博文
基于大语言模型的中文实体链接实证研究
|
引用本文
徐正斐, 辛欣. 基于大语言模型的中文实体链接实证研究. 自动化学报, 2025, 51(2): 327−342 doi: 10.16383/j.aas.c240069
Xu Zheng-Fei, Xin Xin. An empirical study of Chinese entity linking based on large language model. Acta Automatica Sinica, 2025, 51(2): 327−342 doi: 10.16383/j.aas.c240069
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c240069
关键词
实体链接,大语言模型,知识增强,适配器微调,提示学习,语境学习
摘要
近年来, 大语言模型(Large language model, LLM)在自然语言处理中取得重大进展. 在模型足够大时, 大语言模型涌现出传统的预训练语言模型(Pre-trained language model, PLM)不具备的推理能力. 为了探究如何将大语言模型的涌现能力应用于中文实体链接任务, 适配了以下四种方法: 知识增强、适配器微调、提示学习和语境学习(In-context learning, ICL). 在Hansel和CLEEK数据集上的实证研究表明, 基于Qwen-7B/ChatGLM3-6B的监督学习方法超过基于小模型的方法, 在Hansel-FS数据集上提升3.9% ~ 11.8%, 在Hansel-ZS数据集上提升0.7% ~ 4.1%, 在CLEEK数据集上提升0.6% ~ 3.7%. 而当模型参数量达到720亿时, Qwen-72B的无监督方法实现与监督微调Qwen-7B相近的结果(−2.4% ~ +1.4%). 此外, 大语言模型Qwen在长尾实体场景下有明显的优势(11.8%), 且随着参数量的增加, 优势会更加明显(13.2%). 对错误案例进行分析(以下简称错误分析)发现, 实体粒度和实体类别相关错误占比较高, 分别为36%和25%. 这表明在实体链接任务中, 准确划分实体边界以及正确判断实体类别是提高系统性能的关键.
文章导读
在信息处理领域, 实体链接是将文本中的指称(Mention)与知识库中相应实体进行关联的任务, 主要应用于知识图谱扩充[1]、信息检索[2]、问答系统[3]等下游任务. 随着Qwen[4]、ChatGLM (Chat general language model)[5]、GPT (Generative pre-trained transformer)[6]等大语言模型的崛起, 实体链接有了更广泛的应用场景. 首先, 大语言模型有概率产生“幻觉”问题[7], 这限制了其可靠性; 其次, 大语言模型通过大规模预训练将知识隐式地存储于模型参数中[8], 这限制了知识更新和在特定领域的应用. Kandpal等[9]的研究表明大语言模型难以通过持续训练纳入新的知识. 因此将大语言模型与外部知识库相结合, 成为缓解大语言模型的“幻觉”问题、扩展事实知识的有效方法[9]. 实体链接作为连接自然语言和结构化知识的桥梁, 可以为大语言模型提供上下文相关的事实知识, 将大语言模型与知识库相关联, 以提高大语言模型的能力[10].
当前的神经实体链接方法主要基于预训练 + 微调的范式. 为平衡效率和准确率, 目前的实体链接系统主要包含两个阶段: 候选实体生成和实体消歧, 本文主要关注实体消歧阶段. 实体消歧方法主要基于实体和指称的表示学习[11−13]. 随着预训练语言模型[14]的发展, Yamada等[15]通过构建预训练任务, 在预训练阶段学习实体和指称的表示向量. Wu等[16]通过微调双编码器(Dual encoder, DE), 将实体和指称映射到相同的向量空间, 并通过向量检索生成候选实体, 在消歧阶段, 通过交叉注意力编码器(Cross-attention encoder, CA)构建消歧向量实现消歧. 上述基于预训练 + 微调的实体消歧模型, 通过深度表示学习来构建指称和文本的语义向量, 利用这些向量的交互进行消歧.
相比于小规模预训练语言模型, 具备数十亿乃至上千亿参数的大语言模型涌现出一定的推理能力, 如逐步推理(Multi-step reasoning)[17]、指令遵循(Instruction following)[18]和语境学习(In-context learning, ICL)[6], 而人们通常认为小规模预训练语言模型缺少推理能力[17, 19]. 得益于这些涌现能力, 出现了很多新的模型交互方式. 例如通过自然语言形式的提问就能获得特定任务的答案. 以实体链接任务为例, 图1展示了大语言模型的三种交互方式. 这些示例展现出大语言模型具有推理能力和内部知识, 这启发了将这些涌现能力应用在实体链接任务中, 以提高模型性能.
