博文
基于MARL-MHSA架构的水下仿生机器人协同围捕策略: 数据驱动建模与分布式策略优化
|
引用本文
冯育凯, 吴正兴, 谭民. 基于MARL-MHSA架构的水下仿生机器人协同围捕策略: 数据驱动建模与分布式策略优化. 自动化学报, 2025, 51(10): 2269−2282 doi: 10.16383/j.aas.c250086
Feng Yu-Kai, Wu Zheng-Xing, Tan Min. Cooperative pursuit policy for bionic underwater robot based on MARL-MHSA architecture: Data-driven modeling and distributed strategy optimization. Acta Automatica Sinica, 2025, 51(10): 2269−2282 doi: 10.16383/j.aas.c250086
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c250086
关键词
仿生机器鱼,围捕−逃逸问题,深度强化学习,数据驱动建模,注意力机制
摘要
针对水下仿生机器人集群的围捕−逃逸问题, 提出一种融合多头自注意力机制的多智能体强化学习策略训练框架. 该框架构建一种基于多头自注意力机制的中心化决策网络, 在提升策略训练效率的同时, 保留分布式决策架构, 有效增强个体的自主决策能力与群体间的协同性能. 此外, 针对策略由仿真环境向真实场景迁移过程中动力学建模不精确、感知−动作存在偏差等挑战, 构建一种由真实场景机器鱼运动数据驱动的仿真环境, 有效提升了策略的可迁移性与部署的可靠性. 通过仿真与真实场景实验验证了所提方法在水下仿生机器人协同围捕任务中的有效性. 相较于多智能体近端策略优化算法, 该方法可使平均围捕成功率提升24.3%、平均围捕步长减少30.9%, 显著提升了水下仿生机器人集群的协同围捕效率. 该研究为多智能体强化学习在水下仿生机器人集群任务中的应用提供了新的思路和技术支持.
文章导读
自然界是人类创新的无穷源泉. 鱼群通过高度协同行为形成的集群智能, 为多水下仿生机器人系统的协同决策研究提供了宝贵的启示. 在自然界中, 鱼群通过分布式感知与自适应协调的方式, 可在复杂动态环境中高效完成协同捕食、动态避障和集群迁徙等复杂任务[1−2]. 以虎鲸群体的波浪式围捕策略和旗鱼群的分工协作狩猎模式为例, 其在目标定位精度、围捕成功率及能量利用效率等方面展现出显著优势. 这类生物群体在环境适应性与协作效率方面表现出的卓越能力, 激起了控制科学、仿生工程与群体智能等交叉学科的研究热潮[3−5]. 作为多智能体系统的典型应用, 受生物捕食行为启发的围捕−逃逸问题逐渐成为研究的热点. 在多机器人围捕−逃逸任务中, 围捕者团队由多个独立个体组成, 通过合作在地面[6]、空中[7]和水下[8]等特定环境中高效捕捉逃逸者. 其关键在于如何在动态变化的环境中进行复杂的决策和协调, 确保围捕者团队能够实现紧密合作、处理实时信息, 并通过有效的动态规划实现任务目标[9−11].
在以往解决方案中, 研究人员通常会对对手的行为施加一定假设[16]. 然而, 在许多实际场景中, 围捕−逃逸任务中往往包含智能化的竞争对手, 这些对手的行动并不局限于预定义的规则或受限的行动集. 因此, 设计能够在对手采取最坏行动时优化某一准则的策略, 并确保策略在对同一对手所有可能行为下都具备稳健性, 成为当前研究中的一个重要挑战[17−18]. 1999年, Isaacs[19]首次提出双机器人一对一追逃问题, 并通过构建围捕者和逃逸者的偏微分方程来寻找该问题的可行解. 此后, 随着研究的深入, 多机器人围捕问题逐渐引起学术界的广泛关注. 常见的解决方法包括动态博弈法[20]、粒子群优化算法[21]和图论建模[22]等. 尽管这些方法在某些场景中表现优异, 但它们通常依赖于理想化的模型假设, 并且具有较高的计算复杂度. 此外, 在高度非线性和不确定性较强的场景中, 动力学和环境的精确建模往往变得十分困难. 除此之外, 随着智能体数量的增加, 这些方法的计算复杂度通常呈指数级增长, 严重限制了其可扩展性.
