博文
深度学习多隐层架构数理逻辑浅析(十八)(3)
|
一提起战神,大家内心默认都是拔山举鼎武夫,其实真正的战神不是武夫而是万中无一的数学大师。因为他需要在99%概率优势在敌的情境中,创造并把握1%的稍纵即逝的时机消灭掉敌人。他需要在相互关联、环环相扣、牵一发而动全身的复杂局面中极致精准计算各种要素。比如,白起长平决战虽兵力不足仍围歼赵军,若非精准布局诱耳、精准时点封堵、精准一击致胜,很可能惨遭赵括反杀;韩信半渡而击龙苴,若非对当前气候、河水流速、沙袋数量、敌军进攻时点等精准预判,大概率会被敌方杀得片甲不留;霍去病无后勤奔袭数千里杀匈奴,若非算准了敌游牧地点,恰好卡准时点,在合适位置合适时间合适规模通过敌营补充给养,只怕我军早已在路途中不战而全员饿毙。
如今的战场,AI战神以压倒性优势,深度预演料事如神。首先,提前挖掘收集更广泛精细数据,一维数据扩展为多维矩阵数据、高阶张量数据;其次,不断训练厘清这些信息要素图谱联络和脉络权重特征,从线性方程计算、到矩阵方程计算、到张量方程计算。深度学习AI凭借多隐层架构,其分析能力远超传统兵演好几个层次数量级。
一、多模态张量深度学习每个隐层都是线性空间,多个隐层复合就是多重线性空间复合(即高阶张量)。深度学习”多层次模型突破了向量空间局限性,不期然间迎合了现实世界原本的多重线性特征。现实世界的数据天然形态本质上是高阶张量。一张彩色图片是3阶张量(高、宽、通道),一个视频批次是5阶张量(批次、帧数、高、宽、通道)。深度学习的多隐层结构,实际上是在对这些高阶张量进行逐层的几何变换。
多隐层结构是深度学习模型的核心,我们仍然以语义识别为例。 人类的自然语言的层次性非常明显,最下面一层是‘词汇’、上一层是‘语句’、再上一层是‘段落’、然后是‘章回’等等。从低层到高层的特征表示越来越抽象,高层特征是低层特征的组合、抽象、主题。 上一层是下一层的特征变换,这种特征变换通常是线性的。比如:语句1含义 = 单词1含义 + 单词2含义 + 单词3含义 + ...... 这里,语句1含义和单词1含义、单词2含义、单词3含义具有明确的线性关系。这是一种层次线性关系。特别指出,由于‘语句’和‘单词’是不同层次的逻辑概念,数学表达‘语句’函数和‘单词’函数时,两种层次类别的函数其各自变量必然不同。这意味着‘语句’和‘单词’之间的关系是“线性变换”(不是“线性算子”)。比如:语句"cat set on the mat",五个单词共同融合为一个主题。线性逻辑结构如下:
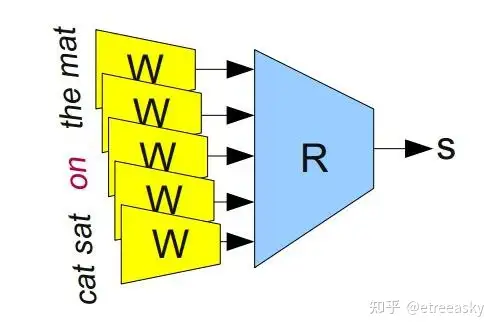
这种层次线性的融合主题关系,可以采取比单层线性更复杂的逻辑结构。比如考虑下面这个句子“the cat sat on the mat”,很自然地它可以被分成下面这样用括号分开的不同的段:“((the cat) (sat (on (the mat))”. 我们可以把每层逻辑(记为A)应用在这个分段上:
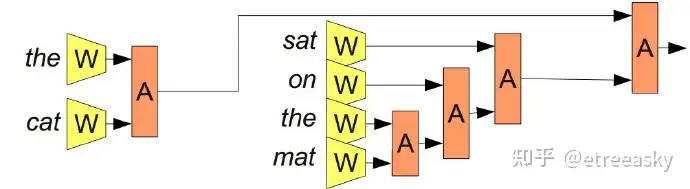
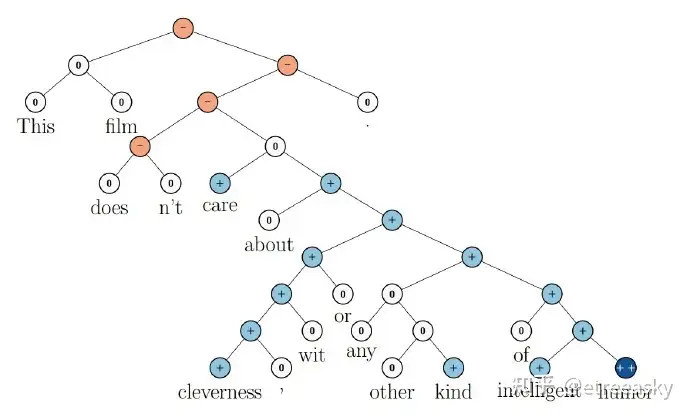
这样的模型通常被称作“递归神经网络”因为一个模块经常会使用另外一个同类型模块的输出。有时候它们也被称作“树形神经网络tree-structured neural networks”。递归神经网络在一系列NLP任务中都有很重大的成功。比如Socher et al. (2013c) 就利用了一个递归神经网络来预测句子的情感:
并且,更重要的是,这种多层次线性关系不仅仅对于一个单一的语言体系如此。对于多语言体系,亦如此。比如英语和汉语的二元融合体系,可以看出这种二阶张量大体系遵从共同规律,这是自动翻译的理论基础。我们可以从两种不同语言中把单词嵌入到一个共享的空间去。我们用词汇向量化差不多的方法来训练W(en)和W(zh)两种表达。由于某些中文和英文的词汇有相似的意思。也就是说翻译过后意思相似的词理所当然应该离得更近。更有意思的是我们未知的翻译后意思相似的词结果距离也很近。因为向量内积关系,词汇向量化会把相似的词聚到一起,所以如果我们已知的中英词汇离得近,它们的同义词自然离得近。我们还知道类似性别差异趋向于可以用一个常数的差异向量表示。看起来,对齐足够多的点会让这些差异向量在中文和英文的嵌入中保持一致。这样会导致如果我们已知两个男性词互为翻译,最后我们也会得到一对互为翻译的女性词。直观来讲,仿佛就是两种语言有着相似的“形状”,通过对齐不同的点,两种语言就能够重叠,其他的点就自然能被放在正确的位置上。
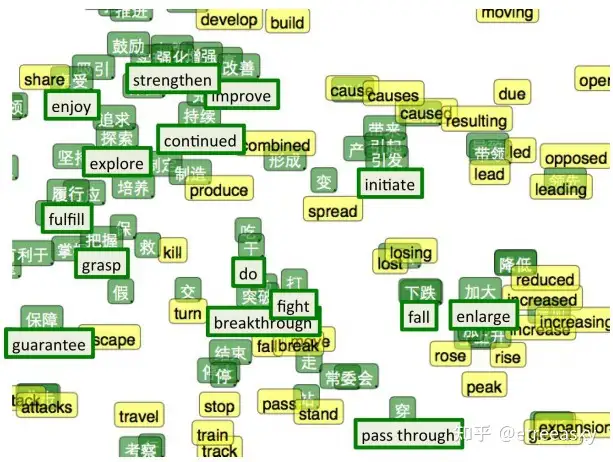
双语单词嵌入的t-SNE可视化图。绿色是中文,黄色是英文。在‘中文向量⊗英文向量’双语单词嵌入中,我们对两种很相似的数据学习了一个共享表征。注意,这是一种新的多语言层次线性关系,比单语言体系自身的‘词汇’、‘语句’、‘段落’的那种层次逻辑结构关系更加复杂。多语言层次模型,形象显示出了两种语言体系融合的内在的多重线性关系。
更有意思的是,我们还可以把非常不同的几种模态的向量数据嵌入到同一个高阶张量空间(多模态向量复合)。比如,单词向量⊗图像向量的复合张量:
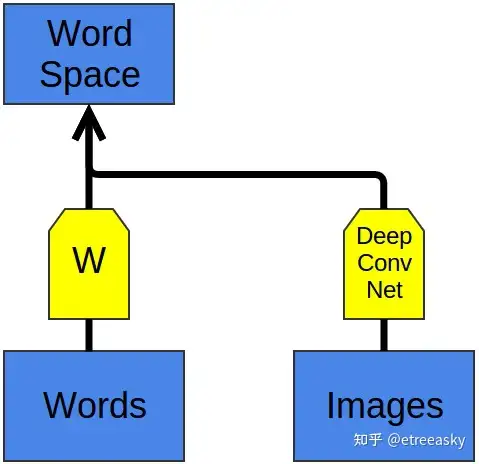
基本思路就是你可以通过单词嵌入输出的向量来对图像进行分类。狗的图像会被映射到“狗”的单词向量附近。马的图像会被映射到“马”的单词向量附近。汽车的图像会被映射到“汽车”的单词向量附近。以此类推。有趣的是如果你用新类别的图像来测试这个模型会发生什么呢?比如,如果这个模型没训练过如何分类“猫”,也就是把猫的图像映射到“猫”向量附近,那当我们试图对猫的‘单词向量⊗图像向量’复合进行分类的时候会发生什么呢?
