博文
研究领域开放数据的十年——真正的变革还是缓慢的顺应?
||
引用本文请注明出处
作者:Mark Hahnel 译者:何倩 校译:贺琳
来源:https://scholarlykitchen.sspnet.org/2022/03/30/guest-post-a-decade-of-open-data-in-research-real-change-or-slow-moving-compliance/
《自然》(Nature)杂志最近发表的关于NIH(National Institutes of health,美国国立卫生研究院)数据政策(从2023年1月开始)的新闻称其为“地震级别的”,这引起了很多人的关注。在我看来,事实确实如此。许多人会争辩该语言表达仍然不够有力,但是对我来说,世界上最大的生物医学研究公共资助者正在要求研究人员分享他们的数据,这一事实表明开放学术数据的推进速度正在加快。
虽然大多数人把注意力都集中在激励结构和研究人员的负担上,但学术界不应忽视开放数据在提升研究可重复性和效率方面潜在的“地震级别的”好处,以及推动知识更进一步和更快发展的能力。
在过去十年中取得了哪些成就?
我所在的公司Figshare为研究机构提供数据基础设施,同时也作为一个免费的通用存储库。我们最近获得了NIH GREI(Generalist Repository Ecosystem Initiative,通用存储库生态系统倡议,旨在补充NIH特定领域数据存储库)项目的资助,以改善通用存储库的状况,并与Dryad(一家致力于研究数据重用的非盈利组织)、Dataverse(一个开源研究数据存储库软件)、Mendeley Data(一个基于云的研究数据存储库)、Open Science Framework(一个开放的研究协作平台)和Vivli(一个全球临床研究数据共享平台)的同事进行合作。这个存储库社群见证了发布数据集的研究人员的快速增长以及随之而来的对最佳实践指导的需求。
从下面这张来自Dimensions.ai(一个关联研究信息数据集的平台)的曲棍球棒形图可以看出,这些存储库中的数据集在同行评审文献中的引用量在增长。请记住,这只是通用存储库,它不包括机构或特定学科的数据存储库。
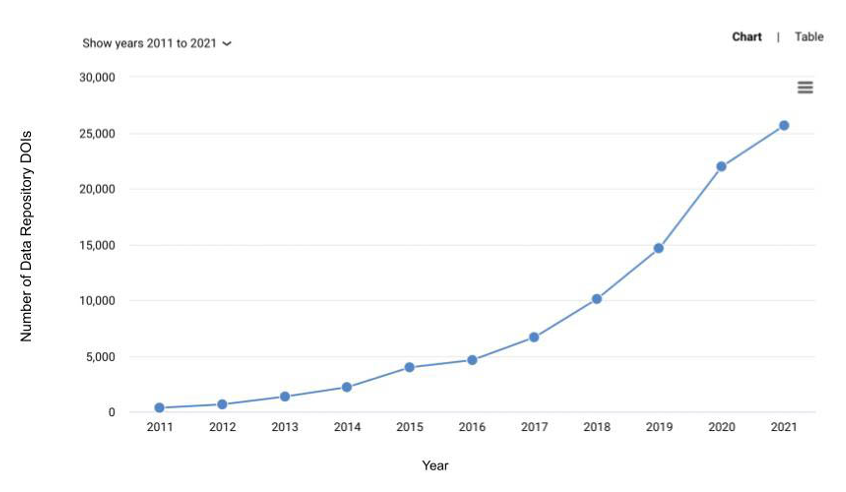
图1 已发表文献(2011—2021年)中引用Figshare、Dryad、Dataverse、
Mendeley Data、Open Science Framework和Vivli DOIs的增长情况
回顾开放研究数据的过去十年,有一些关键进展助长了该领域的发展势头,但也有一些理念迄今为止还没有实现。
