对于学生用户来说,这可是个好消息。

开源从前人们有一种刻板印象——大语言模型里好用的,基本上都是闭源模型。而前些日子,Meta推出了Llama3后,你可能已经从中感受到现在开源模型日益增长的威力。当时我也写了几篇文章来介绍这个系列模型,例如这一篇《如何免费用 Llama3 70B 帮你做数据分析与可视化》,很受欢迎。

最近阿里推出了新一代的开源大语言模型 Qwen2。同样是一个系列 —— 从非常小不到 10 亿参数的模型,一直到 72B (也就是 720 亿)参数的中型模型。因为信息比较多,我干脆让 Perplexity 给我对 Qwen2 的信息做了个汇总。

Perplexity 说,Qwen2 系列模型规模大,多语言能力强,并且在编程、数学等领域提升非常明显,且支持超长上下文。最后这一点,我觉得它比 Llama 3 的表现要好。
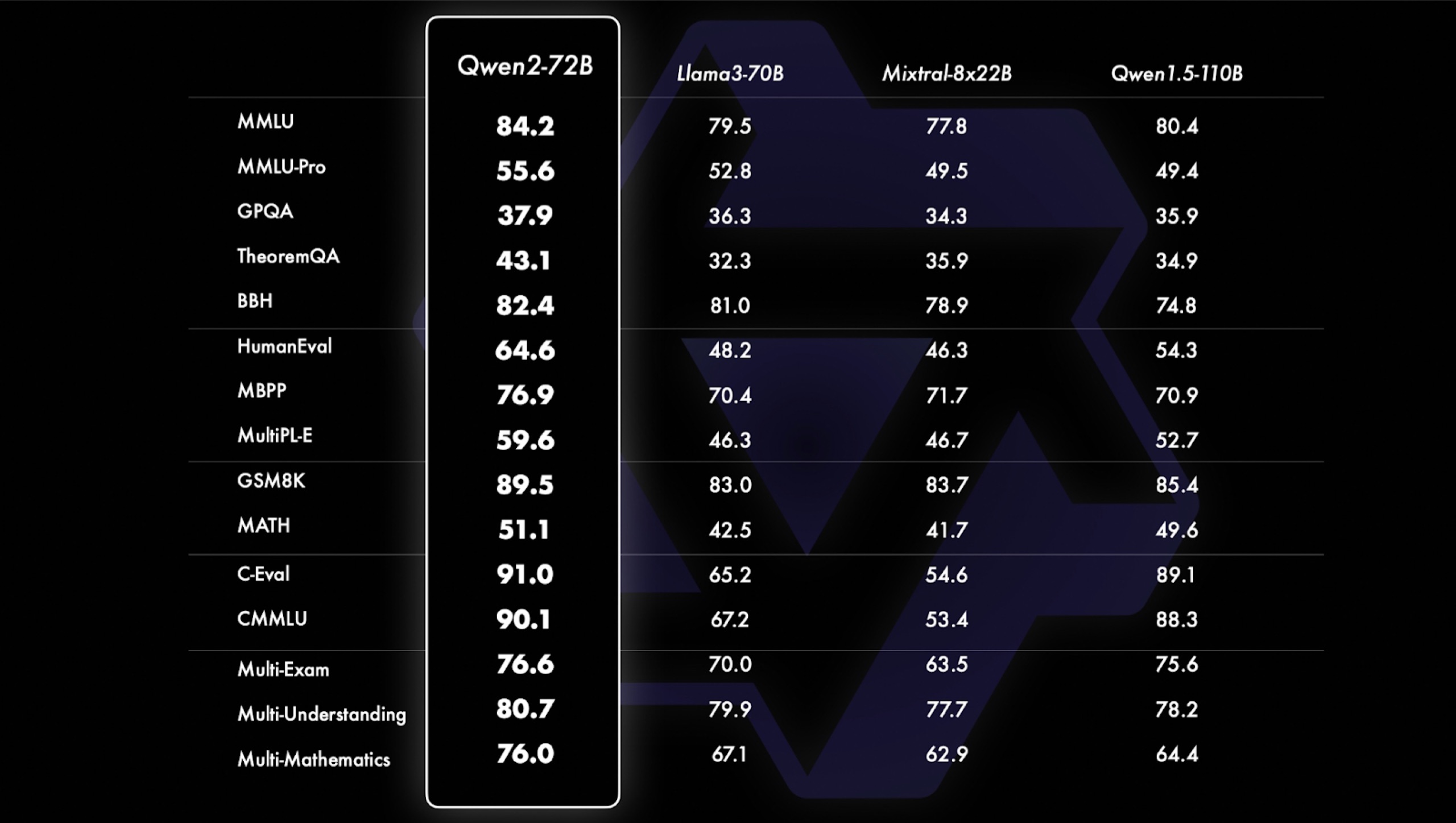
我这里拿了一张 Qwen2 发布会时的图,它展示了 Qwen2 的 72B 与 Llama3 的 70B 以及 Mixtral-8x22B 混合专家模型间的对比。Qwen2 相较于后者,在每一个指标上都有提升。
当然,我们不能光看数据对吧?这篇文章,咱们得动手实践获得一手认知。首先,咱们来试试本地运行。
尝试考虑到本地机器计算能力限制,我们选一个小一点的模型,也就是 Qwen2 的 7B 模型。这里我使用 Ollama 来运行它。关于 Ollama 的介绍,可以参考这篇文章。
我们执行指令:
ollama run qwen2
Ollama 会立即自动下载模型。
下载好后,你就可以直接跟它对话了。
我提的问题是:
帮我写个 Snake Game in Python。
你可能会问,为什么指令写得这么奇怪?你要么说中文,要么说英文,为什么中英文混用呢?
