博文
基于PIML的微观人群移动建模仿真与干预决策框架
|
引用本文
郭润康, 朱正秋, 艾川, 叶佩军, 秦龙, 尹全军, 王飞跃. 基于PIML的微观人群移动建模仿真与干预决策框架. 自动化学报, 2026, 52(3): 411−429 doi: 10.16383/j.aas.c250312
Guo Run-Kang, Zhu Zheng-Qiu, Ai Chuan, Ye Pei-Jun, Qin Long, Yin Quan-Jun, Wang Fei-Yue. Microscopic crowd movement modeling, simulation, and intervention decision-making framework based on physics-informed machine learning. Acta Automatica Sinica, 2026, 52(3): 411−429 doi: 10.16383/j.aas.c250312
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c250312
关键词
微观人群移动,物理信息机器学习,导航势能场,干预决策,多智能体强化学习
摘要
人群移动是影响城市公共安全及应急管理的重要因素, 如何对其进行高精度的建模仿真和有效干预是亟待解决的问题. 为此, 提出一种物理信息机器学习驱动的微观人群移动建模仿真与干预决策框架. 基于平行智能思想, 该框架构建“数据感知−融合建模−动态仿真−智能干预”四层闭环结构, 形成从建模仿真到策略生成、执行及反馈修正的完整链路. 针对人群的移动仿真与引导决策问题, 分别提出基于物理信息时空图卷积网络的导航势能场模型和物理信息多智能体深度确定性策略梯度算法, 有效解决了传统方法中模型准确性较差、仿真与干预孤立以及决策依赖人工经验的问题. 最后, 基于真实数据集开展仿真实验验证了所提框架的有效性.
文章导读
随着全球城市化进程加速, 城市人口持续增长, 给智慧城市建设带来更大压力的同时, 也对公共安全风险管控提出更高要求. 特别是在商业广场、交通枢纽、文体场馆等大型公共空间中, 人群运动模式复杂多变, 叠加潜在的突发事件风险, 极易引发踩踏事故或造成局部拥堵等群体性安全事件[1]. 因此, 人群移动规律研究已成为城市规划、交通治理与应急管理等领域的重点关注方向[2−3]. 实现高精度的人群动态建模仿真及智能化的干预策略优化, 不仅能有效降低人群安全事故风险, 还能显著提升公共空间的运营效率. 为此, 迫切需要构建一种有效的微观人群移动建模仿真与干预决策框架, 以提升复杂场景下干预策略的精准性和适应性, 实现建模仿真与干预优化的闭环控制.
尽管部分研究在特定场景中实现了较高精度的人群移动仿真, 但在实际应用中仍存在以下问题: 1)建模仿真与干预决策脱节. 现有方法通常将两者解耦处理, 干预策略依赖人工经验调参, 缺乏科学性与精准性. 2)强化学习方法的局限性. 基于DQN(deep Q-network)[26−27]、MADDPG (multi-agent deep deterministic policy gradient)[28−29]等框架的优化方法虽能减少主观经验依赖, 但缺乏与实时仿真的连接, 智能体决策时缺少数据驱动支撑, 未能充分利用移动数据的时空依赖信息, 无法形成闭环反馈机制, 导致实际干预效果欠佳. 综上, 当前方法在建模层面缺乏数据驱动与物理机理的深度融合; 在仿真层面缺乏时空依赖注入, 难以维持长期稳定性; 在干预层面未形成闭环反馈机制, 策略精准性较差.
针对上述挑战, 受平行智能[30−31]思想的启发, 本文提出一种物理信息机器学习(physics-informed machine learning, PIML)驱动的人群移动建模仿真与干预决策框架. 该框架采用数据与机理融合建模的方式, 构建“数据感知−融合建模−动态仿真−智能干预”四层结构, 形成从多源数据感知、物理信息融合建模、动态仿真推演到自适应干预引导的闭环链路. 在真实城市开放场景中的实验初步验证了该框架的有效性与可靠性. 该框架可为城市大型公共空间人群管控以及应急疏散提供科学计算支撑, 辅助管理人员进行日常管理与应急决策.
本文的主要贡献如下:
1)提出一种数据与机理融合驱动的人群移动建模仿真与干预决策框架. 该框架通过数据驱动与物理机理的深度融合, 解决了传统仿真或干预方法缺乏实时数据支撑或过度依赖人工经验/预设规则的问题. 基于此框架构建的应用系统, 能够实现高精度的人群移动仿真推演并生成有效的干预策略.
