博文
如何用 AI 给科研提速?超长对话记忆 Kimi Chat 体验  精选
精选
|
我尝试了网络文章总结、学术文献分析,以及长文翻译。

最近经常听小伙伴提及 Kimi Chat 这款国产大语言模型,据说它在上下文记忆能力很有特色。于是我打开官网(https://kimi.moonshot.cn/)进行了尝试,今天就来给你分享一下我的使用心得。

Kimi Chat 在首页提供了一些示例。它能够概括输入的 PDF 文件,或者帮助你分析网页链接。从样例中不难看出,Kimi Chat 官方宣传的一大特色便是它的超长对话上下文(long context)。官方声称可以处理高达 20 万字的中文输入。Kimi Chat 的长期目标是建立一个具有持久记忆的大型语言模型。也就是说,你天天跟他对话,去年与它互动的内容其间隔了无数的其他对话乱入,可如果你今天突然问起来,它依然能够精准想起来。
Kimi Chat 的宏大愿景是当大语言模型成为操作系统时,它可以作为高效可靠的存储服务,为大语言模型的计算提供基础和保障。我觉得,在 OpenAI 一马当先时,后发的大语言模型都需要找准自己的定位,才能在竞争和发展中有足够宽广的「护城河」。
你注册并登录之后,就可以开始新对话了。
下面,咱们通过网络文章总结、学术文献分析,以及长文翻译这几个场景,分别试试 Kimi Chat 的能力。
网文总结首先,我尝试了 Kimi Chat 首页提供的一个总结链接对应内容的示例。只不过,我把示例中的链接换成了自己的公众号文章,让它帮我概括并针对文章内容提出问题。
提示词如下:
结合文章标题,用一句话精确凝练地总结这篇文章,在回答中用 “一句话总结:” 开头;
整理这篇文章中的观点,并展开阐释;
如果你是一名效率应用专家,针对这篇文章再提出三个问题;
