博文
基于双高斯分布混合的可解释自适应鲁棒神经网络建模方法
|
引用本文
刘鑫, 李琪琪, 代伟. 基于双高斯分布混合的可解释自适应鲁棒神经网络建模方法. 自动化学报, 2026, 52(3): 463−480 doi: 10.16383/j.aas.c250602
Liu Xin, Li Qi-Qi, Dai Wei. An interpretable and adaptive robust neural network modeling method based on dual Gaussian mixture distribution. Acta Automatica Sinica, 2026, 52(3): 463−480 doi: 10.16383/j.aas.c250602
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c250602
关键词
随机配置网络,双高斯分布混合,鲁棒建模方法,期望最大化算法
摘要
工业过程数据常常受到混合噪声干扰, 传统基于单一重尾分布的鲁棒建模方法在处理混合噪声问题时, 在准确性与可解释性方面均存在一定局限. 基于此, 提出一种混合双高斯分布的可解释鲁棒自适应建模方法. 该方法首先采用随机配置算法构建基础的随机配置网络学习模型, 确定模型的隐含层节点数、输入权重和偏置; 其次为保证模型对混合噪声的鲁棒性, 构建双高斯分布(一大一小方差)加权组合而成的噪声表征模型; 随后利用期望最大化算法自适应迭代学习随机配置网络输出权值和混合高斯模型噪声参数, 最终形成基于双高斯分布混合鲁棒建模方法. 该方法具有以下优势: 噪声模型能够通过参数自适应学习逼近实际混合噪声特性, 其中大方差高斯分量负责对异常噪声进行粗调, 小方差高斯分量则用于精细拟合主体噪声, 从而增强模型的可解释性; 在网络模型输出权值估计过程中, 通过为每个输出数据点自适应分配惩罚权重, 保障模型的鲁棒性能. 为验证所提方法的有效性, 分别在函数仿真、基准数据集和工业实例上设计多组对比实验, 结果均表明所提方法具备良好的可靠性与实用性.
文章导读
随着工业4.0和智能制造的快速发展, 数据驱动建模技术凭借其强大的分析与决策能力已成为现代工业过程监控、优化和控制的核心手段[1−5]. 工业大数据中蕴含着丰富的生产过程信息, 通过统计和机器学习方法构建具有高泛化能力的数学模型, 能够有效实现产品质量预测、故障诊断和能效优化等关键功能[6−8]. 然而, 在工业现场数据采集过程中, 由于受复杂电磁环境、传感器精度衰减、设备机械振动及网络传输延迟等多源因素影响, 数据普遍存在严重的噪声污染与异常值干扰问题[9−12]. 其中, 高斯噪声、脉冲噪声等随机干扰会导致数据特征畸变, 而设备突发故障、人为操作失误引发的异常值则会破坏数据分布的统计特性, 这些数据质量缺陷显著增加了数据预处理的难度, 严重影响建模分析的准确性和可靠性.
为应对上述挑战, 鲁棒建模理论与方法持续受到广泛关注与研究. 早期主要是基于M-估计的鲁棒回归等经典方法. M-估计框架通过设计具有抑制异常值影响的损失函数, 如Huber损失、Tukey双权函数等, 在线性与广义线性模型中取得良好效果, 但其处理复杂非线性关系的能力有限[13−14]. 在工业过程建模领域, 神经网络作为典型的数据驱动方法, 凭借其对非线性函数的强逼近能力, 已成功应用于复杂工业过程建模[15−19]. 然而, 传统基于误差反向传播(error back propagation, BP)算法训练的神经网络存在收敛速度慢、易陷入局部最优解、网络结构设计缺乏系统性方法以及学习参数调优困难等问题, 导致其在实际工业场景中的应用受限. 针对上述问题, 随机化方法在神经网络中的应用为工业过程建模带来新的突破方向. Pao等[20]提出一种随机向量函数链接网络(random vector functional link, RVFL), 其训练主要包括两个步骤: 一是输入权值和偏置的随机分配; 二是用最小二乘法评估输出权值. 通过引入随机化机制不仅大幅提升训练效率, 还显著增强了模型的泛化性能. 然而, RVFL模型的普遍近似性质更多停留在理论层面, 在实际工程应用中存在局限性. 为提升随机化学习技术的实用性与普适性, Wang等[21]提出随机配置网络(stochastic configuration network, SCN), 该模型采用增量构建策略, 并引入监督机制对随机参数进行配置, 有效避免产生垃圾节点, 从理论与实践两个层面双重保障其普遍逼近能力. 凭借在数据建模中的显著优势, SCN已经成功地应用于多个工业领域, 展现出强大的工程适应性与技术潜力[22−26].