答案是我故意的因为Qwen2号称多语言能力比较强,所以我们先让它试试这种混用看效果怎么样。
测试结果来看,Qwen2 对中英文混合的 prompt 理解效果挺好。它不仅懂了我的意思,还直接开始基于 Pygame 来输出 Python 代码。

代码完整输出完后,Qwen2 还会告诉用户怎么用。

我于是先按照它的要求把 Pygame 安装上。
之后,我把 Qwen2 生成的代码贴到 Visual Studio Code 里面,再执行。
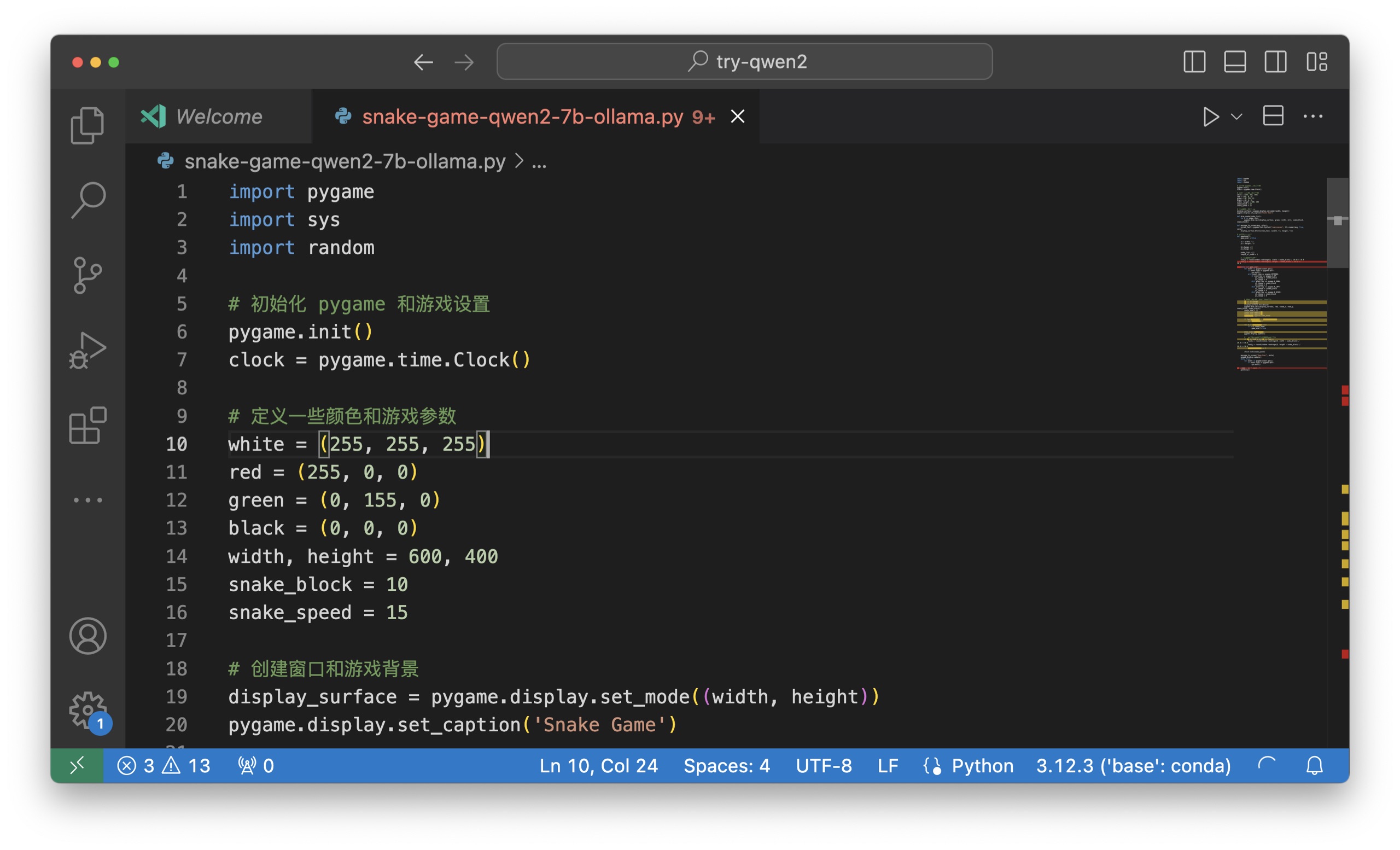
这是运行的效果。我试玩儿了好一会儿。

你不难发现,「人工智能」挺智能的,可以快速编出这样的程序;反倒是玩儿游戏的这家伙,看上去似乎不怎么智能 😂
7B 的小型版本可以在本地运行,那么目前最大的 72B 版本 Qwen2 怎么运行呢?要想本地运行也不是不可以,不过对硬件要求相对较高。