https://blog.sciencenet.cn/home.php?mod=space&uid=377709&do=blog&quickforward=1&id=1416221
这篇文章是我最近发布的,标题为《过去这一年我有哪些离不开的效率应用》,我们看看 Kimi Chat 如何回答。

Kimi Chat 首先进行了一些思考,然后开始输出。

这是 Kimi Chat 最终输出的结果:

Kimi Chat 首先做出了一句话的总结,然后对文章中的观点进行了阐释。除了视频剪辑、内容管理,还提到了资料查询,这与我在文中列出的三款应用相符。
Kimi Chat 还提出作为一名效率应用专家,可以进一步提出三个问题。包括:
在处理视频剪辑时,能否识别并自动消除视频中的其他问题,比如背景噪音或画面抖动;
Heptabase 是否可以与其他笔记应用,如 Notion 等集成;
Perplexity 在生成图表或流程图的准确性和可靠性如何。
我认为 Kimi Chat 提出这些问题都很有趣,至少能给我们提供一些启发。
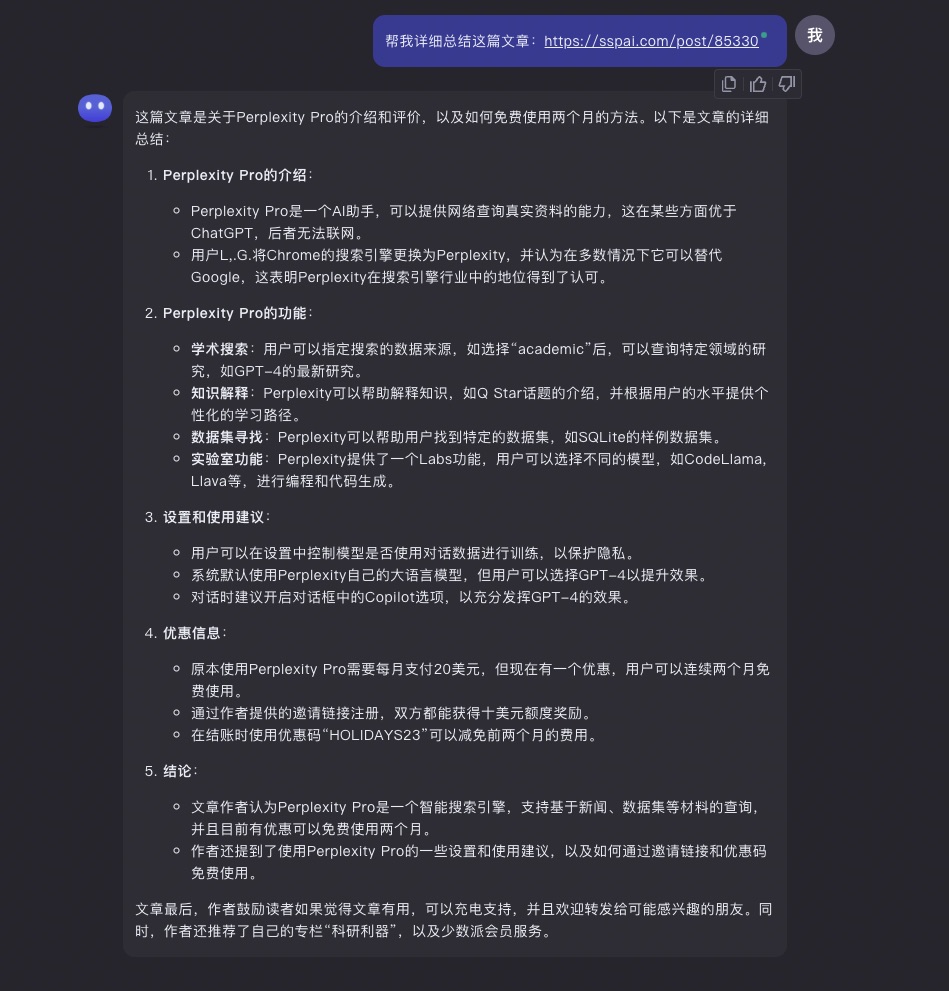
公众号文章总结,我觉得 Kimi Chat 做得非常好。不过我们平时用到的链接,不止来自于公众号。为了进一步测试它总结网文的通用性,我把自己的一篇少数派文章的链接发给了它。这篇文章《Perplexity Pro 好用吗?如何免费连用两个月?》介绍了 Perplexity Pro 的功能和当时官方提供的优惠信息。

我发现 Kimi Chat 对这篇少数派文章内容的提取依然非常全面,包括基本介绍、功能、使用建议、优惠信息以及最终结论,显示了它对链接对应全文准确而深刻理解。
接下来我测试了 Kimi Chat 处理学术资源的能力。我询问它能处理哪些类型的学术资源,比如是否能直接读取 CNKI 的信息?