NIH并不是第一个要求他们资助的研究人员应向所有人公开他们的研究数据的资助者。Sherpa Juliet(英国高等教育和研究数字解决方案提供商Jisc旗下提供研究资助者开放获取政策信息的数据库服务)网站上有52个资助者要求将数据存档作为资助条件,还有34个资助者鼓励这样做。出版商的推动也成为研究人员分享数据的主要动力。这可以追溯到PLOS(Public Library of Science,公共科学图书馆)在2014年要求所有文章作者公开他们的数据。现在,几乎所有主要的科学期刊都有某种形式的开放数据政策。有些人可能会说,对于研究人员来说,没有什么比面临文章不能发表的风险更能激励他们分享数据了。
2016年,一篇题为《科学数据管理的FAIR指导原则》(FAIR Guiding Principles for scientific data management and stewardship)的文章在《科学数据》(Scientific Data)杂志上发表,此后,关于可发现(Findable)、可访问(Accessible)、可互操作(Interoperable)和可重用(Reusable)数据的定义的辩论热潮一直在持续,这对该领域来说这是一次净赢。尽管每个机构、出版商和资助者的目标可能并不完全相同,但这是一个能更好地描述数据并最终使数据成为可用的独立成果的举措。可发现、可访问、可互操作和可重用数据的原则强调,在考虑研究数据时,未来的数据消费者将不仅仅是人类研究人员——我们还需要为机器提供数据。这意味着计算机将需要在很少或没有人类干预的情况下解释内容。要做到这一点,数据产出需要采用机器可读的格式,且元数据需要足够准确地描述数据是什么以及数据是如何产生的。
这就凸显了能够在最短时间内产生最大改变的领域(在我看来):元数据的质量。通用存储库总是难以捕捉到与特定学科存储库同样层级的元数据。因此,特定学科存储库应该始终是研究人员存放数据的第一站。然而,在未来十年,我们不太可能看到每个学科都有一个特定学科的数据存储库。我们将看到的是多管齐下的推进,为每个数据集都提供更好的元数据。这可以通过多种方式实现:
l 使用能鼓励用户采取最佳实践的软件。一个简单的第一步是鼓励研究人员像写论文一样给他们的数据集取个标题。可以通过软件提示用户:将数据集命名为“dataset”和将论文命名为“paper”一样有用。
l 招募图书馆员在研究数据发布之前编辑这些成果的元数据。
l 为学者提供更多培训,使他们意识到让数据更加具有描述性能使他们的数据更容易被发现。理论上,更高的可发现性意味着更大的重用潜力以及增强研究者的影响力——这是最大的激励因素。
l 提供数据规划服务。Dryad在这方面已经做了十年,我们开始看到有更多类型的解决方案可用于各种类型的数据。
l 利用网络上公开的相关信息对现有元数据进行标记。
对于出版商来说,存在着一个帮助研究人员发布数据的大好机会。大多数政策要求在发表关联论文时就发布数据。虽然论文总是为数据提供了语境和解释,但机器需要围绕这些对象的元数据,这些元数据要么直接来自论文——这意味着两者之间的联系是最重要的——要么在成果发布之前就在编辑人员的鼓励下准备好。
还有哪些方面的工作需要完成?
