博文
通信受限的双网络零和博弈分布式在线优化
|
引用本文
廖岚, 于湛, 袁德明, 张保勇, 徐胜元. 通信受限的双网络零和博弈分布式在线优化. 自动化学报, 2026, 52(1): 108−120 doi: 10.16383/j.aas.c250295
Liao Lan, Yu Zhan, Yuan De-Ming, Zhang Bao-Yong, Xu Sheng-Yuan. Distributed online optimization for two-network zero-sum games under communication constraints. Acta Automatica Sinica, 2026, 52(1): 108−120 doi: 10.16383/j.aas.c250295
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c250295
关键词
零和博弈,分布式在线优化,动态纳什均衡遗憾,Bandit反馈,事件触发通信
摘要
研究双网络零和博弈中的分布式优化问题, 其中两个网络代表两个对立的玩家. 每个网络由一组具有时变损失函数的智能体组成, 智能体通过通信和协作来优化己方网络在博弈中的收益. 考虑到现实优化场景中通信资源受限和信息反馈受限两种通信受限情形, 设计基于事件触发通信和两点Bandit反馈的分布式在线优化算法, 并采用动态纳什均衡遗憾评估算法的性能. 在某些假设条件下, 建立相对于总博弈次数为次线性的动态纳什均衡遗憾界, 从而验证了算法的有效性. 此外, 将设计的算法拓展为多周期版本并建立次线性的动态纳什均衡遗憾界. 最后, 通过双线性矩阵博弈的仿真算例进一步验证了所设计的两个算法的性能.
文章导读
近年来, 大数据以及云计算等技术不断发展, 传统的集中式优化方法在解决此类大规模场景中的优化问题时面临诸多挑战. 与此同时, 基于多智能体网络的分布式优化方法逐渐显现出优势[1–3]. 首先, 分布式优化将问题分解为若干个子问题并分配给不同的智能体, 智能体分布式地通信和协作, 从而提高解决问题的效率. 其次, 如果单个智能体发生故障, 其余智能体仍然能够继续工作, 从而保证整个系统的容错能力. 因此, 分布式优化成为优化领域的研究热点, 并引起广泛关注. 相应地, 涌现出一系列优秀的分布式优化算法[4–5], 例如分布式梯度下降算法[6–7]、分布式无投影算法[8–9]、分布式原始−对偶算法[10–11], 以及分布式镜面下降算法[12–13].
分布式优化算法在传感器网络、机器学习, 以及资源能源协调等场景中展现出应用潜力[14–16]. 然而, 通信受限常常影响算法的应用范围. 一方面, 需要考虑通信资源受限问题. 在实际优化场景中, 通信成本和计算资源通常是有限的, 针对该问题, 常用的解决办法是引入事件触发通信机制来合理利用资源. 该机制为智能体设置事件触发协议, 用于决定智能体是否将当前信息传输给邻居, 避免不必要的通信. 近年来, 基于事件触发通信的分布式优化算法设计成为研究热点. Cao 等[17]考虑固定网络拓扑和时变代价函数, 设计离散时间序列下的分布式次梯度下降算法, 并建立次线性的静态遗憾界. 考虑固定网络拓扑和固定代价函数, 杨涛等[18]提出两种基于比例积分的分布式连续时间优化算法, 并证明了算法的收敛性. Xiong 等[19]针对固定网络拓扑和时变代价函数设计离散时间序列下的分布式镜面下降算法, 该算法基于延迟次梯度并取得次线性的静态遗憾界和动态遗憾界.
另一方面, 信息反馈模式受限同样是分布式优化工作中需要解决的问题. 许多分布式优化算法采用全信息反馈机制, 在该机制下, 智能体提交自己的决策后能够收到代价函数的完整信息从而直接计算梯度. 然而, 在实际优化场景中, 梯度信息通常很难甚至无法获取, 传统的全信息反馈不再适用, 而Bandit反馈却显现出优势. 在Bandit反馈机制下, 智能体向外界提交决策后会收到决策附近的一个或多个代价函数值而非完整的代价函数信息, 智能体根据这些函数值进行梯度估计. 近年来, Bandit反馈在实际系统中得到广泛应用, 例如在广告推荐系统中[20]可以根据先前广告的投放效果确定后续广告的投放形式. 此外, 出现了一些基于Bandit反馈的优秀成果. 考虑单点Bandit反馈, Wang等[21]设计了分布式push-sum算法并建立次线性的静态遗憾界. Yuan等[22]研究量化通信下的分布式优化问题并设计基于单点Bandit反馈的算法, 算法同样能取得次线性的静态遗憾界. 考虑延迟反馈, 侯瑞捷等[23]分别设计基于单点Bandit反馈和两点Bandit反馈的分布式复合优化算法, 并建立次线性的动态遗憾界.