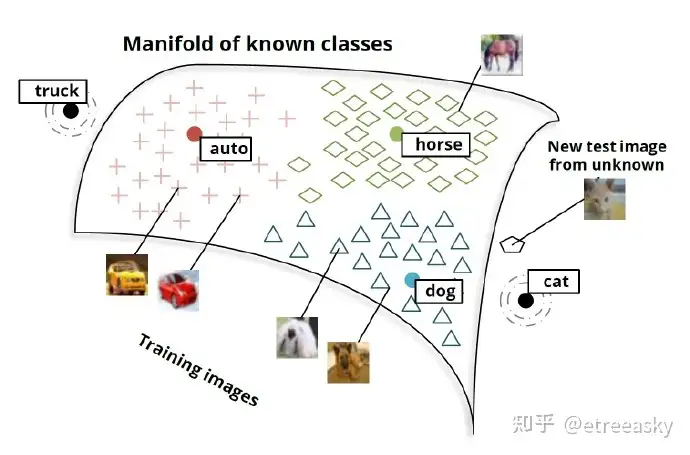
结果表明,这个网络是可以很合理地处理新类别的图像的。猫的图片并没有被映射到单词嵌入空间的随机的点中。相反的,他们更倾向于被映射到更接近于“猫”的向量。相似的,卡车的图片最后离“卡车”向量相对也比较近,“卡车”向量和与它相关的“汽车”向量很近。
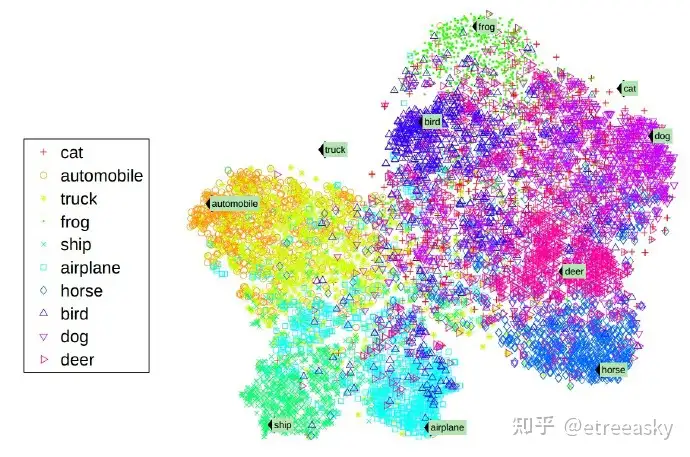
这个图是斯坦福一个小组用8个已知类(和2个未知类别)做的图。利用“这些词是相似的”的推断,结果一目了然。
深度学习中多个隐含层的复合并不是线性空间的简单堆叠,而是一种更为复杂的多重线性乃至非线性变换过程,高阶张量通过层层复合来逼近复杂的函数关系。 表面上看,多层次线性关系也不过是一种向量化空间的拓展,似乎只是单层线性关系的简单扩充而已。 其实不然,因为多重线性和单层线性区别是本质性的。正如ℵ2阶无穷大与ℵ1阶无穷大的本质不同。
单个隐层通常处理的是线性空间(向量空间)中的运算,如矩阵乘法。但当多个隐层复合时,这种结构在数学上可以被推广理解为模结构。一阶到高阶的跃迁,在线性空间中,特征元通常是一阶的(如向量),它们只能进行加法运算。而在多隐层复合形成的“模”结构中,特征元不仅包含一阶特征,还通过层层非线性激活函数的引入,生成了高阶特征属性。环扩张与特征生成,深度学习的过程可以看作是一种“环扩张”。这不仅仅是特征数量(维度)的增加(加法扩张),更是特征复合阶数的增加(乘法扩张)。每一层的输出都是对前一层特征的非线性重组,这种重组在数学上类似于张量积的高阶复合。例如,低层可能检测边缘(一阶),中层组合成形状(二阶),高层组合成物体(高阶)。特征从一阶向量向高阶复合体的进化,不仅是数量增加,更是模结构与环扩张,结构复杂度的指数级增长。
深度学习每个隐层都是线性空间,多个隐层复合就是多重线性空间复合(即高阶张量)。从张量场角度,分析深度学习多隐层复合的特性。如果我们将整个神经网络视为一个张量场,那么张量数据元正是输入数据(如图像、文本)在这个场上定义的基本神经元。

多隐层网络通过非线性变换,将输入数据从原始的高维、稀疏、平坦的欧氏空间,升级映射到一个低维、稠密、具有特定曲率的流形上。这个流形学习与嵌入过程可以理解为在张量场中沿着特定的联络(由权重参数化)进行平行移动,最终将同类数据聚集在流形的特定区域(子类),不同类数据区分开来(聚类)。层间映射 fl:Pl−1→Pl不仅是点映射,还需保持纤维丛结构,线性部分 Wl对应联络(connection),非线性激活 σ对应截面的非线性变换,复合映射 f=fL∘⋯∘f1 形成丛的复合(张量积)。
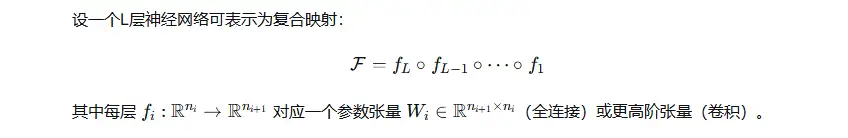
深度学习中的多隐层网络通过张量场的视角进行深刻理解,这种视角有助于我们把握网络结构的本质特征和优化机制。深度学习中的多隐层网络适当改造可被视为一个动态张量场系统,其中每个隐层对应一个特定的张量变换操作,而整个网络的训练过程则是对这个张量场进行优化以达到收敛状态。每个隐层相当于在前一层的张量空间中定义了一个新扩张的参照系,通过权重张量实现坐标变换。每个隐层实际上执行的是一个非线性张量变换,而非单纯的线性空间。虽然线性变换(权重矩阵乘法)是基础,但激活函数引入了关键的非线性特性。从张量场角度看,每个隐层可表示为一个张量算子。浅层隐层捕获低级特征(如边缘、纹理),深层隐层捕获高级抽象特征(如物体部件、语义概念),这种层次化结构在张量场中体现为特征张量的层级变换。随着数据通过隐层,特征张量的秩(即特征多样性)通常会‘先增加(特征提取)、后减少(特征抽象)’,形成一个张量秩的瓶颈结构。
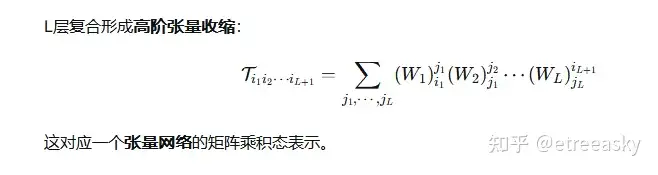
将CNN视为单一高阶张量一元性体现,是单一大张量的全息原理。虽然 {T}可能有 10^6-10^9个分量,但其有效自由度被架构对称性极度压缩。训练过程是参数流形上的相变过程,收敛到基态,即极小值点θ^*,其稳定性由Hessian矩阵的指标定理决定。在相变点附近,Fisher度规 g{μν}出现本征值坍缩,导致学习率必须自适应调整(Adam的beta参数本质上是曲率正则化)。批归一化的随机性是经典场的量子涨落,其逆温度 beta与学习率关联,训练过程是退火过程。
