博文
本周学习内容记录
||
学习PLSA:之所以要看这个方面的内容是因为PLSA和NMF在中程度上是等价的,已有人证明PLSA和以KL散度为测度的NMF的 结果一致。为了弄明白PLSA,研究了一下EM算法。其中,对我帮助最大的李航老师写的《统计机器学习》中的介绍和博文http://blog.tomtung.com/2011/10/em-algorithm/上的内容。
谱聚类的相似度矩阵的融合:12-CVPR-Affinity aggregation for spectral clustering
文中提出谱聚类是一种依赖于相似度矩阵的聚类算法。借鉴当前比较热门的multi-viewclustering和multi-view kernel learning,本文提出对给定的很多的相似度矩阵融合一下,以期望能得到最好的聚类效果。这篇文章的思想比较简单,就是对很多的相似度矩阵加权。但是不同于以往加权的文章,文中通过最优化谱聚类的目标函数得到最优的权重,这点很值得借鉴。
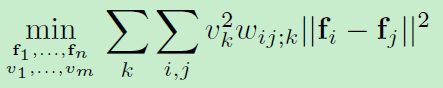
概率谱聚类:NIPS2005_A Probabilistic Approach for Optimizing Spectral Clustering
虽然这篇文章是谱聚类中很老的一篇文章了,但是,很惭愧的现在才看到。通过与PLSA的接触,现在对概率的知识不再抵触。之前接触到的谱聚类都是通过求解特征向量获得解。其实本身这种方式是最适用于二分类的,然后将其扩展到多分类上要用k-means等方法再进行一次聚类。本文中直接对多分类的情况求解,在计算两个簇的cut时如下式所示,考虑相应的点属于该簇的概率,然后以最大化相应的目标函数得到最终结果。这种方法得到的结果是局部的最优解。
文中用实验证明这种方法相比于求特征向量来说更加的稳定。求特征向量时涉及到求几个的问题,实验证明前 K 个不一定就是最好的,而本方法就没有这种问题。并且,本方法的运行效果要比之前的好很多。


https://blog.sciencenet.cn/blog-795564-708146.html
上一篇:multi-view clustering of multilingual documents