 并对Atari游戏、DMControl及其变体等常用视觉强化学习基准平台进行介绍. 文献[13]则侧重于状态表征的生成方式, 将现有方法划分为基于度量、辅助任务、数据增强、对比学习、非对比学习以及基于注意力等类别, 但其涵盖范围仍局限于无模型在线场景, 且未对相关基准平台展开系统评述. 相比之下, 本文在覆盖广度和内容深度上均有显著拓展: 不仅全面涵盖无模型与基于模型两大类方法, 还系统梳理了在线与离线两种学习范式下的视觉强化学习进展. 在基准平台方面, 本文进一步讨论一个覆盖多样化视觉应用场景的综合基准平台RL-ViGen, 为视觉强化学习的系统评估与比较提供重要参考.
本文结构安排如下: 第1节介绍视觉强化学习的背景知识与问题定义; 第2节系统梳理图像增强型、模型增强型、任务辅助型、知识迁移型以及离线视觉强化学习五类方法的研究进展; 第3节概述四种常用基准测试平台及其特点; 第4节阐述视觉强化学习在机器人控制、自动驾驶和多模态大模型等典型场景中的应用; 第5节探讨该领域面临的挑战与未来发展趋势; 第6节对全文进行总结.
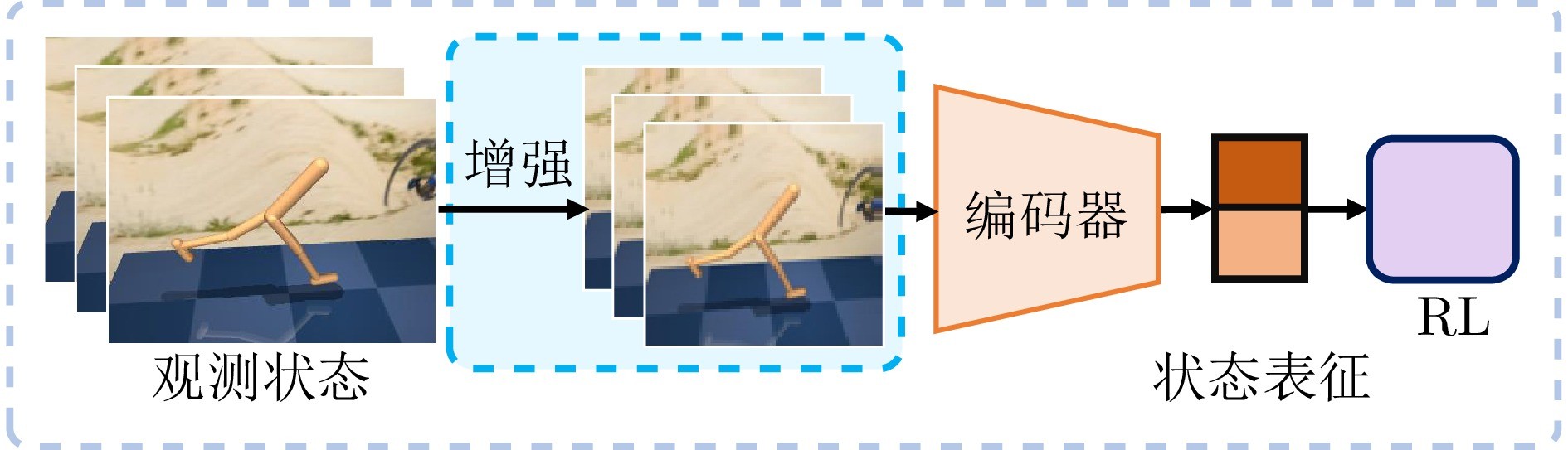
图1 图像增强型视觉强化学习示意图
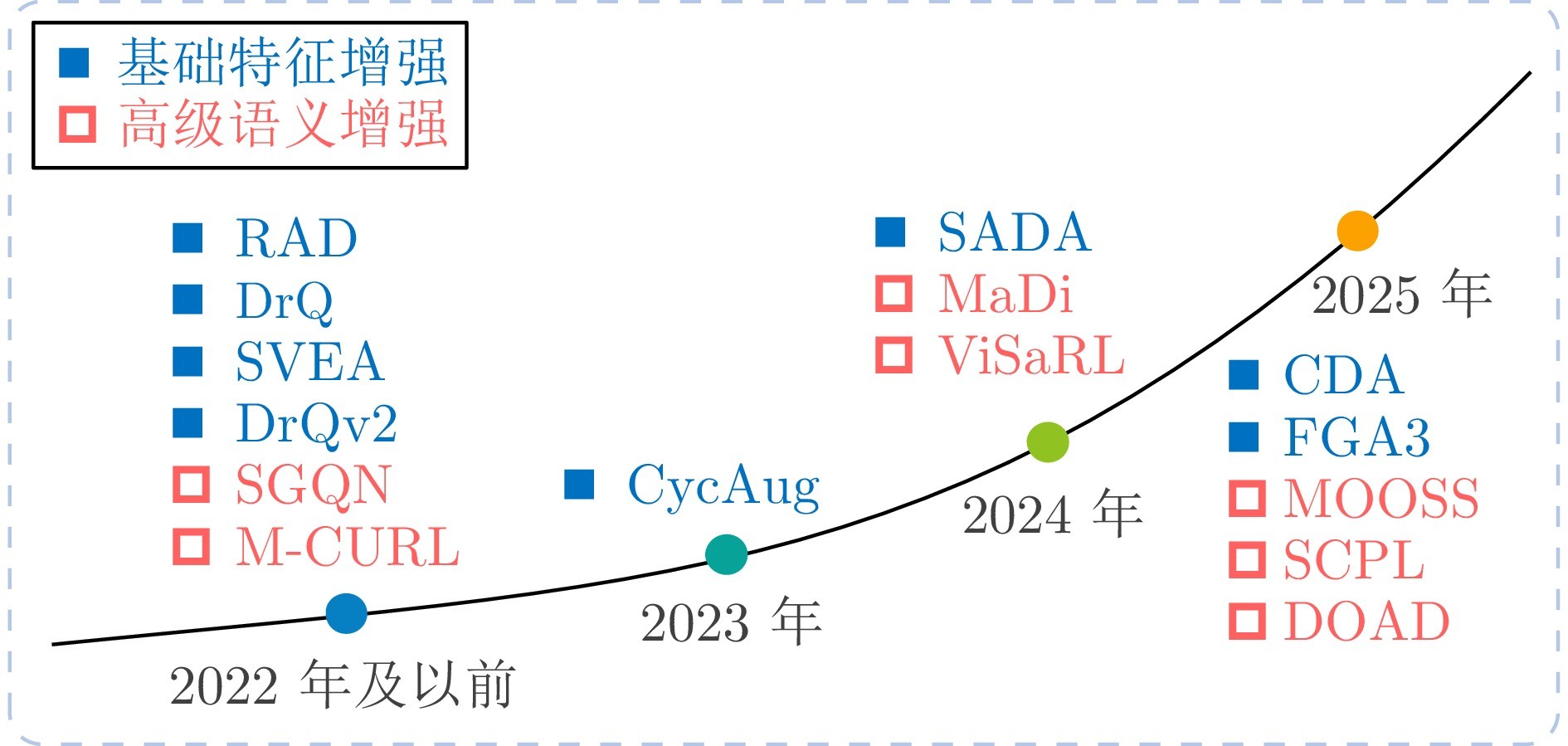
图2 图像增强型视觉强化学习时间线
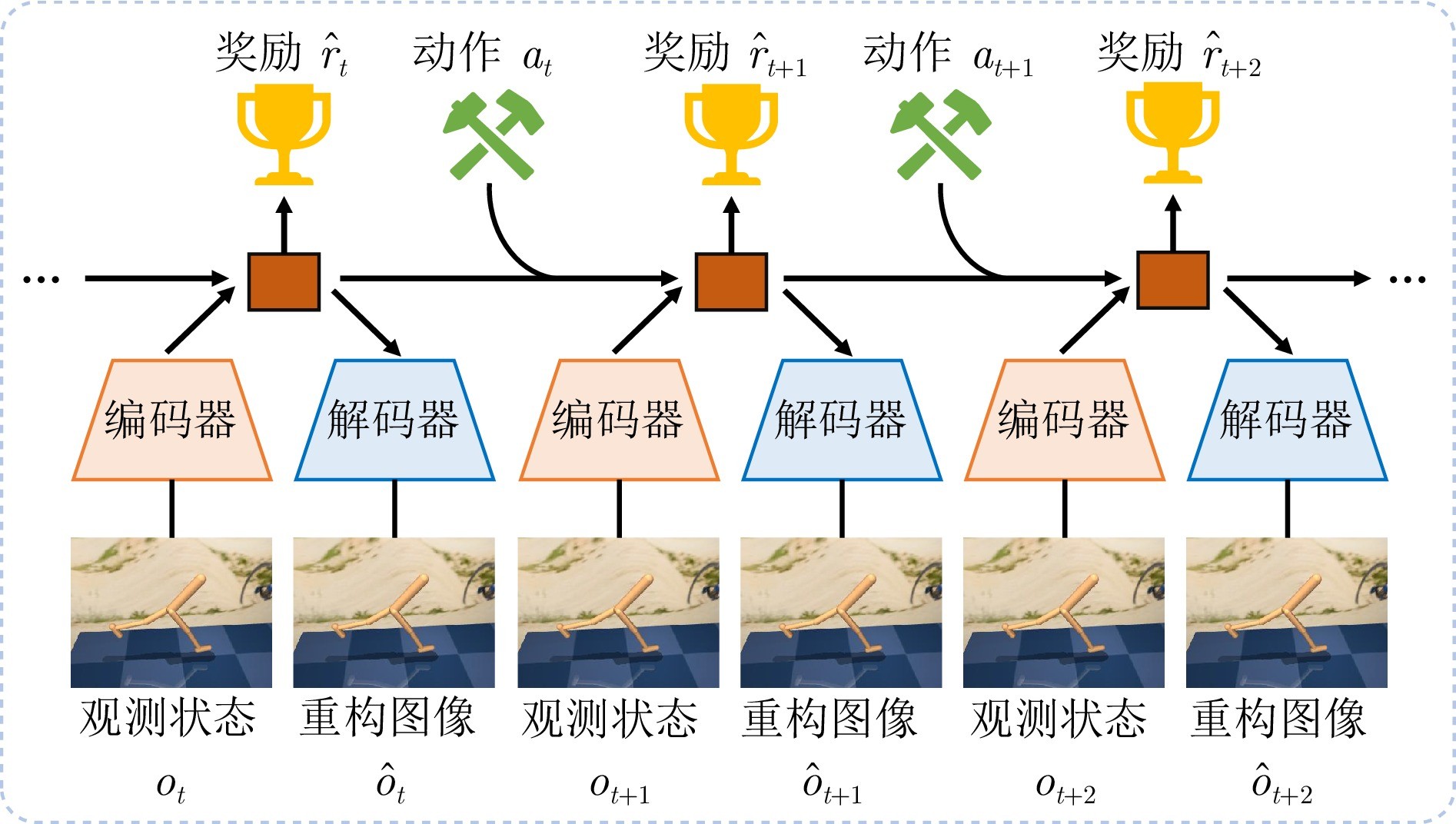
图3 模型增强型视觉强化学习示意图(以基于世界模型的视觉强化学习为例)
本文系统综述视觉强化学习的研究现状与关键技术. 首先围绕不同方法的核心思想与实现机制, 深入分析图像增强型、模型增强型、任务辅助型、知识迁移型以及离线视觉强化学习方法的研究进展与演变脉络, 比较各类方法的特点与优劣. 随后, 介绍四种常用的基准平台: DMControl、DMControl-GB、DCS和RL-ViGen, 并辨析它们之间的区别与联系. 此外, 还结合机器人控制、自动驾驶和多模态大模型等多个应用场景, 开展典型案例分析. 最后, 在总结现有研究基础上, 指出当前视觉强化学习面临的主要挑战, 并对未来发展方向进行展望.
作者简介
王荣荣
中国矿业大学博士研究生. 2021年获得济南大学硕士学位. 主要研究方向为深度强化学习. E-mail: wangrongrong1996@126.com
程玉虎
中国矿业大学教授. 2005年获得中国科学院自动化研究所博士学位. 主要研究方向为机器学习, 智能系统. E-mail: chengyuhu@163.com
王雪松
中国矿业大学教授. 2002年获得中国矿业大学博士学位. 主要研究方向为机器学习, 模式识别. 本文通信作者. E-mail: wangxuesongcumt@163.com
https://blog.sciencenet.cn/blog-3291369-1530219.html
上一篇:《自动化学报》2026年52卷3期目录分享
下一篇:基于PIML的微观人群移动建模仿真与干预决策框架