“深度带来特征抽象性” 的张量本质,在于每一层的参照系诱导,都是对特征张量的指标升维 / 秩提升,高阶特征对应更高维的参照系,其能表征更复杂的输入数据拓扑结构。迁移学习是将预训练的张量分量在新的坐标卡下进行协变调整,保留原有的特征映射内蕴。张量的协变性是其参照系的核心数学性质,多层复合的协变传递每一层的张量缩并均满足协变性,因此多层复合后的全局张量场仍保持协变不变性,这是跨任务 / 跨数据集迁移学习的张量场本质。 从范畴论视角,多隐层的参照系复合可抽象为张量函子的复合,这让分散的层操作被统一的范畴态射约束,体现了 “高阶张量的整体统一性”。对象是不同流形上的张量场(如输入张量、各层特征张量),态射是层操作(线性缩并 + 非线性激活),每一层对应一个张量函子,将前一层的张量范畴映射到后一层的张量范畴,保持态射的复合性;多隐层复合就是函子的连续复合,整个网络的全局张量场是该复合函子的像。多层的参照系不再是孤立的,而是被函子复合的范畴规则统一,无论隐层数量多少、维度多高,其操作都属于同一范畴的态射,这是 “多隐层高阶张量架构复杂但参照系规则统一” 的数学本质。通过优化高维张量场的几何结构,使网络能够有效捕捉数据中的复杂模式。
深度学习的成功不仅仅在于“深”,更在于这种深度带来的高阶张量复合能力,它使得机器能够从海量数据中自动挖掘出具有复杂几何结构的特征表示。虽然单个隐层的变换相对简单,但多层复合形成的高阶张量场能够表达极其复杂的函数关系,这正是深度学习强大的根本原因。
在量子力学中,可观测量对应厄米算符。在深度学习中,权重矩阵的奇异值分解(SVD)得到的奇异值(实数)对应特征的“重要性”,这类似于厄米算符的本征值。多隐层的特征提取过程,本质上是将输入数据投影到由这些“本征向量”张成的特征空间中。然而当前的深度学习模型在处理坐标变换(如图像从笛卡尔坐标转为极坐标)时往往表现不佳。这是因为现有的网络架构缺乏微分同胚协变性,即无法保证在坐标变换下特征表达的内蕴一致性。
未来的研究方向可能在于如何赋予这个张量场更丰富的几何结构(如曲率感知),使其具备更强的物理直觉和泛化能力。下阶段的深度学习需要引入更复杂的几何结构(如规范场论或黎曼几何),使网络具备对输入数据进行“弯曲”和“拉伸”不变的感知能力。需将神经网络重新诠释为流形间的非线性映射及其微分几何结构。将神经网络视为主纤维丛 P(M,G)上的结构,底流形 M是输入数据流形(维数 n),结构群 G是每层的变换群(如 GL(dl)),纤维 F是 每层的特征空间,每一层 l对应一个纤维丛 Pl(Ml,Gl),其中(M_l)是第 l 层激活值的流形,Gl是该层的对称群(如神经元排列、缩放对称性)。第 l 层的激活值 hl可视为流形 (M_l−1) 上的张量场,(0,1)-张量场(向量场),但具有内部结构,局部坐标h_li(x)其中 i=1,…,dl 是特征维度,在基变换下hl按张量规则变换。权重 W_l是流形 (M_l−1)×(M_l)上的混合张量场,有W_l∈T(M_l−1)⊗T(M_l),W_l定义了一个丛同态T(M_l−1)→T(M_l)
神经元排列的对称性:将权重 W_l 视为联络,定义层间的平行传输,从第 l−1层的 h_l−1到第 l 层的传输为:
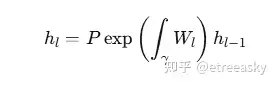
其中 P表示路径有序积分。离散近似为 h_l=σ(W_lh_l−1)。
复合层作为张量场,L层网络的整体映射是高阶张量场。这不是简单的张量积,而是参数化映射的层叠复合,对应微分几何中的喷射流形 (jet bundle) 结构。权重矩阵 W_i不是独立参数,而是联络系数 (connection coefficients),它们定义了纤维间的平行输运规则。整个网络的参数空间 构成黎曼流形,其度规由Fisher信息矩阵诱导。梯度下降本质上是沿测地线的自然梯度流动。深度网络的曲率奇点集中在层间耦合区域,即 W_i与 W_{i+1}的乘积流形上。多层复合的参照系特性是流形上张量的协变不变性与范畴化函子复合,整个深度学习系统的张量场定义在乘积流形 ,该流形是赋范欧氏流形(欧式空间的子流形,因权重衰减 / 正则化使其有界),其坐标是参数的索引,是张量的参数指标。线性变换本质是张量缩并(缩并张量的一对协变 / 逆变指标)。特征张量场的逐分量内蕴映射,不改变张量的型和指标集,仅改变张量在流形上的分量值,属于张量场的非线性自同态(保证特征空间的拓扑不变性,如 ReLU 保持线性空间的拓扑,Sigmoid 是光滑同胚)。“参照系” 在张量场中对应流形的坐标卡选择,张量的核心性质是坐标无关性(内蕴性),即张量的物理意义(特征提取、映射能力)不随坐标卡的变换(架构参数调整、数据维度变换)而改变,仅分量值发生协变变换。深度学习未来升级架构的多隐层的复合过程,要求张量参照系的逐层诱导、对称对偶、协变传递与范畴化复合,进而完美适配 “多层复合 = 高阶张量” 。

