博文
干货分享 | 仪表识别究竟难在哪?
|
摄像直读抄表,俗称“视觉抄表”,是一种通过手机或终端设备对水电气表拍照后利用图像识别算法将仪表照片自动识别为读数的智能抄表方案,具有使用范围广、安装简单、有图有真相、易于使用等特点。仪表表盘图像识别算法是视觉抄表中至关重要的一环,早在21世纪初,便有不少专家学者开始从事这一研究工作。然而,由于当时的算法识别率低、硬件成本高、通信基础设施不完善等诸多原因,视觉抄表一直停滞在研究阶段,并没有大规模普及开来。
随着NB-IoT网络、高性价比芯片等相关技术的发展为之提供了硬件基础,深度学习等图像识别技术的快速发展为之提供了软件基础,视觉抄表这一直观方法重新登上历史舞台,引起了业内人士的广泛关注。快速赋能离线表计,让表网数据更完整,有图有真相的特点彻底解决了买卖双方信用纠纷问题,让决策更可信。如今,在存量市场有绝对优势的视觉抄表方案,毋庸置疑成为了仪表智能化2.0时代不可或缺的产物。
受益于深度学习技术的出现,摄像直读抄表的识别精度相对于本世纪初得到了很大的提升,然而为了实现大规模商业化应用,视觉抄表方案存在大量工程化问题需要解决。例如,摄像终端硬件如何做到低功耗、低成本、高传输成功率、结构高适配,同时还能有效应对恶劣复杂的现场环境;云计算平台如何对千万级图片数据进行可靠快速存储、如何应对高并发、如何满足各行各业对于抄表背后更深层次的应用诉求;算法识别结果的准确率如何做到保障,如何对异常数据进行快速稽查等等。
一般的,视觉抄表的流程可概括如下:1、在仪表上外挂式安装拍照采集设备;2、设置采集终端定期启动拍照;3、图像通过无线网络上传至服务端;4、通过图像识别算法,将照片读数转化成数值结果;5、实现远程抄表、数据分析、收费管理等上层应用服务。本文将以北京羿娲科技自主研发的“羿读AI 视觉读表系统”(如图1所示)为例,从识别率、通用性、配套服务三个层面分析仪表智能识别系统在算法工程化过程中面临的问题。
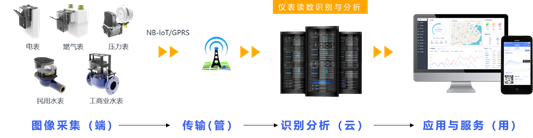
图1:摄像直读远传抄表的一般流程
一、识别率
影响模型识别率的因素是多方面的,这里从图像层面和算法层面两个角度分析。
(1)图像层面
水、电、气、热等仪表所处的环境比较复杂,通常安装于狭小、隐蔽的位置。这些地方常年累月无人问津,导致仪表本身经常出现进水(湿表)、表面脏污、结构遭到破坏等现象。这种情况下拍摄的仪表图片通常质量较低。图2显示了摄像终端拍摄的几张低质量水表图片的示例。对于水表来说,决定于其机械结构,很容易出现进水的现象。对于有水珠、水泡、水纹的仪表,拍摄的图片其数字容易出现变形和切断的现象。另外,表盘脏污、表盘冻裂、灰尘、反光、传输出错也是降低识别率的因素。这就给识别造成了严重的干扰。当仪表表盘出现脏污等现象时,即使是使用手机拍摄高清大图,有时也难以辨认数字或指针(如图3所示)。在一些情况下,终端可能因外力或者人为因素而产生移位,导致所拍图片没有包含表盘(如图4所示)。识别时应对这种非仪表类型图片做出正确区分,避免识别率受其影响。

