为什么 Sam Altman 那么激动?

兴奋OpenAI 的创始人 Sam Altman,在社交媒体上相当激动地宣布 GPT-4o 图像功能升级,你看他还用了感叹号呢。
为了让你看得更明白,我把 Sam Altman 的第一条社交媒体帖子翻译成了中文。

他是这么说的:「这是一项令人难以置信的技术和产品。我记得第一次看到这个模型生成的图像时,很难相信它们真的是由 AI 制作的。我们认为人们会喜欢它,并且我们很高兴看到由此产生的创造力。」
不过我们都知道一句谚语:
王婆卖瓜自卖自夸。
所以,盲目采信大模型厂商的宣传语,是不审慎的。
GPT-4o 图像处理的实际效果是不是真像 Sam 说得那么让人激动呢?咱们来试试看。
替换首先,我们来尝试一个常见的操作:替换图片前景里的物体。
你看,这是我在我们学校生态校园拍的一张照片,校园里经常能看到大鹅在散步。照片里正好有这么几只大白鹅在草地上。

然后我就在 ChatGPT 4o 里上传了这张图,并且告诉它:「替换成迅猛龙」。
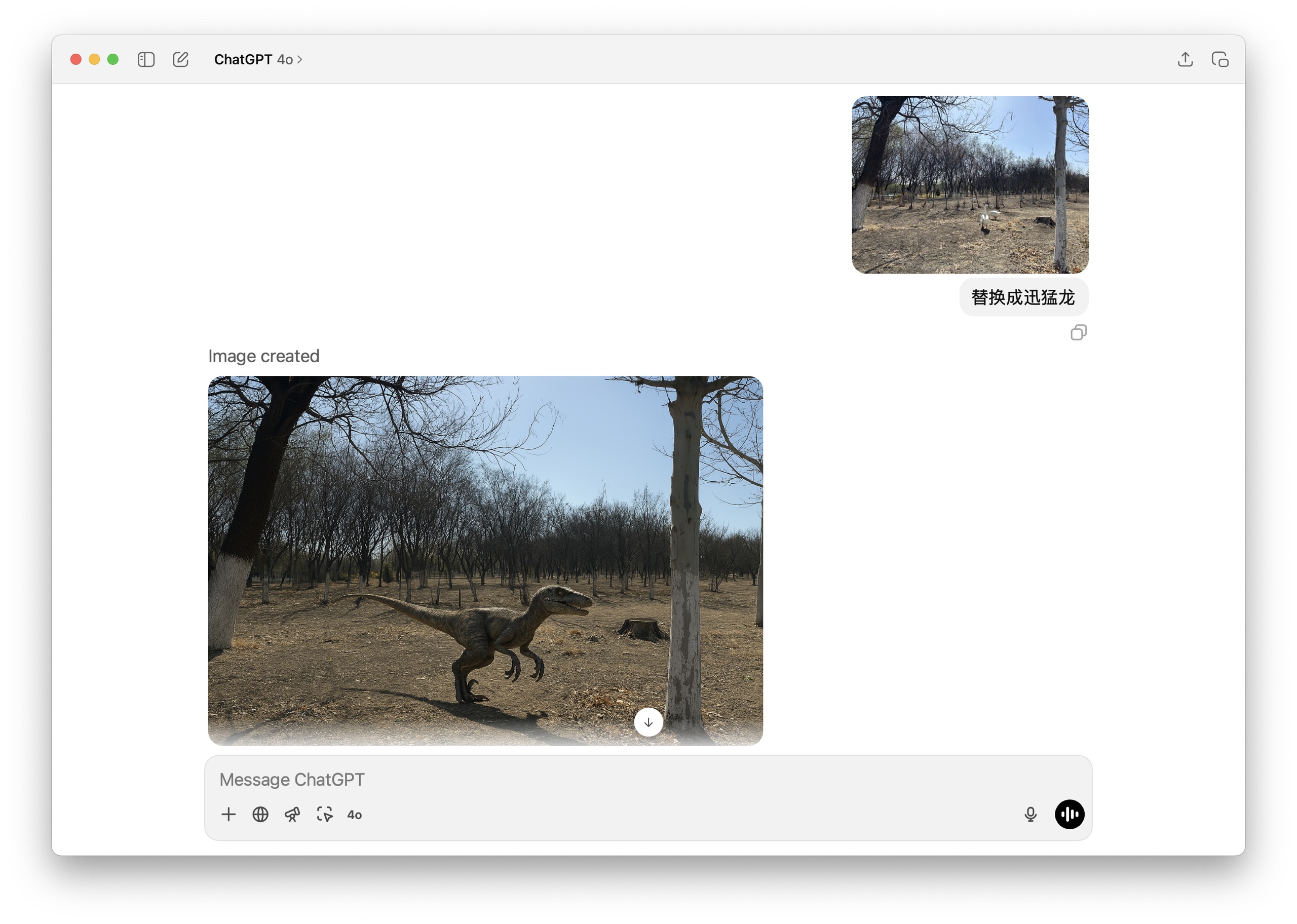
这是它给我生成的结果。咱们放大仔细看看。