值得注意的是,当前的深度学习架构(如CNN、Transformer)大多隐含假设数据存在于平坦向量空间中,使用的是标准的欧氏内积(如点积注意力)。这意味着它们在处理数据的非线性变换(如旋转、扭曲)时存在局限,因为缺乏对弯曲时空度量的直觉感知。从优化和参数化的角度看,将多隐层复合视为一个整体的高阶张量,为我们提供了新的模型压缩和优化思路。传统的卷积神经网络(CNN)往往逐层进行参数更新,层与层之间存在信息孤立。
传统视角下,CNN的卷积、全连接、注意力、激活等操作是相互独立的 “层算子”,而张量场视角将其全部统一为特征张量场的基本变换,将各层参数统一为整体参数张量场的“子场”,使深度学习成为不可分割的整体一元系统—— 这一统一让研究者能从全局视角分析网络的性能,而非局限于单一层的设计。传统视角下,深度学习被视为 “分层算子的串联”(卷积→激活→池化→全连接),各层参数独立优化、特征逐层传递;而张量场统一视角将整个深度学习网络视为不可分割的整体一元系统。深度学习的所有研究对象(参数、特征、误差)均可抽象为定义在特定高维流形上的张量场,张量场的阶数、支撑集、光滑性对应网络的结构属性、可训练性与信息表达能力;网络的前向传播是特征张量场在 “层伪时间 / 空间” 上的动态演化过程,层操作是张量场的基本变换算子;损失函数是参数 - 数据乘积流形上的标量值能量场,网络训练的本质是在高维参数流形上求解该能量场的全局 / 局部极小值,反向传播是实现这一目标的张量场微分运算与梯度流传播机制;所有网络参数并非独立的 “数值集合”,而是单一高维参数张量场的不同分量 / 子场,反向传播的 “联合优化” 本质是对该整体张量场做全局变分微分,而非对各层参数单独求导。
深度学习的核心架构(如CNN、Transformer)均由多隐层线性变换(卷积、全连接)与非线性激活复合而成。从张量场视角看,多隐层的线性复合本质是高阶张量场的逐层变换,整个网络可视为一个统一的高阶张量场。虽然多隐层高阶高维张量架构数据非常复杂,但整个网络多层复合的计算可视为张量网络的统一场,体现整体一元论:
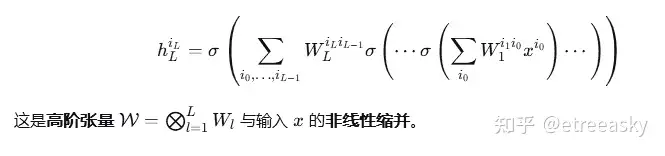
将CNN视为单一高阶张量一元性体现,是单一大张量的全息原理。“统一场的整体一元论” 对应张量场的纤维丛整体结构,CNN 的收敛性则是该张量场在参数流形上的截面梯度流收敛,让高维高阶的复杂张量操作被统一的变分优化泛函约束。CNN 的卷积是张量的循环卷积缩并(利用平移不变性约束张量的分量对称性),CNN 的池化是张量的指标收缩(对空间 / 通道指标求和 / 取极值,降低张量的秩),均是约束下的张量场约化操作。收敛性的本质是张量场在参数流形上的截面,沿损失泛函的梯度流收敛到临界点 / 次临界点,其拓扑基础是参数流形的紧性(正则化保证),代数基础是特征张量的秩逼近,分析基础是张量场的可微性 / 次可微性。CNN 的多隐层的本质并非单纯的多重线性空间复合,而是乘积流形上混合型张量场的逐层诱导、缩并与非线性映射,其参照系特性是张量的协变不变性、逐层诱导性与范畴化函子复合,保证了特征映射的内蕴性与操作的统一性。
如果将整个 CNN 视为单一高阶张量,本质是乘积流形M上的纤维丛结构,这一结构诠释了 “高阶高维复杂但整体一元” 观点,也是多隐层联合优化的张量场普遍性框架:CNN 联络权重张量场W,是纤维丛上的线性联络,负责将基底上的特征张量从输入端'平行移动'到输出端(即特征传播);通过反向传播的联合优化,对纤维丛联络的整体校准,调整联络的分量(权重),让平行移动的结果(输出特征)与目标一致,校准的准则是损失泛函的极小化。在这一纤维丛结构中,CNN 的所有架构参数、数据维度、权重参数都被统一到单一的纤维丛张量场中,多隐层的复合是纤维丛上的联络复合,收敛性是纤维丛联络的校准收敛,而张量场‘一元论’ 是纤维丛的整体拓扑结构。 