博文
视觉–语言–动作模型综述: 从前史到前沿
|
引用本文
张慧, 梁姝彤, 李明轩, 田永林, 葛经纬, 于慧, 李灵犀, 王飞跃. 视觉–语言–动作模型综述: 从前史到前沿. 自动化学报, 2025, 51(9): 1922−1950 doi: 10.16383/j.aas.c250417
Zhang Hui, Liang Shu-Tong, Li Ming-Xuan, Tian Yong-Lin, Ge Jing-Wei, Yu Hui, Li Ling-Xi, Wang Fei-Yue. Vision-Language-Action models: From the early foundations to the state-of-the-art. Acta Automatica Sinica, 2025, 51(9): 1922−1950 doi: 10.16383/j.aas.c250417
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c250417
关键词
具身智能,视觉–语言–动作模型,多模态融合,端到端学习,任务泛化
摘要
视觉−语言−动作(VLA)模型作为具身智能发展的核心方向, 旨在构建统一的多模态表示与感知–决策–执行一体化架构, 以突破传统模块化系统在功能割裂、语义对齐不足及泛化能力有限等方面的瓶颈. 本文系统回顾前VLA时代的技术积淀, 梳理模块化、端到端和混合三类主流建模范式, 分析其结构特点、能力优势与面临的关键挑战. 在此基础上, 总结当前代表性VLA模型的体系结构、训练机制、多模态融合策略及应用成效, 并对典型数据集与评测基准进行分类比较. 最后, 结合跨模态协同、知识注入、长时序规划与真实环境泛化等方面, 展望未来VLA模型的发展趋势与研究方向.
文章导读
近年来, 随着人工智能技术的持续演进, 智能体(Agent)技术正由早期面向封闭环境的强化学习(Reinforcement learning)智能体, 逐步演化为具备复杂感知、语言理解与人机交互能力的开放式具身智能体系统[1−2]. 具身智能(Embodied intelligence)强调感知−决策−执行之间的闭环联动, 要求智能体在多模态环境中感知复杂输入、理解语义意图, 并以动作形式完成对物理环境的反馈交互. 这一新范式正在挑战现有人工智能系统的基本架构, 促使研究者重新思考多模态协同与智能决策之间的协作机制. 传统具身智能系统多采用模块化设计范式: 视觉模块用于提取图像或点云中的几何信息, 语言模块独立解析自然语言指令, 动作模块基于状态空间进行规划. 然而, 该分而治之的结构暴露出显著的“感知−决策割裂”问题[3−4]: 感知模块难以理解任务目标, 决策模块缺乏语义约束, 导致系统执行路径冗余、行为不稳定、泛化能力差. 此外, 跨模态语义对齐能力的缺失也是制约性能提升的根本瓶颈. 传统方法常依赖显式中间表示(如目标框、状态图或语言标签)实现模态对接, 带来严重的信息损耗与语义断层[5], 难以支撑复杂开放环境中的端到端任务执行. 多模态基础模型(Multimodal foundation models)的兴起, 为攻克这一挑战提供了新的解决方案. 以CLIP为代表的视觉语言预训练模型通过图文对比学习构建统一语义空间, 实现图像与文本的自然对齐[6]; 以GPT为代表的大语言模型(Large language models, LLMs)展现出出色的语义建模与推理能力, 支撑指令驱动、上下文感知的任务执行[7]. 这些通用基础模型的融合, 推动具身智能系统从割裂式结构向语义一致性驱动的端到端闭环系统演进, 为更自然、高效的任务执行提供技术基础.
随着多模态交互与具身智能研究的持续深化, 视觉−语言−动作(Vision-Language-Action, VLA)模型应运而生. VLA模型旨在构建统一的多模态表示机制与感知−决策−执行一体化执行路径[8−9], 通过Transformer等结构将语言指令直接映射到感知特征与动作控制中, 突破传统模块拼接式架构的限制. VLA系统通常包含三个核心组成部分: 多模态输入编码器、语义推理模块与动作生成器, 可在训练阶段通过图文−动作三元组联合优化, 在推理阶段实现语义一致的端到端控制路径[10]. VLA模型的发展得益于多项关键技术的协同推动. 一方面, 多模态预训练、指令微调(Instruction tuning)与多任务学习机制显著提升了模型的泛化能力与迁移性能; 另一方面, 世界模型(World model)与预测式编码器的引入增强了模型的环境建模与未来状态推理能力[11−12], 进一步提升了系统在复杂任务中的前瞻性与可解释性. 近年来, Transformer 架构与强化学习框架的融合也为高效训练与动态决策提供了有力支撑, 推动VLA模型逐步演化为“可看、可听、可动” 的新一代具身智能体核心框架. 在实际应用中, VLA模型在多个领域均展现出广泛前景与显著优势. 例如, 在家庭服务场景中, VLA系统能够理解自然语言指令(如“把杯子放进洗碗机”)并根据视觉输入生成动作路径; 在工业制造中, VLA可部署协作机器人完成复杂装配与检测任务, 提升生产柔性与效率; 在教育、医疗、虚拟现实等人机交互场景中, VLA可作为智能助理提供动作引导、语言交互等服务, 极大拓展智能体的服务边界.
