博文
“视觉智能与信息安全”专栏 | MDPI Sensors:深度学习传感器融合用于行人检测的初步研究
||
原文出自 Sensors 期刊:
Plascencia,
A.C.; García-Gómez, P.; Perez, E.B.; DeMas-Giménez, G.; Casas, J.R.;
Royo, S. A Preliminary Study of Deep Learning Sensor Fusion for
Pedestrian Detection. Sensors 2023, , 4167.https://doi.org/10.3390/s23084167
引言
自动驾驶汽车 (ADC) 是一个不断发展的研究领域,全自动公共汽车很可能很快成为现实。根据一些官方预测,预计到2035年,大多数汽车将实现完全自动驾驶。在这种情况下,ADC的安全因素之一是检测不同天气条件和不同情况下的行人。例如,正确识别和检测ADC附近的行人对于避免潜在的道路事故至关重要。大多数行人检测方法都集中在基于RGB与激光雷达融合的边界框上。这些方法与人眼如何感知现实世界中的物体无关。此外,激光雷达和视觉在散射环境中很难检测到行人,雷达可以用来克服这个问题。
近期,Sensors 期刊发表了题为 “A Preliminary Study of Deep Learning Sensor Fusion for Pedestrian Detection”的研究论文。作为初步步骤,这项工作的动机是探索将激光雷达、雷达和RGB融合用于行人检测的可行性。该方法使用全连接卷积神经网络架构用于多模式传感器。该网络的核心是基于SegNet,一个逐像素的语义分割网络。激光雷达和雷达是通过将它们从3D点云转换为具有16位深度的2D灰度图像来合并的,RGB图像通过三个通道合并。该架构对每个传感器的读入使用单个SegNet,然后将输出应用于完全连接的神经网络,以融合传感器的三种模式。然后,应用上采样网络来恢复融合的数据。
研究内容
该文的主要贡献是探索使用小型数据集将RGB图像与激光雷达和雷达点云融合用于行人检测的可行性。提出了一种新颖实用的用于语义像素分割的全连接深度学习CNN架构SegNet。该网络由三个对每个传感器的输入进行下采样的SegNet子网络、一个融合传感器数据的全连接 (fc) 神经网络 (NN) 和一个对数据进行上采样的解码器网络组成。因此,该方法侧重于在像素级别上检测人。识别行人的任务被称为语义分割,包括基于在像素级标记的数据集产生像素级分类。通常,只有一类人感兴趣,那就是行人。此外,在融合过程中加入雷达具有能够在恶劣天气条件下检测行人的优势。此外,该文还提出了一种利用激光雷达和RGB相机对雷达进行外部校准的方法。
