博文
超启发式算法:一种跨领域的问题求解模式
|||
超启发式算法与元启发式算法有些类似,也提供了一种高层框架,通过调用底层启发式算子来实现对于问题的求解。与元启发式算法相比,超启发式算法更加侧重如何将应用领域知识屏蔽在高层框架以外。通俗地说,超启发式算法是“寻找启发式算法的启发式算法”。更加严格地定义如下:
定义1. 超启发式算法提供了某种高层策略(High-Level
Strategy,HLS),通过操纵或管理一组低层启发式算法(Low-Level
Heuristics, LLH),以获得新启发式算法。这些新启发式算法则被运用于求解各类NP-难解问题。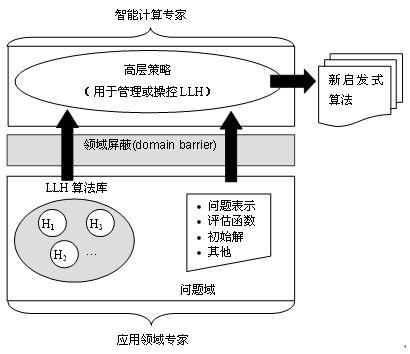
图1 超启发式算法的概念模型
图1 给出了超启发式算法的概念模型示意图。从图中可以看出,超启发式算法分为两个层面:在问题域层面上应用领域专家需根据本人的背景知识,提供问题的定义、评估函数等信息和一系列LLH;而在高层策略层面上,智能计算专家则通过设计高效的操纵管理机制,利用问题域所提供的问题特征信息和LLH算法库,构造新的启发式算法。因为这两个层面之间实现了严格的领域屏蔽,仅仅需要修改问题域的问题定义和LLH、评估函数等领域有关信息,一种超启发式算法就可以被快速地迁移到新的问题上。因此,超启发式算法特别适合求解跨领域的问题。需要引起注意的是,研究超启发式算法的目标并不是取代智能计算专家,而是如何将智能计算技术更快地推广到更多的应用领域,同时有效第降低启发式算法的设计难度,从而将领域专家和智能计算专家的研究重点有效地划分开。根据图1 可知,智能计算专家在超启发式算法设计中主要关注于高层策略,而领域专家则重点研究问题的目标函数和LLH等。
由于超启发式算法的研究尚处于起步阶段,对于已有的各种超启发式算法,国际上尚未形成一致的分类方法。按照高层策略的机制不同,现有超启发式算法可以大致分为4类:基于随机选择、基于贪心策略、基于元启发式算法和基于学习的超启发式算法。
该类超启发式算法在构造新启发式算法时,每次都挑选那些能够最大化改进当前(问题实例)解的LLH。由于每次挑选LLH时需要评估所有LLH,故此该类方法的执行效率低于基于随机选择的超启发式算法。
该类超启发式算法采用现有的元启发式算法(作为高层策略)来选择LLH。由于元启发式算法研究相对充分,因此这类超启发式算法的研究成果相对较多。根据所采用的元启发式算法,该类超启发式算法可以细分为基于禁忌搜索、基于遗传算法、基于遗传编程、基于蚁群算法和基于GRASP with path-relinking等。
2. 超启发式算法vs.启发式算法
超启发式算法与已有的启发式算法既有一定的相似性,又有显著的不同。通过分析超启发式算法与启发式算法的异同点,可以更加深入地理解超启发式算法。表2从多个视角,对超启发式算法与启发式算法进行了对比,从中我们可以发现以下现象:
(1)超启发式算法与启发式算法均是为了求解问题实例而提出的。因此,问题实例可以视为超启发式算法和启发式算法两者共同的处理对象。
(2)超启发式算法与启发式算法都可能包含有参数。在传统的启发式算法中,可能有大量的参数需要调制。比如遗传算法中的种群规模、交叉率、变异率、迭代次数等。而超启发式算法的参数来源有两个层面,在LLH和高层启发式方法中均可能有参数需要调制。
(3)超启发式算法与启发式算法都是运行在搜索空间上,但是各自的搜索空间构成不同:传统启发式算法是工作在由问题实例的解构成的搜索空间上;而超启发式算法运行在一个由启发式算法构成的搜索空间上,该搜索空间上的每一个顶点代表一系列LLH的组合。因此,超启发式算法的抽象程度高于传统启发式算法。
(4)超启发式算法与启发式算法均可以应用到各种不同的领域,但是它们各自对于问题领域知识的需求是不同的。启发式算法设计通常需要依赖于问题的特征;而超启发式算法的高层启发式方法部分则几乎不依赖于问题的领域知识,LLH则是与问题的领域知识紧密相关的。目前启发式算法的应用已经十分广泛,而超启发式算法由于历史较短,还主要局限在部分常见的组合优化问题上。
表2 超启发式算法与启发式算法多视角对比
|
|
启发式算法
|
超启发式算法
|
|
处理对象
|
问题实例
|
问题实例
|
|
参数
|
可能有
|
可能有
|
|
搜索空间
|
由实例的解构成
|
由LLH串(启发式算法)构成
|
|
应用领域
|
广泛
|
有待拓展
|
---------------------------------------------------------------------------------------------
1Workshop
in conjunction with GECCO’09: Automated
Heuristic Design: Crossing the Chasm for Search Methods.
Special Session with CEC’10: Hybrid Evolutionary
Algorithms, Hyper-heuristics and Memetic Computation.
Workshop in
conjunction with PPSN’10: Self-tuning, Self-configuring and Self-generating
Search Heuristics.
https://blog.sciencenet.cn/blog-267533-530895.html
上一篇:[推荐SCI/EI期刊] IEA/AIE 2012会议专题截稿日期:1月6日
下一篇:皇后也疯狂:如何在1分钟内摆放300万个皇后