近年来, 随着多模态大模型能力的持续突破, 视觉−语言−动作一体化建模逐渐成为推动具身智能发展的关键方向之一. 围绕VLA的研究已陆续出现多篇综述, 但各自的关注点存在差异. Ma等[13]对VLA在具身智能领域的发展进行综述, 从整体架构出发, 重点讨论高层任务规划与低层控制策略, 并对相关数据集、仿真平台及评测方法进行总结, 但随着技术快速演进, 该综述在最新方法和评估体系方面已显局限. Zhong等[14]专注于动作表示问题, 从“动作Token”出发, 将VLA的动作加以系统划分, 并探讨其发展趋势, 这一思路虽具创新性, 但在架构演化和跨任务应用方面覆盖仍有限. Din等[15]主要面向机器人操作场景, 强调大规模模型与数据资源的重要性, 整理相关研究成果并评述主流仿真平台, 但其讨论范围仍局限于操作任务. Sapkota等[16]从应用与挑战视角出发, 对自动驾驶、医疗、农业等领域的VLA研究进行多角度分析, 强调其在不同行业的应用广度及面临的伦理与部署风险, 但对前VLA时代的技术积累和架构演进缺乏系统回溯. 与上述工作不同的是, 本文首先指出前VLA时代的研究虽然在模块化架构、策略学习和多模态耦合等方面奠定基础, 但普遍存在感知–决策割裂、跨模态融合不足以及应用范围受限等问题. 然后, 本文系统梳理VLA在建模范式、数据与训练方法、评估体系和应用场景四个核心维度的最新进展, 贯通历史脉络与前沿趋势, 为未来研究提供更加全面的演进图景与参考框架.
值得注意的是, VLA模型的发展路径与平行智能(Parallel intelligence)理论[17]在理念上高度契合. 平行智能提出“人工系统–计算实验–平行执行” 的架构, 通过人工系统支撑现实行动, 并以虚拟实验不断校正和优化决策, 从而实现虚拟与现实的深度耦合[18−19]. 类似地, VLA依托仿真环境或数字孪生开展预训练, 在真实物理场景中结合多模态感知与语言推理完成动作控制, 并通过环境反馈不断修正策略, 逐渐形成高效稳健的执行链条. 可以说, VLA是平行智能思想在具身智能领域的一种具体化落地, 它不仅继承了前 VLA时代的技术积累, 也在多模态大模型与世界模型的推动下, 为复杂开放环境中的智能决策开辟了新的范式. 总体而言, VLA的提出并非孤立演进的结果, 而是多模态基础模型、具身智能需求与平行智能思想共同演进的结果. 当前研究虽已取得重要进展, 但如何实现更紧密的感知–语义–决策的深度融合以及如何在动态复杂任务中保持泛化与稳健性, 仍是未来亟须突破的核心问题.