无论纤维(参数)多复杂、基底(架构 + 数据)多高维,其都被纤维丛的整体结构约束,形成一个不可分割的统一场。CNN 等网络的单一高阶张量场是纤维丛结构,所有架构、数据、参数都被统一到纤维丛的整体拓扑中,联合优化是纤维丛联络的整体校准,损失泛函是全局能量准则,让高维高阶的复杂张量操作实现了形散而神不散的整体统一;调整 CNN 的卷积核数、深度、通道数等,本质是改变纤维丛基底的坐标卡,而参数优化是调整纤维丛联络的分量,神经架构搜索(NAS)则是对纤维丛基底与联络的联合优化,是更彻底的单一高阶张量场全局优化。通过张量场的内蕴几何(如曲率、挠率)研究网络的表达能力,通过纤维丛的拓扑不变量研究网络的泛化能力,让深度学习从炼金术般工程性试错走向严谨可靠对称几何化理论。

将CNN视为单一高阶张量的参数化方法能够捕获网络的完整结构特性,这种设计并非简单的参数堆叠,单个层也不再是的独立特性。单一的高阶张量的每一个维度代表网络的一个架构设计参数(如卷积核数量、深度、通道数等),通过反向传播控制出口误差,对整个网络进行联合优化。误差反向传播从输出层开始,误差信号以张量形式反向传播,通过链式法则计算各层参数的梯度。反向传播中的关键步骤是张量收缩,即对误差张量与权重张量进行特定维度的求和,这对应于传统神经网络中的矩阵乘法。通过批量归一化、残差连接等技术,可以优化张量场中的梯度流动,避免梯度消失或爆炸问题。整个CNN网络可视为一个单一的高阶张量,其维度对应网络的架构设计参数(如卷积核数量、深度、通道数)。例如,一个CNN的架构参数(卷积核数量K、深度L、通道数C)对应一个L阶张量,其中每个维度代表一个设计参数。这种设计体现了整体一元论,网络的所有参数(如卷积核权重、全连接层权重)均为该高阶张量的分量,通过反向传播联合优化,实现端到端的训练。从张量场视角看,统一场的本质是张量场的整体变换,每个隐层的线性变换是该高阶张量的一个切片,通过逐层复合,最终实现从输入到输出的全局映射。例如,CNN的卷积层、池化层、全连接层共同构成一个高阶张量场,其整体变换将输入图像映射到分类结果,而每个隐层的变换是该张量场的一个局部参照系调整。张量场的参照系变换具有自适应性,即根据输入数据的结构(如图像的边缘、纹理),自动调整参照系(如卷积核的权重),以实现最有效的特征提取。这种自适应性是深度学习优于传统机器学习的关键是通过张量场的参照系变换,自动适应数据的结构,提取最有效的特征。
深度学习多隐层复合的张量参照系特性,通过逐层张量变换,将数据从原始空间映射到特征空间,并实现整体一元论(整个网络视为单一高阶张量)。而神经网络张量场的收敛性本质,是通过流形优化(如黎曼梯度下降)和反向传播(梯度反向流动),在约束空间内稳定收敛到最优解。CNN 通过张量场的参照系变换(如旋转、缩放、弯曲)实现对数据结构的自适应提取,并通过流形优化(如黎曼梯度下降)保证收敛性。深度学习网络的收敛性(如反向传播的有效性)本质是张量场的流形优化,通过约束张量场的参数空间(如权重张量的低秩性、流形约束),保证优化过程稳定收敛到全局最优或局部最优。流形优化的核心是在约束空间内进行梯度下降,保证参数更新的方向始终在流形上。例如,黎曼梯度下降通过指数映射(将切空间的梯度映射到流形上)和对数映射(将流形上的点映射到切空间),实现参数的稳定更新。反向传播的本质是张量场的梯度反向流动,即通过计算损失函数对各层参数的梯度,调整张量场的参照系(如卷积核的权重),以最小化损失函数。从张量场视角看,反向传播的核心是梯度的链式传递,本质是调整张量场的参照系,使梯度流动更稳定,从而保证收敛性。例如,BN通过归一化将特征图的分布调整到标准正态分布,这对应张量场的参照系缩放,使梯度的大小更适中,避免梯度爆炸。

最新的研究表明,我们可以升级将整个CNN网络视为一个单一的高阶张量。这个张量的每一个维度代表网络的一个架构设计参数(如卷积核数量、深度、通道数等)。通过高阶张量的低秩分解技术,可以对整个网络进行联合优化。这种方法能够捕捉层与层之间的相关性,打破层间分离,从而在减少参数冗余的同时,找到更好的局部最优解。这就像在张量场中寻找一个低维的、紧致的子流形来近似表达整个复杂的网络功能。数据在高维张量场中沿着特定路径流动,被折叠和弯曲,最终在低维流形上呈现出线性可分的结构。将整个网络视为单一高阶张量,利用张量分解技术进行全局优化,消除冗余,提升泛化能力。CNN 与 DNN 的核心区别,在于其张量场具有平移对称性,即参照系的空间坐标平移不改变张量的分量值,这是卷积操作的张量本质。CNN 的卷积缩并是循环卷积张量缩并,其权重张量的空间指标满足平移不变性,这一对称性让 CNN 的张量场成为平移不变张量场,其参照系的空间坐标自由度被大幅降低,无需为每个空间位置定义独立的权重分量,这也是 CNN 比全连接 DNN 更高效的张量场本质 —— 通过对称性约束减少了张量的分量数,让高阶张量的优化成为可能。
