博文
人工智能:大数据、模型与数据驱动
|
1.人工智能走过的两条路线
莱特兄弟之前,人们发明飞机的思路是模仿鸟类飞行,希望造出能振翅高飞的器械,这种尝试无一例外都以失败告终。莱特兄弟改变了思路,他们用的是空气动力学原理,而不是仿生学。
人工智能也经历过“仿生学”阶段,早期人工智能的思路是,先了解人类是如何思考的,然后让计算机模仿人类思考。沿着这条思路,人们研究了十几年,结果除了做出几个简单的“玩具”之外,人工智能解决不了什么问题。
到了20世纪70年代,人们开始尝试另一种思路,即数据驱动。什么是数据驱动?回答这个问题之前,先看看计算机的工作流程。简言之,计算机工作流程是:获取数据——建立模型——分析决策。
2.模型与大数据
根据计算机的工作流程,自然要问:解决某个具体的问题,该用什么模型?下面从我的工作经历说起。
在我职业生涯的早期(2010年),我遇到一个直线共轭齿轮设计问题。学机械的人都知道,在学校学的齿轮(包括市面上大多数齿轮)都是渐开线齿轮。现在我要面对的是一个从未见过的问题。
我查找了文献,发现主要有三种模型,第一种是利用坐标变换,建立参数方程;第二种是利用复数矢量法,建立复数矢量方程;第三种是通过建立齿廓法线,反转求解直线共轭齿廓方程。三种模型如下图:
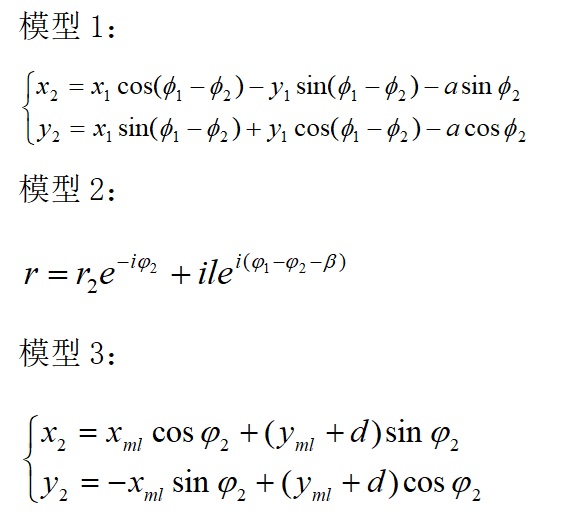
这三种模型不但复杂,且无法解决我当时遇到的实际问题(齿轮加工)。忘了在什么的启发下,我想到读研时学过函数逼近理论,于是重新翻了数学教材和一些数学著作(如《数学,它的内容、方法和意义》)。发现俄国数学家切比雪夫在设计机械时提出了最佳一致逼近的设想,后来,德国数学家魏尔斯特拉斯证明了:可以用代数多项式以任意给定的精度逼近任何连续函数。
据此,我只用了初中就学过的一元二次方程,顶多一元三次方程,就以足够的精度解决了问题,比上面那些模型简单得多。6年后,即使2016年,我把分析过程整理成文,发表出来,如下图。
但是我的模型也不是十全十美的,比如它没有几何和物理意义。这说明,即使齿轮这种很简单的问题,也很难找到十全十美的模型。
人们期望计算机能解决的问题,比齿轮复杂得多。很多时候,完美的模型根本不存在,即使存在,找到它也不容易。有人想到用不太完美的模型,或者用多个不太完美的模型进行组合达到完美的效果。
无论找到一个完美的模型,还是由多个不完美的模型来组合,下一步要确定模型的参数。比如说我采用初中学过的一元二次方程模型:
y=ax2+bx+c
那么就要根据实际情况,找到模型参数a,b,c,参数越准确,效果就越好。如果这个过程由计算机完成,就叫机器学习,也叫机器训练。
科学技术的进步很多时候都要看运气,人工智能也不例外。1972年康奈尔大学的贾里尼克教授去IBM做学术休假。那时的IBM是巨无霸,拥有大量数据,贾里尼克教授无意中利用了IBM的数据和算力优势。发现随着数据量的增大,训练效果会越来越好,而过去的办法(仿生学),很难受益于数据量的增大。
后来其他教授去IBM参观,看到IBM采用数据驱动的方法取得巨大成功,很多教授都接受了这种方法。李开复就是在这种背景下,在传统的人工智能实验室,采用新的方法(数据驱动)开展他的人工智能(语音识别)研究的。
据一些人说,如果没有李开复的工作,他的导师不可能获得图灵奖,可见,李开复的名声是名副其实的。继李开复用数据驱动办法,解决语音识别之后,很多计算机科学家考虑能否用数据驱动解决其他智能问题。
李开复之后,数据驱动的人工智能又经历了近20年的波折,比如数据驱动用在语音识别上效果很好,用到别的问题,比如机器翻译效果却不好。期间争论不断,直到21世纪初,大部分人都看到了数据驱动的优势,纷争才逐渐平息。
近20年的波折主要原因是数据量不足,直到90年代互联网的兴起,使数据的获取变得容易,数据驱动方法才逐渐见到光明。其实有些领域到21世纪头几年还很难获得足够的数据,比如2006年李飞飞训练视觉智能时,还很难获取到足够的图片。有些问题直到现在可能都还很难获得足够的数据。
不过按吴军的观点,2005年算是大数据的元年。理由是,在当时还名不见经传的谷歌公司,以巨大的优势打败全世界所有机器翻译研究团队,一跃成为该领域的领头羊。
谷歌有什么秘诀呢?其实说出来太没创意了,方法还是老方法,只不过谷歌拥有比其他研究机构多几千上万倍的数据而已。量变引起质变,谷歌用大数据训练出来的模型远远优于其他团队。
至此,我们看看什么叫大数据?