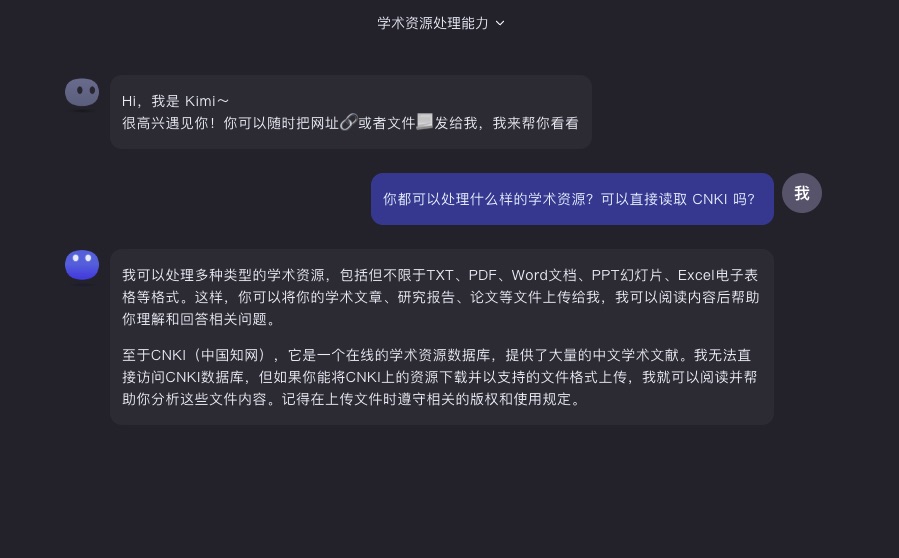
Kimi Chat 说回答它可以处理 txt、PDF、Word 等多种文档格式。至于 CNKI(中国知网),它无法直接访问,这确实是一个遗憾。
但是,Kimi Chat 提出,用户可以下载 CNKI 资源并以支持的格式上传,然后它可以进行阅读和分析。Kimi Chat 还特别提醒,在上传文件时要遵守相关的版权和使用规定。我觉得这个提醒很重要。
顺便说一句,我这两天就该问题咨询了 Kimi Chat 的客服人员。得到的答复是虽然目前 CNKI 资源因为版权问题尚未支持,但是 Kimi Chat 后续会考虑采购和对接更多学术文献数据源。不过 Kimi Chat 目前已经列出的用户需求比较多,得根据优先级一个个实现。如果有更多学术用户提出需求,他们会把学术数据源扩展的优先级提升。所以建议平时需要查文献的小伙伴们,抓紧给 Kimi Chat 提需求吧,哈哈。
Kimi Chat 明确提示用户最多可以上传 50 个文件,每个文件大小不超过 100MB。这是我目前所用到的大语言模型中,上传文件限制最宽的。Kimi Chat 还规定了可以上传的各种文件类型。由于我们关注的是处理学术资源的能力,所以这回我们主要使用 PDF 格式的文件。

首先,我尝试了 Kimi Chat 对单篇文献的总结能力。为了确保我对文献内容的熟悉,我选择了自己的一篇论文,2023 年 10 月发表在《图书情报知识》上的《AIGC 时代的科研工作流:协同与 AI 赋能视角下的数字学术工具应用及其未来》。

我将这篇论文交给了 Kimi Chat,要求它帮助解读文章的创新方法和局限性。
Kimi Chat 思考片刻,立即开始认真输出结果。