如果你对比一下原图,会发现背景几乎没什么变化,一致性非常高。但是前景里的大白鹅不见了,取而代之的是只活灵活现的迅猛龙,好像它真的在我们学校校园里溜达一样。这个前景物体的替换做得相当不错,连地上的阴影效果都考虑到了。
背景接下来,我们再试试背景替换,看看能不能把照片的整个背景环境给换掉。
这次我选了一张开家长会的照片。为了保护大家的隐私,我在照片上打了码。

你可以看到,这是一个现代化的教室环境,对吧?
我的提示词很简单:「把场景改成山洞」。
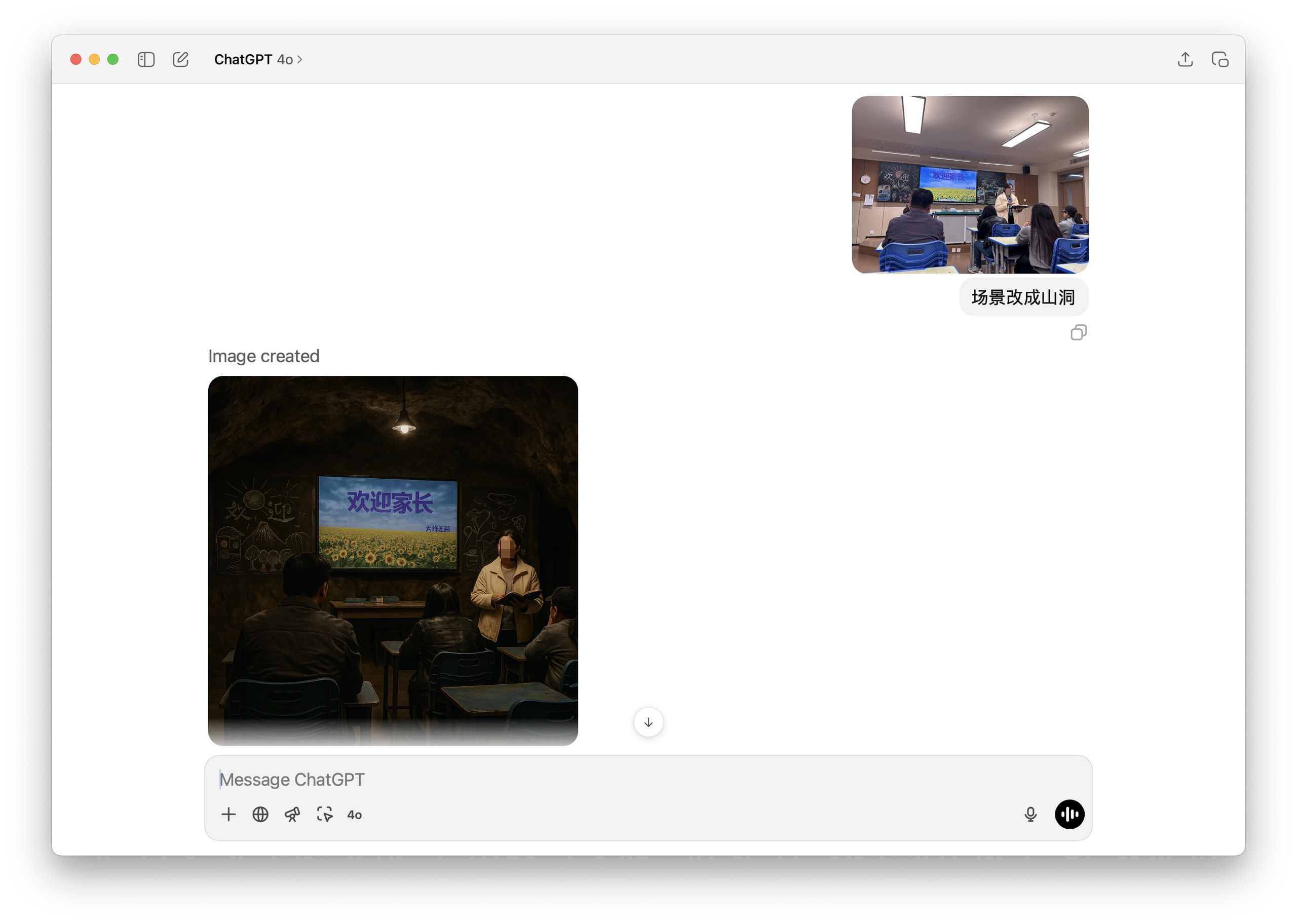
我们来看看生成的结果。把它放大看一下。

