博文
一种新的基于迁移学习的跨项目缺陷预测方法
||
随着软件系统的规模不断的扩大,为了提高软件的质量,软件缺陷预测技术近几年来日益受到关注。其中,如何进行跨项目缺陷预测是该技术需要考虑的一个重要问题,但是由于不同的项目之间的数据分布情况存在者一定的差异,传统的同项目软件缺陷预测方法很难适应跨项目缺陷预测;而目前已有的跨项目缺陷预测方法往往较少考虑到缺陷预测数据中存在的类别不平衡问题。基于上述的问题,本文提出了一种基于样本权值的采样方法,并将其与迁移学习方法相结合提出了一种新的跨项目软件缺陷预测方法TSboostDF。在本文中将其与现有软件缺陷预测方法进行对比,实验表明TSboostDF相较于已有的缺陷预测方法具有一定的先进性。
成果简介
TSboostDF分为初始化、训练和预测三个阶段。在初始化阶段中,我们对源项目中的每一个数据赋予两个权值(即样本权值和相似权值),并对其进行初始化;在训练阶段中,我们训练若干个基分类器,且在每次训练基分类器前,我们依据样本权值对源项目中的所有样本进行抽样重新构建训练集和测试集,然后在这些数据集上训练基分类器并计算该分类器的权值。在预测阶段中,TSboostDF将训练得到所有基分类器,依据其权值集成起来对样本进行分类。
具体来说,在初始化阶段中我们对源项目中每一个样本赋予两种不同的权值,即相似度权值和样本权值,其中相似度权值被用于度量源项目中的样本与目标领域的相似程度,而样本权值被用于度量抽样概率。
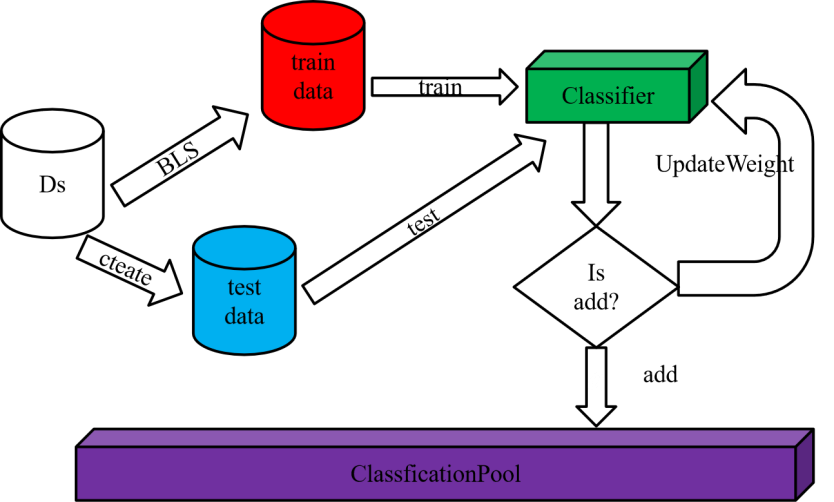
如图所示,在训练阶段中,我们使用类似booting的策略训练出若干个基分类器并将其加入一个分类器集合ClassficationPool中。具体来说,我们分为如下几个步骤构建每个基分类器。第一步,我们从训练数据中相似权值较大的样本集里按一定比例抽取若干个样本构成测试集;第二步,依据对样本权值对训练样本进行抽样构建训练集,并在这个训练集上建立一个基分类器;第三步,在测试集上对新建立的基分类器进行测试并根据其性能调整数据的样本权值。然后,当其性能不至于太差时,则计算训练集与目标项目分布的相似距离并将该基分类器加入ClassficationPool中,否则将重复第二步直至构建出合适的训练集为止。最后,将根据分布之间的相似距离对各个基分类器分配不同的权值。在预测阶段中将训练得到的基分类器依据计算的权值集成起来对目标项目进行预测。
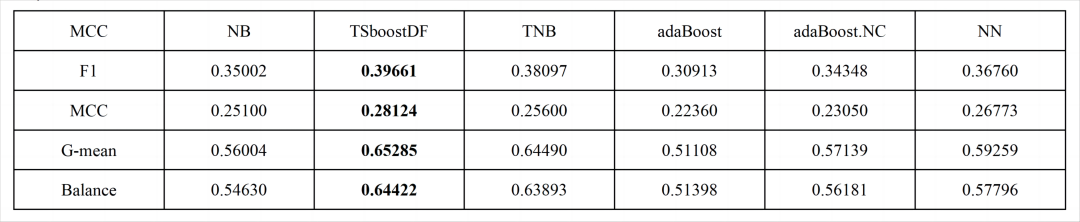
在实验部分,本文将TSBoostDF与传统机器学习方法朴素贝叶斯(NB)、adaBoost、adaBoost.NC以及迁移学习方法TNB和NN进行对比。实验表明:TSBoostDF相较于其他方法不但在综合性能评指标F1值和MCC值上取得较好的效果,同时也在类别不平衡评价指标G-mean值以及Balance值上也取得了较好的效果。
文章来源
S. Tang, S. Huang, C. Zheng, E. Liu, C. Zong and Y. Ding, "A novel cross-project software defect prediction algorithm based on transfer learning," in Tsinghua Science and Technology, vol. 27, no. 1, pp. 41-57, 2022.
点击阅读全文:https://www.sciopen.com/article/10.26599/TST.2020.9010040
期刊介绍
清华大学学报自然科学版(英文版)(Tsinghua Science and Technology)于1996年创刊,由中国工程院院士、清华大学教授孙家广担任主编。致力于反映计算机和电子工程领域具有创新性和重要性的研究成果。被SCIE、Scopus、Ei Compendex、CSCD等国内外重要数据库收录。2018年获“第四届中国出版政府奖期刊奖提名奖”。2019年入选“中国科技期刊卓越行动计划”梯队期刊项目。
https://blog.sciencenet.cn/blog-3534092-1367956.html
上一篇:双堆点亮清华梦,一甲绽开百拾香——清华大学核研院60周年院庆专刊
下一篇:喜讯丨iEnergy 被DOAJ数据库收录