博文
人工智能研究重心严重偏向工业界
|
人工智能研究重心严重偏向工业界
受到潜在巨大红利的驱动,工业界巨头大局投入AI,其投入资金已经远远超过政府投入,相应地出现大量从大学和研究机构挖人问题。资本追逐利润的本质可能会让AI的研究更多投入到利润高的领域,可能会带来更多不公平甚至社会危害。
几十年来,人工智能(AI)研究在学术界和工业界并存,但随着深度学习(人工智能的数据和计算驱动的子领域)已成为该领域的领先技术,天平正向工业倾斜。工业界的人工智能成功很容易在新闻中看到,但这些头条新闻预示着一个更大、更系统的转变,因为工业界越来越多地主导着现代人工智能研究的三个关键要素:计算能力、大型数据集和高技能研究人员。这种投入的主导地位正在转化为人工智能研究成果:行业在学术出版物、尖端模型和关键基准方面变得越来越有影响力。尽管这些行业投资将使消费者受益,但随之而来的研究主导地位应该成为全球政策制定者的担忧,因为这意味着重要人工智能工具的公共利益替代品可能会变得越来越稀缺。
The growing influence of industry in AI research | Science
工业界投入优势
长期以来,工业界可以更好地访问具有经济价值的大型数据集,因为它们的操作在与大量用户和设备交互时自然会产生数据。例如,在 2020 年,Whats App 用户每天发送大约 100 亿条消息。因此,大多数大型数据中心由行业拥有和运营也就不足为奇了。在本文中,我们展示了行业的主导地位超越了数据,延伸到现代人工智能的其他关键输入:人才和计算能力。
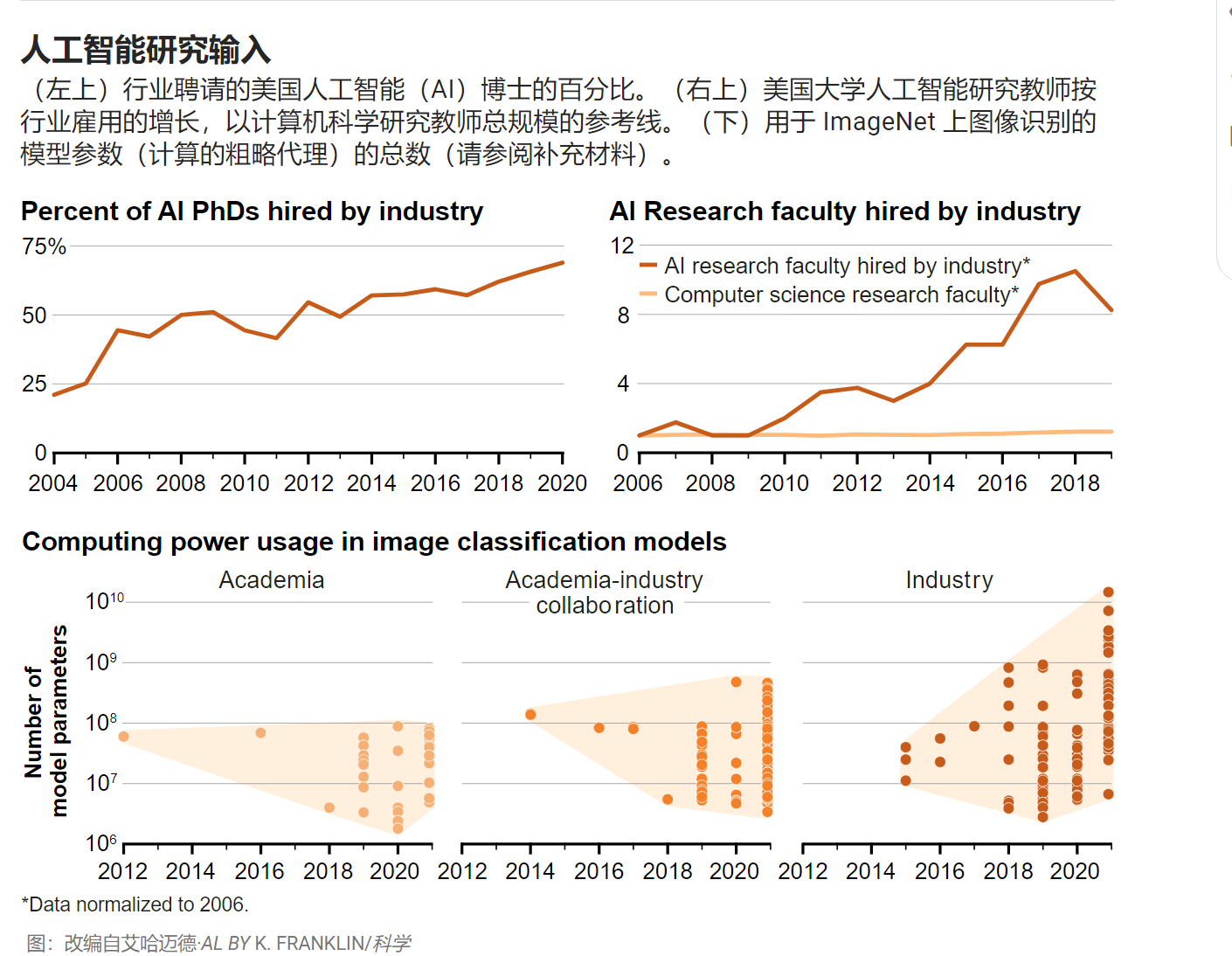
在过去十年中,对人工智能人才的需求增长速度远远快于供应,导致对人工智能人才的竞争加剧。通过两种不同的人才衡量标准,我们看到行业正在赢得这场竞赛。北美大学的数据显示(我们能够在那里获得最佳数据)表明,专门从事人工智能的计算机科学博士毕业生正在以前所未有的数量进入工业界(见第一张图)。2004年,只有21%的人工智能博士进入工业界,但到2020年,几乎有70%的人进入了工业界。相比之下,进入工业界的博士比例已经高于许多科学领域,并且可能很快就会超过所有工程领域的平均水平。专门研究人工智能的计算机科学研究人员也被大学聘用到工业界工作。自2006年以来,这一招聘人数增长了八倍,远远快于计算机科学研究教师的整体增长(见第一张图)。在博士生和教师离开工业界之间,学术机构正在努力留住人才。这种担忧不仅限于美国大学。在英国,华威大学国王十字校区院长Abhinay Muthoo说,“顶级科技公司正在榨干大学人才”。