呃,在一个山洞里,还保留着这样一个现代化的屏幕,似乎有点儿不太协调。
不过,除了这一点之外,你会发现其他方面都还挺不错的。比如光线的处理、人物的穿着,甚至连桌椅都换成了跟山洞场景更搭调的样子。
前景里老师的衣服,还有她手里拿着的本子,都保留下来了原先的风格,只是根据新的场景做了一些「作旧」处理。这说明 GPT-4o 图像功能在调整故事背景方面还是有一套的。
风格下面我尝试的是风格迁移。我给了它一张自己旅途中的照片。


然后我要求:
「图中人物做成吉卜力风格头像 。」

下面是结果:
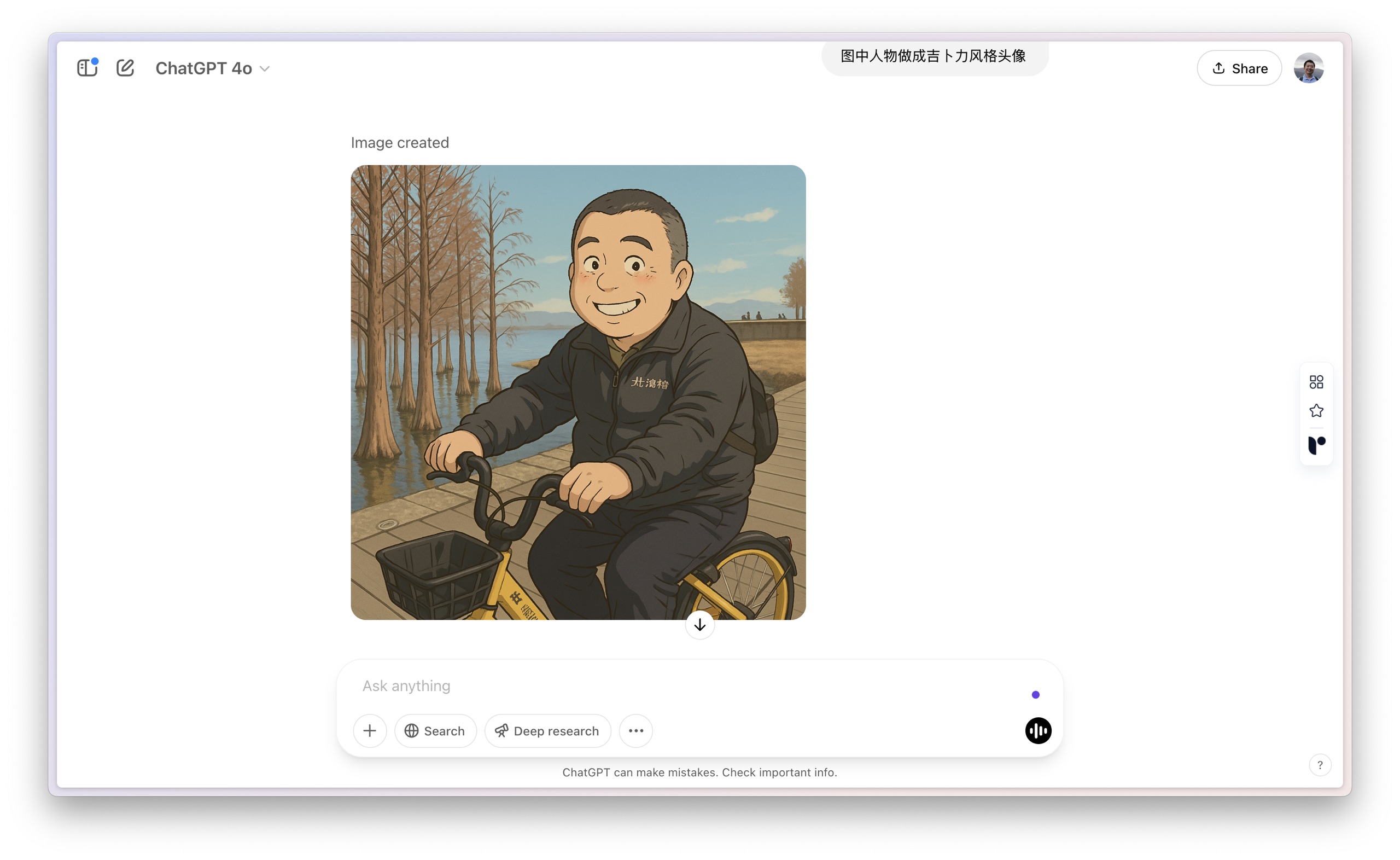
放大一下,是这样的:

我赞叹道:
效果还挺不错的🤭
至于我那些朋友们嘛,说起话来就不怎么客气了。
当真是「抢熊猫口粮 —— 夺笋啊」。
角度我中午在学校里面溜达,拍了一张时间广场的照片。

之后,我突发奇想 —— 你说,能不能让 GPT-4o 从不同角度展现这个场景呢?
于是我直接用手机上传图片,提出:
做成鸟瞰图
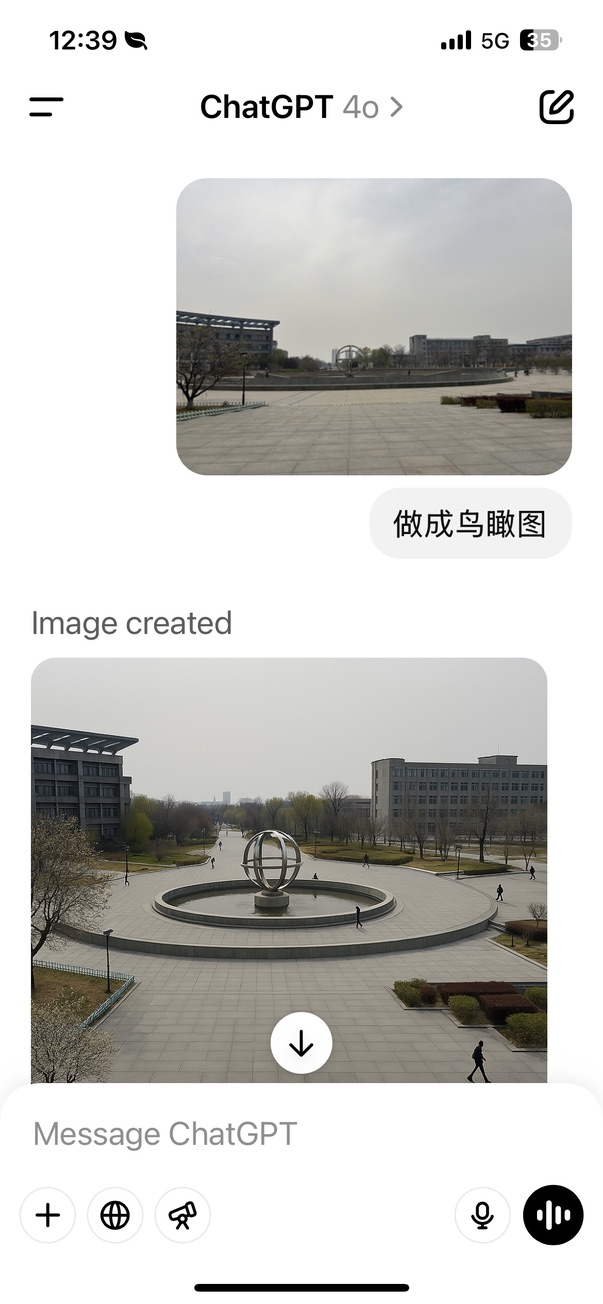
效果图放大一下:

怎么样,是不是视角改变了?
我乘胜追击,指令为:
做成俯视视角
于是画风就成了这样:
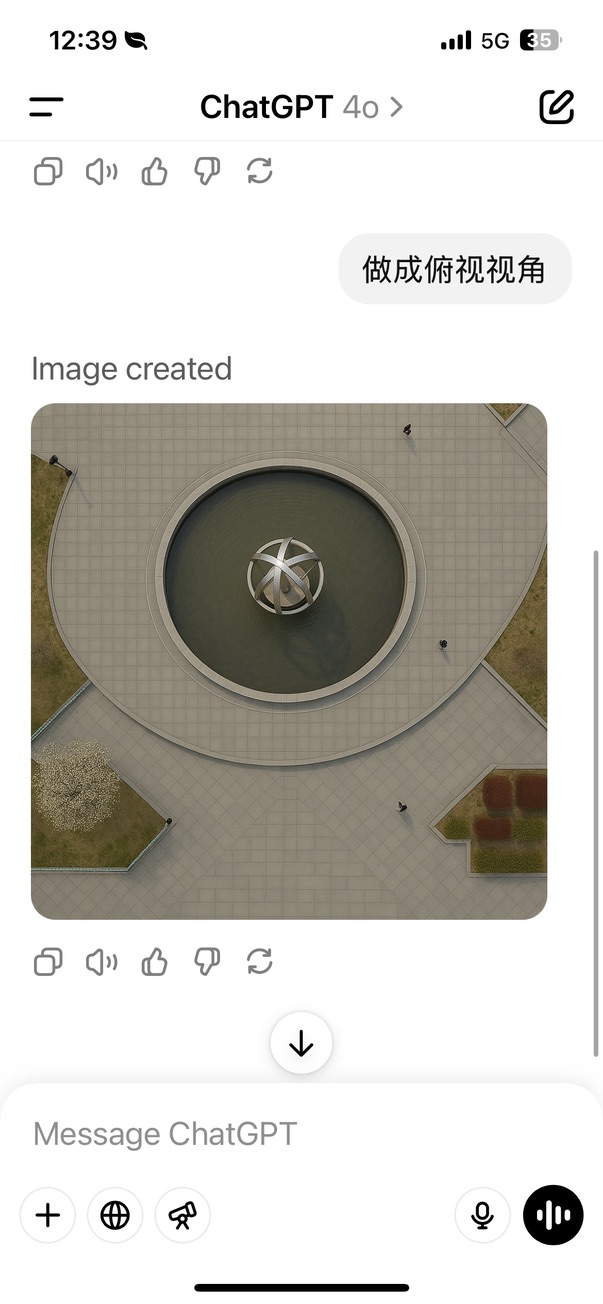
放大是这样的:

我突然感觉,这功能想象空间着实太大了。于是感叹:
AI 会不会让设计师的工作,变得更加轻松一些呢?
不过,从反馈来看,设计师们对 AI 生成的效果普遍不买账。确实,细节上差得还不少。不过没关系,AI 功能的进化速度足够快,相信不久之后,就能达到你们心目中的及格线了。
故事下面我们再来看看,如果不提供照片,直接让 GPT-4o 从零开始根据我的要求讲一个故事,并且配上图,效果会怎么样?
这次,我的要求是:「用四格漫画的方式,把系统开发中用户画像用可视化的方式来描述」。
它先是回复说:「好的」,然后给我规划了一下,先把漫画的标题和每一格要讲的故事梗概列了出来。标题是「谁在用我们的系统:用户画像的故事」。第一格是产品经理的困惑,第二格是虚拟人物登场,第三格是设计师参考画像进行设计,第四格是用户反馈。
然后它还问我,是需要草图版的线稿呢,还是直接生成 AI 风格的漫画图像?并且提供了几种风格选项,比如写实的、Q 版卡通的,或者极简插画风格的。
我对它说:「你画出来挨个试,先画第二个,就是你说的那个 Q 版卡通风格,给我画出来看看」。
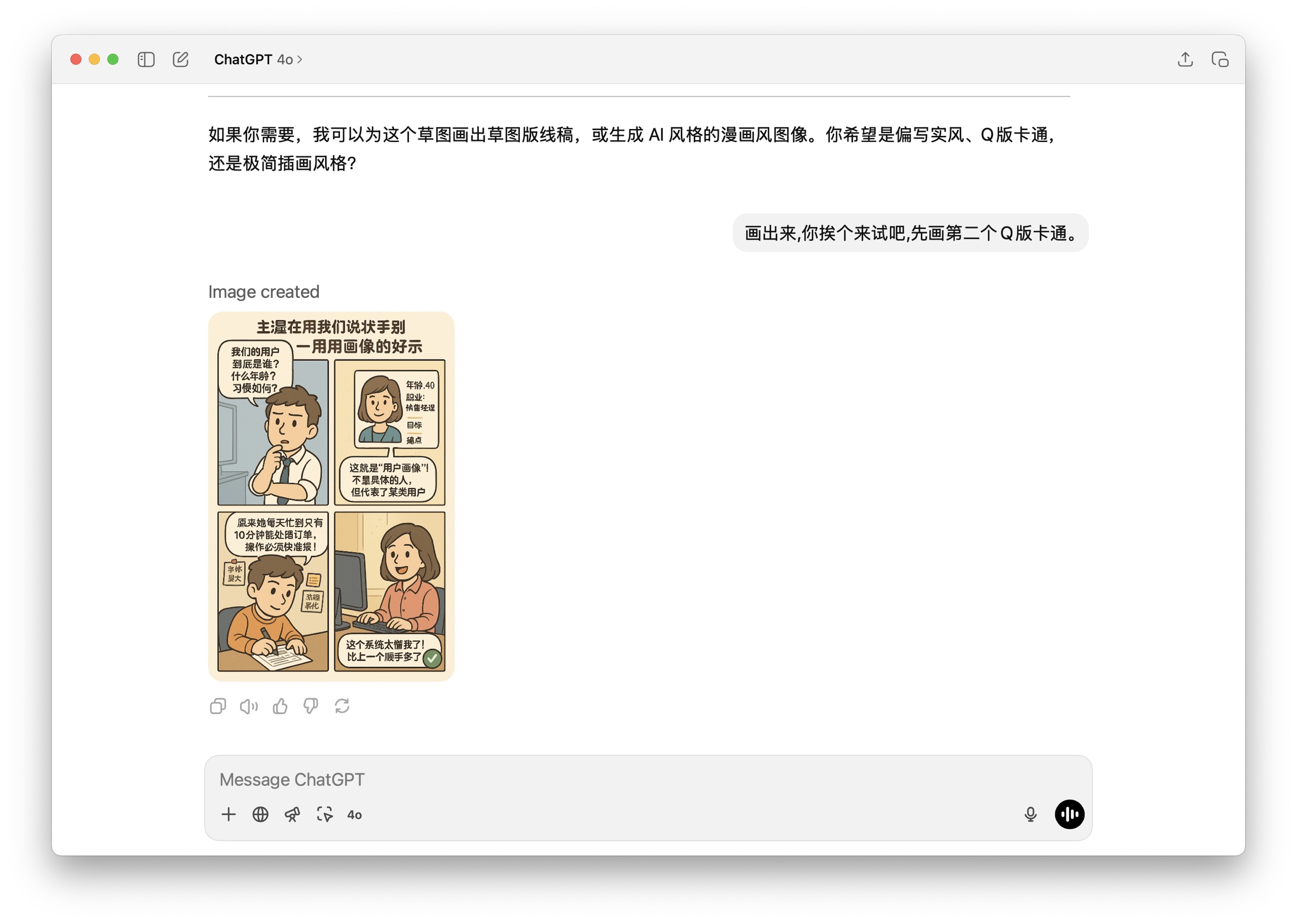
于是,它就给我生成了下面这幅四格漫画。我们打开大图仔细看看。