负面结果或无效数据的发布仍是一个尚未取得重大进展的领域。为研究人员提供公开其所有学术成果的工具只实现了目标的一半。更为重要的是,研究人员没有发布负面结果的动机。
虽然共享数据的研究人员数量正在迅速增长,但这并不意味着研究人员愿意这样做。Digital Science(一家致力于为科学研究过程提供数据服务和工作流解决方案的科技公司)的《开放数据的现状》(The State of Open Data)调查报告表明,大多数研究人员是为了遵守规定而发布数据。39%的受访研究人员说他们没有获得相应的署名或致谢。47%的调查对象说,如果期刊或出版商有要求,他们则会有动力去分享他们的数据。这种缺乏激励的情况,加上对被抢先一步发表的恐惧,可能也是最近越来越多的研究人员在文章中提及“根据请求获取数据”的原因——我认为这是一种不好的做法。
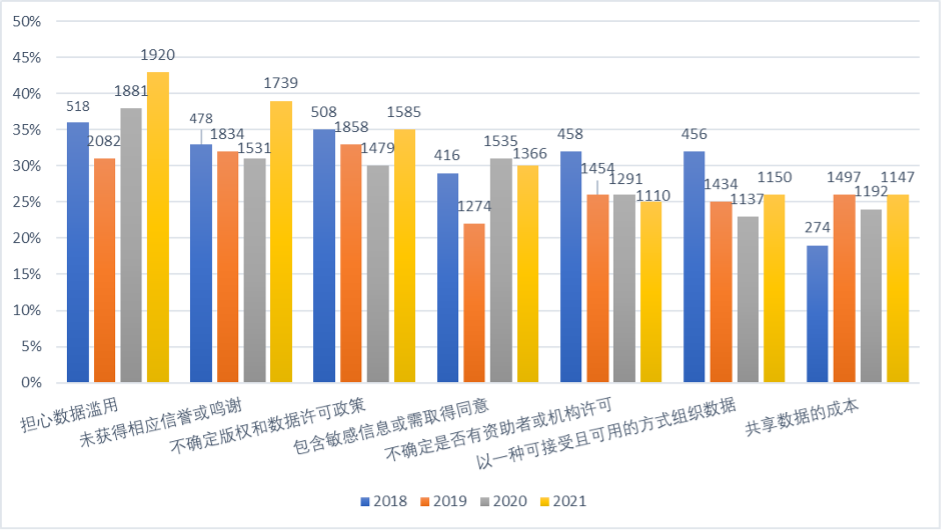
图2 过去4年有关共享数据的问题或顾虑(来自《开放数据的现状2021》报告
https://doi.org/10.6084/m9.figshare.17061347)
接下来会发生什么?
如果说过去10年是鼓励研究人员在网上提供数据,那么未来10年应该是让数据变得有用。学术研究中的第四范式(Fourth Paradigm)概念被设想为一种推动知识前沿的新方法,该范式通过收集、处理、分析和展示数据的新技术来实现。这个词似乎起源于吉姆·格雷(Jim Gray),他为2009年出版的《第四范式:数据密集型科学发现》(The Fourth Paradigm: Data-intensive Scientific Discovery)做出了贡献,但遗憾的是,他已经去世了,无法看到他的预言是如何实现的了。
在过去十年中,我花了很大一部分时间来推测开放数据对加快信息变成知识的速度上会有什么益处。我们开始看到现实世界的例子,比如AlphaFold,这是一个解决生物学领域50年来的巨大挑战的方案。这个成功故事的核心依赖于来自蛋白质数据库(Protein Data Bank)的人工智能训练数据。蛋白质数据库本身已有50多年的历史,它将同质数据集整合在一起,非常适合人工智能和机器学习。下面关于发表来自Deepmind(谷歌旗下前沿人工智能公司)的研究结果的相关引文也强调了将描述良好的开放数据与人工智能结合起来,可以实现第四范式中设定的崇高目标:
“这一突破展现了人工智能对科学发现的影响,以及它在显著加速那些解释并塑造我们的世界的一些最基本领域的进展的潜力。”
因此,描述良好的开放数据将通过为我们的机器霸主提供燃料来加快科学发现的速度。数据的规模和数量可能会继续超出以有意义的方式存储和查询学术成果的能力,如果我们今天没有掌握围绕特定学科社区的最佳实践的基本原理,情况会更加糟糕。机器学习和人工智能可以帮助我们寻找数据中的模式和关系,这将永远超出人类付出努力可实现的范畴。同时也始终需要人类对这些结果的理解以进一步推动前沿发展,就像人类和机器的结合被证明是国际象棋竞争中的最佳选择。
在我们应对后疫情时代的同时,世界从未像现在这样意识到需要在知识发现方面进一步加快步伐。在传统的学术出版过程中,实现这一目标所缺失的拼图是描述良好的开放数据。有些人可能会说,其影响可能是“地震级的”。
https://blog.sciencenet.cn/blog-521339-1338646.html
上一篇:预印本的反馈:FAST原则
下一篇:开放获取及其前进方向