学术界和工业界使用的计算能力也显示出越来越大的鸿沟。在图像分类中,工业界使用的计算能力比学术界或产学合作使用的计算能力更大,增长速度更快(见第一张图)。在这里,我们用参数的数量来代理模型中使用的计算能力——这既是因为参数的数量是所需计算能力的关键决定因素之一,也是因为深度学习缩放定律文献已经显示了它们之间的密切关系。2021 年,行业模型平均比学术模型大 29 倍,凸显了这两个群体可用的计算能力的巨大差异。这不仅是方法上的差异,而且是学术界可用计算的不足。例如,加拿大国家高级研究计算平台的数据显示,自2013年以来,其平台上对图形处理单元(GPU:人工智能中最常用的芯片)的学术需求增加了25倍,但近年来供应只能满足20%的需求。
行业雇用人才和利用更大计算能力的能力可能是由于支出的差异而出现的。尽管公共和私营部门对人工智能的投资都大幅增加,但行业的投资规模更大,增长更快。我们将行业与公共利益人工智能研究的主要来源进行了比较:政府,它们既资助自己的研究,又是学术资金的主要来源。2021 年,美国非国防政府机构为人工智能拨款 1 5亿美元。同年,欧盟委员会计划花费10亿欧元(12亿美元)。相比之下,2021 年全球工业在人工智能上的支出超过3400亿 美元,远远超过公共投资。例如,2021年,谷歌的母公司Alphabet在其子公司DeepMind上花费了15 亿美元,这只是其人工智能投资的一部分。在欧洲,差距较小,但仍然存在类似情况。AI Watch估计,“欧盟人工智能投资私营和公共部门分别占的67%和33%。相比之下,近几十年来,制药行业的研究资金在私营部门和政府或非营利组织之间大致平均分配。开展人工智能研究所需资金规模的一个例子来自OpenAI,它最初是一个非营利组织,声称“不受产生财务回报的需要的限制”,旨在“造福整个人类”。四年后,OpenAI将其地位更改为“有上限的营利性组织”,并宣布这一变化将使他们能够“迅速增加我们对计算和人才的投资”。
