博文
华南师范大学:一种在小数据量的表情数据集上基于Transformer的表情检测方法 | Electronics
||
原文出自Electronics 期刊:
He, E.; Chen, Q.; Zhong, Q. SL-Swin: A Transformer-Based Deep Learning Approach for Macro- and Micro-Expression Spotting on Small-Size Expression Datasets. Electronics 2023, 12, 2656. https://doi.org/10.3390/electronics12122656
近年来,微表情分析因在心理健康和公共安全等领域的广泛应用而备受关注。微表情分析包括检测和识别两个任务,微表情检测是在微表情视频中判断是否存在微表情,并定位微表情发生的时间位置。微表情识别是微表情检测之后的任务,是对已经检测出的微表情进行分类 (如“高兴”和“惊讶”等)。与有着较大运动幅度和较长持续时间的宏表情不同,微表情运动幅度小且持续时间短,导致人工分析难度较大,所以开发一个自动化微表情分析系统有助于使微表情分析方法达到实际应用的程度。针对此问题,来自华南师范大学物理与电信工程学院的何尔恒在陈茜茹老师和钟清华老师的指导下,在Electronics 期刊“Recent Innovations in Computing and Electronics”特刊中发表了文章,提出了一种基于Transformer的表情检测方法,其可用于分别检测宏表情和微表情。

图1. 微表情演示动画 (人脸图像来源于数据库,作者已取得使用许可)。
研究过程与结果
首先,为了保持数据的一致性,作者使用OpenCV的DNN Face Detector在视频序列的每一帧中提取出被试的脸部区域。接着使用TV-L1光流法提取出帧与帧之间的水平光流分量和垂直光流分量,并根据这两个分量计算出光学应变。接着对水平光流分量、垂直光流分量和光学应变三者构成的光流特征进行预处理。预处理首先包括根据被试的鼻子区域的平均光流特征消除被试头部运动带来的干扰,同时对被试的眼球区域的光学特征进行遮盖以消除被试眨眼带来的干扰。下一步提取出被试左眼的眼部区域和眉毛区域作为感兴趣区域1,右眼的眼部区域和眉毛区域作为感兴趣区域2,嘴部区域作为感兴趣区域3。最后将三个感兴趣区域的光学特征进行拼接和堆叠,得到经过预处理的光流特征,如图2中的上半部分所示。
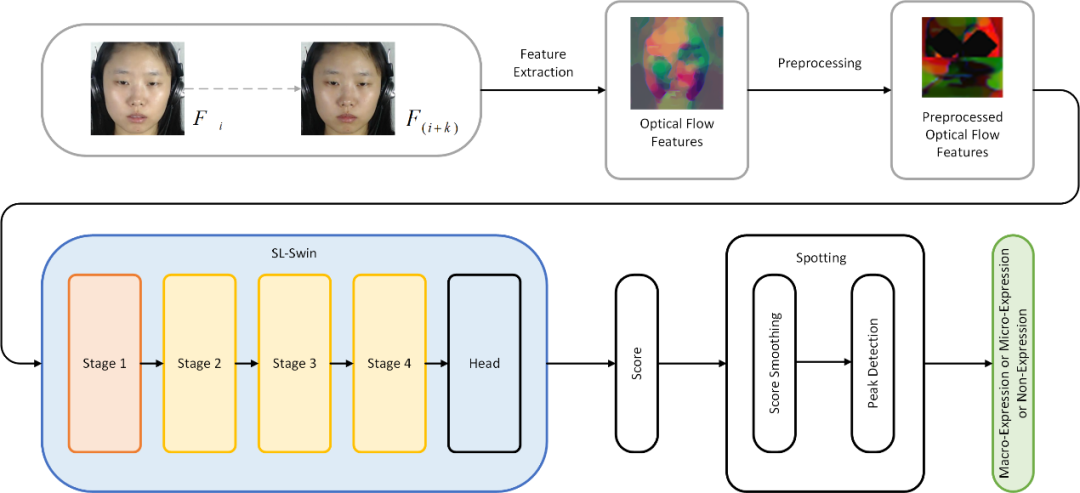
图2. 本研究流程图 (人脸图像来源于数据库,作者已取得使用许可)。
其次,作者将经过预处理的光流特征输入基于Transformer的神经网络SL-Swin进行处理。如图3所示,SL-Swin使用Swin Transformer作为主干网络处理经过预处理的光流特征,并预测表情视频序列中每一帧属于表情区间的置信度。同时,为解决基于Transformer的神经网络在数据量少时表现较差的问题,作者使用了Shifted Patch Tokenization替代主干网络中的嵌入层 (Patch Embedding Layer),使用Locality Self-Attention替代主干网络中的Self-Attention,让网络可以在小数据量的表情数据集上从零开始训练即可达到较为理想的效果,而无需在另外的大数据量的数据集上预训练再在小数据量的表情数据集上微调。最终,如图2下半部分所示,作者通过对神经网络输出的置信度进行平滑处理和峰值检测,检测出视频序列中是否存在表情,并定位出表情发生的时间区间。