咱们可以使用 API 来调用。只不过,API 是要花钱的。
幸好,我看到了 Orange.ai 网友推荐的免费使用方法,分享给你。

环境我们要使用的服务是 Siliconflow ,它类似于我 之前给你介绍过的 Open Router 以及 Together AI。原理都是集成多种不同的模型。然后你可以用一个密钥,调用任意它支持的模型。那感觉,就像进了自助餐厅一般。
你需要先注册一个账户,用手机号码和验证码即可。注册完之后,你会发现 Siliconflow 已经赠送你 42 块钱额度。
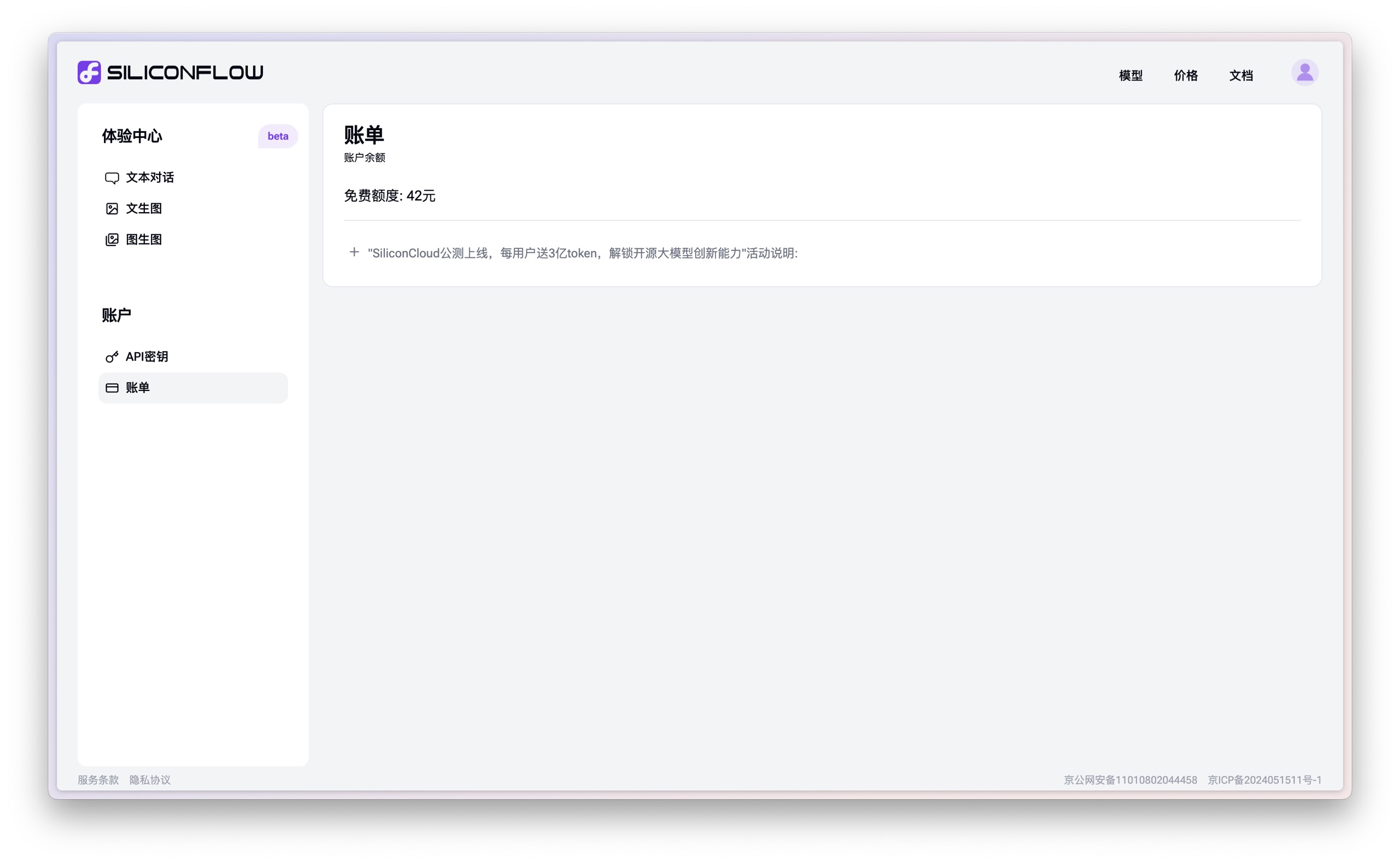
如果你之前早已习惯用 Claude 3 Opus 以及 GPT-4o 这样的模型,可能会觉得 42 块钱能干什么?一会儿不就用没了?
别急,我们现在用的是 Qwen2 模型。价格的差别嘛,你一会儿就能感受到。