工业在人工智能研究中的主导地位日益增强
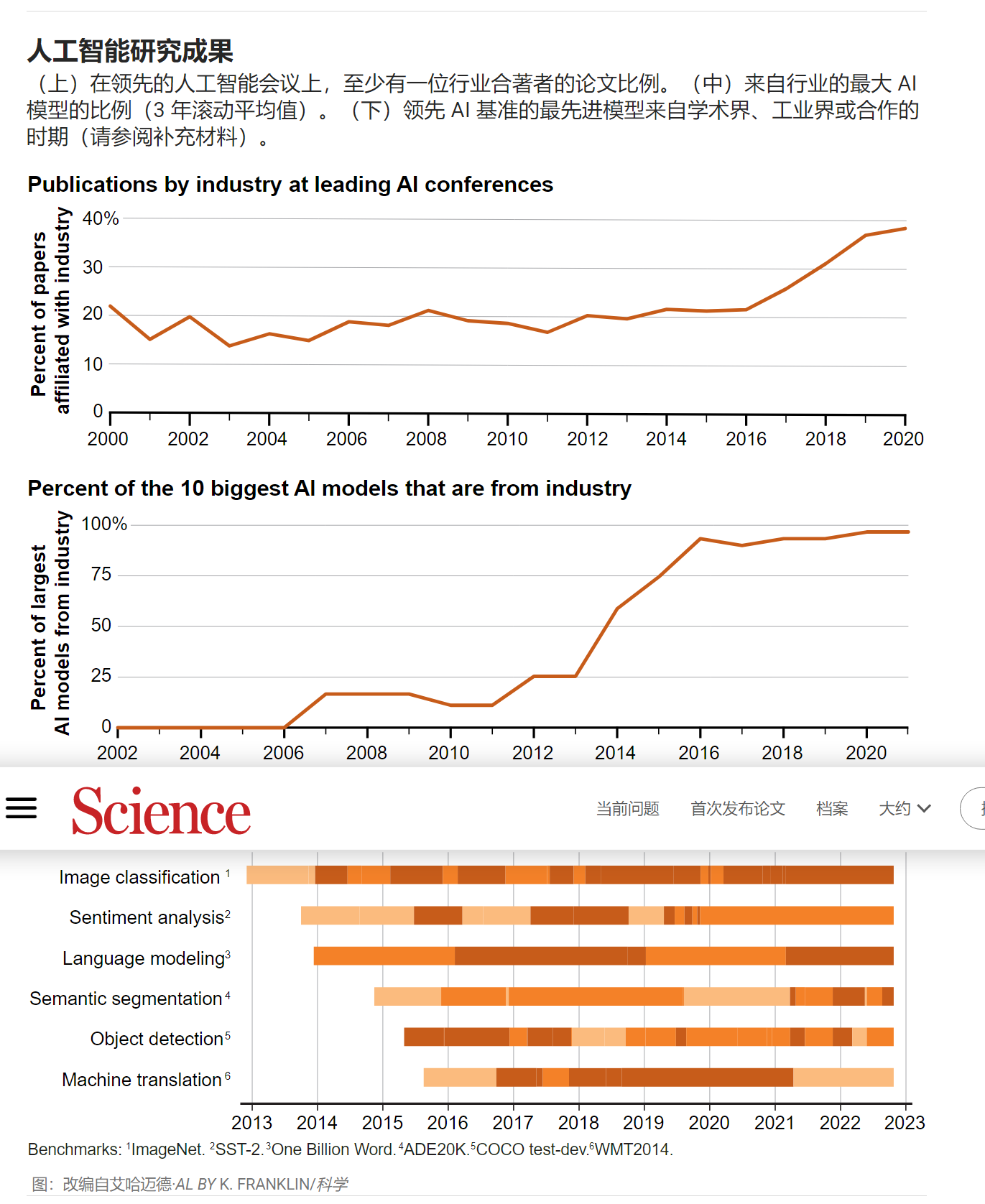
行业在人工智能输入方面的主导地位现在也体现在人工智能成果中越来越突出——特别是在出版、创建最大模型和关键基准方面。含有行业为合作单位的AI研究论文比例从2000年22%增加到2020年的38%(见第二图)。在最大的人工智能模型和基准性能中行业的主导地位更为明显。行业在最大人工智能模型中的份额从 2010年的11 % 上升到2021年的 96%[见第二张图]。使用模型大小作为大型AI模型功能的代理。模型大小也经常用作计算能力的指标(见第一张图)。这种双重用法反映了计算对于预测深度学习系统性能的重要性。
我们调查了学术界、工业界或学术界与工业界的合作何时在人工智能基准上引领了绩效(见第二张图)。在图像识别、情感分析、语言建模、语义分割、对象检测和机器翻译的这六个基准中,以及涵盖机器人和常识推理等领域的另外14个基准时,仅行业或与大学合作在2017年之前拥有62%的领先模型。自 2020 年以来,这一比例已上升到 91%。例如,情感分析可用于理解书面作品的情感基调。直到2017年,学术界在77%的时间内领先这一基准。但自 2020 年以来,仅靠行业或合作主导了 100% 的时间。因此,无论是通过构建最先进的人工智能模型(通过规模或基准性能来衡量)还是通过在领先的研究机构上发表文章来衡量,我们的分析都表明行业在人工智能输出中越来越突出。
政策影响
工业界对人工智能的投资不断增加,有可能通过技术的商业化为社会带来实质性的好处。公司可以创造更好的产品,使消费者受益[例如,机器翻译有利于国际贸易],并且可以简化流程,从而降低公司的成本。工业界对人工智能的投资还产生了对整个社区有价值的工具(如学术界广泛使用的PyTorch和TensorFlow),促进深度学习模型高效训练的硬件[如张量处理单元(TPU)],以及可公开访问的预训练模型(如Meta的开放预训练转换器模型)。