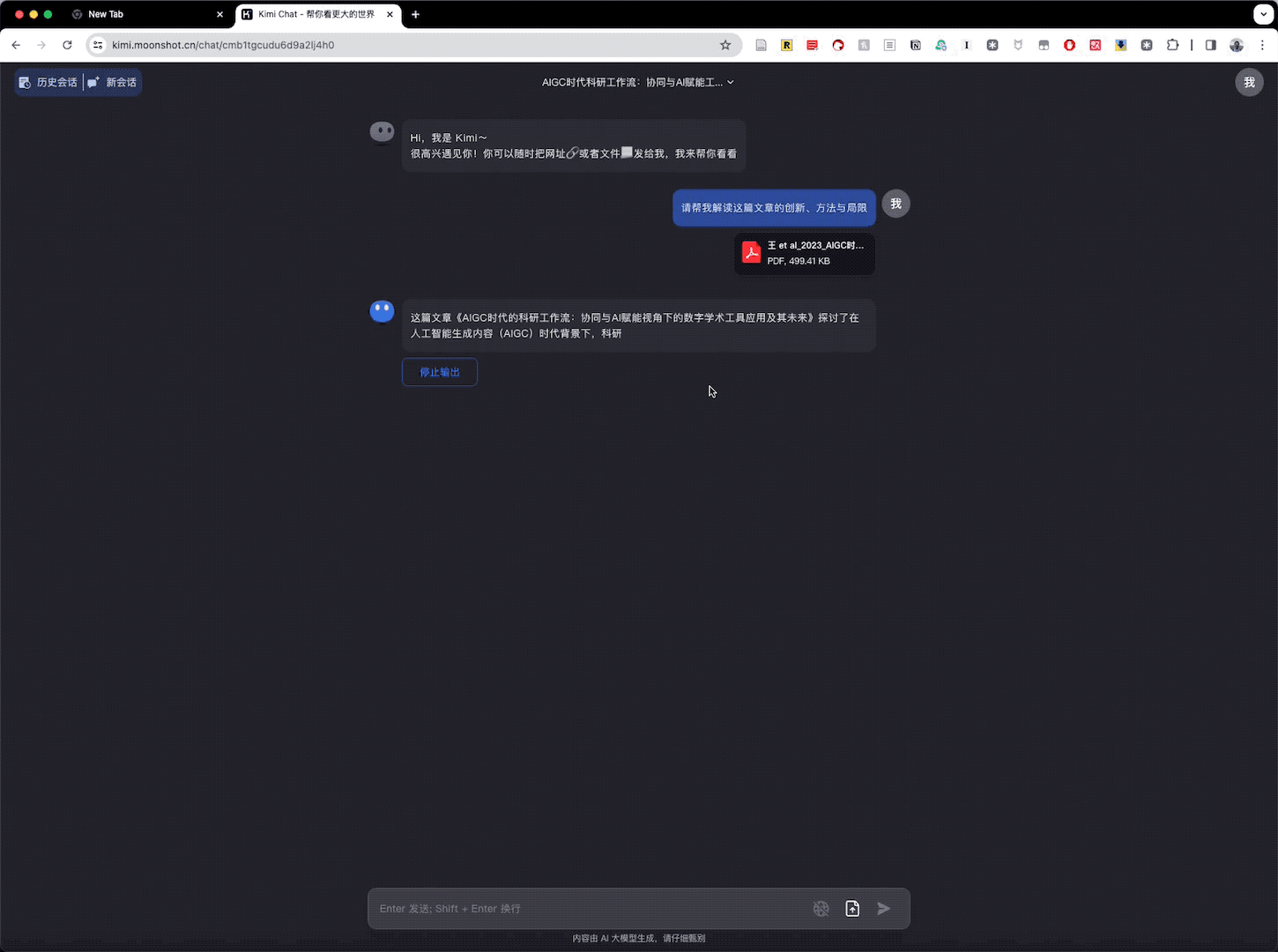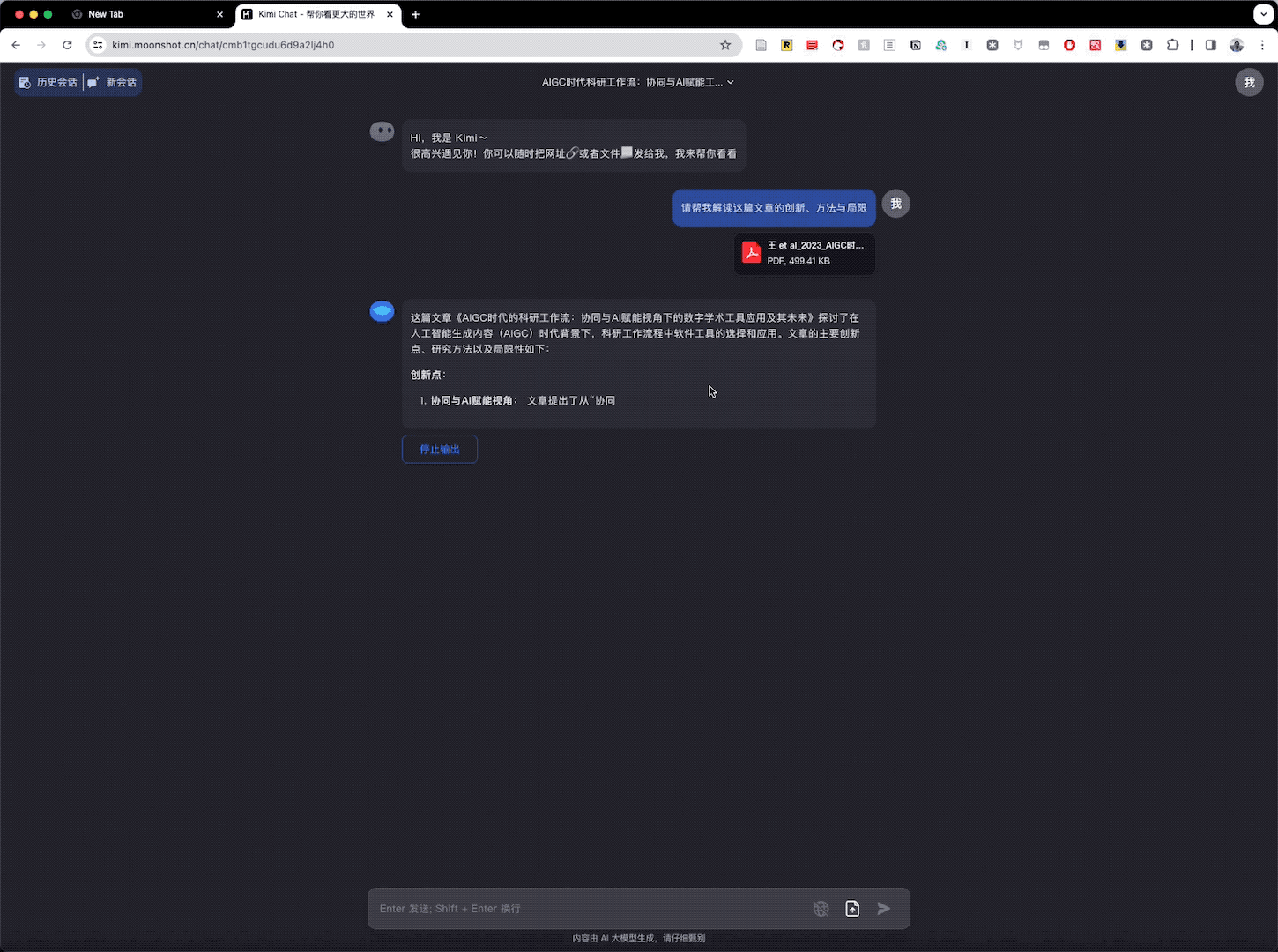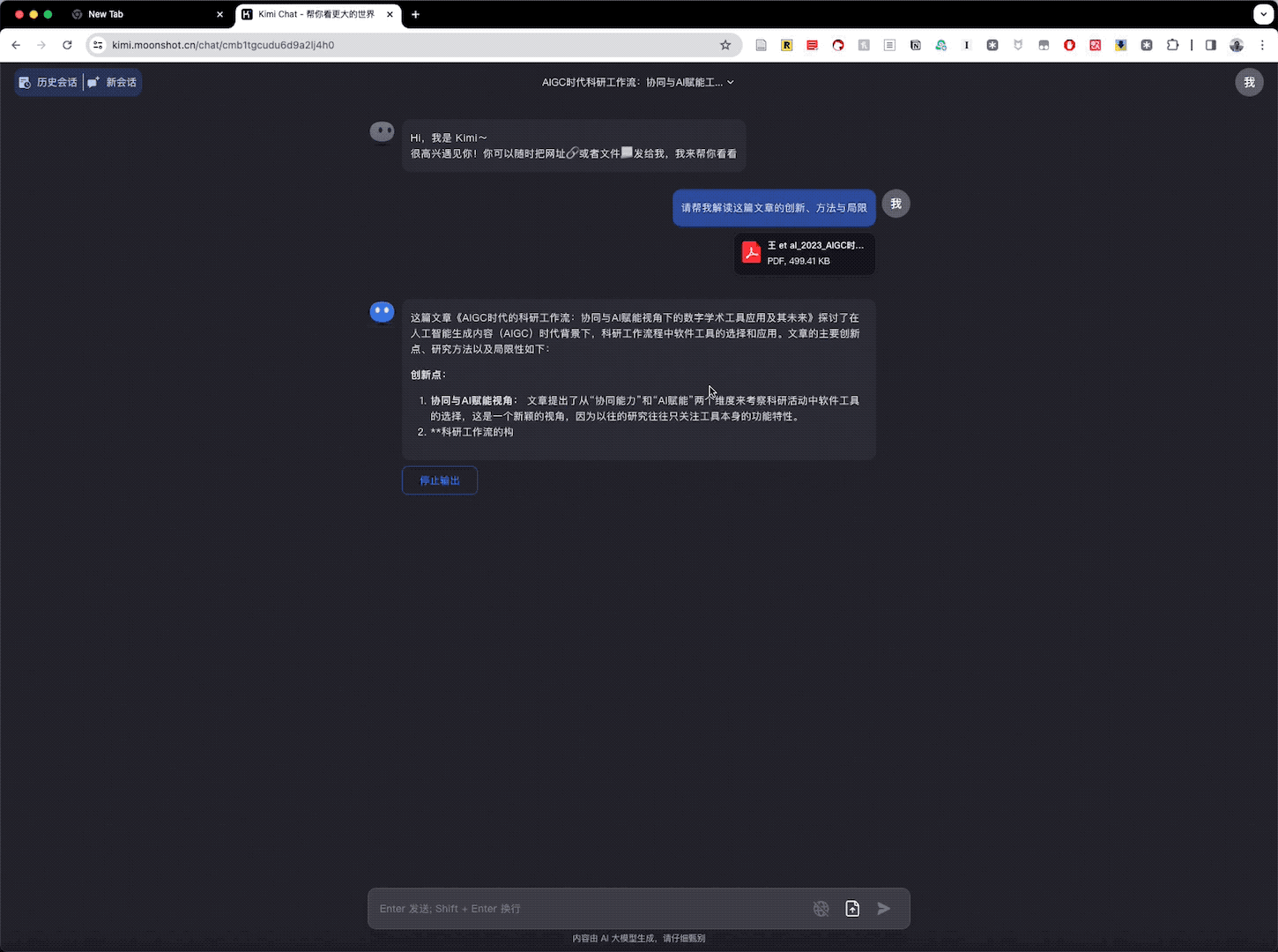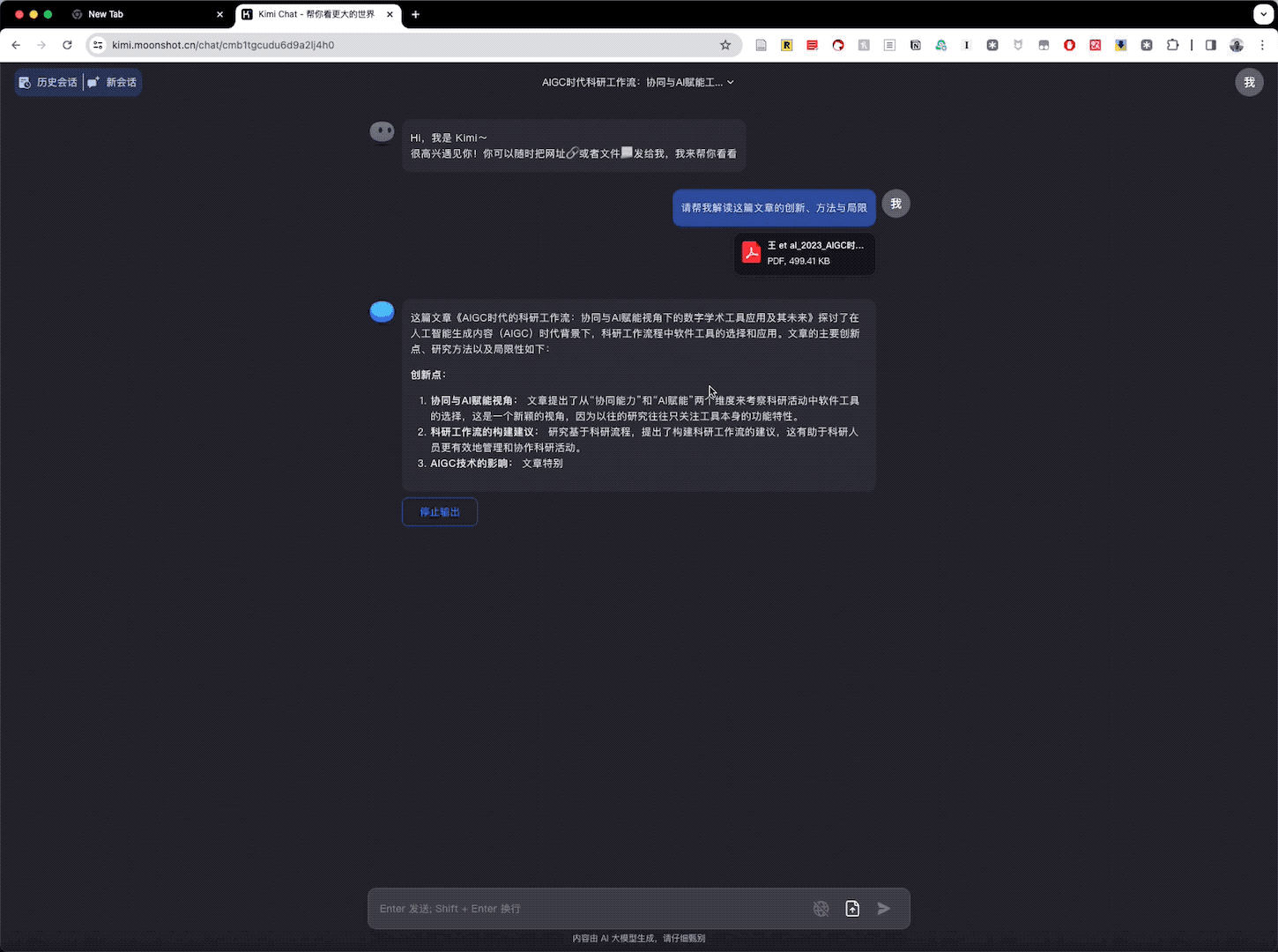
Kimi Chat 一上来提炼出了创新点。创新点包括「提出的新颖视角,科研工作流的构建建议,有助于科研人员更有效地管理和协作」。它特别提到了 AIGC 技术对科研工具发展的影响。此外,Kimi Chat 还提到通过两次调研对比,展示了 AIGC 技术对科研工具生态系统的显著影响。
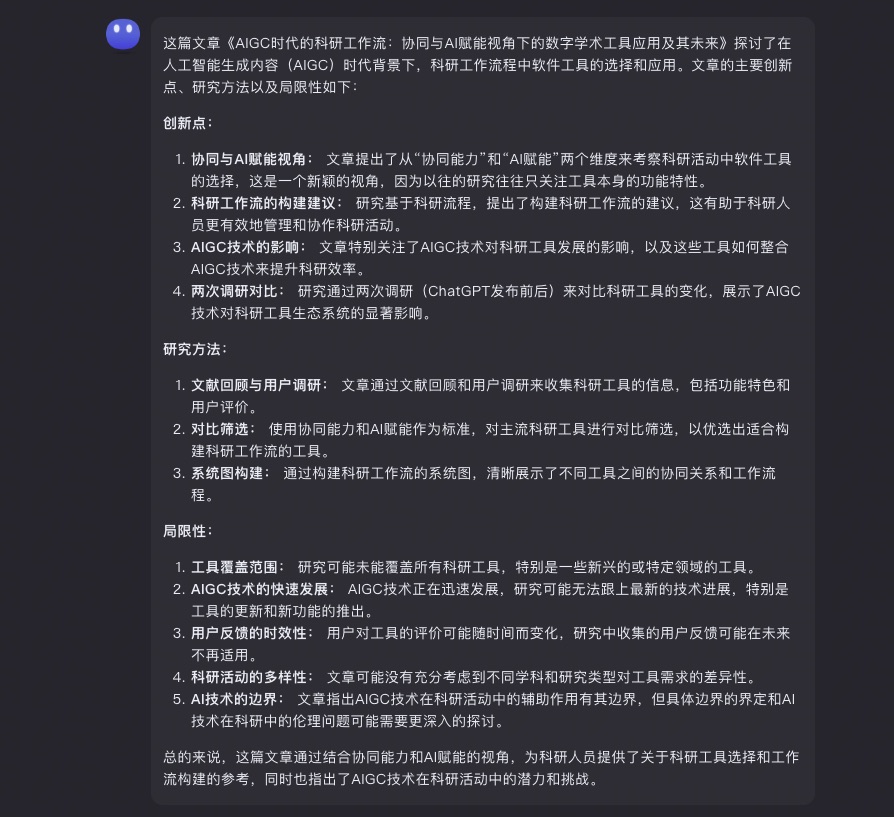
Kimi Chat 总结出的研究方法包括「文献回顾、用户调研对比和系统图的构建」,对我所使用的基础方法和工具的描述是准确的。
关于局限性,Kimi Chat 指出研究「可能未能覆盖所有科研工具。对于快速发展的 AIGC 技术,研究可能无法跟上最新的技术进展」。这确实是前沿领域研究的常见问题。Kimi Chat 还准确地指出了「用户反馈的时效性问题,以及科研活动的多样性和 AI 技术的边界等问题」。其中「用户反馈的时效性问题」确实是我之前自己的局限部分没有列出的,因而我认为 Kimi Chat 的总结和梳理很有帮助。
在尝试单篇文献之后,我继续测试了它综合处理多篇文献的能力。我找到了几篇与当前 AI 技术相关的论文,要求是对这些论文进行综述,并用 APA 格式撰写完整的文献回顾报告。

这是 Kimi Chat 的输出过程。
