ВЉЮФ
Ъ§ОнЭкОђСьгђБиаыЪьЯЄЕФЪЎДѓОЕфЫуЗЈЦфШ§ЁЊЁЊSVM
|||
ЙњМЪШЈЭўбЇЪѕзщжЏIEEE International Conference on Data MiningЦРГіСЫЪ§ОнЭкОђСьгђЕФЪЎДѓОЕфЫуЗЈЁЃдкеце§НјШыЪ§ОнЭкОђЫуЗЈЕФбЇЯАжЎЧАЃЌетЪЎИідкИУСьгђВњЩњСЫЩюдЖгАЯьЕФЫуЗЈгІИУгХЯШбЇЯАвЛЯТЁЃ
зЂЃКБОЮФЪЧЖдЁЖДѓЪ§ОнЁЂЪ§ОнЭкОђгыжЧЛлдЫгЊзлЪіЁЗЕквЛеТЕФжиаТЪсРэЃЌВЂМгШыСЫздМКЕФРэНтЁЃУПИіЫуЗЈжЛЪЧМђЕЅНщЩмЃЌШеКѓЛсЯъЯИбаОПЁЃ
3.svmЃКжЇГжЯђСПЛњ
ЫќЪЧвЛжжМрЖНЪНбЇЯАЗНЗЈЃЌЙуЗКгІгУгкЭГМЦЗжРрвдМАЛиЙщЗжЮіжаЁЃsvmЕФЫМЯыЪЧЪЙгУвЛжжЗЧЯпадгГЩфНЋЯђСПгГЩфЕНвЛИіИќИпЮЌЕФПеМфЃЌбАевдкДЫПеМфЯТзюДѓМфИєЕФГЌЦНУцЃЈвВПЩГЩЮЊОіВпБпНчЃЉЁЃжЛвЊЮЌзуЙЛИпЃЌЗЧЯпадгГЩфзуЙЛКЯЪЪЃЌетИізюДѓМфИєЦНУцзмЛсевЕНЁЃГЌЦНУцПЩвдгаЮоЪ§ИіЁЃдкГЌЦНУцЕФСНБпНЈСЂСНИіЛЅЯрЦНааЕФГЌЦНУцЁЃЗжИєГЌЦНУцЪЙСНИіЦНааГЌЦНУцЕФОрРызюДѓЛЏЁЃОрРыдНДѓЃЌзмЮѓВюОЭдНаЁЁЃ

svmзюДѓЕФСНИігХЕуЃЌвЛЪЧМЦЫуМђЕЅЃЌЖўЪЧТГАєадЧПЃЌВЛашвЊЖюЭтЕФЮЂЕїЁЃ
svmПЩвдРћгУвбжЊЕФгааЇЫуЗЈРДгХЛЏздЩэЃЌЕЋЮвУЧЪЙгУЪБашвЊЬсЙЉЦфЫћВЮЪ§ЁЃЦфжазюЙиМќЕФШ§ИіЃКЪЙгУЕФКЫКЏЪ§ВЮЪ§gЃЌЮЊСЫв§ШыЪ§ОнБфЛЏЫљашЕФГЭЗЃЯЕЪ§CЃЌВЛУєИаЫ№ЪЇКЏЪ§ВЮЪ§ІХЁЃ
svmЕФГЭЗЃЯЕЪ§CЁЂКЫКЏЪ§ВЮЪ§gЁЂВЛУєИаЫ№ЪЇКЏЪ§ВЮЪ§ІХЕШ3ИіЙиМќВЮЪ§жБНггАЯьдЄВтОЋЖШЁЃВЛУєИаЫ№ЪЇКЏЪ§ВЮЪ§ІХжЕдНДѓжЇГжЯђСПЪ§дНЩйЃЌЕУЕНЕФНтБэДяЪНдНЯЁЪшЃЌЛиЙщдЄВтЕФОЋЖШНЕЕЭЃЛГЭЗЃЯЕЪ§CаЁгквЛЖЈжЕЪБбЕСЗЮѓВюБфДѓЃЌДѓгквЛЖЈжЕЪБФЃаЭЗКЛЏФмСІБфВюЃЛКЫКЏЪ§ВЮЪ§gаЁгквЛЖЈжЕЪБвзВњЩњЙ§бЇЯАЃЌДѓгквЛЖЈжЕЪБвздьГЩЧЗбЇЯАЁЃЫљвдЖдsvmЫуЗЈЕФбаОПДѓВПЗжЖМЪЧеыЖдетШ§ИіКЏЪ§ШЁжЕЕФгХЛЏЁЃШчКЮВЛЗбЪБгжФмевЕНзюМбВЮЪ§ЃЌЯТУцзмНсвЛЕуНќЦкТлЮФЕФЗНЗЈЁЃ
PSO-svm(Particle Swarm Optimization)ЃКСЃзгШКЫуЗЈгХЛЏжЇГжЯђСПЛњ
етжжЗНЗЈв§ШыСЃзгШКЫуЗЈЖджЇГжЯђСПЛњФЃаЭВЮЪ§бАгХЙ§ГЬНјаагХЛЏЃЌНЋЖдбЕСЗМЏНјааНЛВцбщжЄЗЈЯТЃЈsvmбАевШ§ИіВЮЪ§ЕФЭЈГЃЗНЗЈЃЉЕФзюаЁОљЗНВюзїЮЊPSOжаЕФЪЪгІЖШКЏЪ§жЕЃЌЭЈЙ§СЃзгдкНтПеМфзЗЫцзюгХЕФСЃзгНјааЫбЫїЃЌбАЧѓзюгХНтЁЃ
