博文
统计扫盲:回归模型中,解释变量可以是分类变量么?
|
常言道,人在江湖飘,盲区少不了!经常有私信问我,回归中,解释变量可以使分类变量么?这确实是个非常基础的问题,但确实是个公众统计认知盲区。有相当一部分人对这个问题一知半解,对相关结果的解读也不是很准确,今天咱们就讨论一下这问题。
首先,一言不合就上答案:可以,没有任何问题,但对于结果要会做正确的解读。
先看以下例子。(Wurz et al. 2022)在17个village中分析了不同土地利用类型对热带混农林系统中生物多样性指标的影响。其土地利用类型,分成OGF, FF, FLW, VFST和 VFLW这五个类型。基于其数据结构,该研究构建了以下线性混合效应模型:
m1<-lmer(normalizedmean ~lutfire +(1|village), data=d1)
其中,normalizedmean为归一化后的多样性指数。我们可以查看一下其中变量lufire,也就是土地利用类型的分类情况:

可见此变量是一个字符型分类变量,且其默认的排在第一位的水平是OGF。
我们查看这个模型的结果:

直接看fixed effects 部分,这部分代表的即是模型对不同土地利用类型下,生物多样性的均值的估计值。仔细看一下,原来数据里包括的五种数据利用类型,怎么就剩下四类了呢?OGF弄哪儿了?别急,其实OGF是被当做截距了。这里的Intercept值的就是OGF, 后面对应的 SE, df, t值和P值,都是检验Intercept和0比差异是否显著的指标。所以这个结果说明,当土地利用类型为OGF时,模型对其生物多样性指数的估计值就是0.228, SE=0.009, P值远小于0.05, 这说明这种情况下,生物多样性指数是显著大于0的。
这部分结果的第二行,lutfireFF的值,表示什么呢?其实这一样表示的并不是当土地利用类型为FF时的多样性指数本身的估计值,而是当土地利用类型为FF时,其多样性指数相对于截距(也就是土地利用类型为OGF时)的差值。该值后面的一系列指标表明了差值跟0比的显著程度,也就是这时,多样性指数实在截距的基础上加上0,还是加上一个跟0比有显著差异的值。这里,这个值为-0.062,对应的P值也非常低。这一结果就说明,土地利用类型为FF的情况下,其生物多样性指数比土地利用类型为OGF时,低0.062,且这一差值和零比有显著差异。或者直接换句统计上的人话,土地利用类型为FF时的生物多样性显著低于土地利用类型为OGF时的生物多样性,且这个差值为0.062。
同样,固定效应部分结果的第3-5行,同样也是对应的土地利用类型下,生物多样性指数和截距的差异,解读完全和上面讲的一样。
那么这里,又引申出两个问题:
1)现在除了作为截距的OGF之外,对于其他的土地利用类型,我们是不能直接知道模型对其多样性指数的计值的,我们知道的只是他们和OGF的差值。虽然我们可以通过手动计算得来,但毕竟略显麻烦。那么我们是否可以直接让模型给出其对不同土地利用类型条件下的多样性估计值呢?当然可以,我们只需运行以下模型:
m2<-lmer(normalizedmean ~lutfire-1 +(1|village), data=d1)
注意看,这里,我们在自变量lutfire后面加了一个-1, -1表示的就是这个模型不要截距了,或者可以认为截距是0,那么这是模型便会直接给出lutfire不同类型条件下,多样性指标的均值的参数估计值:

看fixed effects部分结果,模型对五种土地利用类型下,生物多样性指标的参数估计的均值,SE, 及其和0比是否有显著差异,都已经直接安排好,提供给我们了。我们就还可以直接提取这个结果,进行作图了,这是不是看着很摇摆?
我们也可以稍躺平一点,直接利用现有函数出图:
library(sjPlot)
plot_model(m2,type="eff", terms="lutfire")
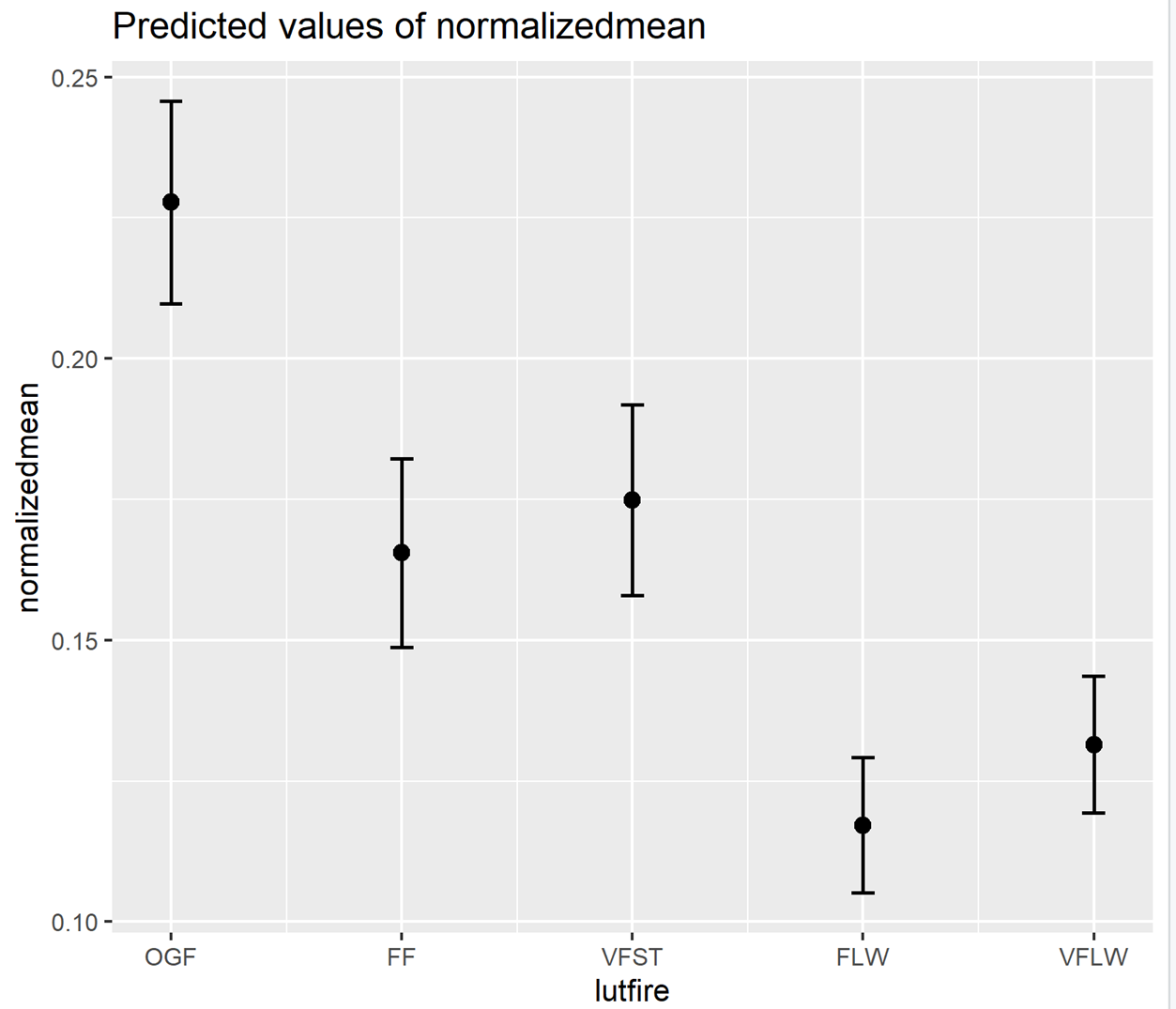
2)通过第一个模型,我们已经知道其他土地利用类型和作为截距的OGF之间是否有显著性差异了。但除了OGF之外的其他土地利用类型之间的差异显著性,我们仍然无法直接判定。那么他们之间的差异性如何呢?
这就是所谓多重比较问题了。我们可以直接安排:
library(multcomp)
comparisons <- glht(glm1a, linfct=mcp(lutfire="Tukey"), test = adjusted("bonferroni"))
summary(comparisons)
这里为了降低我们犯第一类型统计错误(弃真)的概率,对P值做了bon校正。
结果如下:

安排的明明白白,舒舒服服!可见,除了VFST和FF, 以及VFLW和FLW之间无显著差异以外,其他不同类型之间都有显著差异。怎么样,分类变量能否参与回归这一问题,现在清楚了吧?
参考文献:
Wurz, A., T. Tscharntke, D. A. Martin, K. Osen, A. A. N. A. Rakotomalala, E. Raveloaritiana, F. Andrianisaina, S. Dröge, T. R. Fulgence, M. R. Soazafy, R. Andriafanomezantsoa, A. Andrianarimisa, F. S. Babarezoto, J. Barkmann, H. Hänke, D. Hölscher, H. Kreft, B. Rakouth, N. R. Guerrero-Ramírez, H. L. T. Ranarijaona, R. Randriamanantena, F. M. Ratsoavina, L. H. Raveloson Ravaomanarivo, and I. Grass. 2022. Win-win opportunities combining high yields with high multi-taxa biodiversity in tropical agroforestry. Nature Communications 13:4127.
最后,鄙人新一期混合效应模型培训班即将举办,敬请有需要的同仁关注:

https://blog.sciencenet.cn/blog-3442043-1382595.html
上一篇:系统综述(含Meta分析)中的八大问题
下一篇:回归模型中,拟合线置信区间的宽窄是如何计算的?