近年来, 强化学习因其能够适应动态环境且无需精确建模的优势, 逐渐成为解决围捕–逃逸问题的主流方法之一. 2019年, Wang等[23]提出一种结合模糊推理与强化学习的模糊确定性策略梯度算法, 通过演员−评论家(Actor-critic, AC)结构优化方法, 得到在连续动作空间的近似最优策略, 在精度和收敛效率上均优于传统方法. de Souza等[24]提出一种基于双延迟深度确定性策略梯度的分布式多智能体追逐算法, 通过共享经验与课程学习, 成功实现了策略从仿真到现实的转移. Zhang等[25]结合深度强化学习与人工势场法, 提出一种混合追逃策略, 在动态环境中的表现优于单纯的深度学习或人工势场方法, 且可部署于实际系统. Kouzeghar等[26]提出一种基于改进多智能体深度确定性策略梯度算法的分布式异构无人机群多目标追逐方法, 成功实现了在复杂环境中的快速、智能目标追踪. 尽管现有的强化学习算法在多智能体环境中表现良好, 但仍面临难以高效处理复杂交互以及信息利用率低等问题. 尤其是在水下围捕−逃逸任务中, 传统的集中式方法通常从全局视角进行决策优化, 从而忽视了智能体之间的动态交互. 因此, 如何动态调整智能体间的关注点和信息流动至关重要.
除此之外, 随着水下仿生机器人平台性能的不断提升, 如何实现强化学习策略在仿真训练与真实部署之间的有效迁移已成为该领域的研究焦点[27]. 然而, 受限于水下仿生机器人固有的欠驱动特性, 以及水下环境中普遍存在的高噪声与强扰动, 该迁移过程面临着更为严峻的挑战[28−29]. 为应对这些挑战, 研究人员已展开了相关研究. Qiu等[30]通过构建高保真水动力学模型, 成功实现多智能体强化学习的训练, 并完成了线驱动机器鱼的路径跟踪和稳定控制任务. Yan等[31]将深度强化学习与流体动力学、运动学耦合仿真相结合, 提出一种面向仿生机器鱼的仿真与控制框架, 实现了机器鱼在复杂环境中的智能避障控制. Zhang等[32−33]通过采集真实机器鱼的游动轨迹数据, 建立低差异化的仿真模型, 并成功完成了机器鱼在二维平面内的姿态控制和轨迹跟踪任务. Yan等[34]采用模仿学习方法, 通过采集专家数据来缩小仿真与实际场景之间的差距, 从而实现仿生机器鱼在未知水域环境中的最大区域探索. 在上述研究中, 高保真建模方法虽可较为准确地拟合水动力学过程, 但高度依赖精细建模, 导致泛化能力有限. 模仿学习通过专家演示缩小策略差距, 增强了初期策略的稳定性, 但对数据质量和专家依赖性要求较高. 而数据驱动方法则基于实际感知数据构建仿真环境, 在精度与可扩展性之间实现了较好平衡, 近年来受到广泛关注. 但是, 现有数据驱动研究大多聚焦于单一机器鱼, 且主要在静态、平稳的水域中开展, 应用场景相对简单, 尚未能有效应对多机器鱼在复杂动态环境下的协同控制挑战.
综上所述, 针对现有研究方法在水下仿生机器人协同围捕任务中的局限性, 本文提出一种基于多智能体强化学习的策略训练方法, 以提升水下仿生机器人在复杂动态环境中的协同作业和任务执行能力. 首先, 采用数据驱动的建模方式, 构建一个面向水下仿生机器人的高保真强化学习训练环境, 有效解决策略从仿真环境向实际场景迁移困难的问题. 其次, 为增强智能体在动态环境中的协同交互能力, 设计一种结合多头自注意力机制的多智能体强化学习(Multi-agent reinforcement learning with multi-head self-attention, MARL-MHSA)算法, 使智能体能够在每个时刻根据任务需求选择性地关注关键交互信号, 从而实现个体间的高效围捕. 此外, 为满足水下机器人分布式控制需求, 采用集中训练−分布执行(Centralized training with decentralized execution, CTDE)架构, 使智能体在训练阶段利用全局信息进行策略优化, 而在执行阶段则能够独立决策, 实现灵活自主的协同围捕. 最后, 仿真和水池实验验证了所提方法的有效性.
