博文
Hearts:心脏病学中的大型语言模型
||
研究背景
大型语言模型 (LLMs),如ChatGPT、Claude和Gemini,正逐步应用于医学领域。为了评估这些通用模型在心脏病学中的可靠性,一篇发表在 Hearts 题为“Evaluating Large Language Models in Cardiology: A Comparative Study of ChatGPT, Claude, and Gemini”的研究通过比较三者回答临床相关问题的性能,验证了其在专科领域的适用性。
研究设计及结果
这一研究是一项比较性观察研究,旨在评估LLMs在心脏病学相关医疗应用中的表现。研究方法基于四个关键方面:首先,对三种主流人工智能平台 (ChatGPT、Claude和Gemini) 进行比较分析。其次,研究采用标准化框架,整合70个预设临床问题并统一评估标准。此外,本研究实施双盲评估方案,确保评估者无法知晓每条回复的人工智能来源。最后,研究采用多评分员方法,邀请三位临床经验丰富的心脏病学专家使用5分制李克特量表对每个回复的科学准确性、完整性、清晰度和连贯性进行了评分。
为了评估专家评分的一致性,计算了两种互补的评分者间信度指标:Kendall's W系数用于整体一致性,加权κ用于成对一致性。指标结果表明,在所有的四个评估标准上,三位心脏病学专家之间存在高度一致性,范围在0.61 (连贯性) 到0.71 (完整性) (表1)。
表1. 加权κ分析评分者间信度。
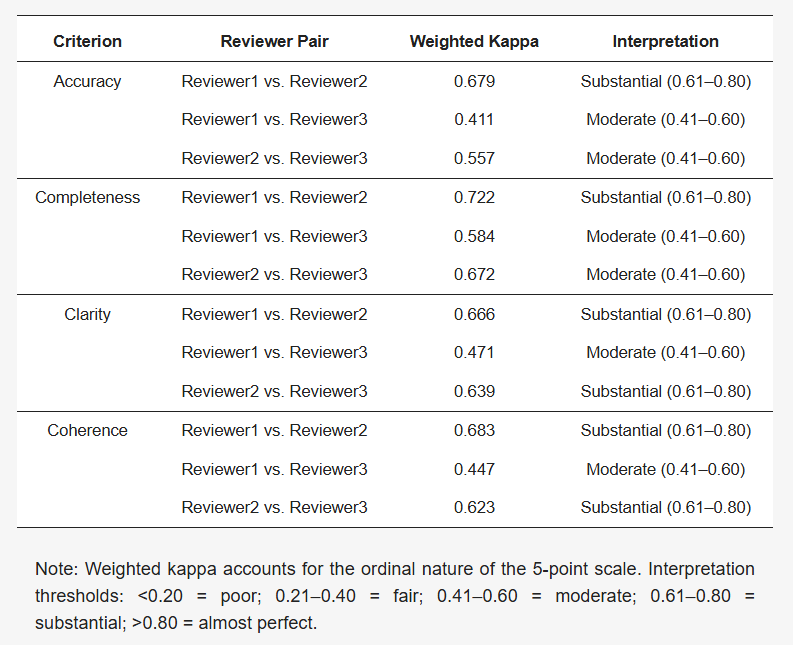
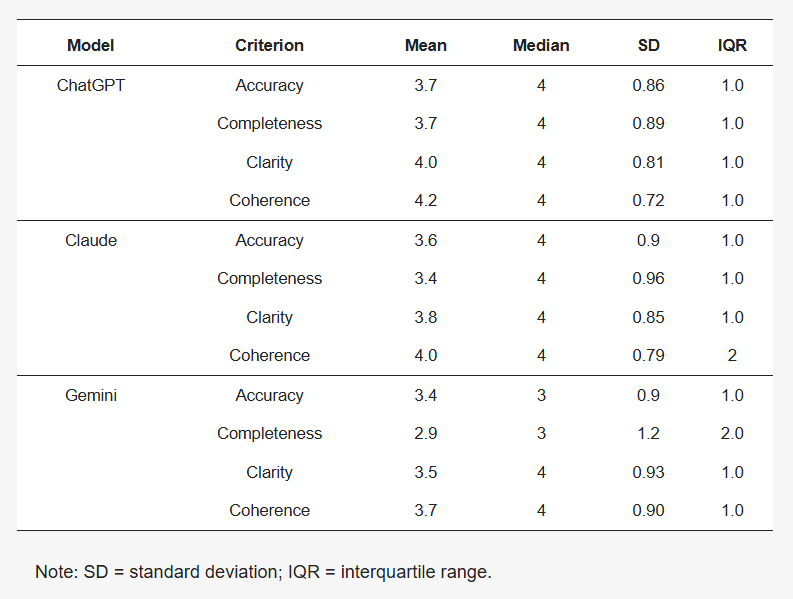
图1显示了三种通用模型评分的分数分布情况。准确性、完整性、清晰度和连贯性的平均得分最高的是ChatGPT (3.7-4.2),其次是Claude (3.4-4.0),最低的是Gemini (2.9-3.7)。所有模型的得分变异性适中,四分位数范围表明性能分布一致。中值表明,ChatGPT和Claude的得分通常为4,而Gemini的得分较低 (表2)。在敏感性分析中,结果仍然稳健。总体而言,在评估的LLMs中,ChatGPT在产生临床相关心脏病学反应方面表现出色,在所有标准上均优于Claude和Gemini。然而,这些模型都没有达到最高评级,而且表现因环境而异。这些发现强调了需要针对特定领域进行微调和人为监督,以确保安全的临床部署。