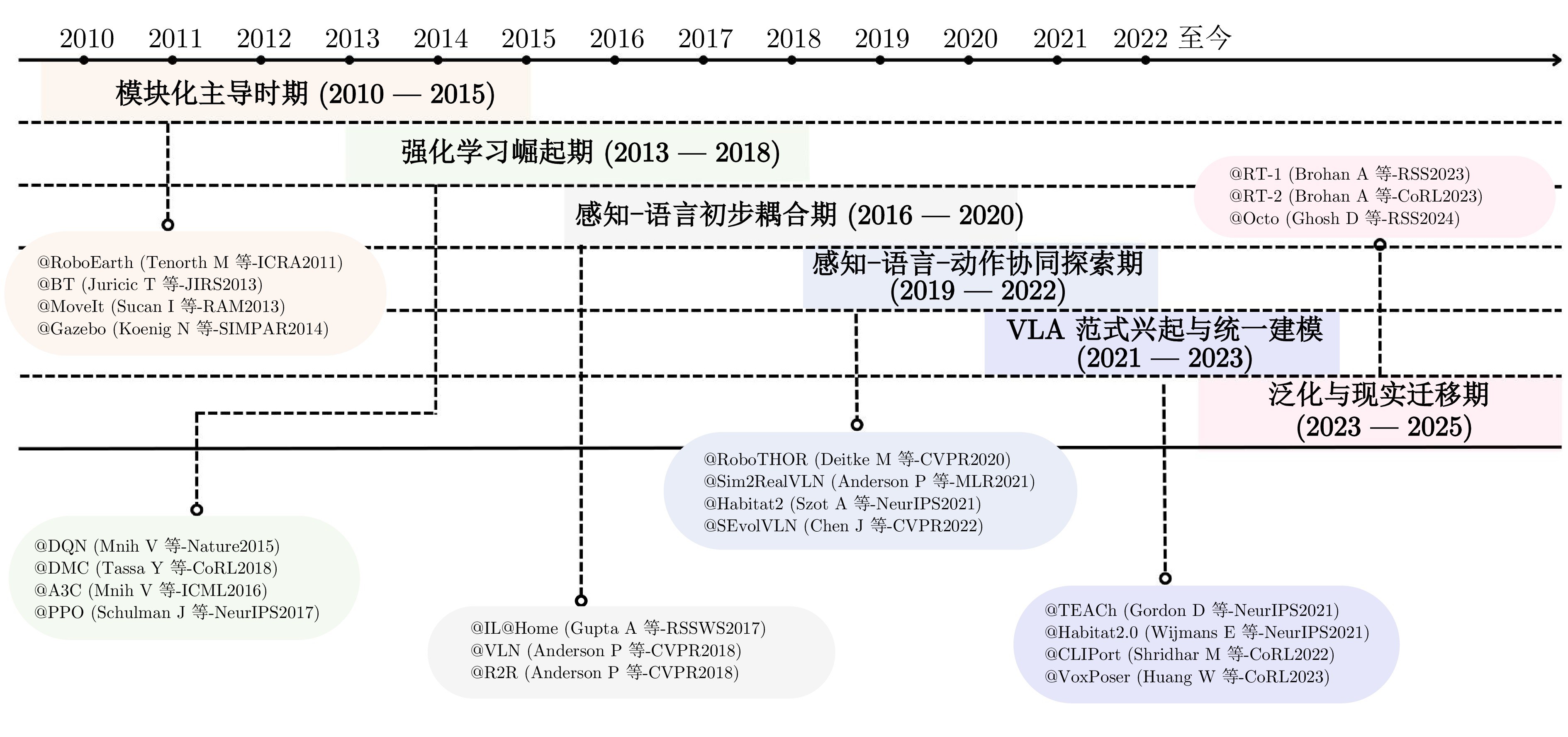
图1 具身智能的技术演进路径示意图
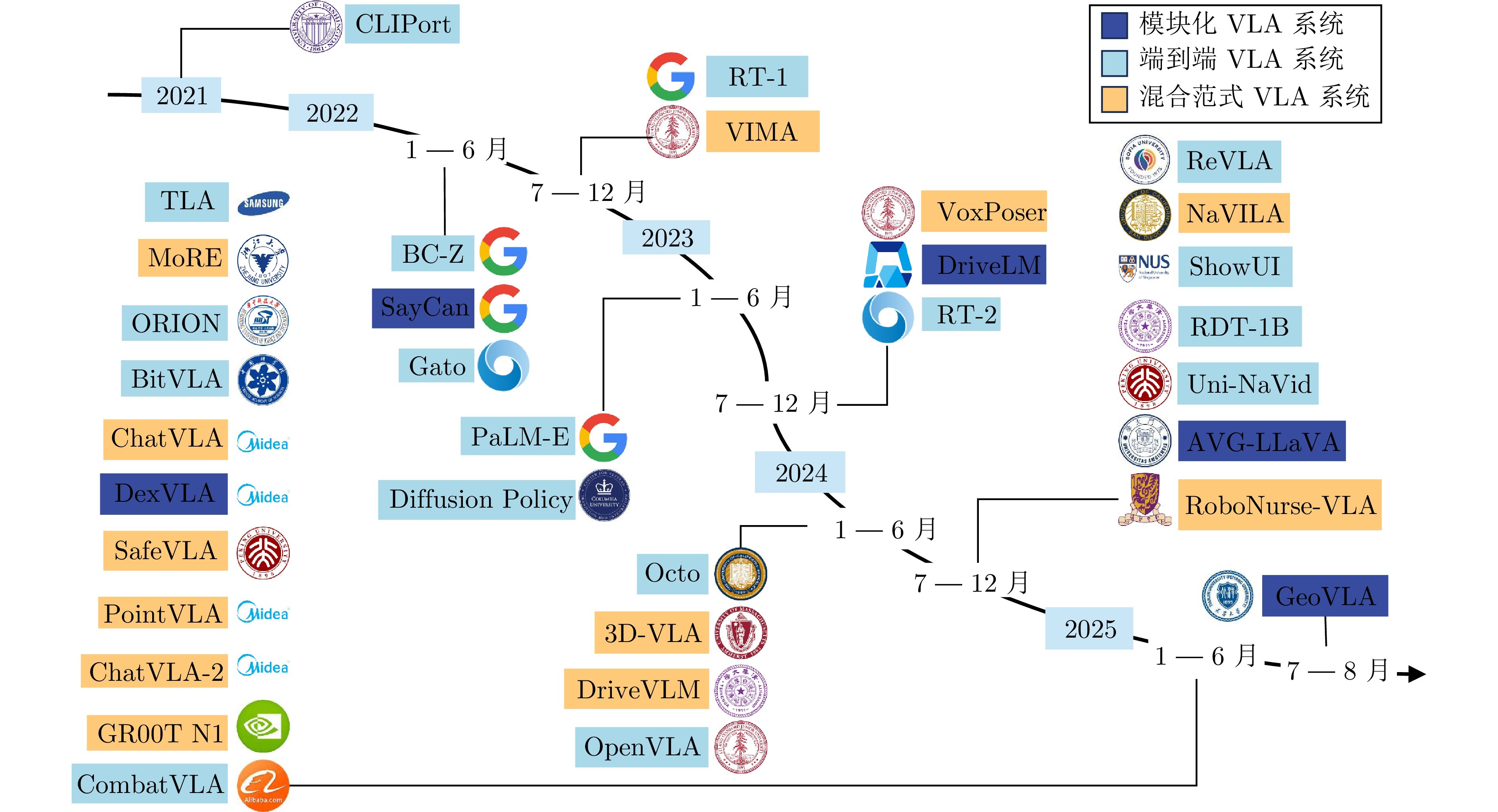
图2 VLA发展历程时间线

图3 VLA架构分类: 模块化VLA、端到端VLA和混合VLA
视觉−语言−动作(VLA)模型作为具身智能与机器人控制领域的重要突破, 正以前所未有的方式整合多模态感知、语义理解与物理动作生成能力, 为构建通用机器人策略探索出新的技术路径. 本文系统梳理VLA模型的发展脉络与关键技术体系: 从“前VLA时代”的技术积淀出发, 到VLA驱动下的具身智能一体化建模方法, 分析主流模型架构的分类与特点; 总结数据构建与训练方法的核心进展; 介绍评估体系与基准测试; 并探讨VLA模型在广泛应用场景中的落地挑战. VLA模型的引入显著提升了具身智能在多模态感知精度、语义理解深度、动态规划能力及数据利用效率等方面的表现, 极大扩展了其在家庭服务、工业协作、医疗辅助等领域的应用前景. 然而, 跨模态对齐、实时决策以及长时序规划等挑战依然是当前研究的主要难点, 亟待进一步探索与突破. 在可预见的未来, 随着基础模型的持续迭代与硬件技术的不断进步, 基于VLA范式的具身智能系统将在物理世界中扮演愈加重要的角色, 成为连接数字智能与现实场景之间的核心桥梁.
作者简介
张慧
北京交通大学副教授. 主要研究方向为多智能体协同, 多模态感知, 具身智能和平行智能. E-mail: huizhang1@bjtu.edu.cn