我们先把 API 的密钥拿下来。左边栏账户下面有个专门的栏目叫 「API 密钥」,点击之后你可以直接创建一个新的密钥并且复制。

咱们闲言少叙,直接介绍用 Siliconflow + Qwen2 执行两个非常实用的功能,分别是翻译和数据分析。
翻译我们这里调用一个 Chrome 浏览器的插件叫 Immersive Translate。我在这篇文章里介绍过它。此处,咱们点开它的设置页面。
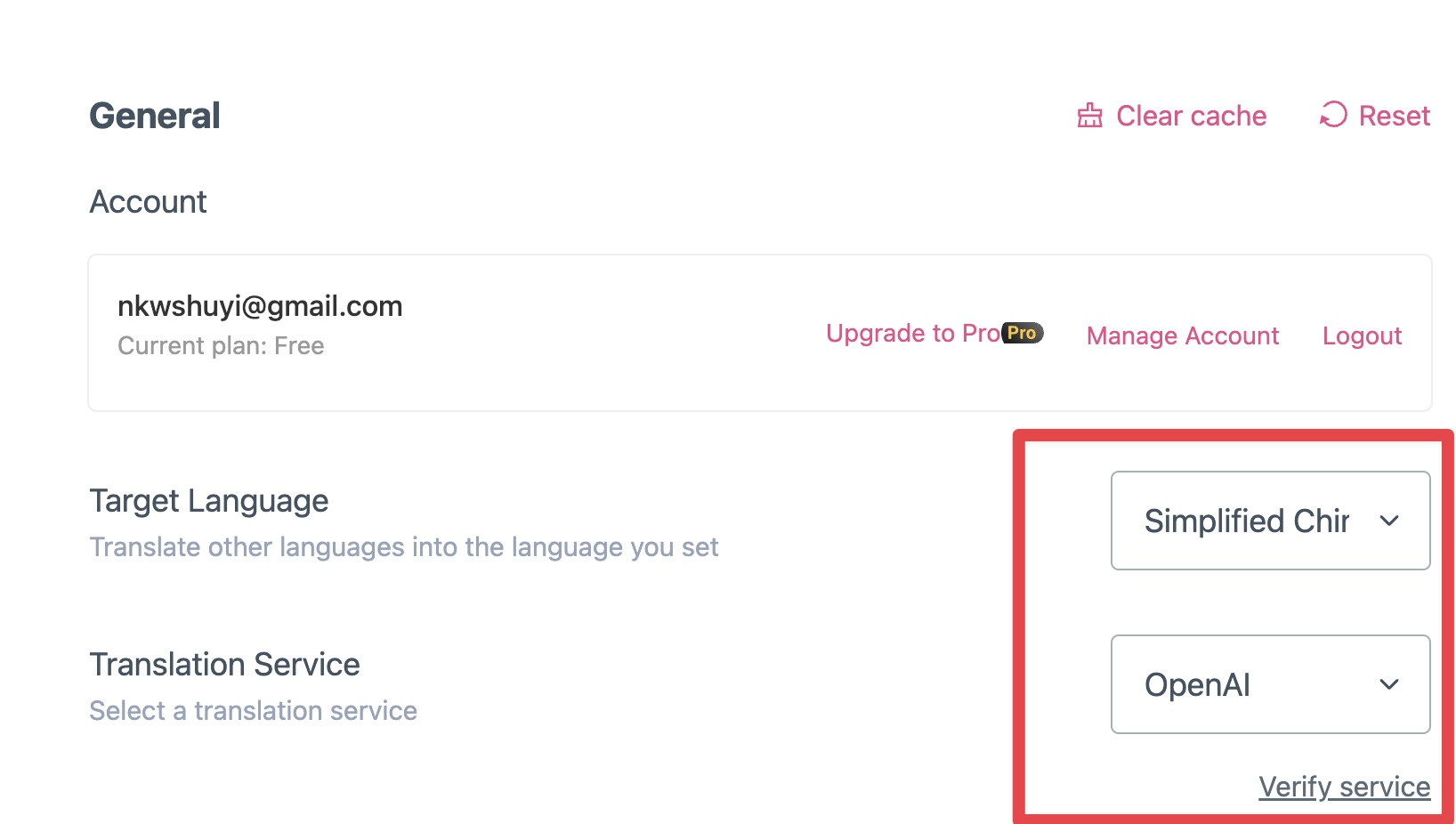
首先,你需要指定好目标语言。这里咱们选择简体中文。然后我们选择翻译引擎,Immersive Translate 提供了很多预置引擎供你选择。此处咱们选 OpenAI。
下面填写 API key,把刚才你从 Siliconflow 里复制的 API 密钥贴进去。
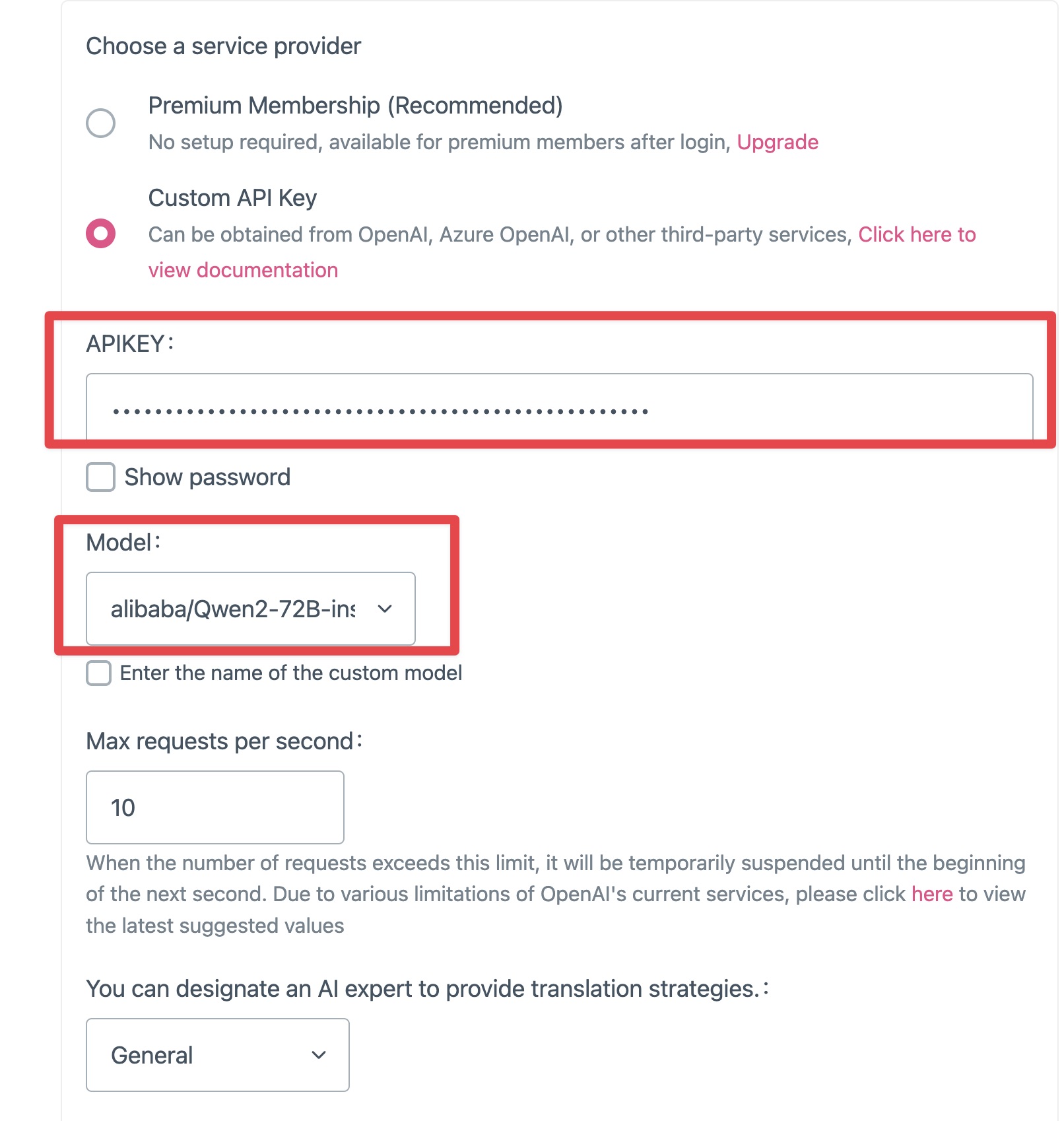