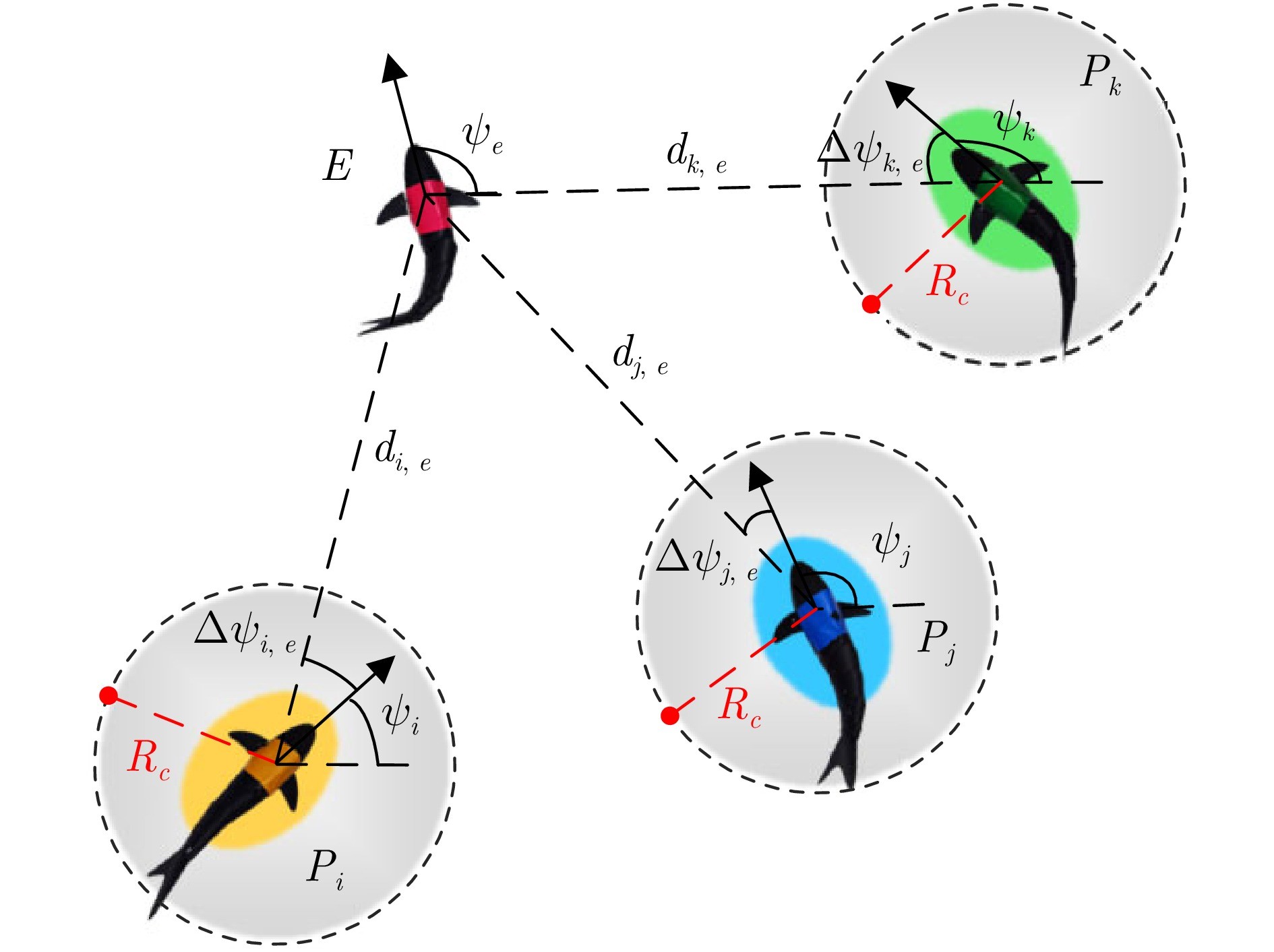
图1 水下仿生机器鲨鱼协同围捕任务示意图
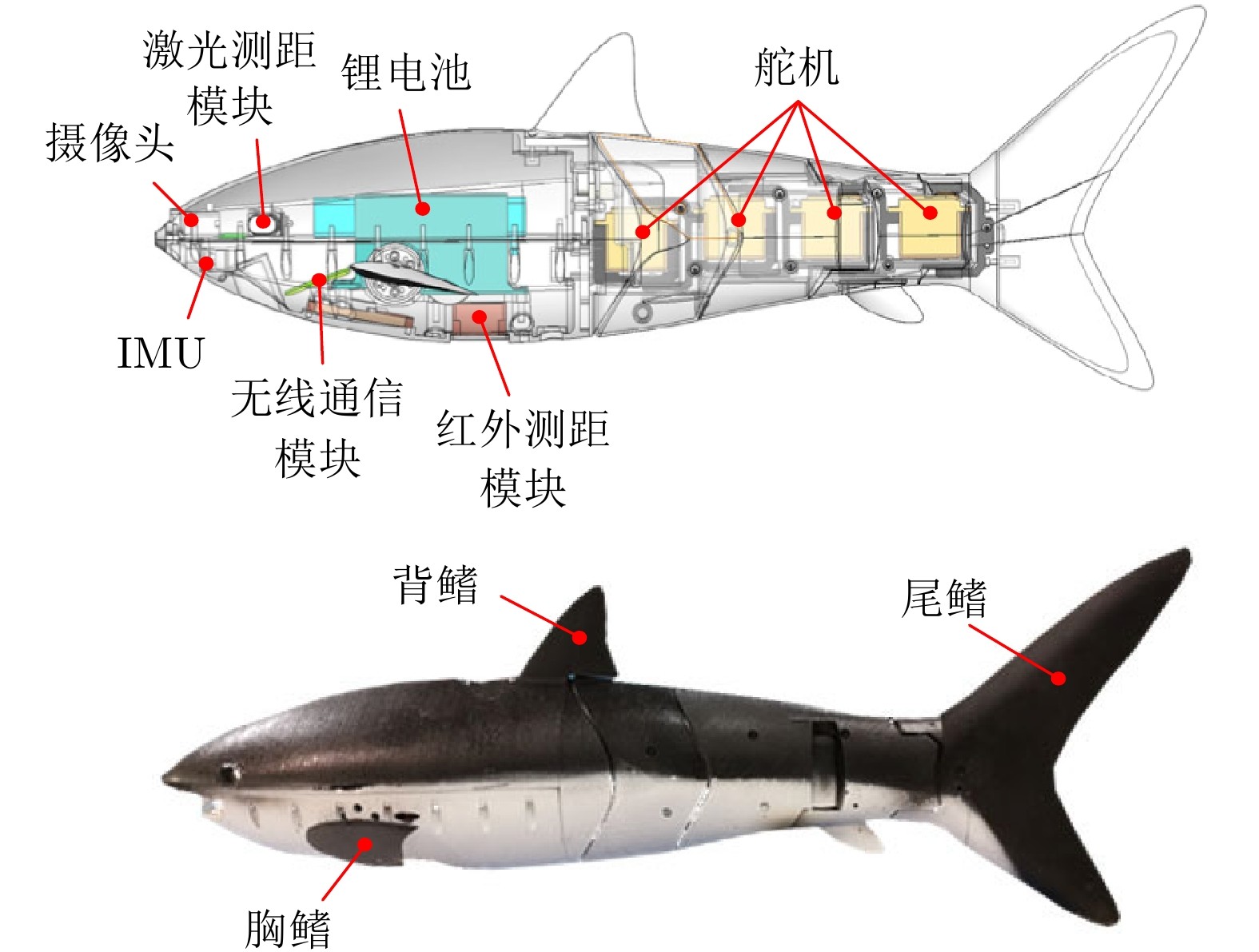
图2 仿生机器鲨鱼设计概念图与原型样机
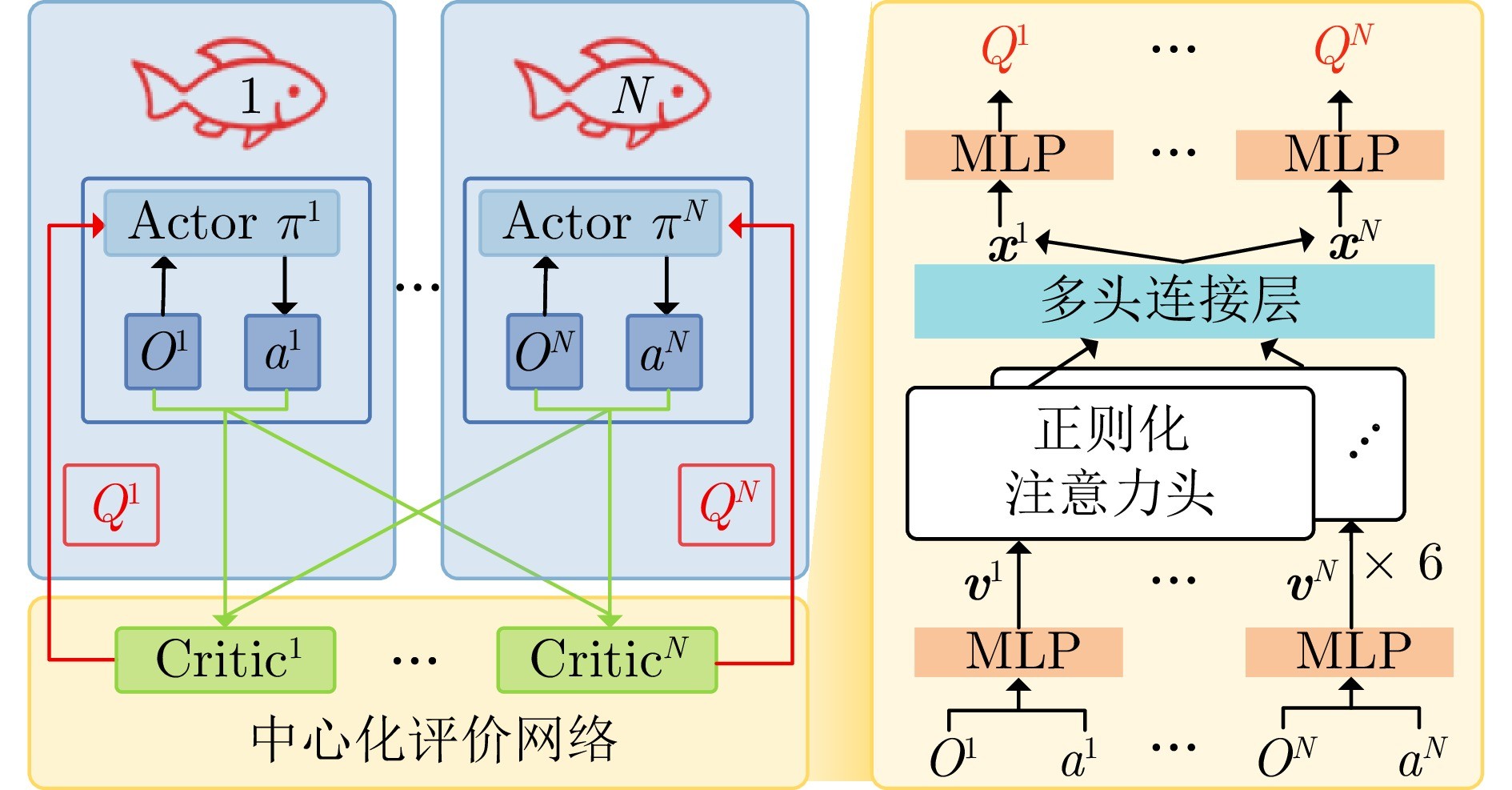
图3 基于多头自注意力机制的多智能体策略训练框架
本文针对水下仿生机器人协同围捕问题, 提出一种基于MARL-MHSA的水下协同围捕决策框架. 首先, 基于数据驱动方法构建水下仿生机器人仿真环境, 以降低策略从仿真训练到实际部署的迁移障碍. 其次, 设计一种基于多头自注意力机制的策略训练框架, 通过引入正则化自注意力函数增强智能体间的信息交互, 从而提高策略训练效率. 