ЫќЪзЯШЖдбљБОЪ§ОнНјааЙщвЛЛЏДІРэЁЃЙщвЛЛЏДІРэЕФФПЕФдкгкНЋВЛЭЌСПИйЕФдЪМЪ§ОнЙцећЕНЙЬЖЈЧјМфЃЌШчЃК[0ЃЌ1]ЁЃдйЛЎЗжбЕСЗМЏКЭдЄВтМЏЃЌНЈСЂжЇГжЯђСПЛњФЃаЭЃЌНсКЯPSOЫуЗЈевЕНВЮЪ§[C,g,ІХ]ЕФзюгХНтЁЃЫцКѓЖдЕУГіЕФФЃаЭНјааЦРЙР
MFO-svm(Moth-Flame Optimization):ЗЩЖъЦЫЛ№ЫуЗЈгХЛЏжЇГжЯђСПЛњ
ЁЁЁЁЗЩЖъдкЗЩаажаБЃГжЯрЖдгкдТЧђЕФЙЬЖЈНЧЖШЃЌЕБЗЩЖъПДЕНШЫдьЙтЪБЃЌЫќУЧЛсЪдЭМБЃГжгыЙтЯпЯрЫЦЕФНЧЖШжБЯпЗЩааЃЌЕЋгЩгкетбљЕФЙтЯпБШдТЧђЕФЙтЯпОрРыНќКмЖрЃЌвђДЫгыЙтдДБЃГжЯрЫЦЕФНЧЖШЛсЕМжТЗЩЖъЮогУЕФЛђжТУќЕФТна§ЗЩааТЗОЖЃЌЗЩЖъзюжеЛсЯђЙтЪеСВЃЎЭЈЙ§ЖдИУааЮЊНЈФЃЃЌЬсГіЃЈЃЭЃЦЃЯЃЉЫуЗЈЃЎНЋЃуКЭЃчСНИіВЮЪ§зїЮЊЃЭЃЦЃЯЫуЗЈЕФгХЛЏБфСПЃЌНЋЃгЃжЃЭзїЮЊЃЭЃЦЃЯЕФЦРЙРКЏЪ§ЃЌетОЭЪЧMFO-svmЕФКЫаФЫМЯыСЫЁЃ
GA-svm(Genetic Algorithm):вХДЋЫуЗЈгХЛЏsvm
вХДЋЫуЗЈЪЧЛљгкздШЛбЁдёКЭЩњЮявХДЋЛњжЦЃЌгУгкШЋОжгХЛЏЁЂЗжРрвдМАЦфЫћЪ§ОнЭкОђММЪѕЕФЪЪКЯЖШНјааЦРМлЕФЗНЗЈЁЃ
ДѓжТСїГЬЮЊЃК
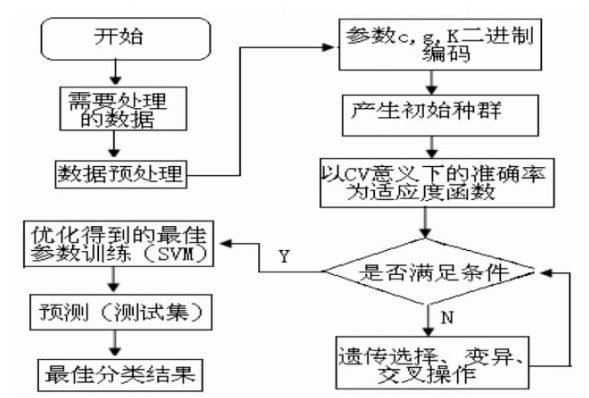
гаЛњЛсЮвЛсЖдДѓВПЗжЕФsvmгХЛЏЫуЗЈзівЛЯТКсЯђБШНЯЁЃ
https://blog.sciencenet.cn/blog-3401624-1157930.html
ЩЯвЛЦЊЃКЪ§ОнЭкОђСьгђБиаыЪьЯЄЕФЪЎДѓОЕфЫуЗЈЦфЖўЁЊЁЊCARTЫуЗЈ
ЯТвЛЦЊЃКЪ§ОнЭкОђСьгђБиаыЪьЯЄЕФЪЎДѓОЕфЫуЗЈЦфвЛЁЊЁЊAprioriЫуЗЈ
ШЋВПзїепЕФЦфЫћзюаТВЉЮФ
ШЋВПОЋбЁВЉЮФЕМЖС
ЯрЙиВЉЮФ
- • УРЙњзєжЮбЧДѓбЇЕШЛњЙЙбЇепЃКизИюВпТдЖдBulldog 805зЯЛЈмйоЃ+Tifton 85ЙЗбРИљЛьВЅВнЕиВњСПМАЦЗжЪЕФгАЯь
- • УРЙњПАШјЫЙжнСЂДѓбЇЁЂУмЫеРяДѓбЇЕШЛњЙЙбЇепбаОПГЩЙћЃКЭСШРЫЎЗжЙмРэВпТдКЭЦЗжжЖрбљадЖдзЯЛЈмйоЃВњСПЁЂгЊбјЦЗжЪКЭХЉГЁгЏРћФмСІЕФгА
- • ЕТЙњЁЂНнПЫВнвЕПЦбЇбЇепГЄЦкЗХФСЪЕбщЃКвьжЪВнЕиАпПщжаЕФЭСШРгаЛњЬМДЂСПКЭЕиЯТЩњЮяСП
- • ШчКЮВХФмСЌајБЛЦРЮЊЪЎФъЁАжаЙњИпБЛв§бЇепЁБЃПЁЊЁЊЖдЛАЩЯКЃДѓбЇЭѕЧфЮФНЬЪк
- • C2CЃКФЯВ§ДѓбЇбЇепЬсГібЇЪѕНЛСїаТИХФю
- • бЇепЮЊЪВУДЕУЗЂБэЮФеТЃП