与此同时,人工智能在工业中的集中也令人担忧。行业的商业动机促使他们专注于以利润为导向的话题。这种激励措施通常会产生符合公共利益的结果,但并非总是如此。如果都是来自工业界的尖端模型,就会出现没有公众意识的替代方案的情况。这种可能性引起了类似于对制药业的担忧,制药业的投资不成比例地忽视了低收入国家的需求。最近的实证研究发现,“私营部门的人工智能研究人员倾向于专注于数据饥渴和计算密集型的深度学习方法”,这是以牺牲“涉及其他人工智能方法的研究、考虑人工智能的社会和伦理影响的研究以及在健康等领域的应用”为代价的。这些关于人工智能轨迹以及谁控制它的问题对于关于工作替代和人工智能引发的不平等的辩论也很重要。一些研究人员担心,我们可能处于社会次优的轨道上,更多地关注替代人类劳动而不是增强人类能力。
即使工业界和学术界之间的分歧越来越大,人们也可以想象,该领域可能会陷入类似于其他学科的劳动分工,其中基础研究主要在大学进行,应用研究和开发主要由工业界完成。但在人工智能中,不存在如此明显的鸿沟;工业界使用的相同应用模型通常是那些突破基础研究边界的模型[这种情况类似于Donald E. Stokes所说的“巴斯德象限”,因为巴氏杀菌的应用研究和基础研究之间存在类似的重叠]。例如, transformers是一种深度学习架构,由Google Brain研究人员于2017年开发。这不仅是基础研究向前迈出的重要一步,而且几乎立即应用于工业使用的模型中。这种重叠的一个好处是,这意味着学术工作可以直接使工业界受益(工业界一直支持增加人工智能公共投资的努力)。但这种重叠也有一个缺点:这意味着行业对应用工作的主导地位也赋予了它塑造基础研究方向的力量。鉴于人工智能工具可以广泛应用于整个社会,这种情况将使少数科技公司在社会方向上拥有巨大的权力。对于世界各地的许多人来说,这种担忧进一步加剧,因为这些组织对他们来说是“外国公司”。例如,生命未来研究所认为,“欧洲公司没有开发通用人工智能系统,并且由于与美国和中国参与者相比处于相对劣势,它们不太可能很快开始这样做”。
即使没有行业研究的公共替代方案,人们也可以想象,通过对行业人工智能的审计或外部监控,监管可能是解决方案。例如,2018年,学者Joy Buolamwini和微软员工Timnit Gebru记录了商业人脸识别系统中的性别和种族偏见。建立监控或审计要求(例如欧洲人工智能责任规则中的要求)可以帮助减轻这些类型的危害。然而,如果学者无法获得行业人工智能系统,或者没有资源来开发自己的竞争模型,他们解释行业模型或提供公共利益替代方案的能力将受到限制。