博文
Publications 从人工到智能:图书馆书目编目自动化新探索
||
概要
随着图书馆数字化进程的加快,面对激增的文献资源,传统的人工编目方式在效率和成本上面临巨大挑战。为了探索更高效的资源组织路径,中山大学与中国人民大学的研究团队在Publications 期刊上发表了题为“Research on Large Language Model-Based Bibliographic Cataloging Agent in the CNMARC Context”的论文。该研究尝试将大语言模型和智能体技术引入书目数据加工流程,通过构建自动化工作流来辅助完成复杂的编目任务,为智慧图书馆的建设提供了新的思路。
研究过程与结果
研究团队设计了一套基于大语言模型的自动化编目框架,核心由四个智能体组成:元数据提取智能体 (Metadata Extraction Agent, MEA)、描述性编目智能体 (Description Cataloging Agent, DCA)、主题分析与标引智能体 (Subject Analysis & Indexing Agent, SAIA) 以及质量控制智能体 (Quality Control Agent, QCA)。这一框架模拟馆员实际操作逻辑,将编目任务拆解为相互衔接的环节,实现从原始资料到标准书目数据的全流程转化。
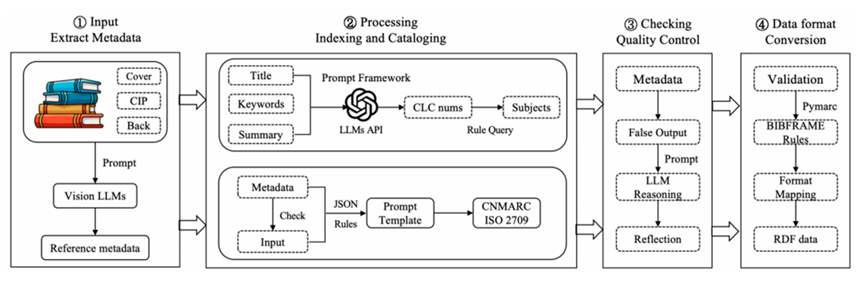
图1 自动编目框架设计
首先,元数据提取智能体负责从封面、版权页等原始资料中识别题名、责任者和出版项等关键要素;随后,描述性编目智能体按照CNMARC规范将这些要素转化为标准字段,确保记录符合行业要求。接下来,主题分析与标引智能体对文献内容进行深度理解,给出分类号和主题标引建议;最后,质量控制智能体对生成结果开展逻辑校验,修正格式偏差或信息遗漏,提升整体可靠性。为检验实际效果,研究团队严格参照《中国图书馆分类法》第五版的标准要求,利用某高校图书馆提供的三万余条真实书目记录进行了大规模实验测试。
表1 多模型元数据识别准确率

表2 多模型描述性编目准确率

表3 多模型《中图法》标引准确率
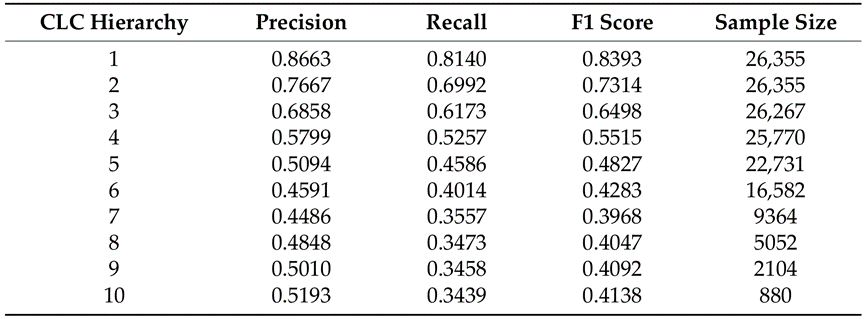
同时,各选一本中文图书和一本英文图书作为实例验证,考察该编目框架在实际编目场景中的表现。结果显示,该框架在元数据提取和主题分析环节均达到较高准确率,初步实现了高效的自动化转化。
表4 基于CNMARC的中英文图书编目实例 (ISO 2709格式)

结论与前景
该研究证明了自动化编目在提升图书馆工作效率方面的潜力,尤其是在处理标准化程度较高的书目数据时能减轻人工负担。尽管目前的系统在逻辑上更倾向于预设好的单智能体线性执行,而非具有复杂信息流和交互特征的多智能体系统,但其展现出的性能已足以作为未来智能化编目系统的实验基准。未来研究将致力于提升模型在处理疑难文献时的精细度,文献复分等复杂问题,并结合检索增强生成、大模型微调进一步优化流程以适应多样化的文献加工需求。
阅读英文原文:https://www.mdpi.com/2304-6775/14/1/19
Publications 期刊介绍
主编:Andrew Kirby, Arizona State University, USA
期刊主题涵盖学术出版,学术交流以及学术文化的各个方面;涉及学术交流理论与实践、开放获取模式、学术文献数据库、出版伦理道德、 版权、数字化出版及其他创新技术、同行评审、学术评估及其影响等热门研究话题。现已被ESCI (Web of Science)、Scopus、DOAJ、CNKI等重要数据库收录。
2024 Impact Factor:2.5
2024 CiteScore:10.0
Time to First Decision:27.4 Days
Acceptance to Publication:4.8 Days
期刊主页:https://www.mdpi.com/journal/publications

https://blog.sciencenet.cn/blog-3516770-1530697.html
上一篇:Lubricants 中国矿业大学朱少禹博士和合肥工业大学孙军教授主持特刊:轴承润滑的多物理场建模
下一篇:关于作者署名,这些“规则”你都了解吗?