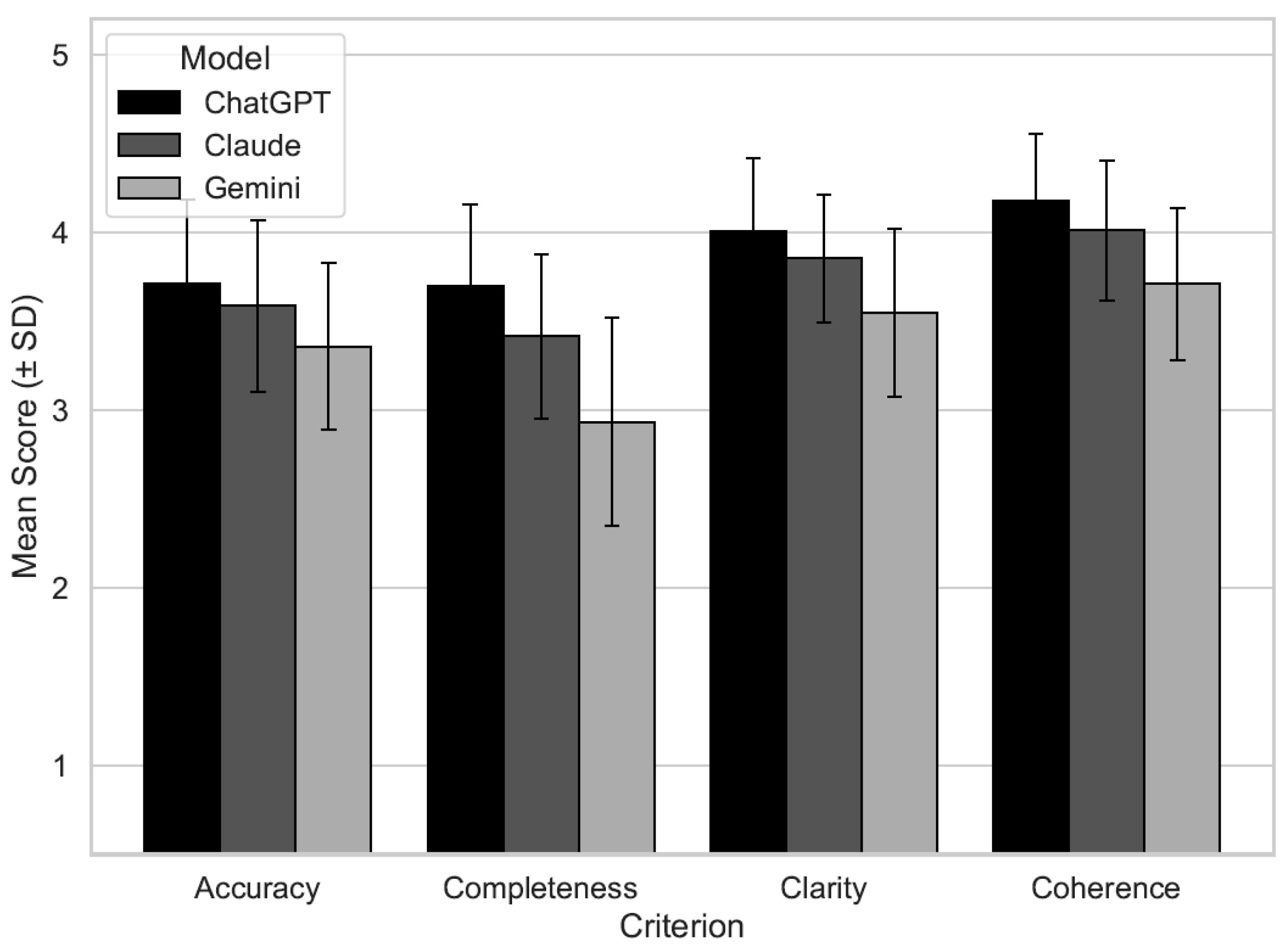
图1. 三种通用LLMs (ChatGPT、Claude和Gemini) 在四个质量维度上的专家评估平均得分:科学准确性、完整性、清晰度和连贯性。评分基于三位盲审心脏病学专家采用5分制李克特量表 (1分=极差,5分=优秀) 的平均评定,统计分析包括Kruskal-Wallis检验、Dunn的事后比较、Kendall's W系数、加权κ和敏感性分析。误差条表示标准差。柱状图采用灰度色块区分三种模型 (黑色=ChatGPT,深灰色=Claude,浅灰色=Gemini)。
表2. 基于模型和标准进行的描述性统计。
研究总结
这一系统性评估表明,ChatGPT目前在解决结构化心脏病学相关提示方面的表现优于Claude和Gemini,特别是在预诊断和患者交互场景中。然而,当前尚无模型达到了专业级可靠性,而且结果仍然存在很大的可变性。这些发现强调了对特定领域的微调、严格的人为监督和持续透明的评估的必要性,以确保LLMs在临床实践中安全有效地应用。随着人工智能模型和临床标准的发展,本研究建立的开放、可重复的基准测试协议为进一步开展持续评估提供了基础框架。
阅读英文原文:https://www.mdpi.com/2673-3846/6/3/19
Hearts 期刊介绍
主编:Prof. Dr. Matthias Thielmann, University of Duisburg Essen, Germany
期刊研究领域涵盖基础、转化和临床研究,心血管医学创新科学所有领域以及相关学科。
Time to First Decision:19.9 Days
Acceptance to Publication:2.8 Days
期刊主页:https://www.mdpi.com/journal/hearts

https://blog.sciencenet.cn/blog-3516770-1526166.html
上一篇:MAKE:机器学习与知识提取的十大研究前沿
下一篇:Medical Sciences:氧化应激——糖尿病血管并发症的核心驱动与治疗新方向