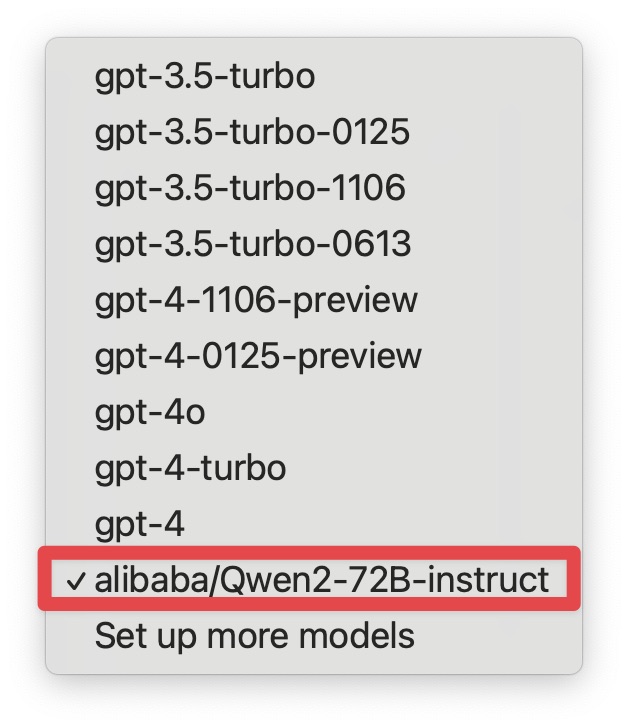
默认情况下,OpenAI 的 model 默认为一堆 GPT 模型,但你可以自己键入 alibaba/Qwen2-72B-instruct。
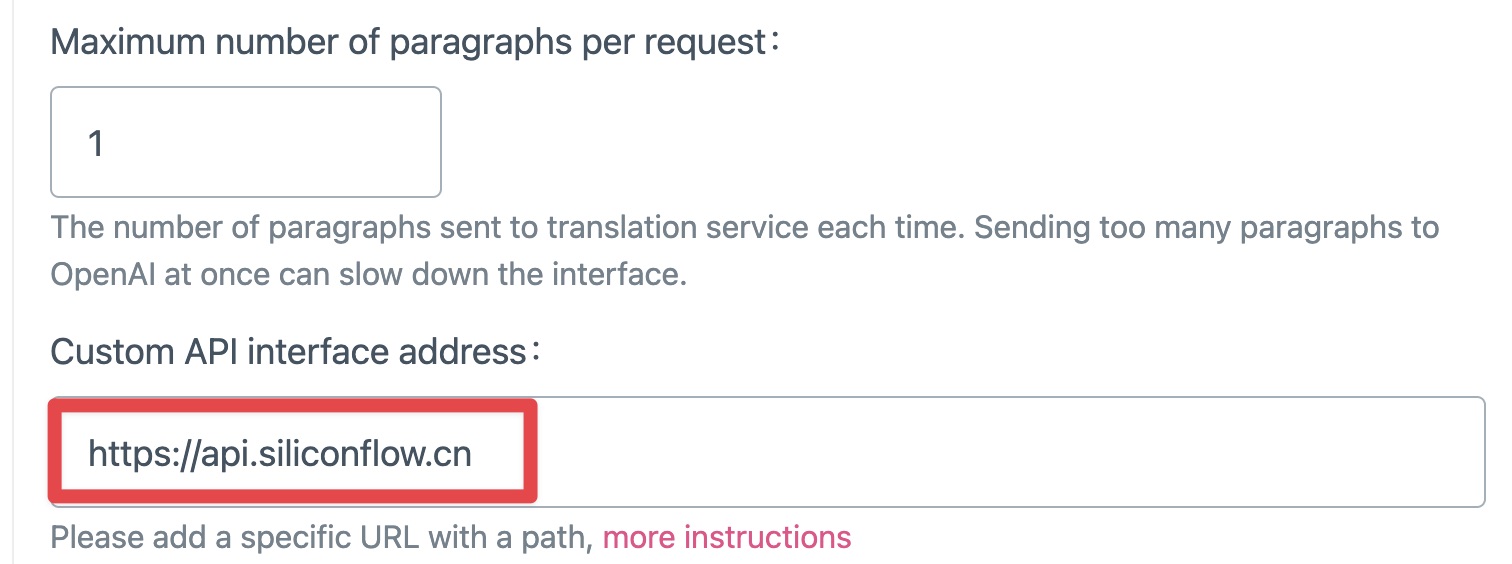
还有一个非常重要的栏目,是你需要输入一个 API 接口地址。Orange.ai 介绍说他测试过,输入内容与官方说明不同。这里你需要输入 : https://api.siliconflow.cn。
然后你点击设置选项的其他标签页,刚才输入的设定内容会自动保存。
现在我们看看效果。这是一篇英文文章的局部:

在 macOS 上面,你用快捷键是 Option + A 启用 Immersive Translate ,你会看到页面很快变成中英文混排,一段英文对应一段中文的翻译。

这样阅读起来,是不是就流畅多了?