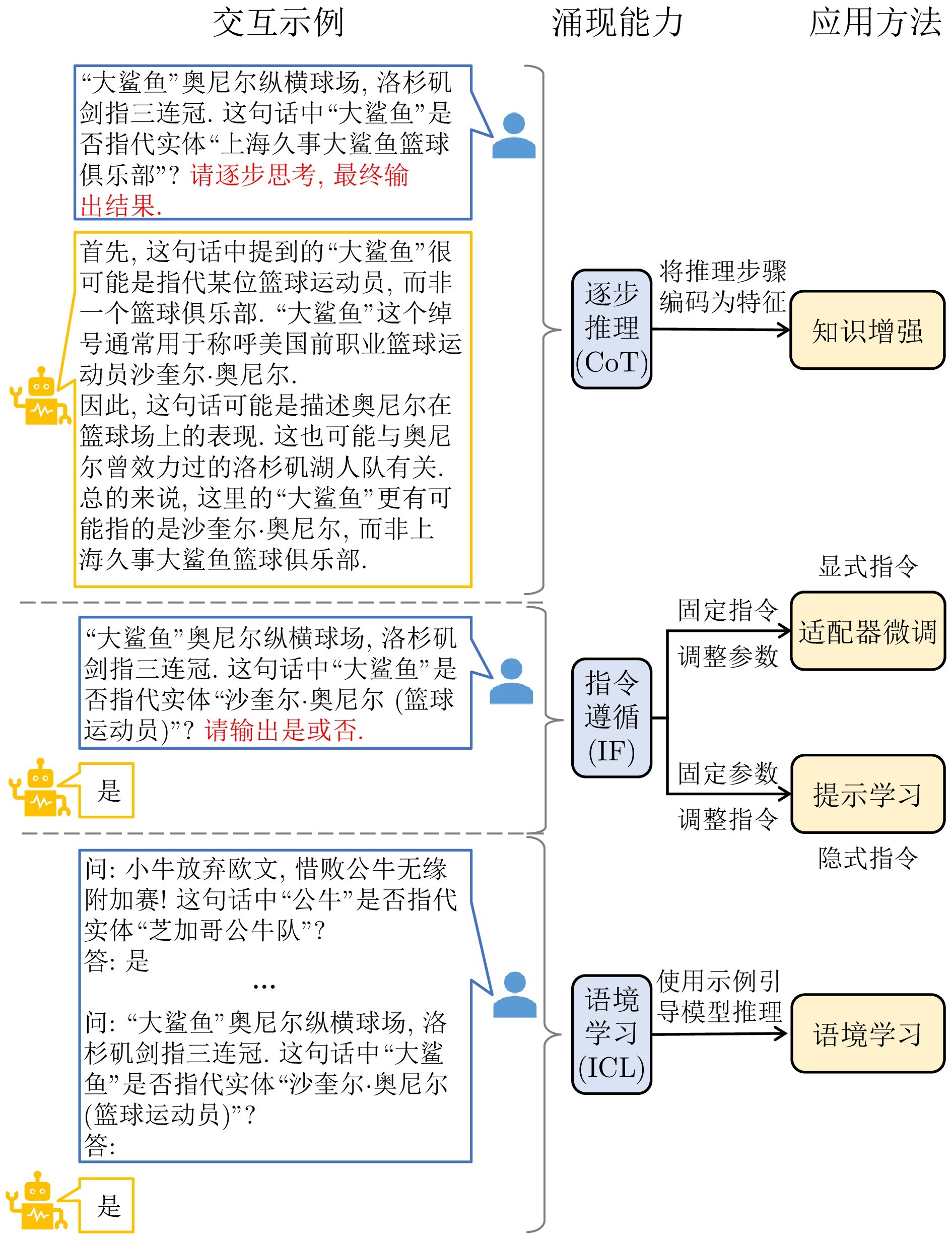
图 1 研究动机
本文基于不同的涌现能力实例化了大语言模型的四种应用方法, 如图1所示. 1)知识增强(逐步推理): 利用思维链提示引导大语言模型生成推理步骤作为小模型的输入特征; 2)适配器微调(显式指令遵循): 通过固定指令并微调模型参数来实现指令遵循; 3)提示学习(隐式指令遵循): 通过固定模型参数并微调指令表示来实现指令遵循; 4)语境学习: 检索相关演示示例, 构造小样本提示输入, 引导大模型进行语境学习, 从而实现推理.