2)提出基于物理信息时空图卷积网络(physics-informed spatiotemporal graph convolutional network, PI-STGCN)的人群移动导航势能场模型. 在融合建模层, 该模型采用位移联合速度特征的双流时空图架构, 以数据驱动方式建模人群位置变化, 并基于人工势能场, 构建物理信息机器学习驱动的导航势能场, 解决了传统模型在长时间人群移动动态仿真中稳定性和泛化性不足的问题.
3)提出基于物理信息多智能体深度确定性策略梯度(physics-informed multi-agent deep deterministic policy gradient, PI-MADDPG)的人群引导策略生成方法. 该方法在智能干预层融合PI-STGCN模型与强化学习, 通过实时感知数据与仿真推演信息自适应地生成引导策略, 并构建“策略生成−平行执行−反馈修正”的闭环机制, 有效克服了传统方法过度依赖人工经验、实际引导效果不佳的问题.
4)基于ETH/UCY真实城市开放场景数据集, 本文对所提框架进行初步验证. 实验结果表明, 所提框架能够有效模拟人群移动模式, 并基于动态仿真数据自适应生成干预策略. 在人群疏散任务中, 相比传统依靠管理人员主观经验和纯数据驱动的干预方法, 平行执行干预策略后疏散效率提升了10.2%.
本文组织结构如下: 第1节介绍ACP (artificial systems, computational experiments, parallel excution)方法与平行智能、人群移动模型、多智能体强化学习(multi-agent reinforcement learning, MARL)等相关理论和背景知识; 第2节阐述微观人群移动建模仿真与干预决策框架结构与实现细节; 第3节基于真实数据集开展微观人群移动仿真与干预实验; 第4节对本文进行总结和展望.