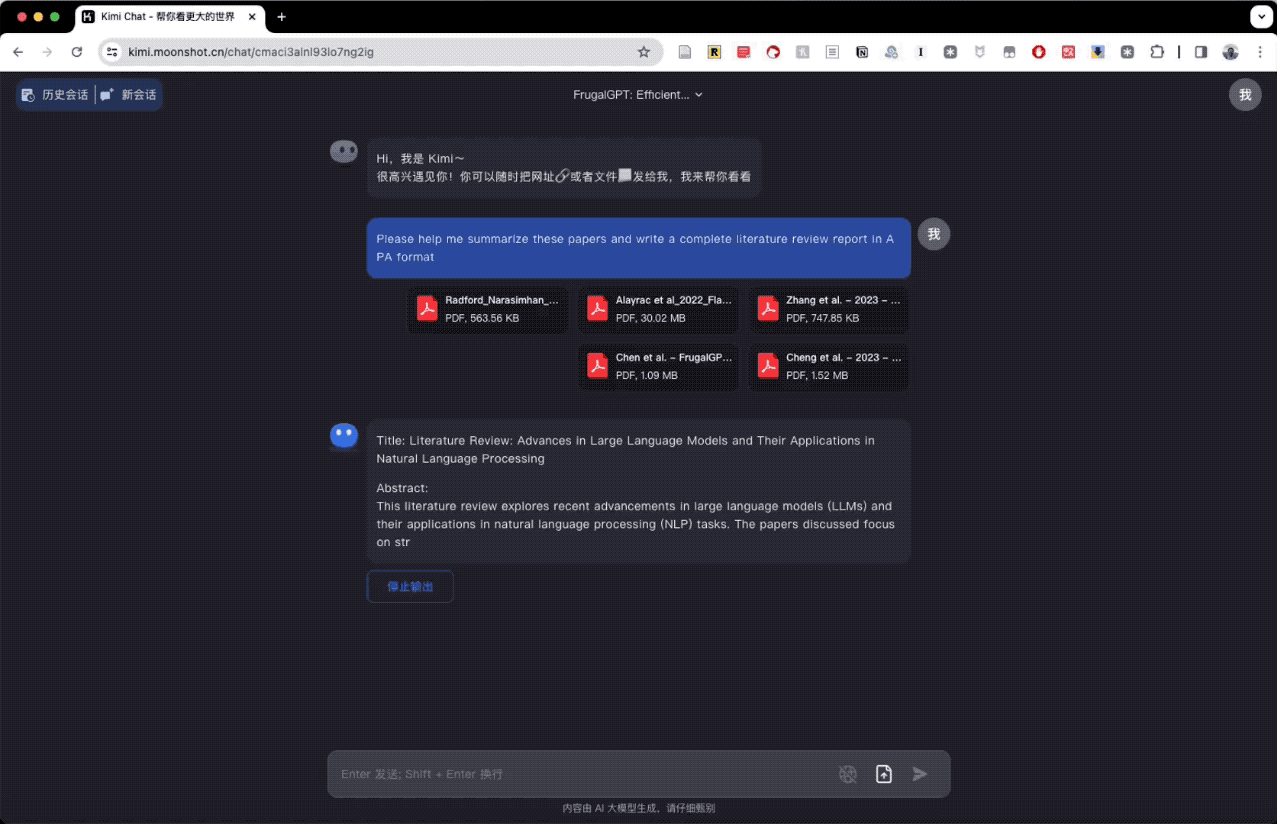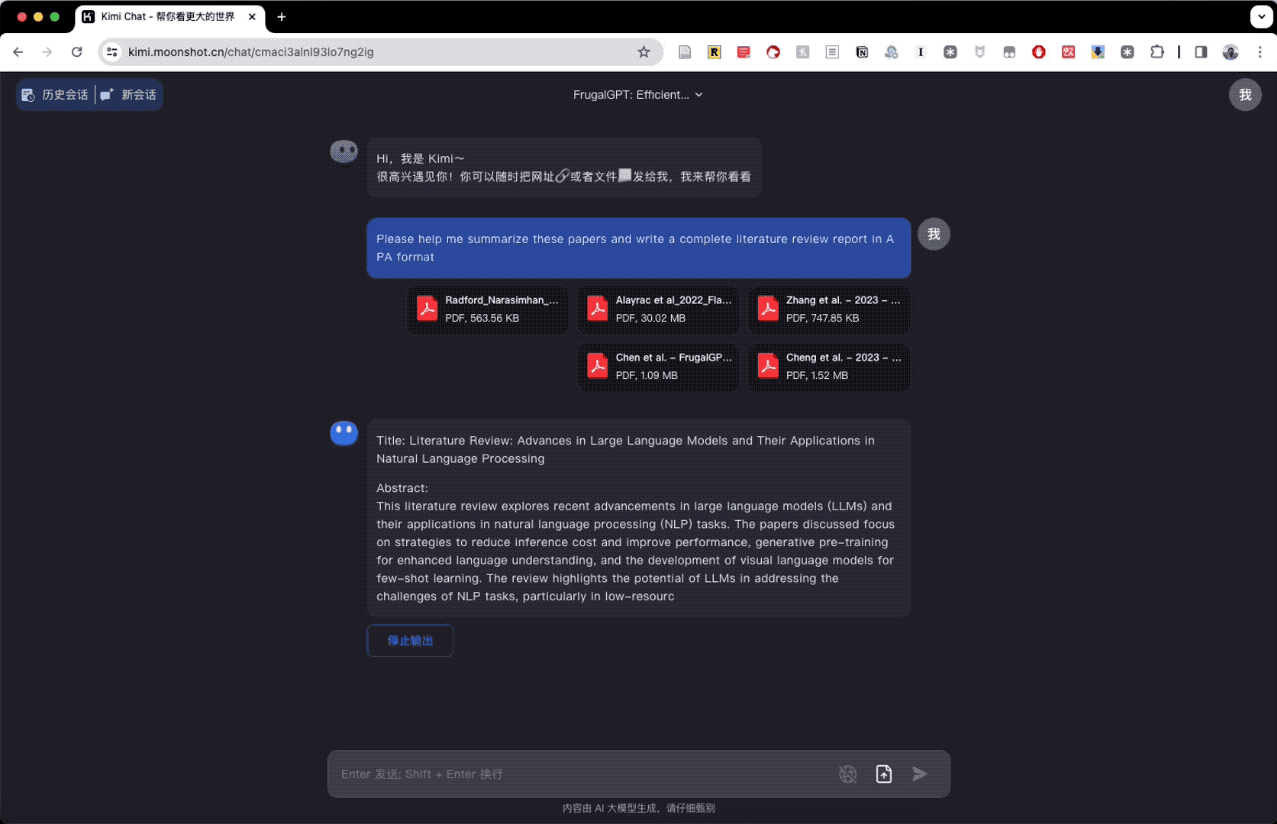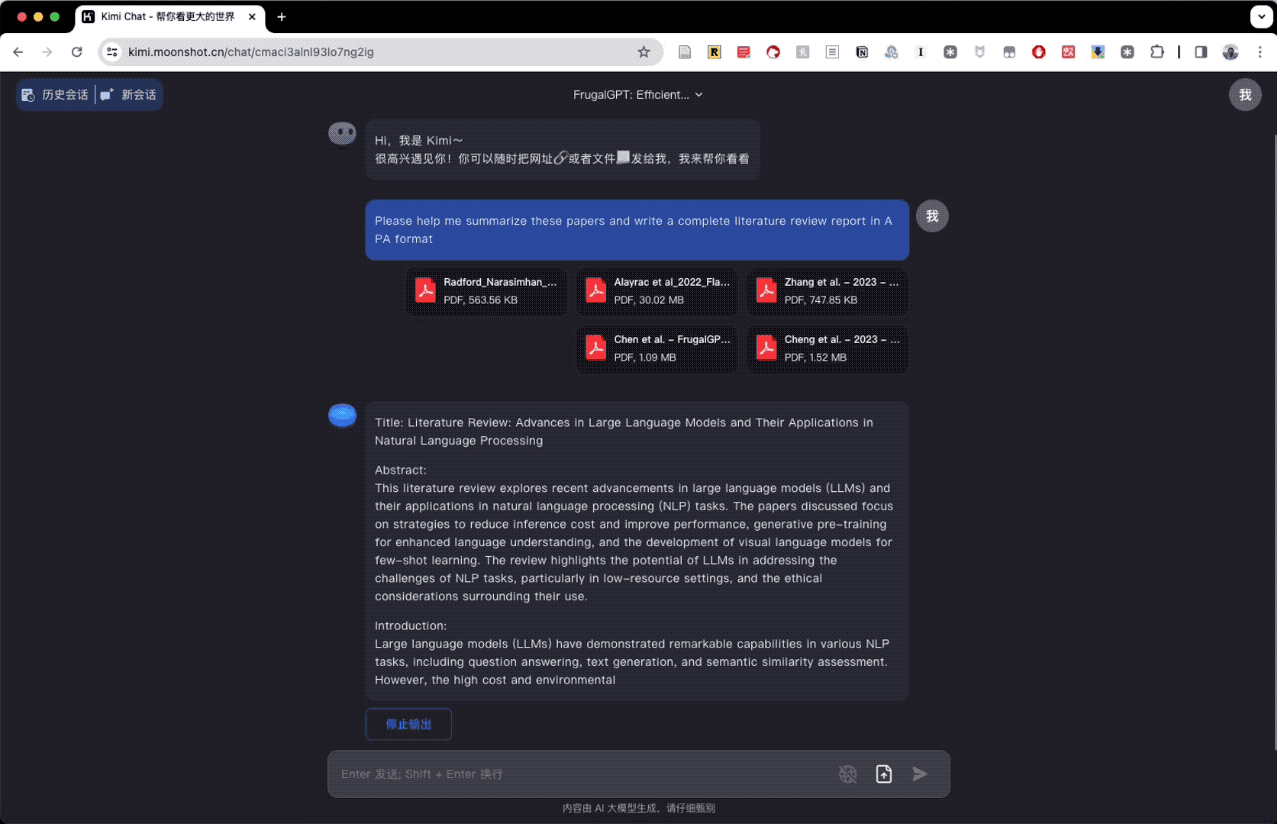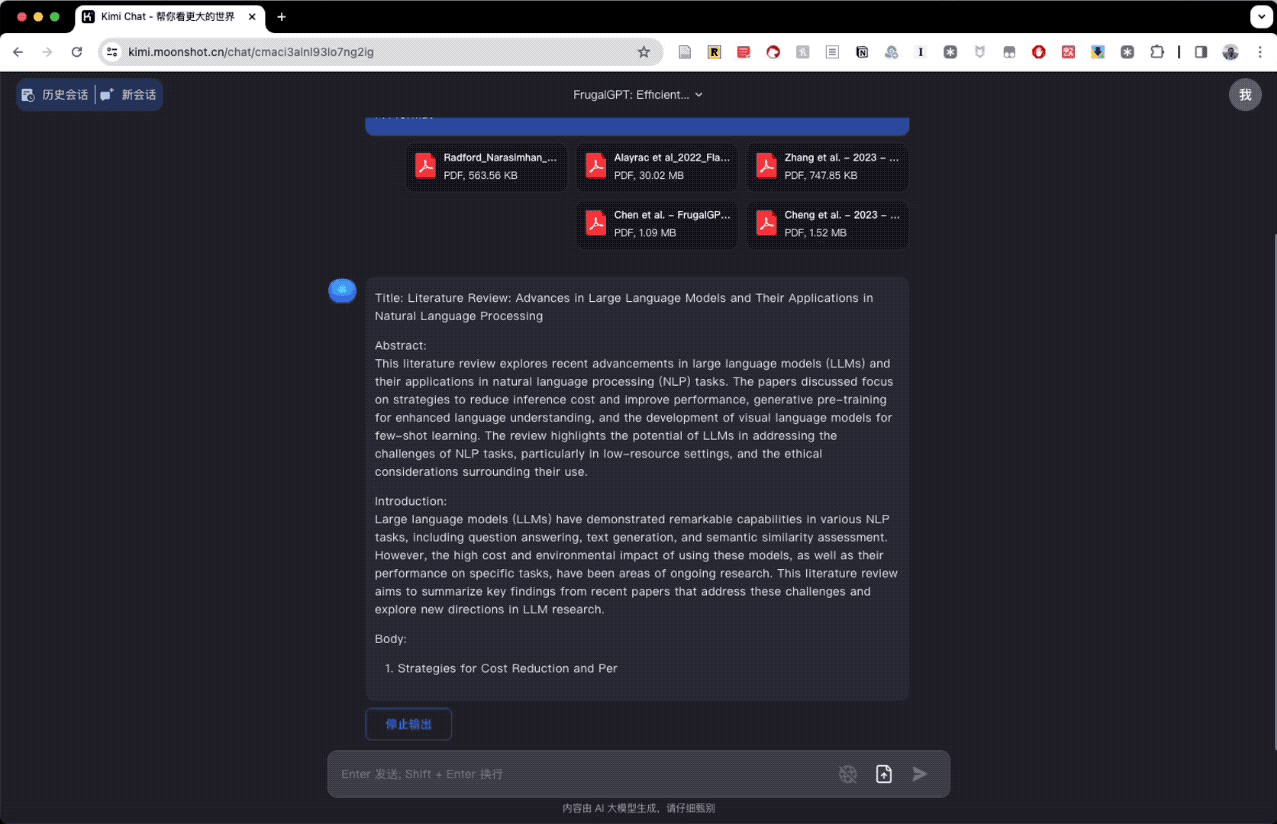
Kimi Chat 对这三篇论文的分析、讨论和结论都做得很理想。
但问题在于,我原本提交了五篇文献,Kimi Chat 却只分析了三篇。这可能是它目前在处理多文件综述时的一个缺陷,被我们捕获了。
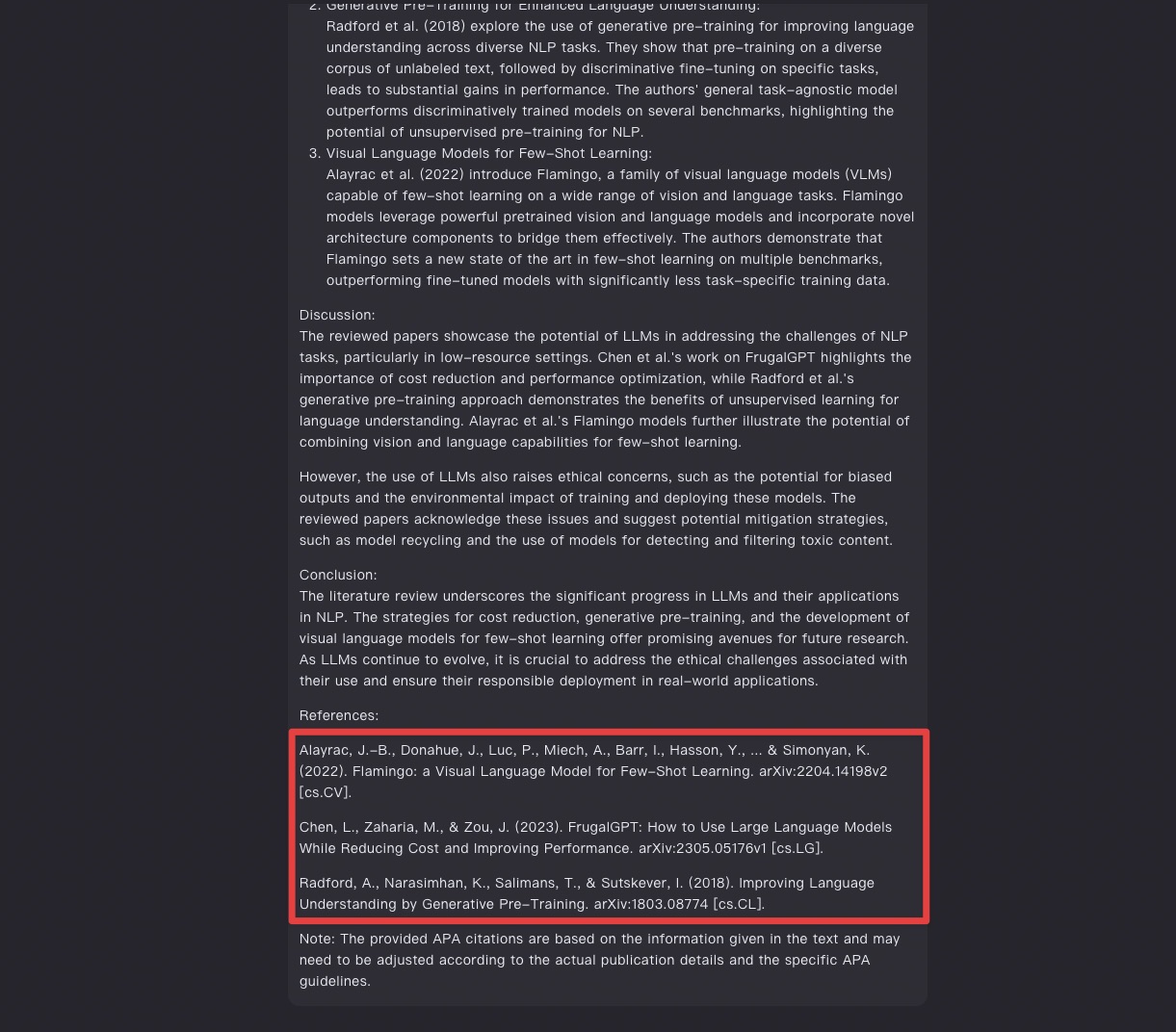
好在,咱们可以通过继续对话的方式,让它补齐。
我新的提示词为:
I asked you to summarize 5 articles, but you only summarized 3. You still need to summarize 2 more. Can you please think step by step and summarize them again without missing anything?
翻译成中文,就是:
我让你总结 5 篇,你总结了 3 篇,还差两篇,能否一步步思考,重新总结,不要遗漏?
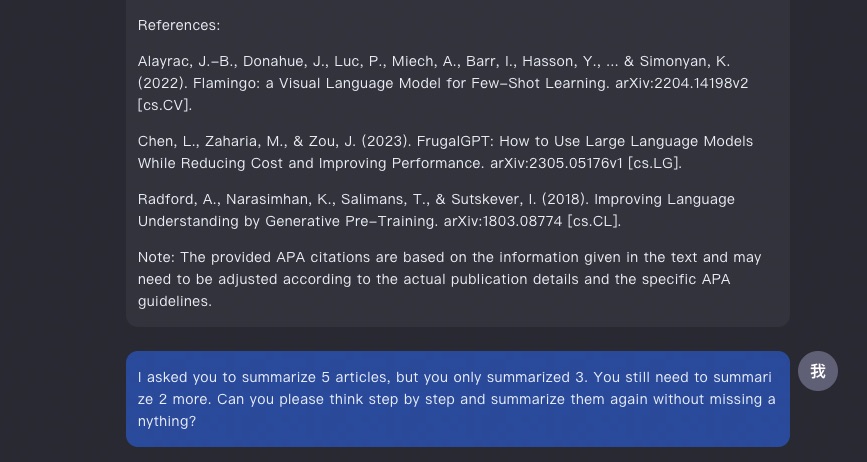
于是 Kimi Chat 立即开始思考,并且输出了以下答案:

经过检查,我发现这次的答案确实补充了前面遗漏的两篇文献。希望 Kimi Chat 后续的改进中,可以自动对输出文献数量进行检查核对,避免用户手动要求补充。
长文翻译接下来我们来讨论 Kimi Chat 的文章翻译能力。我最近尝试了很多长文翻译的方法,其中一个较好的方法是宝玉老师提出的「两遍翻译法」。