显然,正如它的名称,数据量要大。但是不能把大数据等同于大规模数据。比如你拥有全中国14亿人的出生年月日数据,这个数据量不可谓不大,但是这么大规模的数据量除了能够统计出全国人的年龄分布之外,并没有太大的意义。统计全中国人的年龄分布,随机抽一亿个,甚至只需要几百万就足够了。
大数据之所以有用,除了数据规模大之外,还有其它特征。
大数据主要有三大特征:量大、及时、多样(完备)。当然并不是所有数据都要同时满足这三个特征,尤其是及时性。比如研究清朝的GDP,显然不需要及时的数据。但如果要通过交通数据来指导当下人们的出行,显然不能用上周的数据。
数据的多样性最非常关键,多样性的价值可以用考试做类比说明。题海战术某种意义上就是数据驱动,大量刷题,掌握各种题型的解题技巧,考试时恰好很多题目是你训练过的,就能得高分。但是,如果你只大量刷一种题型,就很难得高分,甚至考不及格,因为考试时很多题型你都没见过。
也许你听过幸存者偏差,数据缺乏多样性就容易出现幸存者偏差。很多商业图书的套路是,一个成功企业家总结他为什么成功,隐含的意思是:让我来告诉你如何像我一样大获成功。但是采用跟成功者差不多管理方法的,失败可能还多于成功。所以我们不能只向成功者学习,也要吸取失败者的教训,只是失败者一般不写书。
3.从数据和能量看人工智能
为什么AlphaGo能战胜围棋天才李世石?我们可以从数据和能量的角度估算一下。
人下一盘围棋一般需要1-10小时不等,姑且按3小时一盘计算。假如李世石每天下棋12小时,那么一天下4盘,又假如他全年无休,那么他一年只能下1400多盘。AlphaGo可是分析总结了几十万盘高手对弈,这么大的数据量,李世石下一辈子围棋也无法企及。
AlphaGo用如此大的数据量训练出来的模型,碾压李世石听起来就不足为奇了。
再从能量角度分析。按正常人估算,李世石一餐吃一到两碗饭,每日三餐,顶多再加点水果零食,这就是他一天获得的能量。
AlphaGo跟李世石对弈时,谷歌用了1920个中央处理器(CPU),280个图形处理器(GPU),几十台服务器同时工作。李世石的所有决策,只靠他一个头脑,真是以大欺小,以强欺弱,太不公平了。
这么多服务器同时工作,耗电量多少我没有数据。下面是吴军的数据及他的估算:
跟李世石对弈时,谷歌每个CPU每秒可完成5000-7000亿次运算,每个GPU每秒可完成7万亿次运算,这么大的计算量,如果用早期的计算机,至少要400万座三峡电站满负荷运转给计算机供电才够。
这从一个侧面说明为什么人工智能最近才取得突破——得益于摩尔定义,硬件算力越来越强,功耗越来越低。同时也说明人的大脑处理信息单位功耗很低。
4.问题
随着近10年物联网的兴起,我们已进入万物互联时代。物联网中数量庞大的传感器和设备,加上5G移动通信网络,已为大数据和人工智能铺平了道路。
但现在人工智能仍处于初级阶段,接受大数据、人工智能思想的人不多,有实际行动的更少。当然现在人人都用AI,那只是当高级“百度”使用。
假如你公司采用大数据和人工智能,在设备上安装了很多传感器,用于获取设备的运行数据,但卖出去的产品原则上所有权已属于客户了。
你是否遇到客户不愿意给你提供数据的情况?换句话说,客户不愿意让掌握设备的运行数据。如果遇到,怎么解决?
参考:
1.《智能时代》,作者:吴军。
2.《我看见的世界》,作者:李飞飞。
https://blog.sciencenet.cn/blog-485553-1527390.html
上一篇:人工智能:数据、信息与不确定性
下一篇:人工智能:从工具到思维方式的转变