由于传统SCN输出权值计算依赖最小二乘法, 而最小二乘法对非高斯噪声及异常值高度敏感, 易导致模型精度下降与泛化性受损. 因此, 构建具备强鲁棒性的SCN以有效抵御异常值干扰, 是保障其在工业过程建模中稳定运行与可靠应用的关键技术需求. 针对该问题, 现有研究已提出多种改进方法. 文献[27]提出KDE-RSC模型, 通过核密度估计(kernel density estimation, KDE)方法为每个样本分配惩罚权重以降低异常值影响, 虽然该方法可以自适应分配权重, 但其计算成本随样本量增加而显著上升. 为解决计算效率问题, 基于重尾分布的改进方法近年来越来越受到广泛关注. 文献[28]提出基于学生氏t混合分布的鲁棒模型SM-RSC, 利用学生氏t分布的重尾特性增强模型对异常值的包容性, 但模型参数估计复杂. 文献[29]提出基于高斯分布和多个拉普拉斯混合分布的鲁棒软测量模型MoGL-SCN, 该模型通过多组分混合增强对噪声的建模能力. 此外, 文献[30]提出基于拉普拉斯分布的鲁棒模型Lap-RSC, 自适应更新权重, 并在贝叶斯框架下提供鲁棒性数学解释, 但该方法假设噪声服从单一分布, 难以准确描述工业数据中复杂的多模态噪声特性. 这些研究虽然在不同程度上提升了SCN的鲁棒性, 但仍存在计算效率不足、模型可解释性不足等问题.
纵观现有鲁棒建模方法, 经典统计方法虽理论严谨但对复杂非线性关系建模能力有限; 主流深度学习鲁棒方法依赖大数据与复杂调参, 且理论解释性较弱; 而现有SCN的鲁棒化改进多集中于假设噪声服从特定重尾分布, 对工业环境中复杂、未知的混合噪声机制适应性不足, 模型可解释性不足. 针对上述局限性, 本文提出一种基于双高斯分布的鲁棒SCN算法(robust SCN based on dual Gaussian distribution, DG-RSC). 本文的主要创新点可总结为以下三点:
1)精细的噪声建模能力. DG-RSC算法利用双高斯混合分布噪声模型, 可同时显式地刻画数据中的普通随机噪声与异常值扰动, 从而精准匹配工业数据中复杂的噪声结构, 实现对不同类型噪声的针对性处理.
2)自适应的样本加权机制. 基于期望最大化(expectation-maximization, EM)算法的迭代优化过程, 模型可自动为每个样本分配双高斯分量的占比, 实现动态加权. 正常样本主要由小方差分量解释, 获得高权重以保障建模精度, 异常样本则由大方差分量主导, 被赋予极低权重以抑制其对模型的影响.
3)良好的模型可解释性. 噪声模型能够通过参数自适应学习逼近实际混合噪声特性, 其中大方差高斯分量负责对异常噪声进行粗调, 小方差高斯分量则用于精细拟合主体噪声, 从而增强模型的可解释性.