第一遍是直译,保留原文的细节;第二遍则是在直译的基础上进行意译。这个方法很有创意,效果也很好。在 GPT-4 对话中,我要求它逐段进行翻译。这样尽可能避免了 GPT-4 对上下文的混淆、遗漏和误解。
这次,我把自己多日以来摸索出来的一整套 GPT-4 翻译长文提示词直接提供给了 Kimi Chat。它接受后,请我提供文章。

作为样例,我提交给了 Kimi Chat 一篇我自己写的中文公众号文章《过去这一年,我有哪些离不开的效率工具?》。提交的格式为 Markdown,里面包括了正文、链接和图片等。
这里,我给你展示一下,在 GPT-4 环境下这种逐段的翻译效果是怎样的。
Kimi Chat 立即开始工作了。
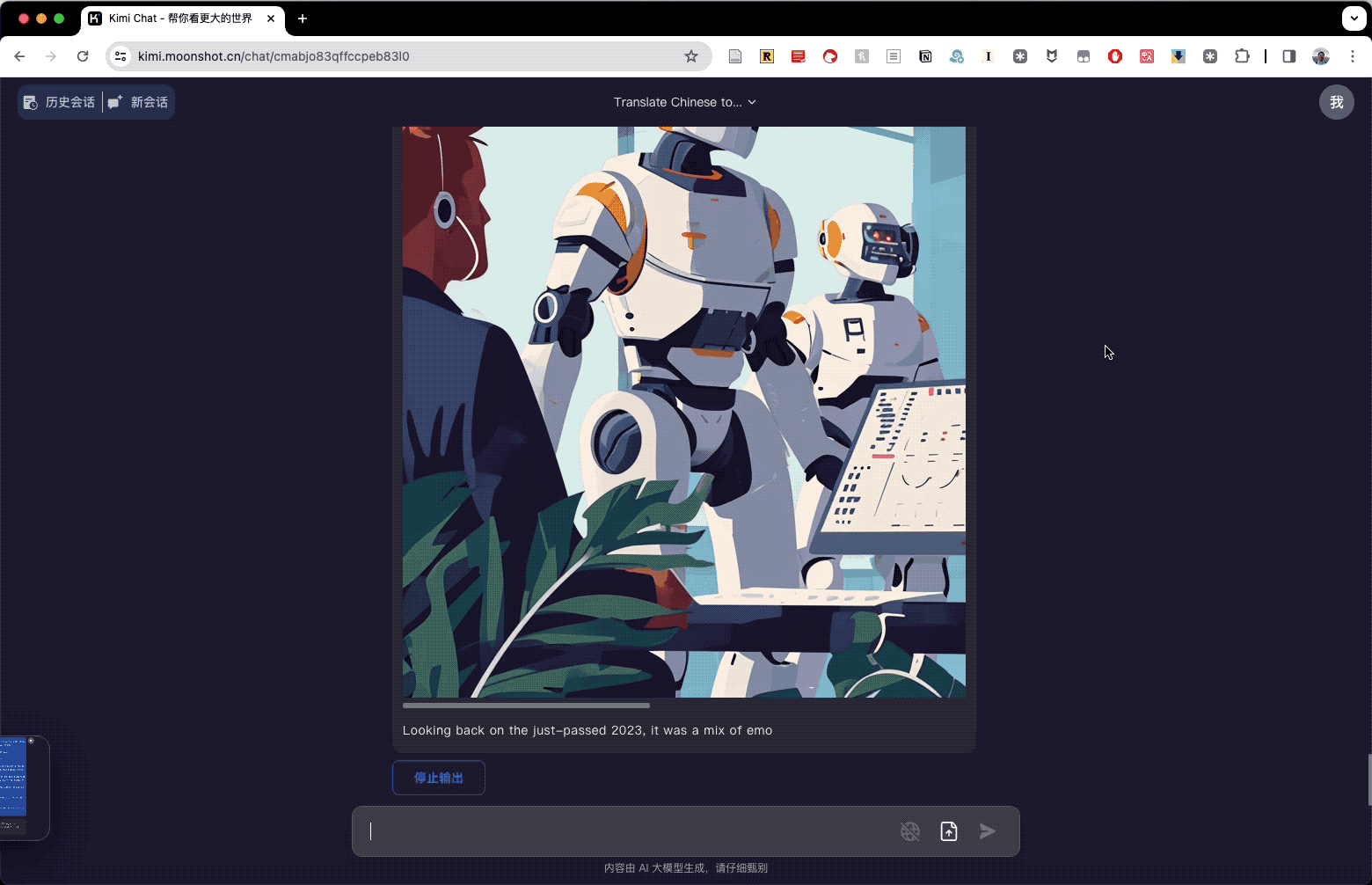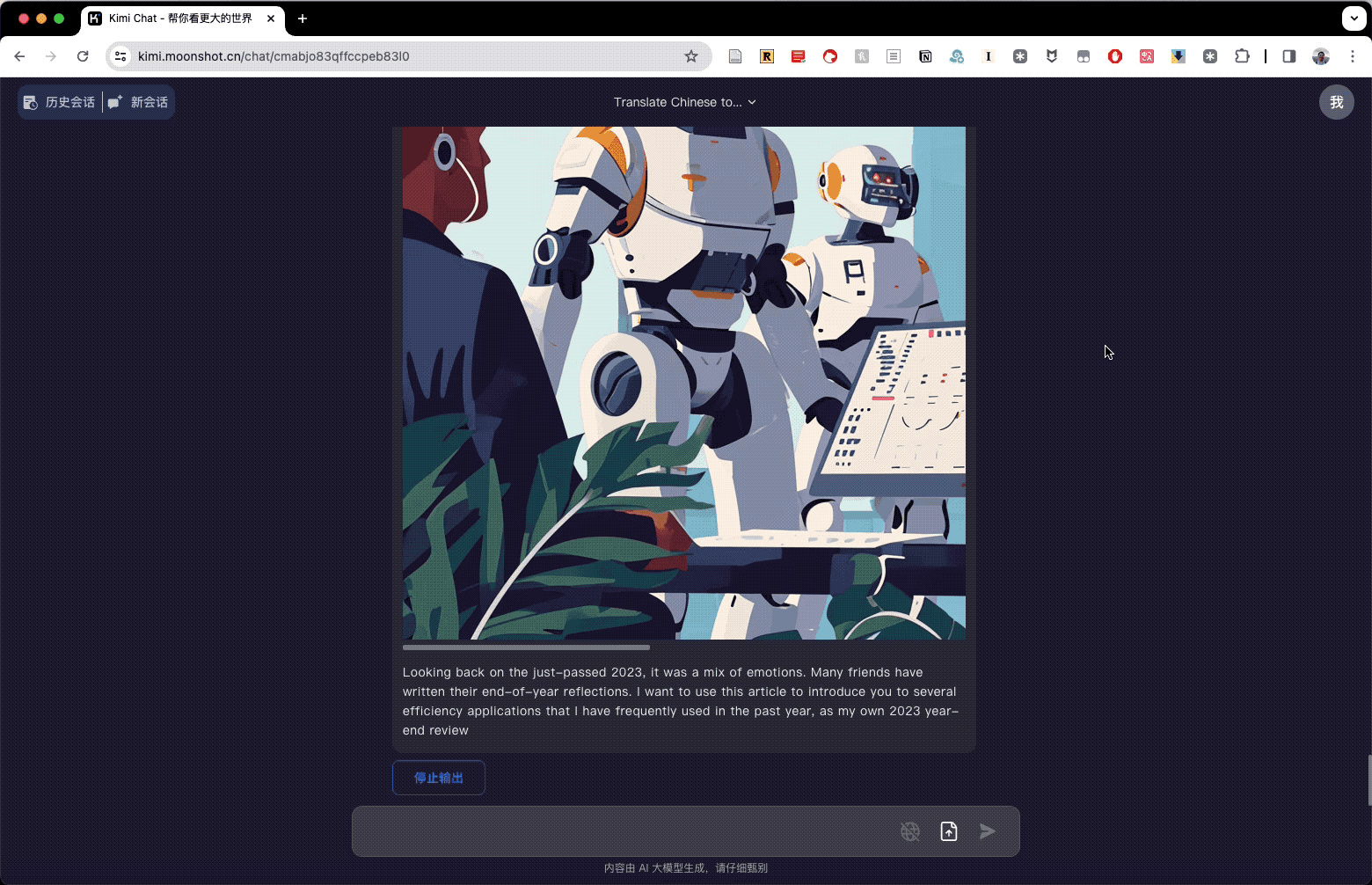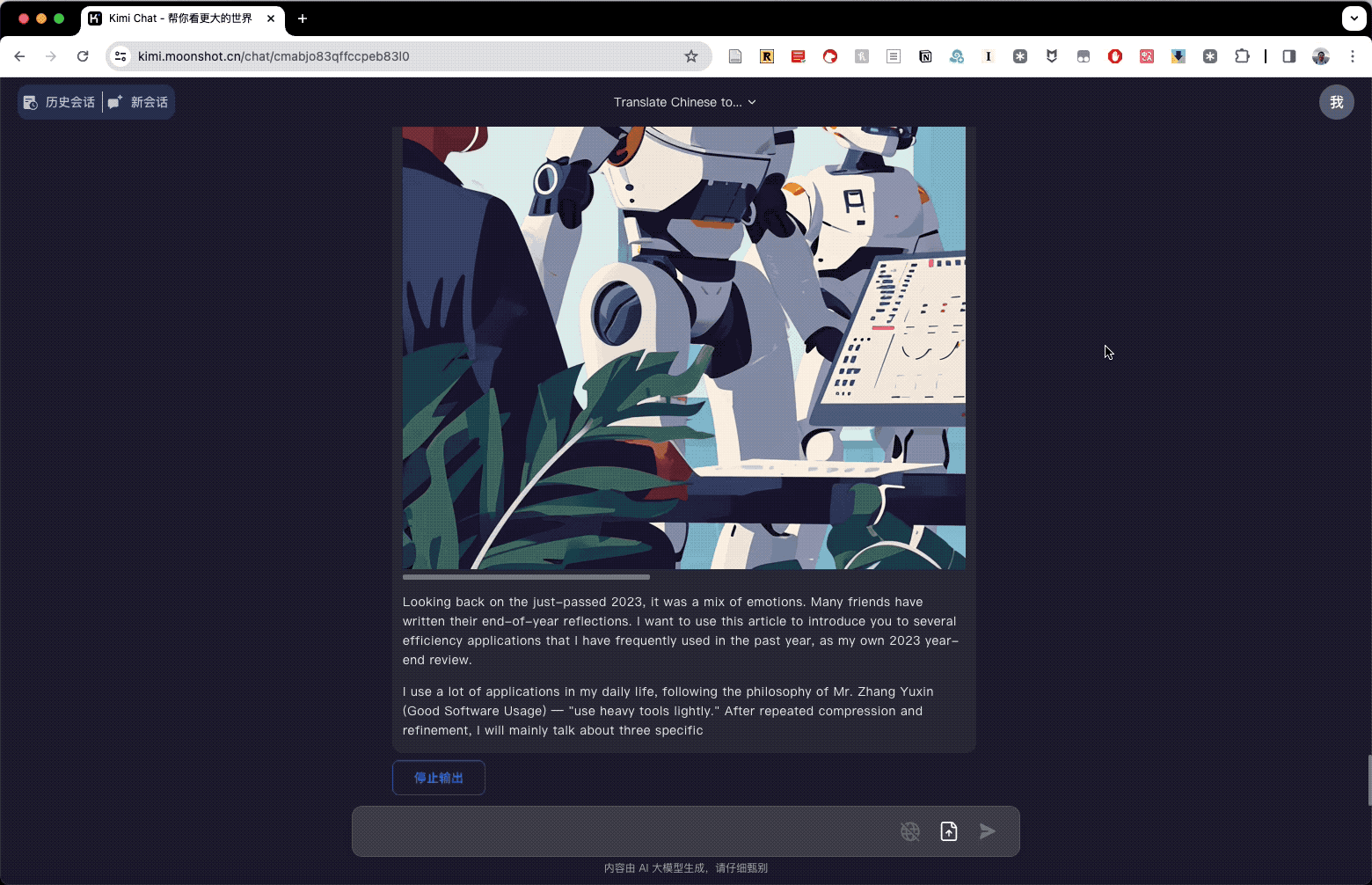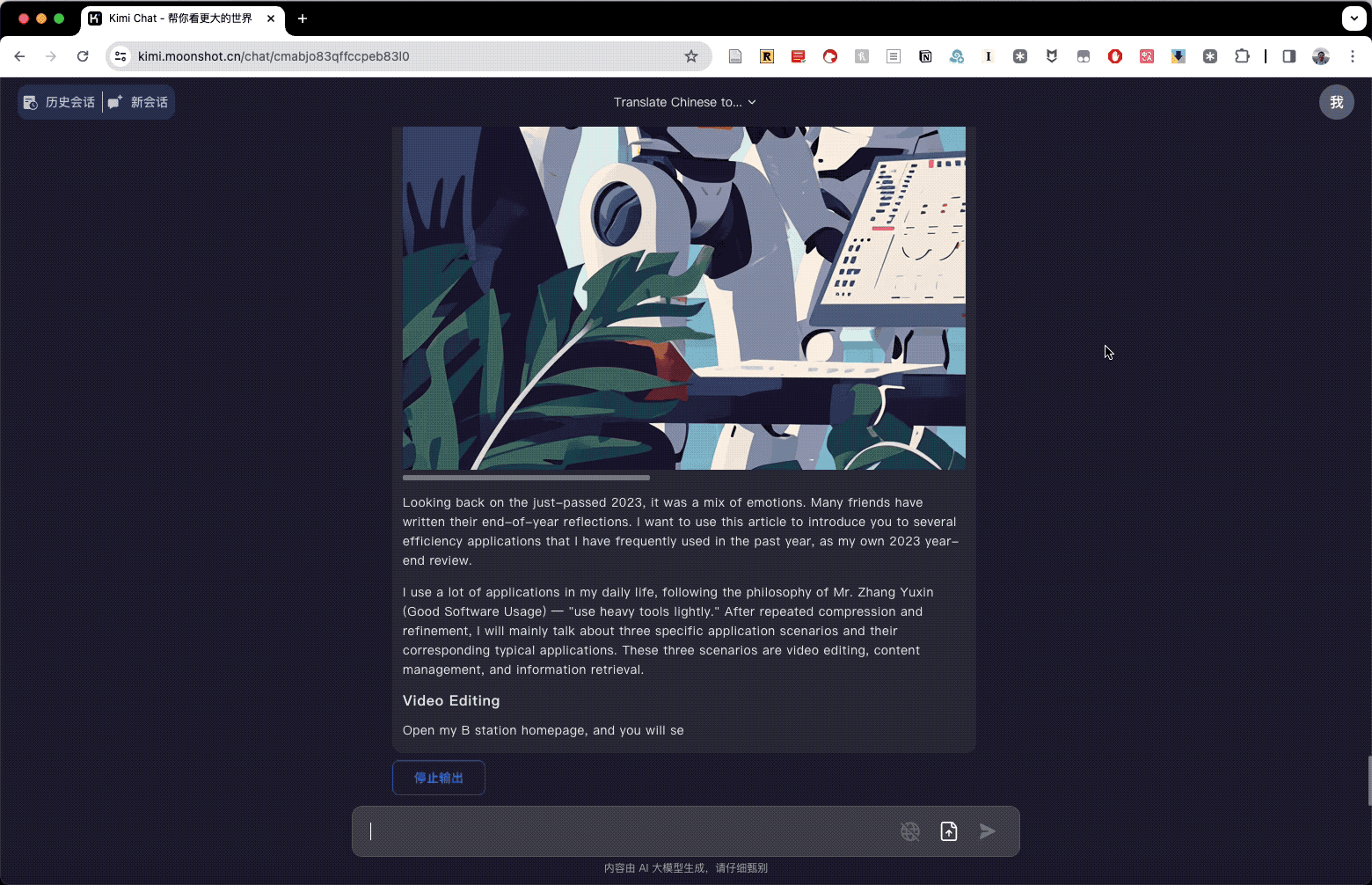
起初,我对 Kimi Chat 输出的结果感到非常失望 —— 我原本希望看到的是逐段进行的两遍翻译,即每一段输出原文,然后先直译后意译的过程。但实际上,我只看到了 Kimi Chat 一次翻译的结果,没有原文,也没有意译。这让我很不满意。
然而,从第一性原理思考,我突然意识到之前需要逐段翻译是因为 GPT-4 一段对话中可以处理的上下文不够长。只有分段进行,才能保证 GPT-4 对原文记忆和理解的准确性;可是现在我使用了 Kimi Chat,它的特点就是对超长上下文具备强记忆能力,那逐段翻译是否还有必要呢?于是我踏踏实实看着 Kimi Chat 先把翻译结果输出完。
值得注意的是,尽管目前 Kimi Chat 可以接受 20 万字中文的输入长度,但是输出的时候,窗口虽大,却不能一次性把翻译结果完整输出。中间停顿了一次。
