博文
主成分分析之R篇
||
R中psych包可以进行主成分分析,其分析的步骤为:
(1) 判断主成分的个数;
(2) 提取主成分;
(3) 获取主成分得分;
(4) 列出主成分方程,解释主成分意义。
【例子】 测定了20株杨树树叶,每个叶子测定了4个变量(叶长x1,2/3处叶宽x2,1/3处叶宽x2,1/2处叶宽x2),测定结果如表4-52所示。试进行本样本的主成分分析。

psych包中的fa.parallel()函数可以判断主成分的个数,其使用格式为:
fa.parallel(x, fa = , n.iter =)
其中,x为待研究的数据集或相关系数矩阵,fa为主成分分析(fa= "pc")或者因子分析(fa = "fa"),n.iter指定随机数据模拟的平行分析的次数。分析代码如下:
1 2 3 4 5 6 7 8 9 | ########## 代码清单 ########## library(psych) # 载入psych包 df<- read.table(file = 'd4.11.1.csv', header = T, sep = ',') # 读入数据 # df.cor<-cor(df[,-1]) # 计算相关矩阵 ####判断主成分的个数 fa.parallel(df[,-1], fa = "pc", n.iter = 100, show.legend = F, main = "Scree plot with parallel analysis") |
运行上述代码,得到结果如下:

上图中,直线与x符号链接的曲线为碎石图,1.0水平线为1准则的特征值,虚线为100次随机数据模拟的平行分析。碎石图画出了特征值与主成分分数的图形。结果表明,选择2个主成分即可保留样本中的大量分信息。
第二步,提取主成分。psych包中的principal( )函数可以根据原始数据或相关系数矩阵做主成分分析,其使用格式为:
principal(x, nfactors =, rotate =, scores =)
其中,x是原始数据或相关系数矩阵,nfactors指定主成分个数,rotate指定旋转的方法(“none”或“varimax”),scores为是否需要计算主成分得分(“T”或”F”)。
分析代码和运行结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | library(psych) pc<-principal(df[,-1], nfactors = 2, score = T, rotate = "varimax") > pc ### 运行结果 #### Principal Components Analysis Call: principal(r = df[, -1], nfactors = 2, rotate = "varimax", scores = T) Standardized loadings (pattern matrix) based upon correlation matrix RC1 RC2 h2 u2 x1 -0.07 1.00 1.00 0.0031 x2 0.94 -0.28 0.97 0.0297 x3 0.99 0.09 0.98 0.0175 x4 0.99 -0.10 0.99 0.0060 RC1 RC2 SS loadings 2.86 1.09 Proportion Var 0.71 0.27 Cumulative Var 0.71 0.99 Proportion Explained 0.72 0.28 Cumulative Proportion 0.72 1.00 Test of the hypothesis that 2 components are sufficient. The degrees of freedom for the null model are 6 and the objective function was 6.8 The degrees of freedom for the model are -1 and the objective function was 0.42 The total number of observations was 20 with MLE Chi Square = 6.6 with prob < NA Fit based upon off diagonal values = 1 |
从上述的结果中可以看出,RC1、RC2栏包含了旋转的成分载荷(component loadings),成分载荷是观观测变量与主成分的相关系数。成分载荷可用于解释主成分的含义。在本例中,第一主成分(RC1)与X2、X3、X4高度相关(相关值 > 0.9),第二主成分(RC2)与X1高度相关(相关值 = 1)。
h2栏是成分公因子方差,是主成分对每个变量的方差解释度。U2栏是成分唯一性,是主成分无法解释变量方差的比例,其值 = 1-h2。比如,本例中,第一主成分对x2变量方差的解释为97%,2.97%不能解释。
SS loadings包含了与主成分相关联的特征值,其含义是与特定主成分相关联的标准化后的方差值。比如,本例中,第一主成分的值为2.86。接下来的proportion var和cumulative var分别为主成分对整个数据集的方差解释度和累积解释度。
本例中,第一主成分解释了4个变量71%的方差,第二主成分解释了27%的方差,累计方差的解释度为99%。
第三步,获取主成分的得分。在第二步的代码基础上,加上下面的代码,即可获得主成分的得分。
round(unclass(pc$weights),2) ## 获取主成分得分的系数。
运行结果如下:
1 2 3 4 5 6 | > round(unclass(pc$weights),2) RC1 RC2 x1 0.09 0.94 x2 0.31 -0.16 x3 0.37 0.20 x4 0.35 0.02 |
根据上述的结果,即可写出第一和第二主成分的方程:
Y1 = 0.09 X1 + 0.31 X2 + 0.37 X3 + 0.35 X4
Y2 = 0.94 X1 - 0. 16 X2 + 0.20 X3 + 0.02 X4
从上述的两个方程中可知,第一主成分中,x2、x3、x4的系数相差不多,x1的系数较小,而x2、x3、x4均是叶宽的变量,因此第一主成分是表示叶宽的综合因子。同理,第二主成分主要由x1决定,是表示叶长的综合因子。总之,叶片之间的差异主要表现为叶宽,其次是叶长。
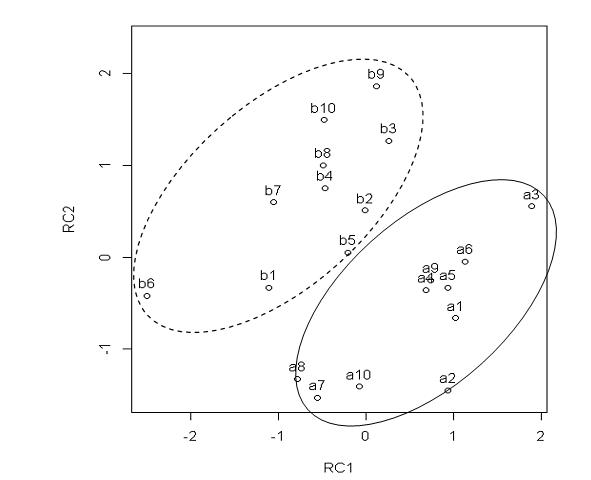
最后,还可画出样本排序图,横坐标为各样本第一主成分的得分,纵坐标为各样本第二主成分的得分,图中可直观地看出样本间的相互关系。全部叶片大致可分为两组:a1 ~ a10样本为一组,b1 ~ b10样本为一组。
https://blog.sciencenet.cn/blog-1114360-736595.html
上一篇:双性状分析之MCMCglmm篇
下一篇:颜色等高图之R篇