在现实生活中, 竞争与对抗无处不在, 很多场景都可看作是非合作博弈. 零和博弈作为非合作博弈的一种, 在政治学、经济学以及社会学等领域得到广泛的应用[24–25]. 在零和博弈中, 玩家的收益之间存在一种零和关系, 如果某个玩家的收益增加, 其他所有玩家的总收益将会等量减少. 在此背景下, 如何优化每个玩家的收益成为研究的重点. 作为零和博弈的核心概念, 纳什均衡为玩家提供了一种相对稳定的策略组合. 在纳什均衡策略下, 玩家无法通过单独改变自己的策略来增加自己的收益. 因此, 在零和博弈中, 玩家可以选择纳什均衡策略来保证自己至少获得均衡收益. 本文研究的双网络零和博弈框架由 Gharesifard 等[26]提出, 其理论体系被不断完善和发展[27–30]. 考虑切换通信拓扑, Lou等[27]设计基于次梯度的异构步长分布式算法, 保证了智能体的策略收敛到纳什均衡. Huang等[28]设计分布式镜面下降算法用于纳什均衡求解. 考虑事件触发通信和全信息反馈, Xiong等[29]设计了分布式投影次梯度算法. Shi等[30]则提出基于顺序策略的分布式增量算法并以异步方式更新策略. 此外, 很多现实应用场景可以看作本文研究的时变双网络零和博弈. 例如在网络攻防中[31], 黑客团队和网络安全专家团队分别代表两个对立玩家, 每个团队相互协作, 根据对手团队在每轮攻防中的行动不断调整自己的策略. 由于网络环境不断变化, 每个团队的攻防成本也随之变化, 因此网络攻防可看作具有时变损失函数的双网络零和博弈.
研究动机. 现有的双网络零和博弈相关工作大多采用固定的损失函数[26–30], 而时变损失函数更符合现实生活中不断变化的复杂优化场景. 此外, 在传统的时间触发机制下, 即使当前状态未发生显著变化, 智能体也需要周期性地与邻居分享自己的信息, 容易引起不必要的通信资源消耗. 近年来, Bandit反馈在分布式优化中逐渐显现出优势. 相较于全信息反馈, Bandit反馈可根据损失函数在决策点附近的损失函数值估计梯度信息, 从而有效解决一些现实优化场景中获取梯度信息成本过高的难题. 受上述讨论启发, 本文研究了基于事件触发通信和Bandit反馈的时变双网络零和博弈.
主要贡献. 1)本文研究带有时变损失函数的双网络零和博弈, 并设计基于在线梯度下降的分布式优化算法, 克服了现有双网络零和博弈工作[26–30]无法应对不断变化的现实优化场景的难题.
2)本文采用事件触发通信, 仅在状态误差超过阈值时触发通信, 能够避免冗余通信和不必要的资源消耗. 此外, 本文采用两点Bandit反馈, 无需损失函数的全部信息即可估计梯度信息, 有效应对了传感器网络等优化场景中梯度信息难以获取的情形.
3)本文以动态基准下的动态纳什均衡遗憾作为性能指标, 构建遗憾意义下的收敛性分析, 并建立关于总博弈次数T为次线性的遗憾界. 此外, 本文通过关于双线性矩阵博弈的仿真算例进一步验证了算法的有效性.
结构安排. 第1节介绍本文所研究的时变双网络零和博弈模型以及收敛性分析要用到的必要假设和技术性引理; 第2节设计基于事件触发通信和两点Bandit反馈的在线算法及其多周期版本用于解决双网络零和博弈中的分布式优化问题, 同时提供算法的一致性结果和收敛性结果; 第3节通过一系列仿真实验进一步验证了所设计算法的性能; 第4节对全文总结并对未来研究方向进行展望.