你看,第一格,产品经理很困惑:「我们的用户到底是谁?年龄、习惯如何?」
第二格,就展示了一个典型的用户画像:年龄 40 岁,职业是什么,目标和痛点是什么,强调这「不是具体的人,代表了某类用户」。
第三格,设计师参考这个画像进行思考:「原来她忙到每天只有十分钟能处理订单,那操作必须要快,界面一定要简洁!」
第四格,是用户的反馈:「这个新系统太懂我了,比上一个顺手多了!」
仅仅是基于我那句简单的提示词,就能直接生成这样一幅内容相关的四格漫画,我觉得挺厉害的。尤其是你看漫画里的中文文字,虽然不是每个字都完美呈现,但基本都能看明白意思。这比起之前的 DALLE 3 版本,进步已经真的非常明显。而且你再看看这个画风,四格里面人物的形象保持了相当好的一致性。
小结我们来简单总结一下。这次 ChatGPT 4o 更新之后,图像生成与跟随提示词修改处理效果,确实是给了用户们一个惊喜。
我们刚才看到的例子里,图片中文文字处理能力还有些欠缺。但一来如果你用英文提示,效果通常会更好。二来我相信在未来一年之内,无论是 OpenAI 还是其他的 AI 公司,应该都会持续改进中文字体显示等明显问题。
这意味着什么呢?可能从此以后,你再进行图像创作时,质量的上限将更多地取决于你的想象力、对艺术史的了解,以及你对图片结果的品味。你的绘图技术可能再不会拖后腿了。至少对我来说,能让 AI 帮我画出刚才那样的四格漫画,已经非常满意了。
这让我不禁想到了一个问题。你以前可能也听过一个关于达・芬奇的故事。说达・芬奇小时候,他的老师(据说是韦罗基奥)要求他反复画鸡蛋。达・芬奇画了一个又一个,就问老师为什么要画这么多鸡蛋。老师告诉他,画鸡蛋是为了打好基本功,基本功不扎实,将来怎么能创作出伟大的画作呢?
相信这个故事教育和鼓舞了很多学习艺术的小朋友。但是,在今天 AI 技术如此发展的背景下,我想请你思考一下:我们是否还有必要像过去那样,花大量时间去练习像画鸡蛋这样的基本功呢?
我这里并没有明确的答案,也绝不是说有了 AI 我们就完全不需要基本功了。
我只是想邀请你一起思考:就拿我们刚才生成 Q 版漫画这个具体的例子来说,是不是一定需要我们自己具备非常扎实的手绘基本功,才能创作出令人满意的作品呢?
希望你能把自己的想法写在留言区,分享给大家,我们一起来思考和讨论这个问题。
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1479409.html
上一篇:
新学期,给你自己配一个好用的 AI 助手吧。会思考,能联网,还有知识库那种下一篇:
从枯燥理论到生动实践:AI 智能代理如何用交互式教程讲解复杂概念 
 精选
精选