博文
rank abundance 解析
|||
在16S rRNA扩增子分析中,rank abundance已经是必备的一项分析内容。它可以从OTU的层面总体的反映出物种的分布情况(丰度和均匀度)。如下图:
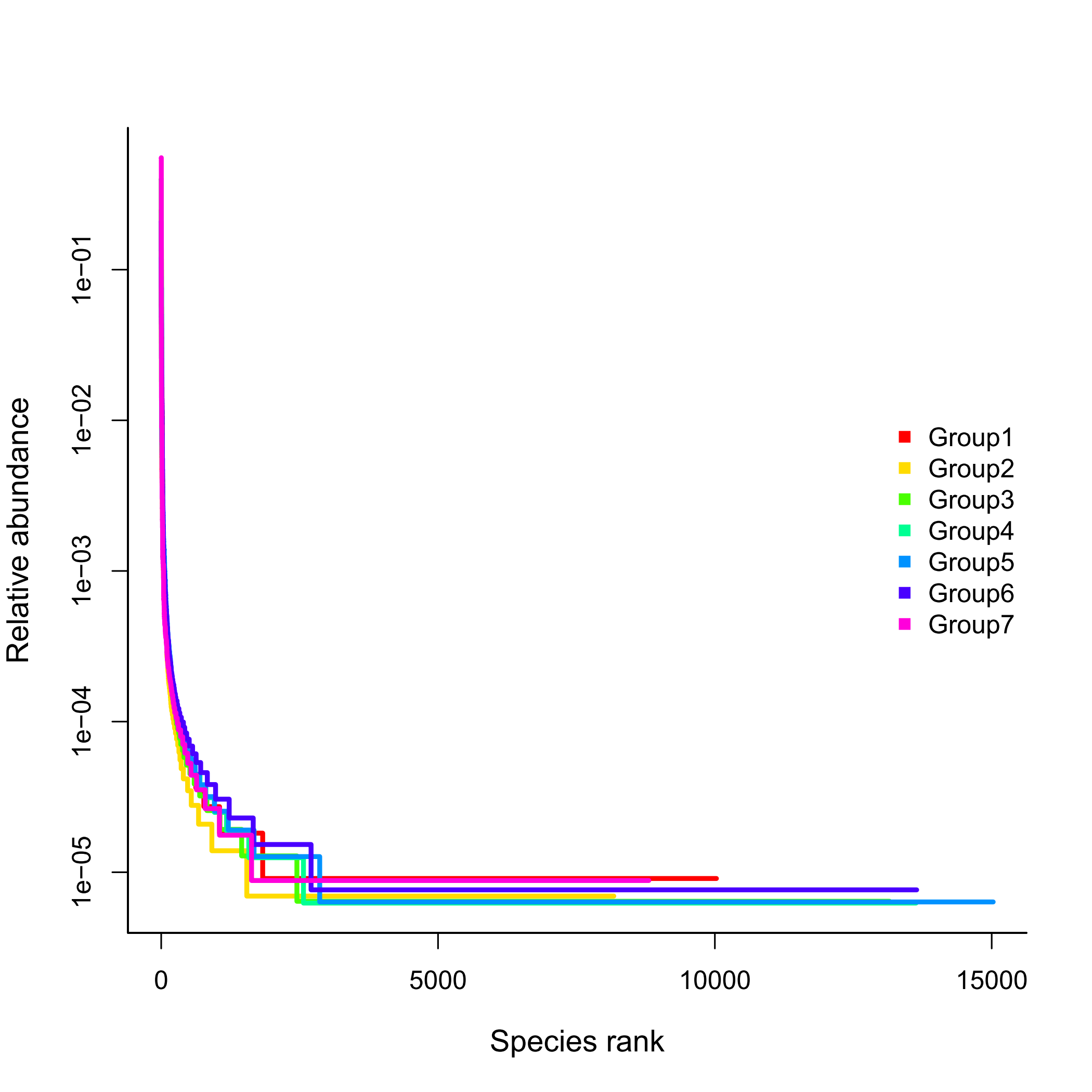
大多数资料只会对横纵坐标进行解释:
x轴反映的是各物种的丰度,物种丰度越高,样本落在x轴上的区间越大,如上图中Group5的物种丰度高于Group1;
整体来看,如果这条曲线下降得越平缓,则表明物种分布越均匀,上图中各物种的均匀程序相差不大。如果遇到某个样本生成的rank abundance曲线中,楼梯下得比较徒,即垂直的线越长表明这个OTU的丰度越大。
但是,rank abundance是怎样算出来的?为什么横纵坐标表示的是上述解释?一般都没有讲出来,这里给出rank abundance的算法,加深理解,理解了就可以自己动手来画。
rank abundance计算过程:
1. 获取每个样本中OTU的丰度值,例如从QIIME的otu table中获取。通俗来讲,即搞清楚样本(如上图中Group1),中每个OTU它代表了多少条序列。
2. 将每个样本中OTU的丰度值按照从大到小顺序进行排序。注意:这步最精华的部分,因此整个分析过程叫做rank abundacne!
3. 将每个样本归一化,获取每个样本OTU的相对丰度。例如样本1中有5个OTU,丰度分别为5,4,3,3,5,那么排序后为5,5,4,3,3,总丰度即sum(5,5,4,3,3)=20,归一化后的相对丰度为5/20=0.25, 5/20=0.25, ... 。
注意:样本的相对丰度和其它样本无关,例如样本1中有5个OTU,样本2中有7个OTU,那么样本1的sum值为这5个OTU丰度的总和,样本的sum值为7个OTU丰度的总和。
4. 对于每个样本, x轴是OTU的种类数,y轴是对应的OTU的丰度。例如样本1中有5个OTU,丰度分别为0.2,0.25,0.25,0.2,0.15,0.15(注意:这里是排好序的相对丰度)。那么按点(1,0.25),(2,0.25),(3,0.2),(4,0.15),(5,0.15)画出梯形图, 一般画的都是下梯形(和正常的楼梯相似)。
5. 一般会将y轴取对数,要不然会相当难看。同时将所有样本y轴的刻度调整到一致。这样就完成了rank abundance图的绘制。
对于微生物多样性,人们最想了解的是两大关键指标:
1. 某个生境下,一个菌落中,有多少种菌(物种多样性)?
2. 每种菌含量是多少(物种丰度)?
rank abundance曲线能够从OTU的层面上很好的回答这两个问题[注意:是从OTU的层面上]:
1. 在rank abundance曲线中每一条垂直的线代表一个OTU,可以理解为一种菌
2. 每一条垂直线右侧的水平线(即楼梯的平台)表示该菌种含量
https://blog.sciencenet.cn/blog-2970729-1069060.html
上一篇:perl的更新与模块的安装
下一篇:QIIME中jackknifed_beta_diversity.py程序的运行过程