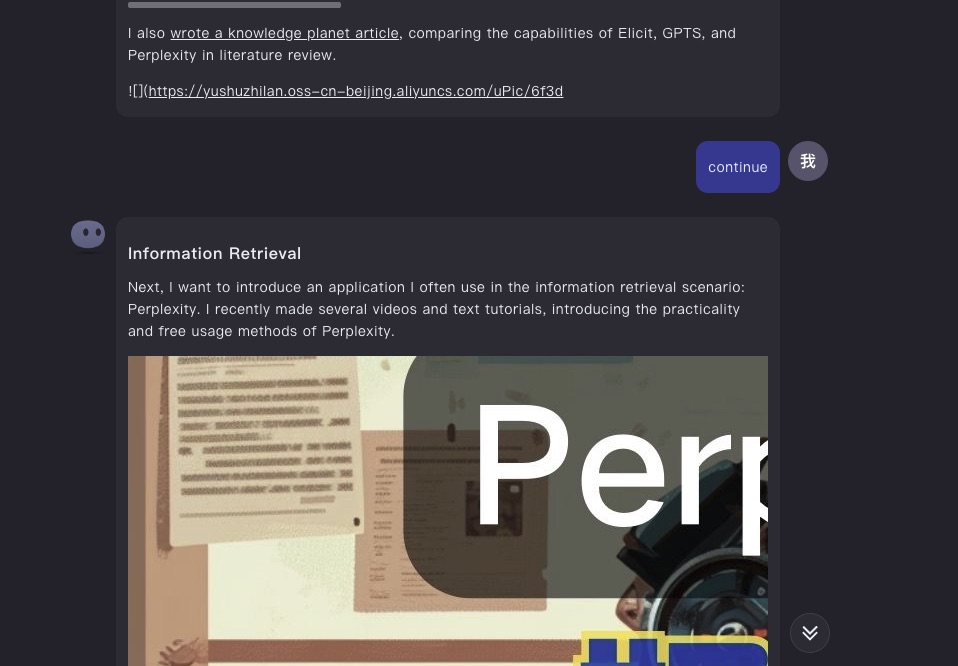
当我让 Kimi Chat 继续时,它能从上一个段落的小节标题处开始继续输出,这非常有趣。因为这意味着 Kimi Chat 在回顾截断处上下文的时候,确实对结构能清晰把握。这可能就是点开「超长上下文」这棵技能树之后,带来的直观好处吧。
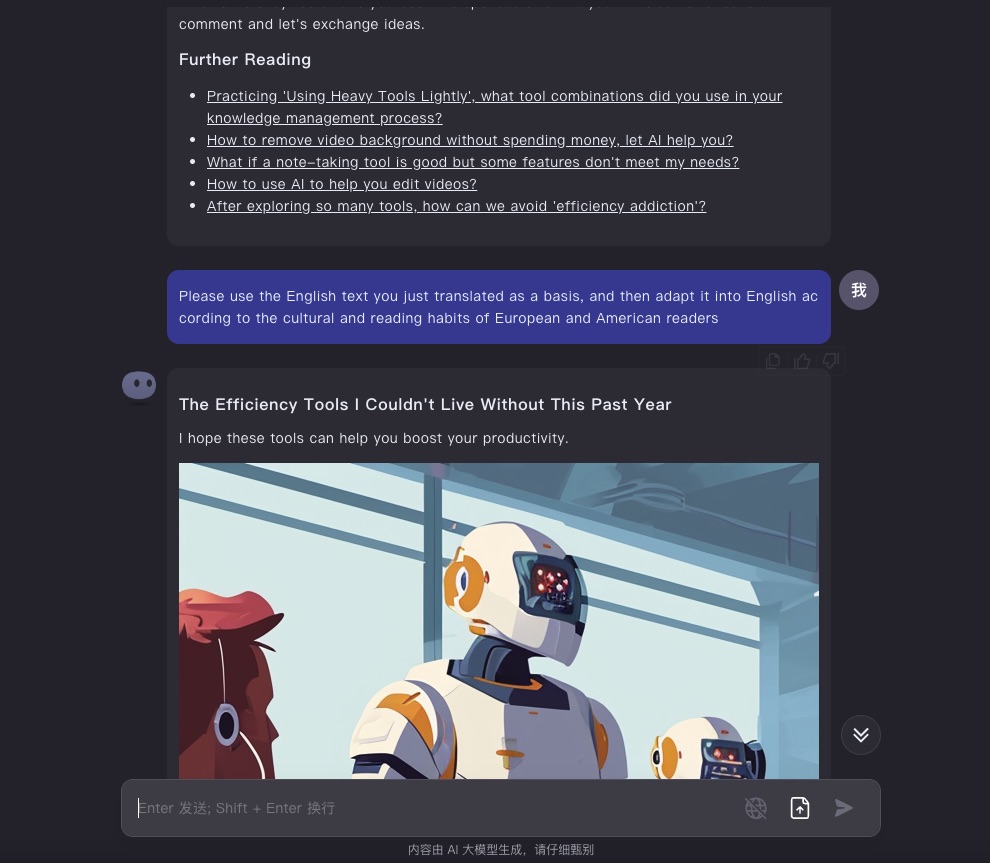
在完成直译后,我指示 Kimi Chat 对刚刚的直译结果进行整体意译。我害怕它听不懂指令,把原文再抄写一遍。好在经过对比,一眼看上去,它就将第一遍直译输出的 “for example” 译为了 “for instance”。这表明它确实理解了要求,真正进行了第二遍翻译。
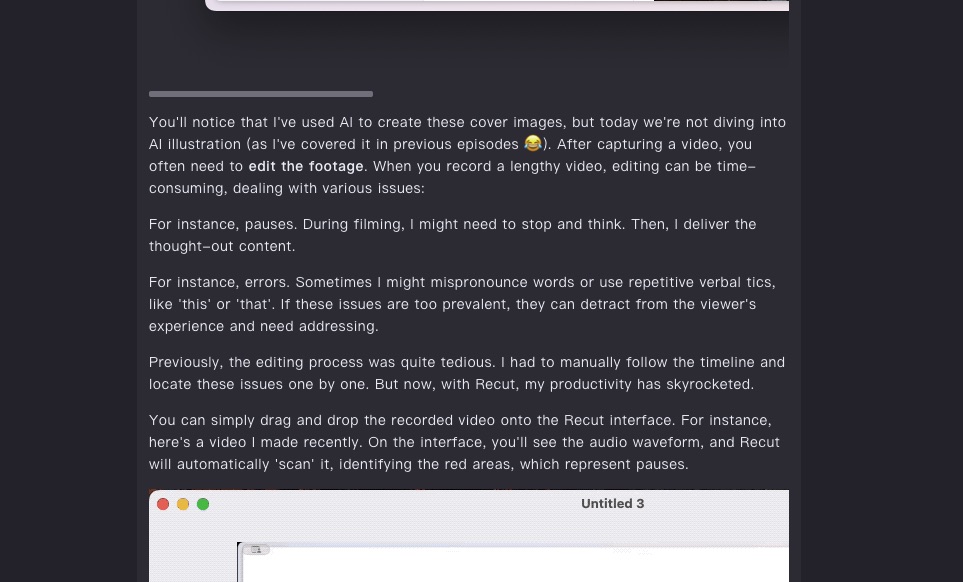
我注意到它在输出全部意译结果的时候,依然能从中断处整节恢复输出。这说明它对上下文结构的理解非常精确。
最终 Kimi Chat 完成了所有的输出,我对比了一下,发现翻译质量已经足够满足我的需要。
这意味着以后进行长文中译英翻译时,我不再需要像以前那样麻烦。我只需要先让 Kimi Chat 进行整体的直译,然后再进行整体的意译,效果已经非常理想。此外,Kimi Chat 的输出中,所有的链接和图片(包括动图)都被完整地保留,这非常方便。
与之相对比,在进行翻译时,GPT-4 有时会在最终输出阶段丢失一些内容。我在 Typingmind 和 ChatGPT 官方对话中,都遇到过类似的问题。例如这是某次整合输出全部译文的结果:
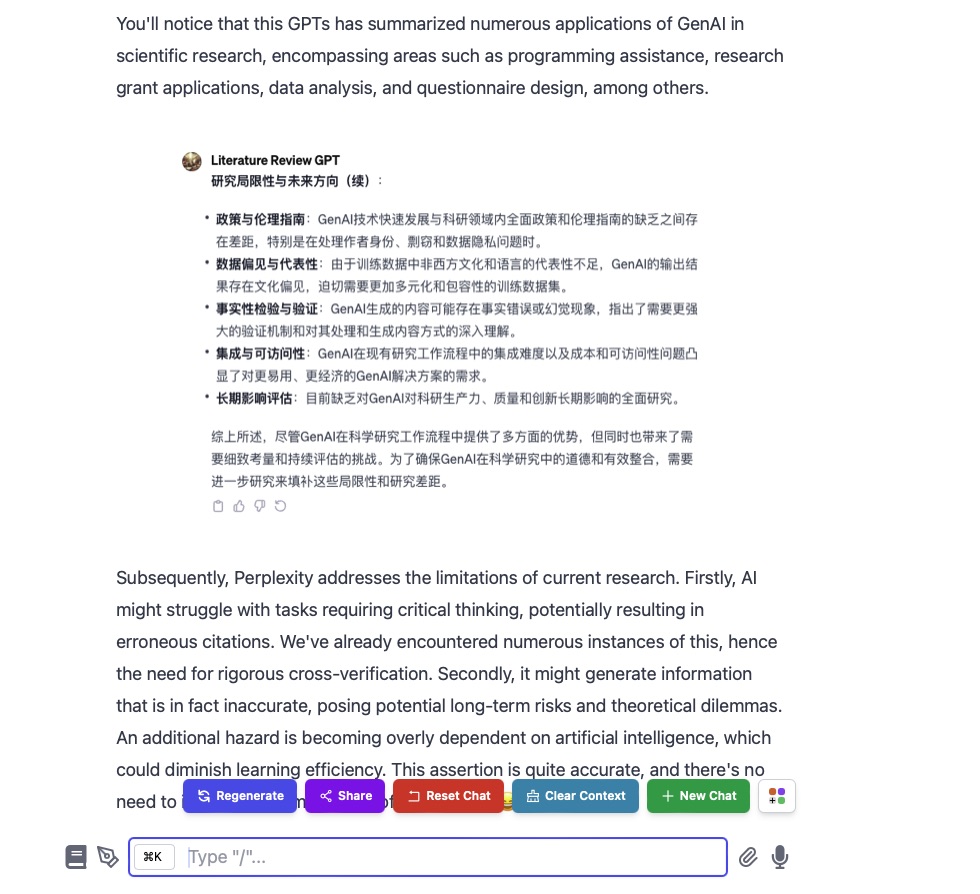