文中所提出的处理传感器融合方法的CNN网络是基于如图1展示的SegNet体系结构。它由编码器和解码器网络组成,分别具有26个卷积层、5个池化层和5个上采样层。编码器网络 (EN) 的功能是对输入进行下采样并提取特征。另一方面,解码器网络 (DN) 对数据进行上采样并重建图像。EN和DN之间的完全连接层被丢弃,目的是在最深的编码器输出处保留更高分辨率的特征图。文中提出了一种卷积网络实现多模态传感器融合方法来检测人 (图2)。该网络由三个作为输入的EN、一个融合数据的全连接神经网络 (FCNN) 和一个对融合数据进行采样和恢复的DN组成。
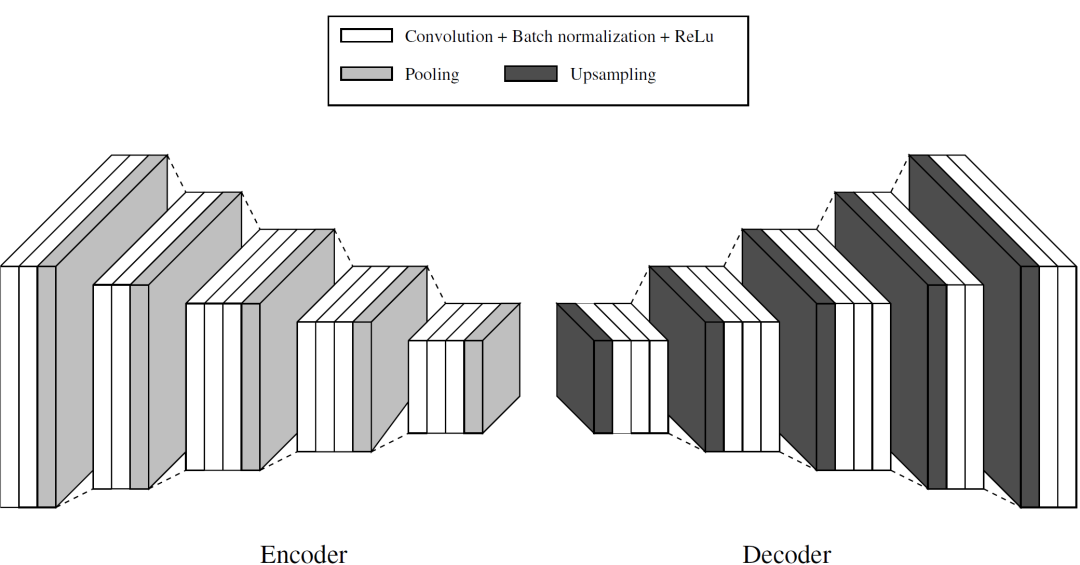
图1. 文中使用的像素语义分割SegNet CNN网络。
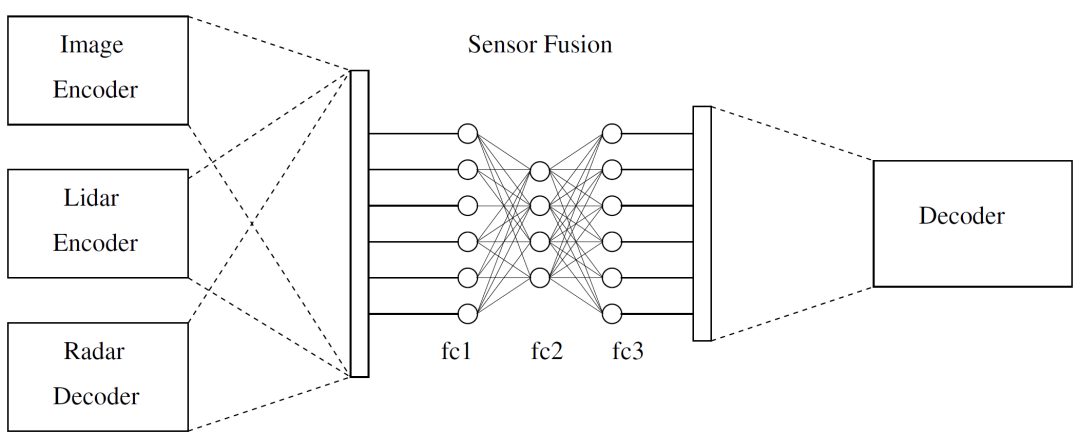
图2. 架构模型。
实验结果
用于仿真的系统由L3CAM激光雷达、UMRR-96 153型雷达和GE66 Raider Intel®Core (TM) i9-10980HK CPU和NVIDIA GeForce RTX 3070 8Gb GPU组成。Ubuntu 20.04.5 LTS上的机器人操作系统 (ROS1) Noetic用于收集传感器数据、计算外部参数和对齐传感器。此外,CNN网络在Jupyter笔记本中使用Python 3和conda环境进行了模拟。
CNN是使用一个自定义数据集进行训练的,该数据集在停车场拍摄,人们走在系统前面。数据集的格式为yyyy-MMdd:hh:mm:ss:zz,其中yyyy表示年份,mm表示月份,dd表示日期,hh表示小时,mm表示分钟,ss表示秒,zz表示毫秒。之所以选择这种格式,是因为激光雷达、RGB和雷达频率分别为6 Hz、10 Hz和18 Hz。例如,典型的格式为20221017_131347_782.pcd,其中hh=13,mm=13,ss=48。这意味着激光雷达将重复48次,RGB将重复10次,雷达将重复18次。zz=782的值对于每次读取都是不同的,因此更易于同步。
之后,对数据集进行同步,总共生成224张LRR图像。选择30个LRR图像,通过翻转并将它们添加到原始集合中,将其扩展到60个。程序“labelme”用于将RGB图像标记为“单一类别的人”。换言之,“labelme”可以创建人物的多边形,并将其保存为JSON,该JSON可通过单个人物类提取为PNG图像。激光雷达图像以PCD格式保存、提取并转换为具有16位深度的2D灰度图像。对它们进行插值以提高质量。雷达图像也以PCD格式保存、提取并转换为具有16位深度的2D灰度图像。雷达图像中每个点的位置都是垂直投影的。
训练、评估和测试模式在Pytorch版本为1.11且GPU激活的Jupyter笔记本电脑上执行。LRR图像被下采样到256×256的大小。此外,由于GPU的容量为8GB,因此将批量大小设置为1。接下来,该网络被训练了300个epoch。此外,使用10张LRR图像进行验证,使用10幅LRR进行测试,得到了80幅LRR图像的总数据集。