图2:摄像终端拍摄的水表图片

图3:手机拍摄的水表图片

图4:终端拍摄的非仪表类型图片
另外,出于降低终端成本、增加终端电池寿命的考虑,摄像终端所采用的摄像头分辨率都不高,拍摄的图片尺寸都比较小,并且使用较高的图片压缩率。对于低分辨率图像进行高精度的识别,其本身就是一个学术难点。通常图像的识别率会随着分辨率的降低而下降(如图5所示),初始阶段降低比较缓慢,随后出现快速下降。因此需要寻找一个成本与识别率之间的平衡点。
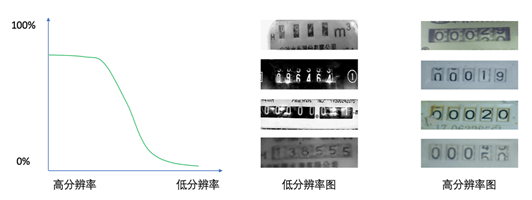
图5:分辨率和识别率的关系(左),低分辨率图难以识别(中),高分辨率图容易识别(右)
(2)算法层面
深度学习的出现,极大地促进了目标检测、图像分类等任务性能的提升。每年在ImageNet、Caltech Pedestrian Detection Benchmark等公开数据上目标识别的精度、速度不断改进。然而,当前基于深度学习的目标检测、识别技术在某些方面仍存在不足。例如,低分辨率识别、小目标问题、多尺度问题、遮挡问题、旋转目标识别问题、泛化性问题、数据需要量大等。

图6:当前算法存在的难点
前文已经提及,低分辨率图片的识别是一个难点,如何延缓识别率降低的拐点是该问题研究的重点。对于仪表识别而言,该问题主要出现在覆盖式或悬挂式摄像终端所拍摄图片的识别上,受限于电池电量,必须使用低分辨率的图片。
小目标通常具有比较弱的视觉信息,给其识别和定位带来了很大的困难。小目标的尺寸比较小,不能在更高尺度的特征图上进行识别。而低尺度的特征图缺乏语义信息、上下文信息。如何有效地在网络中引入语义信息、上下文信息是一个难点。现有的方法包括上下文推理、动态放缩、特征融合等。对于摄像终端而言,通常不存在该问题。而对于手机拍摄的仪表图片(通常来自于抄表人员),由于拍照时操作的不规范性,有时拍的仪表比较小,在图片中仅占很小的范围。
现实世界中的目标通常具有较大的尺度变化,尺度变化范围可以从几像素到几百几千像素,这就给当前的目标检测、识别算法带来了巨大的困难。对于预设锚框的方法就需要精心的铺设好锚框,从而能覆盖所有尺度的目标。然而,大量的锚框会显著降低推断速度。该问题也多见于手机摄像抄表。
手机拍摄的仪表图片可能具有较大的旋转变化、视角变化,如图6所示。例如右上图中右边的压力表,很难进行读数。左下角的水表图,不进行转正也很难进行识别。当前学术上重点研究具有不变性的识别,即不管目标是否发生形变,仿射变化,只要能判定目标的位置和类别即可。即使是旋转目标检测问题也较少研究。然而,在仪表识别这一任务中,旋转变化、仿射变化对读数判定有很大影响。
仪表结构存在诸多变化性,包括不同子目标的放置位置差异、字体差异、颜色差异、指针形状差异等等。这些变化性给仪表识别带来了很大的困难。在一个仪表数据集上训练的模型经常出现在新表型上不能准确识别的现象。
除了算法本身所面临的问题之外,数据收集和标注问题也同样突出。目前深度学习模型需要大量数据进行训练,这些训练数据需要囊括各种不同场景下的不同类型的仪表。要收集这些数据,就必须对大量安装在不同类型仪表上的终端进行连续拍照。收集到数据之后,仍需对其进行标注才可进行训练。而目前的标注方式大都依赖手工标注。标注和管理数据集会消耗相关人员大量的时间和精力。
二、通用性
开发出一个通用人工智能程序是人们长久以来的梦想。近期,相关的研究领域也变得活跃起来,例如,终生学习、元学习等等。然而,不得不说,即使是开发一个通用的仪表识别程序也存在很多困难。其困难来自于两个层面:感知和决策。如前所述,由于图片的低质量,当前感知算法自身的缺陷,不能精确的获取到用于推理的相关信息。而对于决策层面,由于仪表的类型多种多样,读数的规则可能也多种多样,这就给决策带来了很大的困难。下面我们通过几个例子进行阐述。
(1)一种类型、一种读法
对于不同类型的仪表读数方法通常存在很大差异。例如指针水表,需要根据每个指针的位置得到一个数字,再根据前后变化的关系得到最终读数。对于液晶电表,需要识别出小数点和数字,顺序串接一起,得到读数。