比如,在讨论 GPTs 效果的部分时,翻译结果突然跳到了后面 Perplexity 的部分,中间丢失了很多段落的内容。
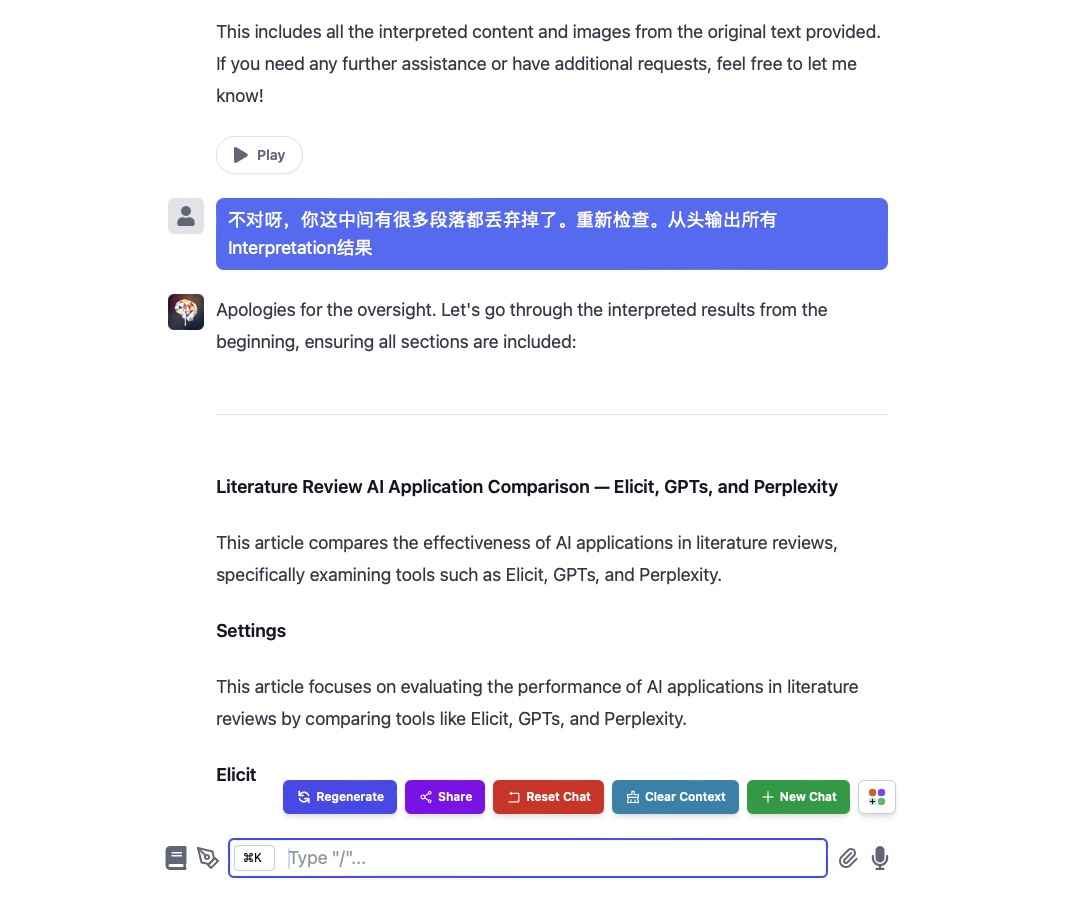
我需要使用提示词来纠正这些丢失,有时甚至需要告诉它具体哪些部分遗漏了,要求 GPT-4 补充。
然后,我会发现 GPT-4 给出的补充结果仍然会有遗漏,不得不逐个进行提示。
最后,我还需要手动找到正确的上下文位置并填充。因此,在进行长文翻译时,目前 GPT-4 实际上不如 Kimi Chat 方便。
小结我们来总结一下刚才的三个用例:网络文章总结、学术文献分析,以及长文翻译。我们从这些实际用例中得到了哪些结论呢?
第一个结论是,超长对话窗口确实可以有效减少对话的中断,使整个工作流程更加流畅;第二个结论是,Kimi Chat 记忆力更强,使得输出过程不至于忘记中间段落,避免了大量的人工检查、提示与手动补充。
不过,通过尝试,我也发现了 Kimi Chat 的一些问题。比如在指令理解方面,我认为 Kimi Chat 还有改进空间,例如我明明要求逐段处理,它却一次性整体输出了;另外在处理所有输入的 PDF 时,它第一次也遗漏了 5 篇中的 2 篇文献。好在我相信随着模型的快速迭代,这些问题会得到有效解决。
这款应用目前是免费的。注册和使用都非常简单,只需要手机验证。为什么不立刻尝试一下呢?
欢迎你把自己的尝试结果,分享在留言区。我们一起交流讨论。
如果你觉得本文有用,请点赞。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读https://blog.sciencenet.cn/blog-377709-1417462.html
上一篇:过去这一年,我有哪些离不开的效率工具?
下一篇:智谱 GLM-4 大语言模型好用吗?