本文主要研究大语言模型在中文实体链接任务中的改进效果. 构建了“检索−重排序”的两阶段中文实体链接基线系统, 在候选生成阶段使用双编码器方法检索实体; 在实体消歧阶段实现了知识增强、适配器微调、提示学习和语境学习四种应用方法. 在中文实体链接测试基准Hansel[20]和CLEEK[21]上的评估表明, 基于BERT等预训练模型的方法[14, 16]存在“过拟合”和“长尾实体”问题; 而基于Qwen-7B和ChatGLM3-6B的知识增强、适配器微调和提示学习方法具有明显优于基线的效果; 基于语境学习和思维链推理的无监督方法在更大规模的大语言模型Qwen-72B上取得与小规模Qwen-7B监督微调相近的结果. 随着参数规模的增大, Qwen模型在长尾实体上的优势进一步凸显. 此外, 本文对实验结果的错误案例进行了分析(以下简称错误分析), 统计了实体粒度、实体类别、全局错误、局部错误、时间错误和地点错误六种主要错误类型的比例.
综上所述, 本文的主要贡献如下:
1) 实例化四种大语言模型应用方法, 分析了不同大语言模型在不同方法下的效果, 其中, Qwen-7B和ChatGLM3-6B的监督学习方法在Hansel-ZS、Hansel-FS和CLEEK上均有提升, 准确率提升分别为3.9% ~ 11.8%、0.7% ~ 4.1%、0.6% ~ 3.7%; 无监督方法在Qwen-72B上取得了与监督微调Qwen-7B模型相近的结果.
2) 实验发现, 大模型Qwen相比小模型BERT在长尾实体场景下有明显的优势, 且随着参数量的增加, 优势会更加明显. 此外, Qwen大模型的参数高效微调方法相比BERT小模型微调和全参数微调更不容易出现“过拟合”问题.
3) 错误分析表明, 大语言模型在涉及粒度和类别的问题上存在较高的错误占比, 分别为36%和25%. 最后通过定性分析给出了改进建议.
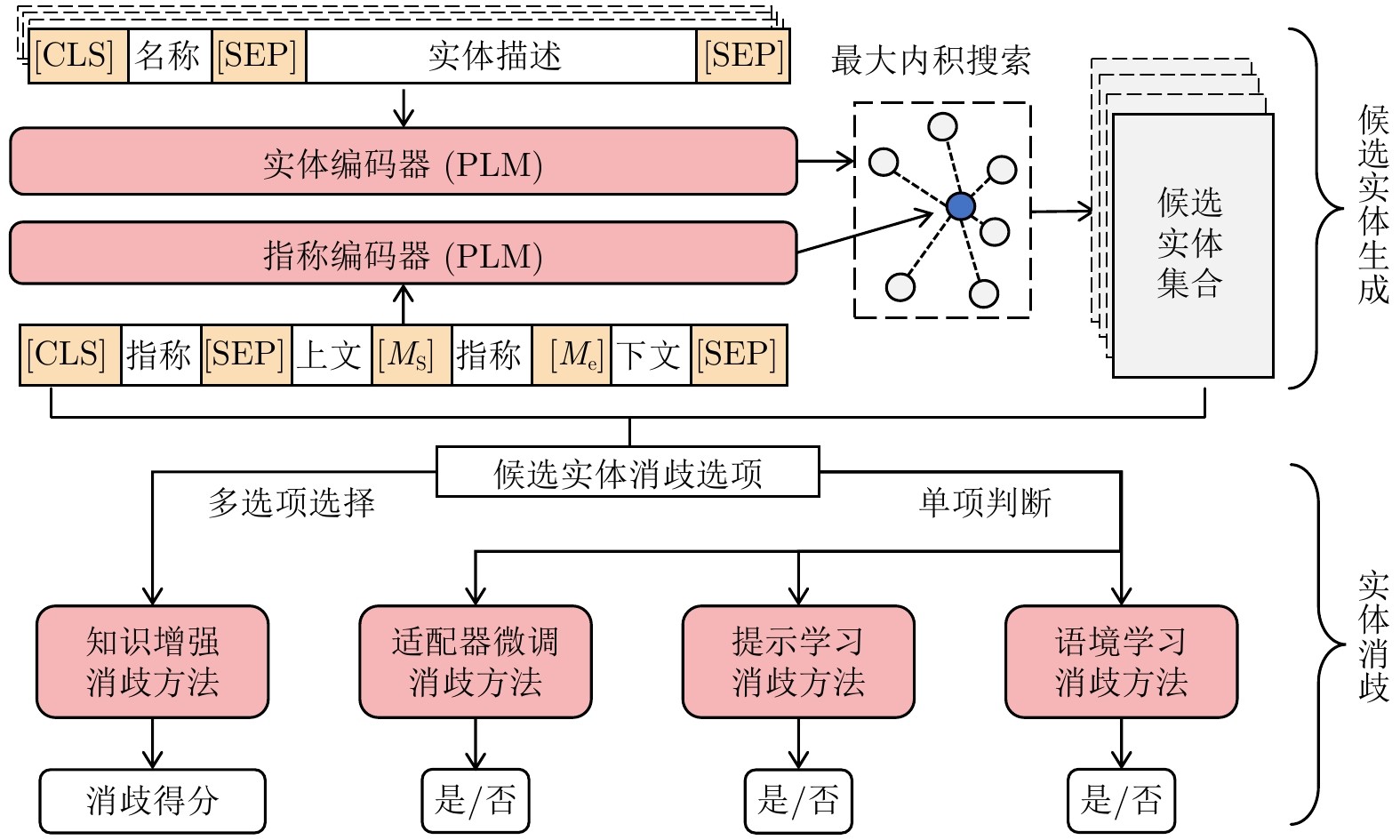