数据分析对于数据分析,我们这次用 Open Interpreter 加上 Qwen2。关于 Open Interpreter 的介绍,你可以参考这篇文章。
这次咱们定义一个 yaml 文件,保存对模型的配置。这样调用起来更方便。
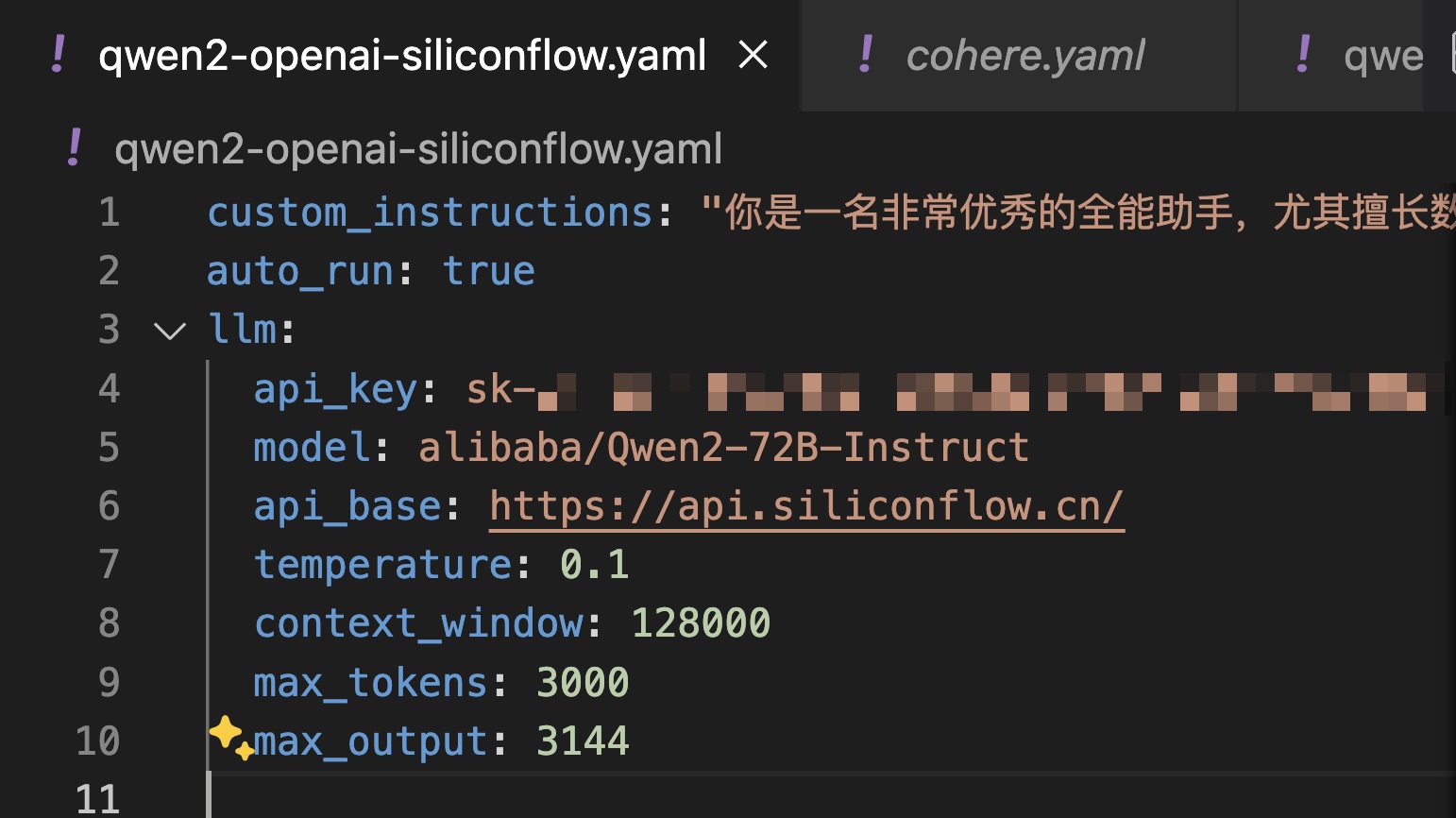
我们使用的依然是刚才从 Siliconflow 获取的 API key,model 还是 alibaba/Qwen2-72B-instruct ,至于 API base ,依然填写 https://api.siliconflow.cn 。
后面的其他设置,你就照着我的样例填写即可。哦,对了,前面有一个 custom instructions (定制指令),咱们指出:「你是一名非常优秀的全能助手,尤其擅长数据分析……」
因为这次咱们定义了配置文件,所以你可以用 interpret --profile <path to your yaml> 的形式来调用这个 yaml 文件。
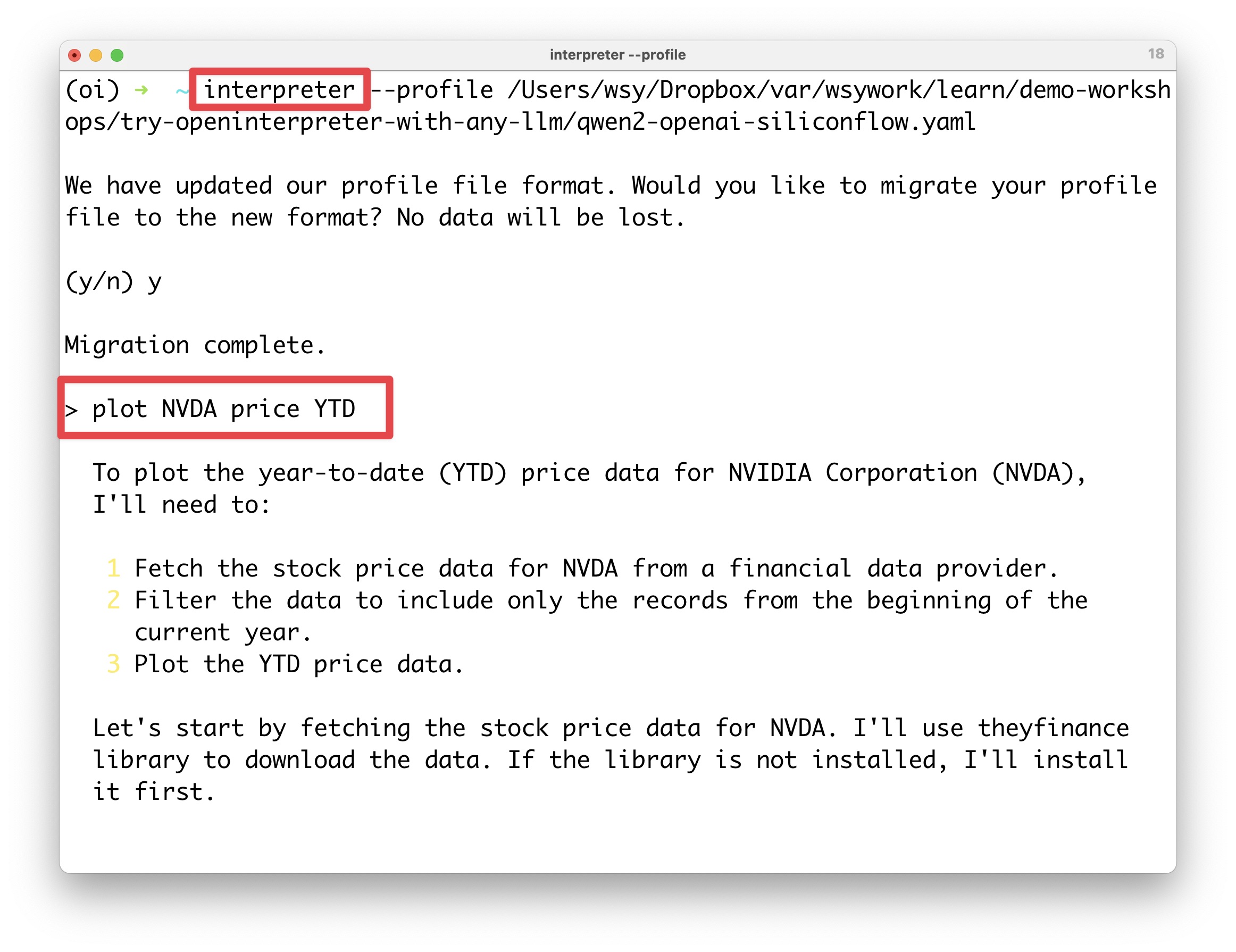