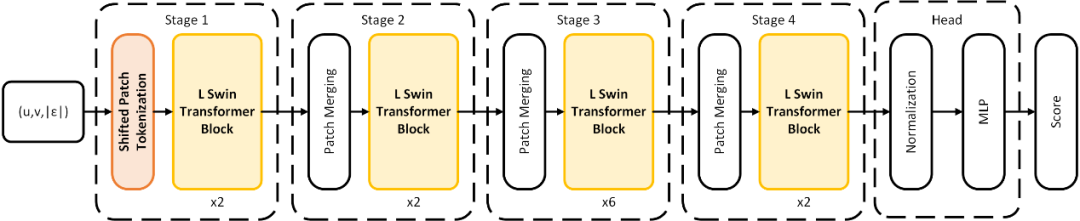
图3. 神经网络SL-Swin的结构示意图。
如图4所示,在面部微表情大挑战2022 (Facial Micro-Expression Grand Challenge 2022, MEGC 2022) 的表情检测任务中,本研究实验得到的综合F1-score为0.1366,优于基准方法 (3D-CNN) 的综合F1-score (0.1351)。比外,如图5所示,在面部微表情大挑战 2021(Facial Micro-Expression Grand Challenge 2021, MEGC 2021) 的表情检测任务中,本研究在CAS(ME)2和SAMM Long Videos数据集上实验得到的综合F1-score分别是0.1824和0.1357,优于基准方法 (3D-CNN) 的综合F1-score (0.1675和0.1084)。
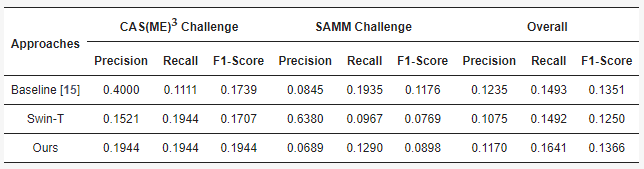
图4. 本研究在MEGC 2022表情检测任务中的实验结果。
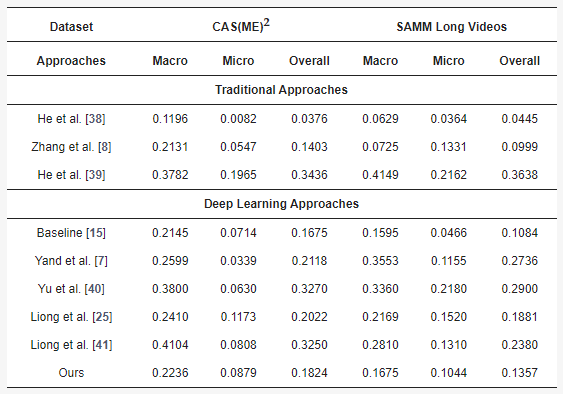
图5. 本研究在MEGC 2021表情检测任务中的实验结果。
研究总结
本研究提出了一种运用深度学习的表情检测方法,其使用基于Transformer的深度神经网络SL-Swin处理视频序列中帧与帧之间的光流特征,预测表情视频序列中每一帧属于表情区间的置信度从而进行表情检测。作者使用Swin Transformer作为SL-Swin的主干网络,并将Shifted Patch Tokenization和Locality Self-Attention应用到主干网络上,让基于Transformer的神经网络可以在小数据量的表情数据集上从零开始训练即可达到较为理想的效果。在MEGC 2022和MEGC 2021的表情检测任务中,本研究的实验结果优于基准方法 (3D-CNN) 的结果。同时,本研究将基于Transformer的深度神经网络运用到表情检测任务中的思想,能够作为其他使用深度学习的方法进行表情检测的参考。
Electronics 期刊介绍
主编:Flavio Canavero, Polytechnic University of Turin, Italy
期刊涵盖的研究领域包括但不限于:电子材料、微电子学、光电子学、工业电子、电力电子、生物电子、微波和无线通信、计算机科学与工程、系统与控制工程、电路和信号处理、半导体器件、人工智能、电动和自动驾驶汽车、量子电子等。期刊致力于快速发表与广泛电子领域相关的最新技术突破以及前沿发展。
2022 Impact Factor:2.9
2022 CiteScore:4.7
Time to First Decision:15.8 Days
Time to Publication:36 Days


https://blog.sciencenet.cn/blog-3516770-1400742.html
上一篇:“小身材、大作用” 对话Agriculture期刊编委——华南农业大学李继宇教授 | MDPI 人物专访
下一篇:Sensors 期刊华中科技大学精选文章 | MDPI 编辑荐读