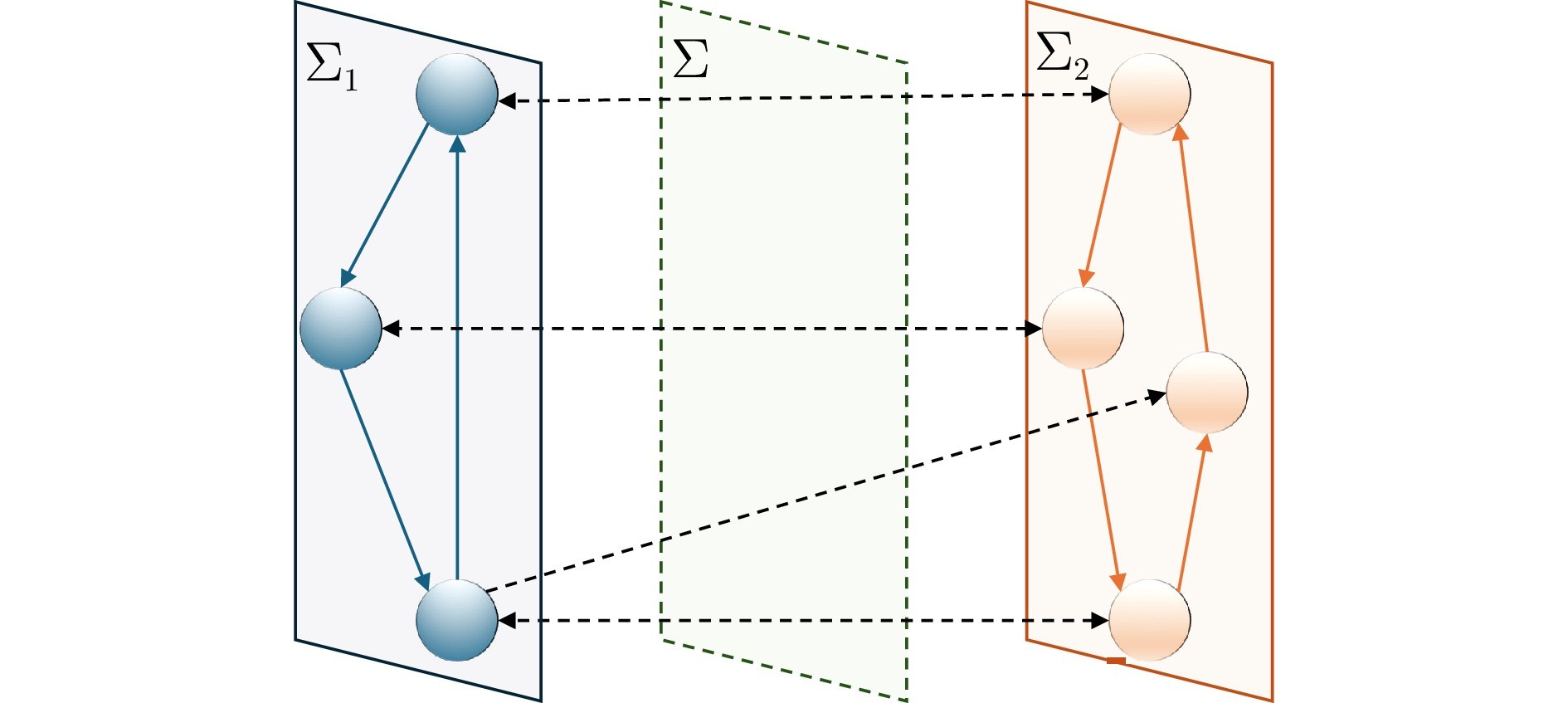
图1 双网络零和博弈模型
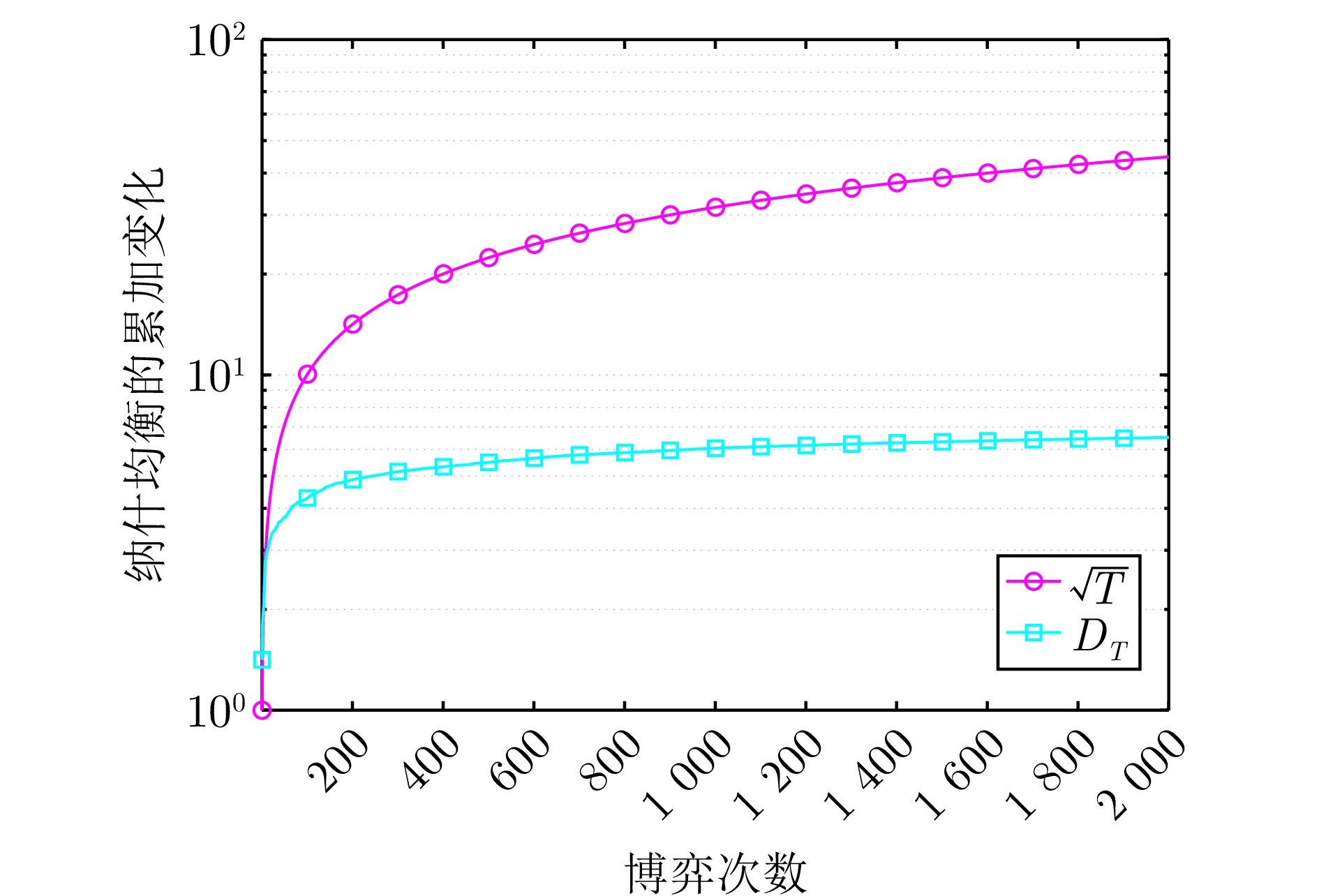
图2 纳什均衡的累加变化
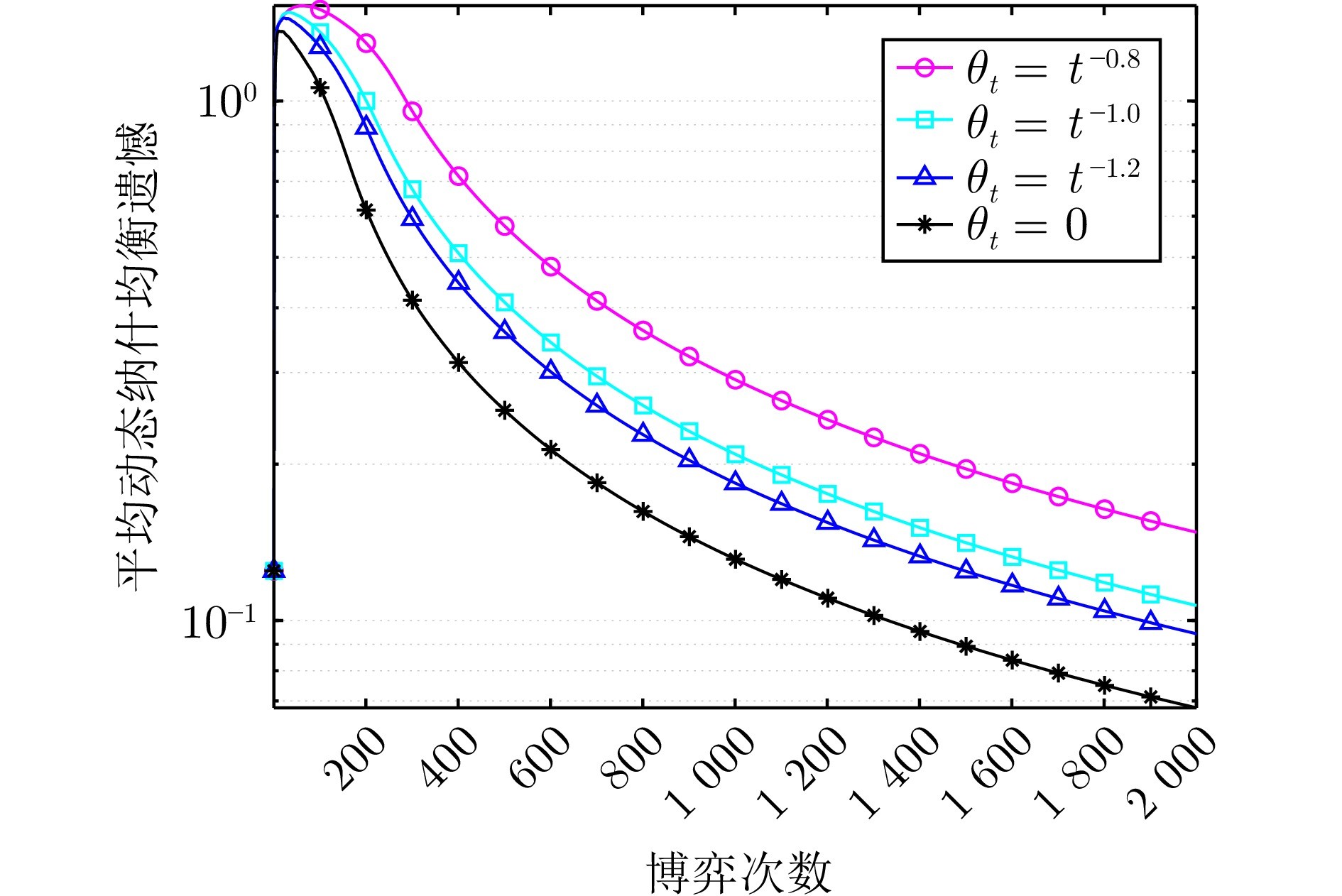
图3 不同触发阈值下算法1的平均动态纳什均衡遗憾
本文对通信受限下的双网络零和博弈展开研究, 两个网络具有不同的时变有向拓扑. 首先考虑通信资源受限, 设计了基于事件触发的通信协议, 智能体仅在通信阈值被触发时将自己的决策信息分享给网络内部的某些智能体, 避免了通信资源的浪费. 然后考虑信息反馈模式受限, 利用两点Bandit反馈估计代价函数的梯度信息, 克服了梯度信息很难或无法获取的难题. 