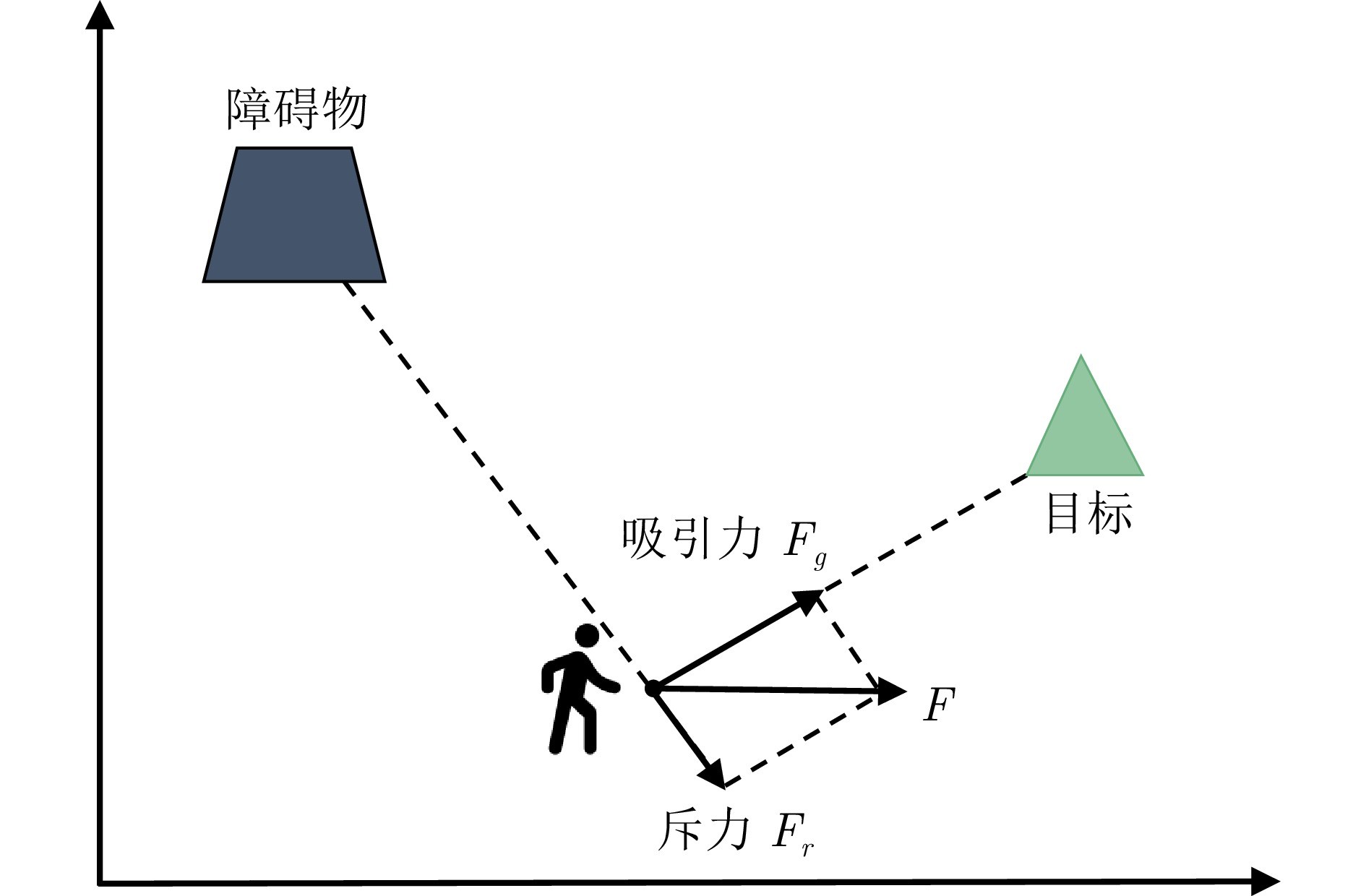
图1 人工势场原理
图2 agent基本结构
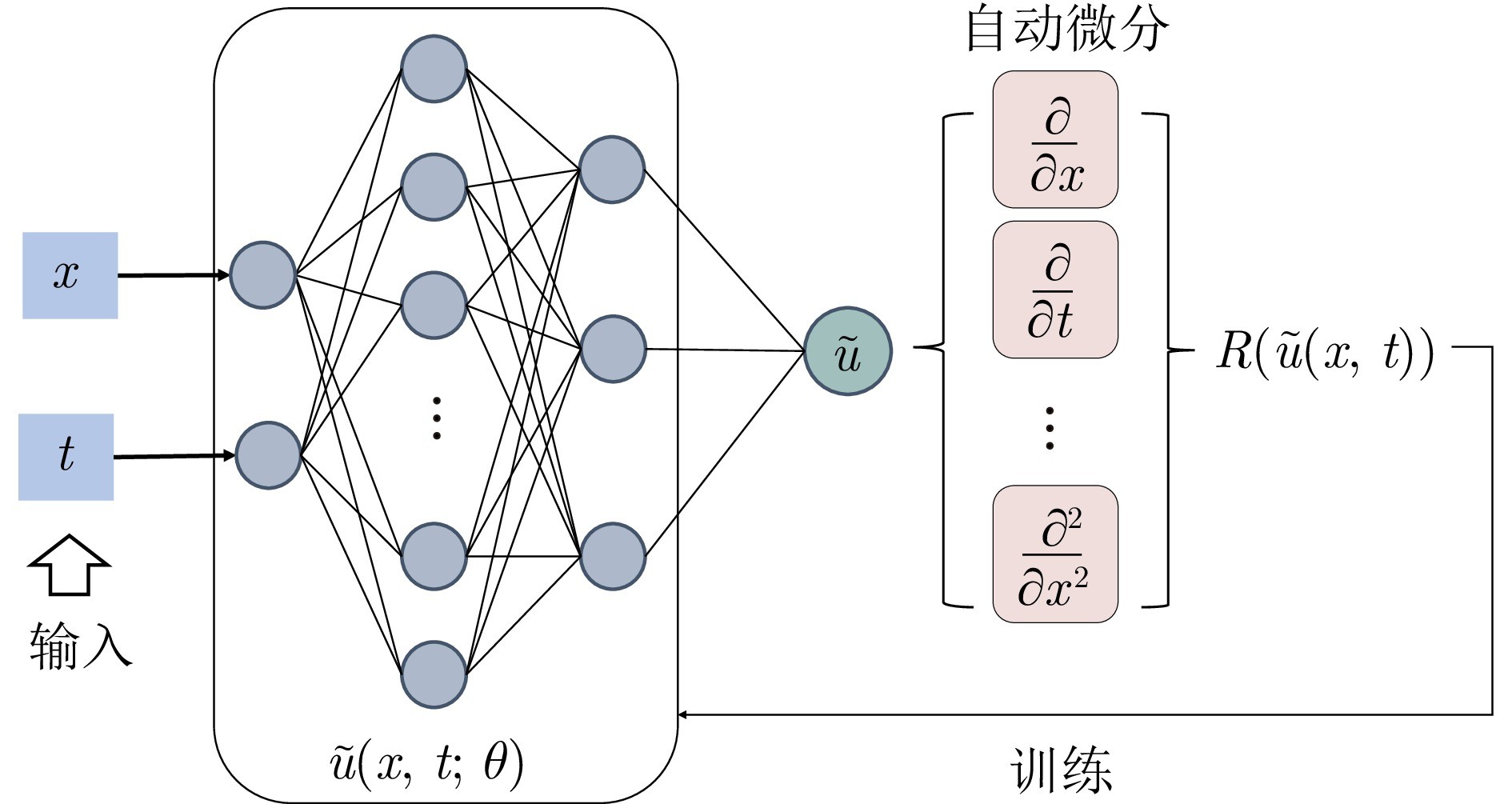
图3 PINN结构
针对微观人群移动管控问题, 本文提出一种物理信息机器学习驱动的建模仿真与干预决策框架. 该框架集成数据感知、物理信息融合建模、动态仿真推演以及智能干预各层级模块, 并基于“平行智能”思想构建人群管理的虚实闭环架构. 在框架中, 本文设计了基于PI-STGCN的人群移动导航势能场模型, 并设计PI-MADDPG强化学习算法自适应生成引导策略, 有效克服了传统方法中仿真精度不足及干预策略过度依赖人工经验等局限, 为大规模人群管控提供科学计算支撑. 真实人群移动数据集上的实验结果表明, 框架在大规模人群仿真与引导疏散任务的应用中表现出较高的准确性与疏散效率. 通过智能干预层平行执行引导策略, 人群疏散效率显著提升, 相比传统各类引导方法, 疏散时间缩短了10.2%. 该框架构建从人群移动建模仿真, 到干预策略生成、执行及反馈修正的完整闭环链路, 可在复杂环境中动态调整策略以高效引导人群移动, 对城市公共安全与应急疏散管理具有重要应用价值.
未来研究将进一步优化模型的适应性, 提升其在多样化城市环境中的泛化能力. 在数据驱动层面, 我们将在现有物理交互机制基础上引入社会关系嵌入与群体感知注意力模块, 以增强对心理与社会因素的建模能力; 在机理建模层面, 将通过融合多源数据(如行人心理特征、社会行为模式、环境天气信息等)进一步强化仿真真实性与决策干预有效性. 此外, 探索复杂群体移动场景中的多智能体协作与协同决策机制, 也将是重点推进的研究方向.