实例1. T-CNN张量卷积神经网络,整个网络视为一个高阶张量,其中每个维度代表网络架构参数(如卷积核数量、深度、通道数等)。通过张量分解,将原本庞大的参数空间压缩到一个低维子流形上,使数据在高维张量场中沿着特定路径流动,最终在低维流形上呈现出线性可分的结构,从而实现更高效的优化。将传统CNN的卷积层替换为基于高阶张量分解的张量卷积层,经典CNN的4级权重张量被分解为四个因子矩阵和一个核心张量,因子张量的互连维度控制着数据压缩率和因子部分之间的相关性。效果:参数数量减少4.6倍,训练时间缩短16%,同时保持与传统CNN相当的准确率、召回率和F1分数;缺陷检测漏检率从10%降至4.6%,相比人工检测提升54%的准确性;通过压缩参数空间有效捕捉关键相关性,忽略不必要的信息,大幅降低计算成本和资源消耗。应用场景:罗伯特-博世制造工厂的质量控制系统。
实例2. TNN张量神经网络,将整个网络视为一个高阶张量系统,通过张量分解技术将高维积分问题分解为一系列低维问题。这种分解本质上是在高维张量场中寻找一个低维的、紧致的子流形来近似表达整个复杂的网络功能,使数据在高维空间中被"折叠"到低维流形上,从而实现高效计算。将损失函数中高维积分的计算转化成一维积分的计算,利用经典数值积分格式获得高精度的高维积分。效果:求解精度远超其他机器学习方法,在"大湾区"粤港澳AI for Science科技竞赛中获得特等奖;被Karniadakis教授课题组用于高精度求解20,000维包含耦合势能的Schrödinger方程和高维Fokker-Planck方程;有效突破了"维数灾难"的限制,使高维问题的求解成为可能。应用场景:高维偏微分方程求解(如20,000维Schrödinger方程)
实例3. 张量并行技术,该技术将整个CNN网络视为一个高阶张量,通过张量分解技术将大张量切分为多个小张量并行处理。这种切分本质上是在高维张量场中寻找一个低维子流形,使数据在高维空间中的流动被分解为多个低维空间的并行流动,从而提高计算效率。使用PyTorch DTensor实现张量并行卷积神经网络训练;将输入值和中间激活值切分到多个GPU上,而模型权重和优化器状态复制到各个GPU;采用Shard(3)策略切分(N, C, H, W)的W维度。效果:降低单个GPU的内存占用和带宽压力,解决高分辨率输入导致的GPU内存瓶颈;对于ConvNeXt-XL模型(3.5亿参数),将输入形状为(7, 3, 512, 2048)的数据切分为四个(7, 3, 512, 512)的切片;无需交换数据时直接调用卷积前向和反向算子;需要交换数据时使用特定算法处理边缘数据。应用场景:蔚来汽车自动驾驶系统的感知模型训练
实例4. TRT-ViT将CNN与Transformer的张量融合架构,TRT-ViT将整个网络视为一个统一的张量系统,通过张量分解技术将CNN的平移对称性与Transformer的全局建模能力进行融合。这种融合本质上是在高维张量场中寻找一个既能保持平移对称性又能捕捉长距离依赖的低维子流形,使网络在保持高效计算的同时具备强大的表达能力。字节团队设计的TRT-ViT(TensorRT-Vision Transformer)模型;将CNN和Transformer组合成混合网络,在Stage和Block位置互补;提出4个设计准则:后期Stage使用Transformer、由浅入深的Stage模式、Transformer和BottleNeck混合Block、先全局后局部模式。效果:在ImageNet-1k top-1准确率为82.7%时,比CSWin快2.7倍,比Twins快2.0倍;在MS-COCO目标检测上,推理速度提高2.8倍;在ADE20K语义分割上,推理速度提高4.4倍;在相似TensorRT延迟下,COCO检测性能比ResNet高3.2AP,ADE20K分割性能比ResNet高6.6%。应用场景:图像分类、目标检测和语义分割任务