此外, 设计了分布式优化算法用于时变双网络零和博弈, 算法在常规假设下取得了相对于总博弈次数T为次线性的动态纳什均衡遗憾界, 使得每个网络的累加收益在博弈次数平均下逐渐收敛到累加纳什均衡收益. 然后将设计的算法拓展到多周期设置上, 多周期版本的算法同样取得了次线性的动态纳什均衡遗憾. 最后, 基于双线性矩阵博弈设计了一系列仿真实验. 在未来, 围绕双网络零和博弈还有很多可继续开展的工作. 例如, 可以考虑时变非平衡通信网络拓扑. 此外, 研究提出的算法在非凸损失函数下的性能是一个有趣且具有挑战性的课题.
作者简介
廖岚
南京理工大学自动化学院博士研究生. 主要研究方向为分布式优化与控制, 分布式博弈. E-mail: lliao@njust.edu.cn
于湛
香港浸会大学数学系研究员. 主要研究方向为学习理论, 分布式优化. E-mail: mathyuzhan@gmail.com
袁德明
南京理工大学自动化学院教授. 主要研究方向为多智能体分布式优化与控制, 分布式机器学习. 本文通信作者. E-mail: dmyuan1012@gmail.com
张保勇
南京理工大学自动化学院教授. 主要研究方向为多智能体分布式优化与控制, 时滞系统和非线性系统的分析与控制. E-mail: baoyongzhang@njust.edu.cn
徐胜元
南京理工大学自动化学院教授. 主要研究方向为广义系统, 时滞系统和非线性系统的分析与控制. E-mail: syxu@njust.edu.cn
https://blog.sciencenet.cn/blog-3291369-1521812.html
上一篇:面向分段计划负荷的耦合配烧优化模型与硫分约束界调整
下一篇:切换拓扑下混合相对阶异构多智能体系统自适应扰动抑制设计