训练模式的结果如图3(a—e) 所示。图3(a) 显示了应用于EN的RGB图像,而图3(b) 显示了地面实况图像。此外,激光雷达和雷达图像如图3(c) 和图3(d) 所示。最后,图3(e) 描绘了激光雷达、雷达和RGB之间的融合图像。此外,网络训练过程中所花费的时间为7019.40秒,而模型在测试模式下的平均时间为0.010秒。

图3. 训练模式的结果。
测试模式的结果如图4所示,其中叠加了地面实况和模型的输出。该模型对行人的检测显示为红色,表示与地面实况重叠的区域。行人附近和行人之间的白点是模型输出的一部分,但与地面实况不重叠。浅蓝色表示检测到的行人较弱,这是模型过度拟合和训练数据大小有限的结果。这可以通过输出和地面实况之间1.413的损耗来证实。

图4. 测试模式的结果。
总结
作为初步或试点步骤,该文探索了通过使用传感器融合像素语义分割CNN-SegNet网络融合激光雷达、雷达点云和RGB图像用于行人检测的可行性。所提出的方法具有在像素级检测行人的优点,这在使用边界框的传统方法中是不可能的。使用自定义数据集的实验结果表明,所提出的体系结构实现了高精度和高性能,适用于计算资源有限的系统。然而,由于这是一项初步研究,因此必须谨慎解读结果。该文还提出了一种基于奇异值分解的激光雷达和雷达在包括RGB相机的多模式传感器融合架构中的外部校准方法,并证明该方法可将激光雷达与雷达点之间的平均范数提高38.354%。
撰稿人:陆哲明
专栏简介
“视觉智能与信息安全”专栏由Sensors 期刊编委陆哲明教授 (浙江大学) 主持,专注于视觉智能与信息安全领域的前沿进展与创新应用。
专栏编辑

陆哲明 教授
浙江大学
浙江大学教授、博士、博士生导师,浙江大学航空航天系主任、航天电子工程研究所副所长。2002年哈尔滨市青年科技奖获得者,2003年全国优秀博士学位论文奖获得者。截至2022年1月3日已发表SCI检索论文163篇,ESCI论文14篇,EI单检论文214篇,获省部级科技一等奖1项、二等奖4项、三等奖1项,厅级科技一等奖2项,出版专著教材15部,发明专利授权14项。2020年和2021年连续两年获得Elsevier中国高被引学者。2013年起担任国防科工局CCSDS专家、国家科学技术奖励评审专家;2017年起逐步担任国家自然科学基金重点项目评审专家、国家网络信息安全领域重大专项评审专家、全国宇航技术及其应用标准化技术委员会空间数据与信息传输分技术委员会委员;2020年起加入腾讯科学探索奖评审专家库,并开始担任澳门特区政府科技奖评审专家。2020年起担任SCI期刊Sensors 编委。陆教授长期从事多媒体信号处理、信息隐藏、复杂网络、人工智能四个领域的研究。这四个方面的研究工作并非孤立的,都是在数字媒体和网络技术飞速发展的背景下展开的。


https://blog.sciencenet.cn/blog-3516770-1387390.html
上一篇:Nutrients:“营养和肝病”主题文章精选 | MDPI 编辑荐读
下一篇:“气候变化与环境可持续性”专栏:基于城市规划的热岛脆弱性评价——以蒙彼利埃都市圈为例