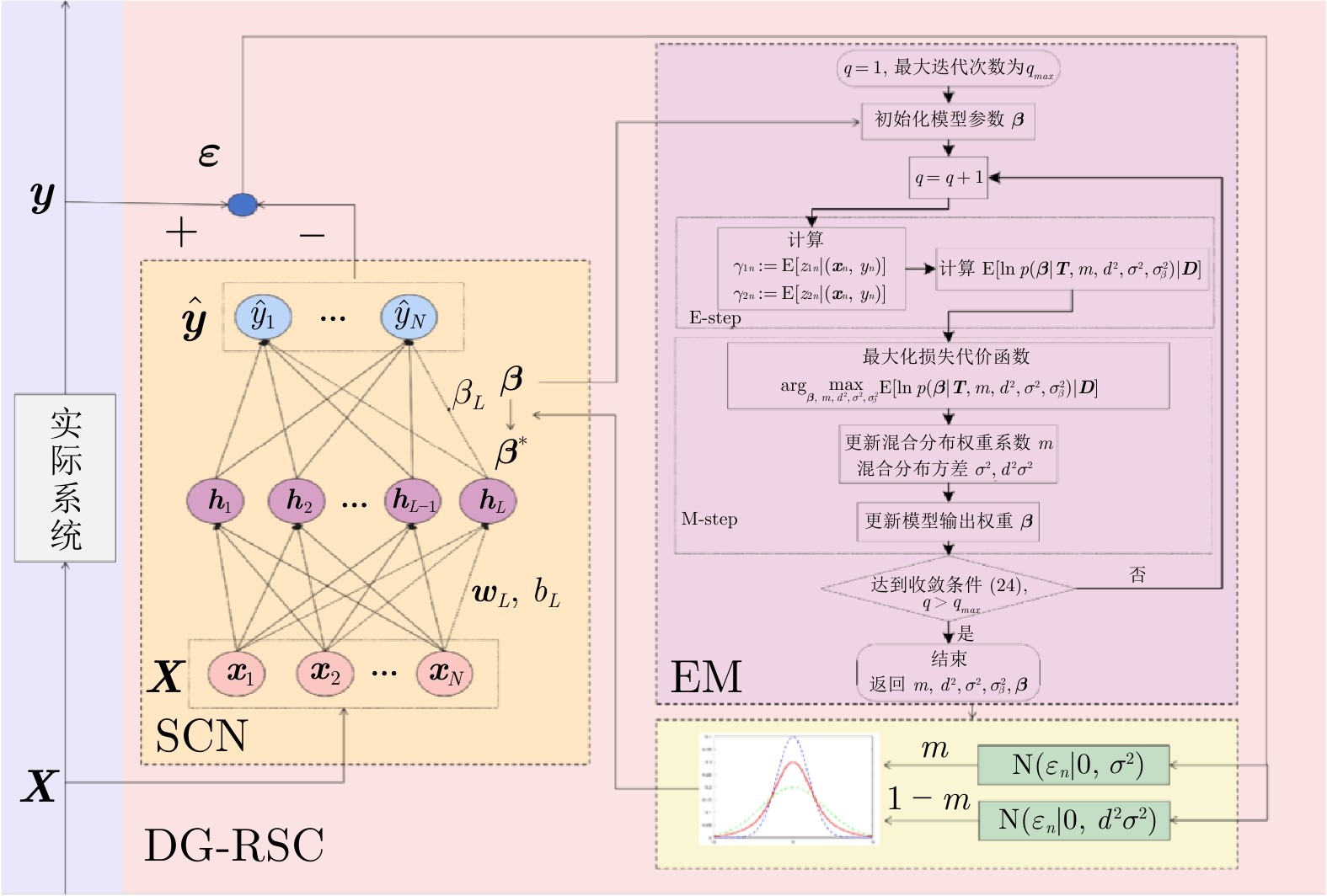
图1 DG-RSC算法网络结构
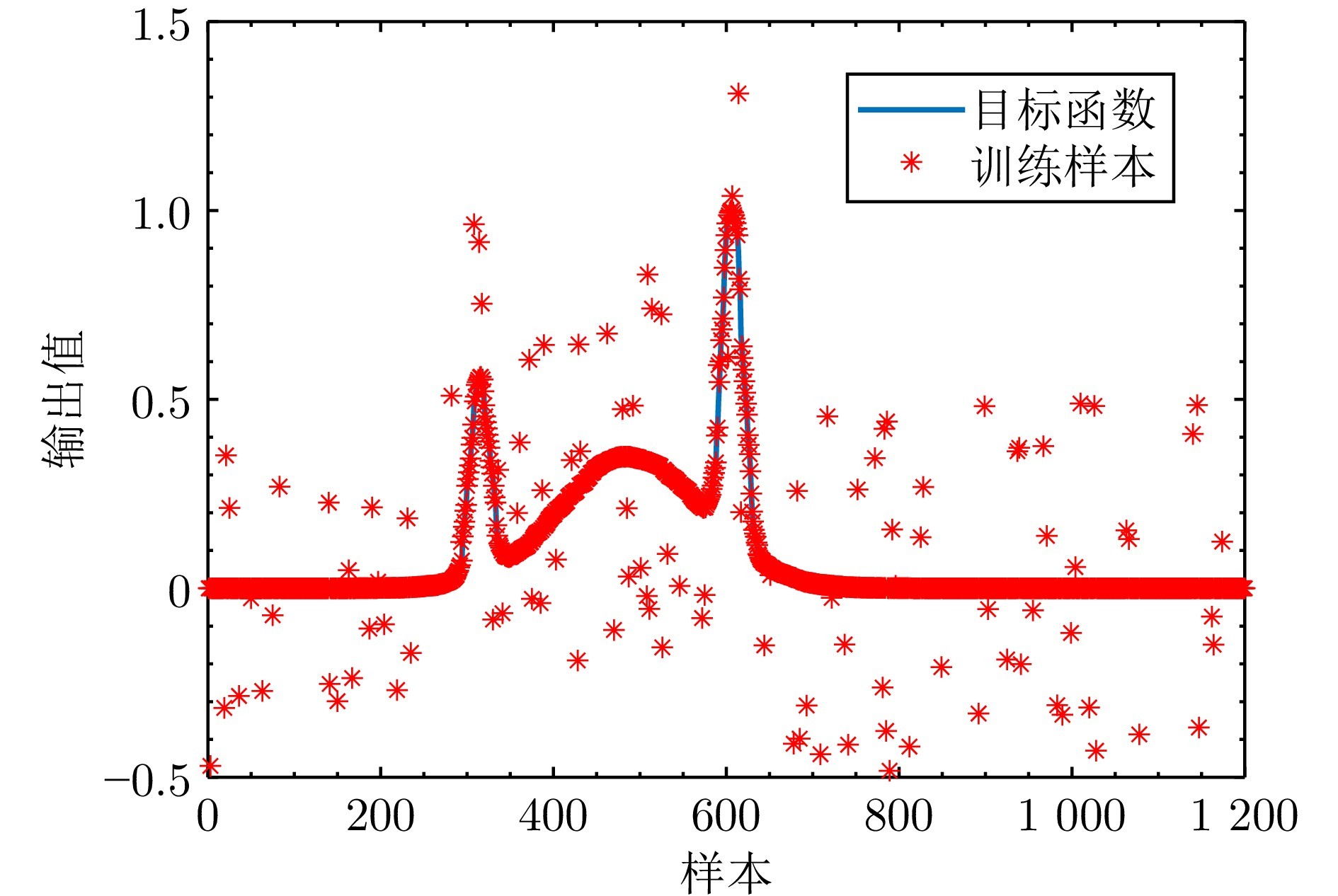
图2 含有10%异常值的训练样本
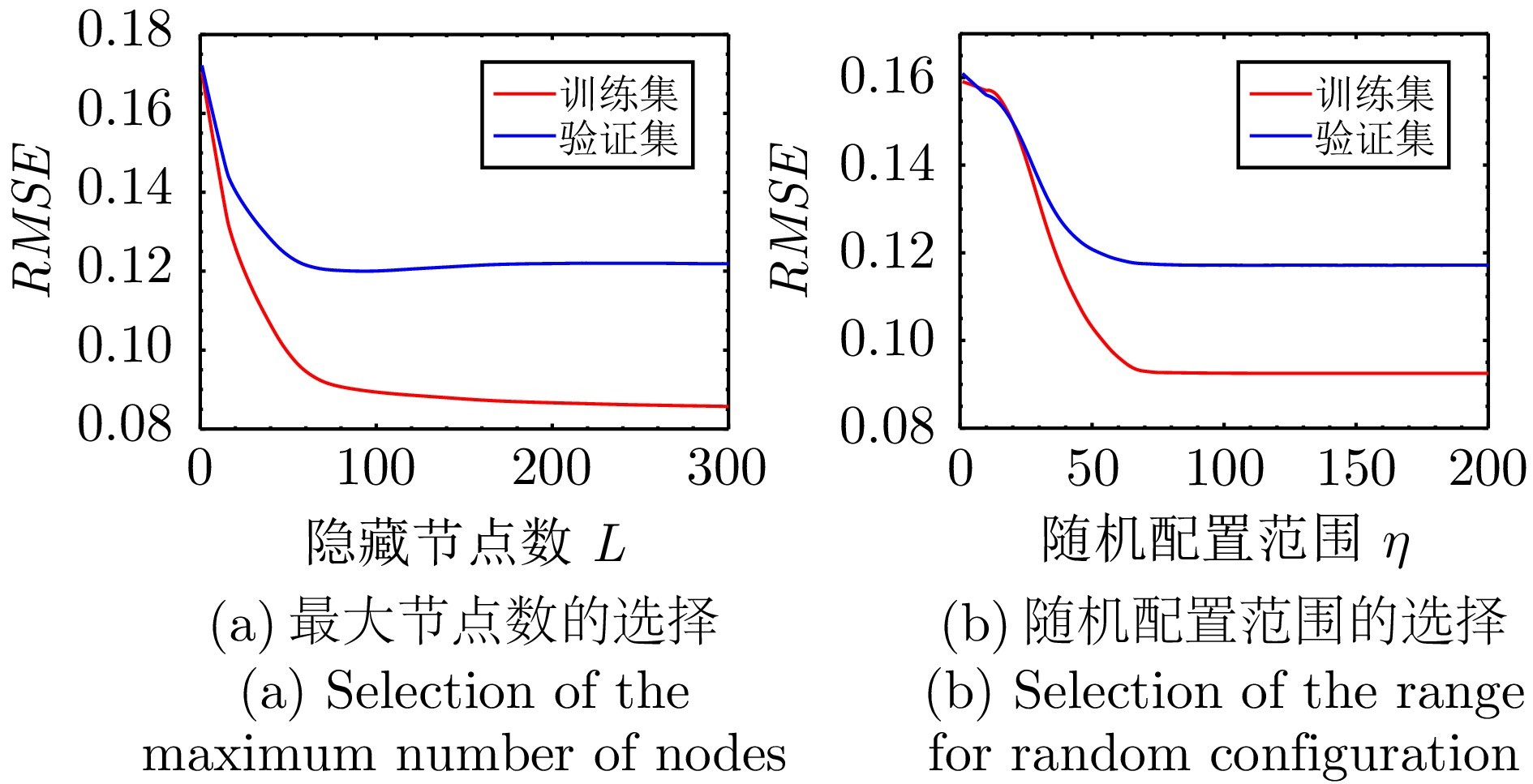
图3 利用验证集对DG-RSC算法进行超参数选择
本文提出的DG-RSC模型通过其双高斯协同抗噪架构, 显著增强了SCN在复杂工业噪声下的鲁棒性与预测精度. 双高斯加权机制通过融合大方差与小方差高斯分布, 分别精准捕获异常值特征与主体噪声分布, 并利用混合系数自适应调节权重, 从而实现对混合噪声结构的精准匹配. 