这既是因为学者们无法构建尖端性能所需的大型模型,也是因为人工智能系统的一些有用功能似乎是“新兴的”,这意味着系统只有在特别大时才获得这些能力。模型的一些负面特征似乎也随着大小而成比例[例如,人工智能生成的语言中的毒性和刻板印象]。无论哪种情况,无法获得足够资源的学者都无法为这些重要领域做出有意义的贡献。
在世界各地,这种对学术界在人工智能研究中资源劣势的担忧正在得到认可,政策应对措施也开始出现。在美国,国家人工智能研究资源(NAIRR)工作组提议创建公共研究云和公共数据集。在加拿大,国家高级研究计算平台一直为该国的学术界服务,自近十年前推出以来一直超额认购。中国当局最近批准了一个“国家计算能力网络系统”,该系统将使学术界和其他人能够访问数据和计算能力。在欧洲,类似的举措尚未出现,尽管人们清楚地认识到了这种风险。正如法国总统马克龙(Emmanuel Macron)所说,“如果你想管理自己对社会的选择,对文明的选择,你必须能够成为这场人工智能革命的一部分”。对于许多国家来说,这些类型的投资所需的规模可能令人生畏。在这种情况下,政策制定者的关键问题是,他们能否与志同道合的合作者集中足够的资源,以达到创建反映自己优先事项的人工智能系统所需的规模。
计算能力并不是应该提供补救措施的唯一领域。还必须对人工智能的其他关键输入采取措施。构建公共数据集将很重要,但也是一个挑战,因为现代人工智能训练数据集可能是数十亿个文档。特别感兴趣的应该是创建没有直接商业利益的重要数据集。提供资源以留住学术界的顶级人工智能研究人员也很重要。例如,提供工资和研究资金的加拿大研究主席计划(CRCP)已被证明是吸引和留住加拿大顶尖人才的成功手段。
对于致力于这个问题的政策制定者来说,目标不应该是学术界做特定份额的研究。相反,目标应该是确保有足够的能力来帮助审计或监测行业模型,或产生考虑到公共利益设计的替代模型。凭借这些功能,学者们可以继续塑造现代人工智能研究的前沿,并对负责任的人工智能应该是什么样子进行基准测试。没有这些能力,重要的公共利益人工智能工作将被抛在后面。
https://blog.sciencenet.cn/blog-41174-1379034.html
上一篇:大脑如何“构建”外部世界
下一篇:“悄悄退出”的消极怠工现象正打击学术界!