图7:不同种类的仪表
(2)不识别小数点后数字
有时,人们不关心小数点后的读数,需要去掉。然而,不同仪表在表征小数点位置上存在较大差异。即使对于外形比较相似的电表和燃气表,其差异也比较明显。如图8所示。有些表通过一个点或者通过颜色表征小数点。但是小数点可能存在差异,比如是实心还是空心圆。使用颜色表征小数位时,颜色可能是数字的背景色,也可能在数字外有一个带颜色的框。这些变化性给感知和决策都带来了较大的挑战。

图8:电表、燃气表
(3)太专业,不知道怎么读
有些表可能具有专业用途,普通群众可能难以接触,因此,可能不知道如何读数,需要查阅相关的资料。如图9所示。

图9:类型或读数方法未知的仪表
(4)选择困难症
实际中存在多屏调变表和多区域表的情况。多屏调变表以一定的或可变的时间间隔呈现具有不同意义的数字,终端以固定的间隔拍摄一批图片,需要通过某种方法将其中需要的数字挑选出来。当表的有效屏比较少,数值接近,或者数值突变(用户充电)时,会给算法带来一定的难度。多区域表为一张图片中存在多个仪表的情况。学术上解决该问题的方法是标出每个区域,每个区域分配一个类别,但这并不一定适用于读表。

图10:多屏表和多区域表
最后,即使是同一类型的仪表,不同的客户可能有不同的实际需求,这又给读数决策带来了更大的困难。然而,这可能更多是一个工程性问题。会给维护带来较大难度。
三、配套服务
一个优秀的识别模型,不仅要有精确的识别效果,其配套的服务也须具备易用性、可靠性、安全性。
(1)易用性
易用性即客户对提供的服务容易理解和使用,相关的配套设施完善。例如,某客户只需要调用算法识别的API接口,接口调用参数需要尽量简单,相关的配套文档需要清晰准确。对于无开发能力的客户,可能会有客户端监控的需求,因此需要根据客户需求,定制相关的客户端功能。除了对图片识别结果的简单展示,图表汇总、统计、数据分析都能在一定程度上增加易用性。
(2)可靠性
给客户提供的识别接口需要稳定可靠,不能经常出现连接失败、空值等现象。这需要识别服务采用合理的架构,并且部署在稳定的云平台上。在服务架构方面,目前较为流行的架构方式是采用微服务这一设计思路,通过Docker和Kubernetes等技术,把各项识别服务容器化,部署在单一机器或服务器集群上。通过把服务容器化这种方式,服务编排和管理的可靠性得到了一定程度的保证。而在云平台方面,目前市场上比较成熟的云服务器提供商有亚马逊的AWS,阿里巴巴的阿里云,腾讯的腾讯云等。在这些较为成熟、稳定的云平台上部署服务可以在一定程度上保证识别服务在机器层面的可靠性。
(3)安全性
客户的数据有时是隐私敏感的,需要相关的技术手段脱敏,从而保证用户隐私不被泄露。或者具备私有化部署的能力,将算法和云平台部署到客户自己的机器上,完全实现服务供应方在数据不可见的情况下提供完整的识别服务。
(4)并发
识别接口在设计时需要充分考虑并发的问题。提升并发能力最直观的两种方式为:增设服务器、降低模型推断时间。其中,增设服务器直接增加了识别服务可用的计算资源,从而提高了并发量;降低模型推段时间则是使模型能够更有效率地利用计算。
四、人脸识别VS仪表识别
与人脸识别中最有挑战的N:N街拍机抓罪犯场景对比,尺度、分辨率、光照、抗干扰等方面两者挑战度类似,角度层面人脸识别难度更大,但在目标多样性和识别精度与鲁棒性上仪表识别挑战大很多,例如识别出的罪犯10中1即可,而仪表识别结果却仍需要保证精度与鲁棒性。
综上,在技术层面,仪表识别和人脸识别在难易程度上相似;在应用中,表比人多,但人可移动,所以二者潜在市场空间都很大。
原创声明:本文为北京羿娲科技有限公司原创,版权归属北京羿娲科技有限公司所有,转载需获得授权。
https://blog.sciencenet.cn/blog-341685-1208813.html
上一篇:Siggraph 2012 总结