梁姝彤
北京交通大学硕士研究生. 主要研究方向为多智能体协同和具身智能. E-mail: 24140062@bjtu.edu.cn
李明轩
北京交通大学硕士研究生. 主要研究方向为多智能体协同和具身智能. E-mail: 25125384@bjtu.edu.cn
田永林
中国科学院自动化研究所助理研究员. 主要研究方向为平行智能, 自动驾驶和智能交通系统. E-mail: yonglin.tian@ia.ac.cn
葛经纬
欧布达大学研究员. 主要研究方向为自动驾驶测试和场景生成. E-mail: jingwei.ge@uni-obuda.hu
于慧
格拉斯哥大学教授. 主要研究方向为视觉与认知计算, 社交视觉, 社交机器人以及机器学习. E-mail: Hui.Yu@glasgow.ac.uk
李灵犀
普渡大学教授. 主要研究方向为复杂系统的建模与控制优化, 智能交通系统, 平行智能以及人机交互. E-mail: lingxili@purdue.edu
王飞跃
中国科学院自动化研究所研究员. 主要研究方向为智能系统和复杂系统的建模、分析与控制. 本文通信作者. E-mail: feiyue.wang@ia.ac.cn
https://blog.sciencenet.cn/blog-3291369-1506081.html
上一篇:面向智能生化实验室的机器人感知、规划与控制技术
下一篇:城市固废焚烧过程神经网络控制研究综述