作者简介
郭润康
国防科技大学系统工程学院博士研究生. 2024年获得国防科技大学硕士学位. 主要研究方向为复杂系统建模与仿真. E-mail: guorunkangnudt@nudt.edu.cn
朱正秋
国防科技大学数智建模与仿真国家级重点实验室副研究员. 主要研究方向为复杂系统建模与仿真, 群智计算, 具身智能. 本文通信作者. E-mail: zhuzhengqiu12@nudt.edu.cn
艾川
国防科技大学数智建模与仿真国家级重点实验室讲师. 主要研究方向为高性能仿真, 社会仿真. E-mail: aichuan@nudt.edu.cn
叶佩军
中国科学院自动化研究所副研究员. 2013年获得中国科学院大学博士学位. 主要研究方向为多智能体系统, 复杂系统建模与控制, 智能交通. E-mail: peijun.ye@ia.ac.cn
秦龙
国防科技大学数智建模与仿真国家级重点实验室副研究员. 2014年获得国防科技大学博士学位. 主要研究方向为复杂系统建模与仿真. E-mail: qldbx2007@sina.com
尹全军
国防科技大学数智建模与仿真国家级重点实验室研究员. 2005年获得国防科技大学博士学位. 主要研究方向为行为建模, 云仿真. E-mail: yin_qaunjun@163.com
王飞跃
中国科学院自动化研究所研究员. 主要研究方向为智能系统和复杂系统的建模、分析与控制. E-mail: feiyue.wang@ia.ac.cn
https://blog.sciencenet.cn/blog-3291369-1530226.html
上一篇:视觉强化学习方法研究综述
下一篇:融合形态特征的基于GRU的介入机器人导丝轨迹预测建模