最后, 通过仿真和实验证明了所提方法的有效性. 实验结果表明, 该策略在围捕任务中的效率、有效性和泛化性方面均表现出显著优势. 此外, 实际水下环境中的围捕−逃逸实验进一步验证了该方法的可行性, 并证明了其在真实任务中的适应性与灵活性. 总体而言, 本文为水下仿生机器人协同围捕任务提供了一种可靠的解决方案, 在实际应用中具有重要的参考价值, 并为未来相关研究提供了新思路.
在未来的研究中, 计划进一步探索本文方法在开放式无边界场景中的扩展应用, 针对缺乏边界约束所带来的感知稀疏、策略发散与围捕困难等问题, 优化奖励函数设计与协同机制建模, 以提升策略在更复杂环境下的泛化能力与协同表现.
作者简介
冯育凯
中国科学院大学人工智能学院博士研究生. 2021年获得北京化工大学机械设计制造及自动化专业学士学位. 主要研究方向为仿生机器人智能控制和多智能体系统. E-mail: fengyukai2021@ia.ac.cn
吴正兴
中国科学院自动化研究所复杂系统认知与决策重点实验室研究员. 主要研究方向为仿生机器人和智能控制系统. 本文通信作者. E-mail: zhengxing.wu@ia.ac.cn
谭民
中国科学院自动化研究所复杂系统认知与决策重点实验室研究员. 主要研究方向为机器人系统和智能控制系统. E-mail: min.tan@ia.ac.cn
https://blog.sciencenet.cn/blog-3291369-1510847.html
上一篇:大回归模型的自适应学习
下一篇:带有输入时滞的非线性系统基于学习的输出反馈控制