图 2 实体链接系统的整体架构

图 3 实体消歧方法中的提示语示例
本文研究了大语言模型的涌现能力对中文实体链接系统的影响, 主要分析了 Qwen-7B和ChatGLM3-6B模型的四种方法(知识增强、适配器微调、提示学习和语境学习)对中文实体链接任务中的改进效果和不足. 实验结果表明, 基于Qwen-7B/ChatGLM3-6B的监督学习方法在Hansel-FS数据集上提升3.9% ~ 11.8%, 在Hansel-ZS数据集上提升0.7% ~ 4.1%, 在CLEEK数据集上提升0.6% ~ 3.7%. 这些方法在一定程度上改善了基于BERT等预训练编码器方法的“过拟合”问题. 经过不同规模的Qwen模型的对比实验, 可以发现无监督的语境学习方法在模型参数量达到720亿时也取得了与监督微调70亿参数模型相近的效果(−2.4% ~ +1.4%), 并且更大参数的Qwen模型在长尾问题上表现出优势. 通过消融实验, 本文深入分析了不同设置对大语言模型实体链接性能的影响. 错误样本的定量分析显示, 大语言模型在粒度范围和实体类别方面仍有36%和25%的错误占比. 通过错误样例的定性分析, 本文进一步定位了问题原因, 并给出相关改进方向. 这些研究为进一步完善大语言模型在实体链接任务中的应用提供了启示.
作者简介
徐正斐
北京理工大学计算机学院硕士研究生. 主要研究方向为知识工程. E-mail: zhengfei@bit.edu.cn
辛欣
北京理工大学计算机学院副教授. 主要研究方向为自然语言处理, 知识工程, 信息检索. 本文通信作者. E-mail: xxin@bit.edu.cn
https://blog.sciencenet.cn/blog-3291369-1479115.html
上一篇:最新发布!JAS持续入选中国科学院分区计算机科学类1区TOP期刊
下一篇:基于红外与可见光视觉的高炉铁口铁水温度场在线检测