从上图里,你可以看到我给出的分析要求是:`plot NVDA price YTD ,就是让它把 NVIDIA(英伟达)从年初到今天的股价画出来。
它思考后,规划出了 3 个步骤,然后开始编程。
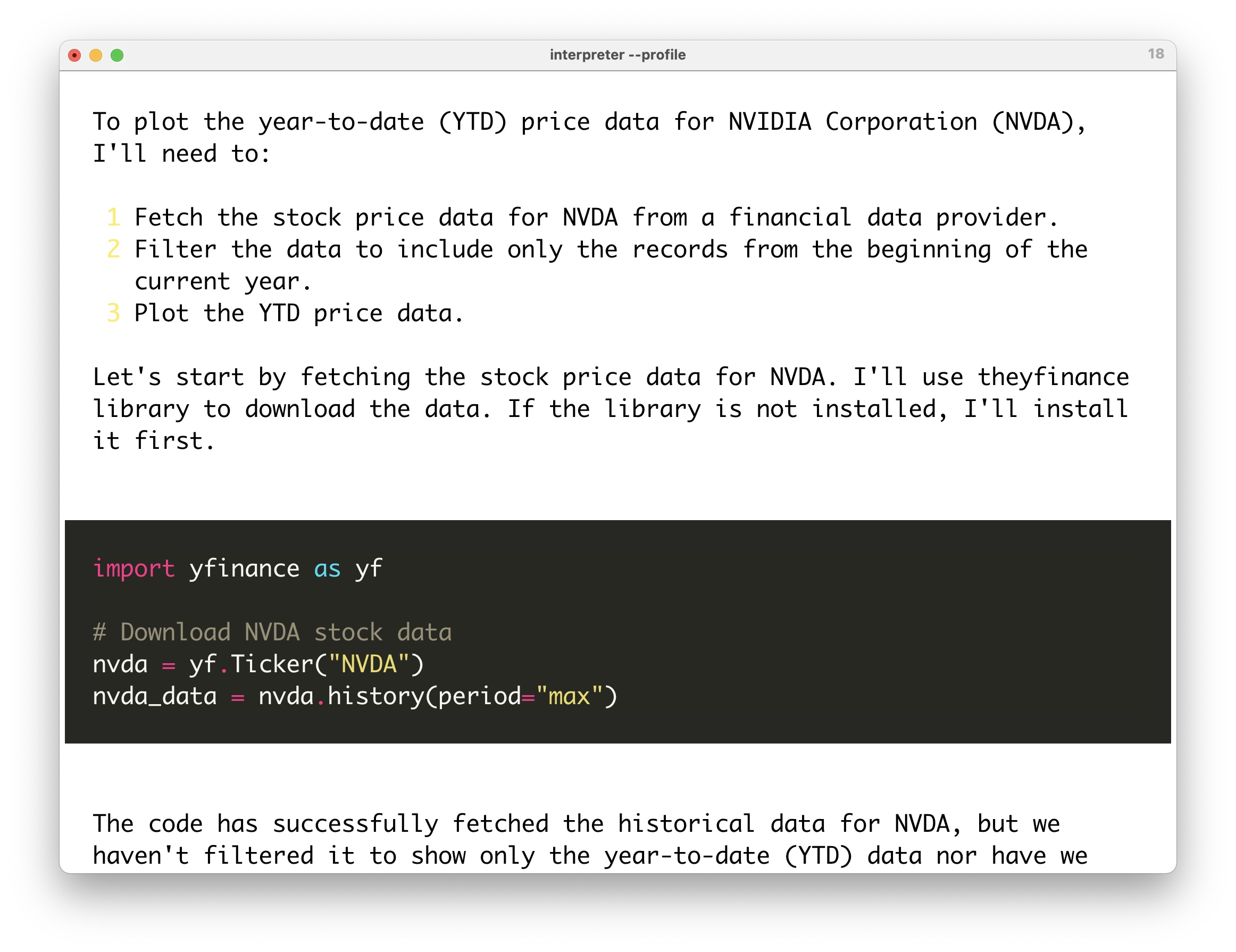
成功提取数据后,Open Interpreter 对数据做了可视化,并且把绘图结果保存到一个 png 文件。其文件名称为 nvda_ytd_price.png,这个自动命名也很合理。
咱们打开这个 nvda_ytd_price.png ,看看绘制的实际结果。
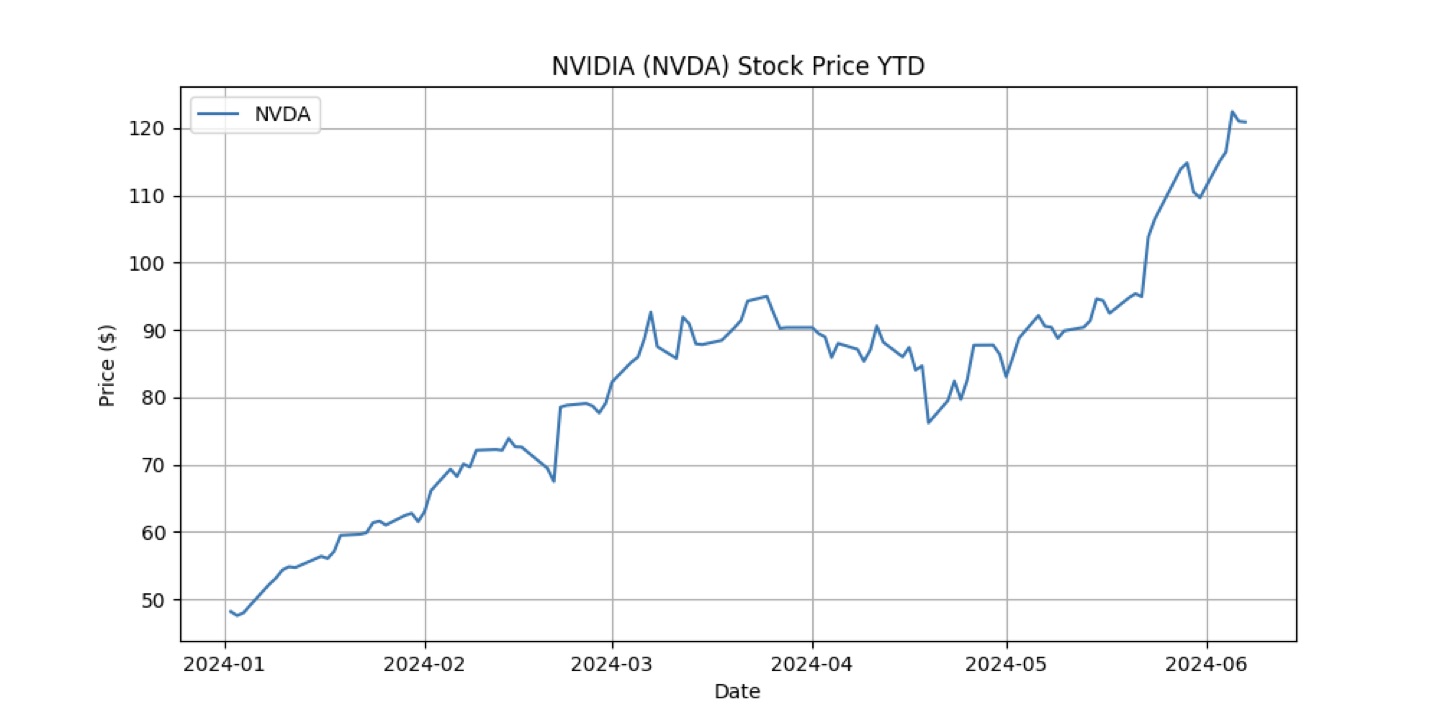
绘图准确无误。
只是看到这个图,我茫然若失,因为感觉自己好像又错过了什么😂
成本下面咱们看看,这一通翻译 + 数据分析 + 其他我没有给你演示的那些折腾…… 一共花了多少钱。
这是账单:
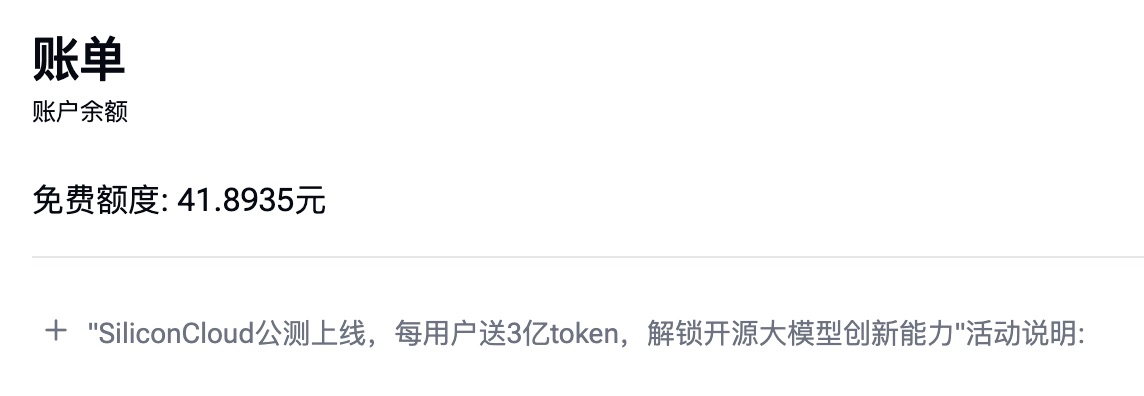
还记得吧?原来 Siliconflow 赠送给新注册用户 42 块,现在剩下 41.8935 元。你算算,我们到底花了多少?
这下你放心了吧?如果只是做翻译和数据分析任务,这些赠送的金额,够你用一阵子了,哈哈。
不过请你注意,官方的公测赠送金额活动,只持续到 2024 年 6 月 18 日。

抓紧时间注册吧,别跟上次 Perplexity 优惠一样错过了。
小结我们总结一下 Qwen2 这个模型的特点。便宜价格就不说了,想必你已经看到了。经过测试,我觉得 Qwen2 确实有良好的兼容性,它和 Immersive Translate 和 Open Interpreter 这些第三方应用之间可以通过 API 调用集成。另外它的速度快,性能也确实不错。
我希望这样的优质国产开源模型越来越多,因为对于很多小伙伴 —— 尤其是学生们来说 —— 的确是个好事。访问更加便利的同时,价格也更加便宜嘛。我准备这周的课程里,就用 Qwen2 替换掉原先的 Claude 3 Haiku ,让学生们来(更轻松地)尝试使用它编程和分析数据。
祝 AI 辅助工作和学习愉快哦!
如果你觉得本文有用,请点赞。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1437770.html
上一篇:
开源免费 AI 朗读中文,居然也能以假乱真了?下一篇:
AI 工作流,选图形界面,还是命令行? 
 精选
精选