采用期望最大化算法同步迭代学习高斯混合参数与网络输出权重, 这为模型提供了坚实的概率学解释基础. 最后在多个基准数据集与真实工业案例上的实验结果表明, 所提方法在抗噪声干扰与预测精度方面均有显著优势.
综上, 针对工业中常见的混合噪声问题, 本文提出的DG-RSC方法与现有鲁棒辨识方法相比, 具有更强的噪声结构匹配能力和综合性能. 在本文研究基础上, 未来的工作可从以下两方面展开:
1)实际工业过程的噪声特性往往随时间变化, 且数据以流式持续到达, 因此可基于本模型的双高斯混合结构研究增量式参数更新机制, 发展面向流数据的在线鲁棒辨识算法, 增强方法在动态环境中的适用性;
2)探索多组分混合模型或非参数贝叶斯方法, 以应对更复杂的噪声模式, 实现对噪声组分数量的自适应学习.
作者简介
刘鑫
中国矿业大学信息与控制工程学院副教授. 主要研究方向为系统辨识, 数据驱动的工业建模和软测量.E-mail: 15B904027@hit.edu.cn
李琪琪
中国矿业大学信息与控制工程学院硕士研究生. 主要研究方向为复杂工业过程建模.E-mail: ts24810009p31@cumt.edu.cn
代伟
中国矿业大学信息与控制工程学院教授. 主要研究方向为复杂工业过程建模、运行优化与控制. 本文通信作者.E-mail: weidai@cumt.edu.cn
https://blog.sciencenet.cn/blog-3291369-1532569.html
上一篇:自动驾驶系统逻辑场景全覆盖测试用例生成方法
下一篇:基于混合驱动与梯度优化的模糊宽度模型预测控制