实例5. 张量特征生成器,该方法将图像特征表示为高阶张量,通过张量分解技术在高维特征空间中寻找一个低维子流形。数据在高维张量场中被"折叠"到这个低维流形上,使原本复杂的分类问题在低维空间中变得线性可分,从而实现快速而准确的分类。提出张量特征生成器替代传统的向量特征表示;直接用张量特征生成新的张量特征,避免过渡为向量特征;与Prototypical Classifier、Logistic Regression和SVM等分类器结合使用。效果:计算量不到张量特征幻觉器的50%,参数量仅为19%;在miniImageNet数据集上,5-way 1-shot分类准确率比Baseline-KD(2)提高2.09%(LR分类器)和3.8%(SVM分类器);在CUB数据集上,5-way 1-shot分类准确率比Baseline-KD(2)提高2.08%(LR分类器)和4.17%(SVM分类器)。应用场景:小样本图像快速分类任务
实例6. 经典的CNN大卷积层(比如一个 3×3×512×512 的四阶张量)分解成小卷积层串联。VGG-16有13个卷积层和3个全连接层,参数量非常大。如果将VGG-16的整个卷积层序列视为一个超级张量,进行全局的低秩TT分解。输入一张 224×224×3 的彩色图片;数据在由这个超级张量定义的“流形”上流动;TT分解发现,虽然VGG-16的卷积核在数值上是独立的,但在“函数空间”中存在大量跨层冗余。比如,第一层提取的边缘特征和后面某层提取的纹理特征之间存在某种耦合关系。全局优化可以识别并去除这种耦合中的冗余部分。效果:实验表明将全连接层(本质是一个巨大的二维矩阵)进行TT分解,可以实现100倍以上的参数压缩,而精度损失极小。对于卷积层,也能在压缩几倍参数的同时,有时甚至因为去除了噪声而提升泛化能力,找到比原始局部最优解更好的点。应用场景:通过张量分解进行参数压缩
实例7. T-Net 单一高阶张量参数化整个CNN,用单个8阶张量 Θ ∈ ℝ^{R₁×R₂×...×R₈} 参数化整个全卷积网络(FCN),这个8阶张量的8个维度分别对应: 卷积块数量 (Number of blocks)、 块内深度 (Depth within block)、 卷积核高度 (Kernel height)、 卷积核宽度 (Kernel width)、 输入通道数 (Input channels)、 输出通道数 (Output channels)、 空间高度 (Spatial height)、 空间宽度 (Spatial width),将上述所有卷积层合并为一个8阶张量,通过分解:Θ = C ×₁ U₁ ×₂ U₂ ×₃ ... ×₈ U₈,其中 C 是核心张量(捕捉层间相关性)、 Uᵢ 是各维度的因子矩阵。效果:压缩率 4倍:精度保持,甚至略有提升(低秩的正则化效应);压缩率 65倍:精度下降仅约5%;压缩率 135倍:仍保持可用精度;应用场景:高压缩率下T-Net优于逐层分解,捕捉了跨层依赖。
实例8. TT-LC与混合分解双层分解策略,第一层TT分解(Tensor-Train),第二层Tucker分解对TT核心进一步分解,保留空间结构信息。贝叶斯自动选秩,使用EVBMF(经验变分贝叶斯矩阵分解)自动确定每层最优秩,避免人工无意义调参。效果:(ResNet-32 on CIFAR-10)参数量压缩率:69.6%;FLOPs压缩率:66.7%;精度保持92.22%(原精度约93%)。应用场景:张量场视角下的数据流形
实例9. Tensor-GaLore 高阶张量低秩分解处理复杂系统,将这一思想应用于傅里叶神经算子(FNO)的训练。傅里叶系数是高阶张量(4D:batch × modes × channels × spatial),优化器状态(Adam的momentum/variance)内存占用巨大。Tensor-GaLore解决方案,对梯度张量使用Tucker分解:G ≈ C ×₁ U ×₂ V ×₃ W,在低秩子空间中更新优化器状态。效果:内存节省:75%;保持张量结构(不展平为矩阵),保留物理可解释性。应用场景:求解Navier-Stokes方程(高分辨率PDE)

https://blog.sciencenet.cn/blog-1666470-1524239.html
上一篇:深度学习多隐层架构数理逻辑浅析(十八)(2)
下一篇:深度学习多隐层架构数理逻辑浅析(十八)(4)
