博文
面向可信自动驾驶策略优化: 一种对抗鲁棒强化学习方法
|
引用本文
何祥坤, 赵洋, 房建武, 程洪, 吕辰. 面向可信自动驾驶策略优化: 一种对抗鲁棒强化学习方法. 自动化学报, 2025, 51(11): 2473−2485 doi: 10.16383/j.aas.c250193
He Xiang-Kun, Zhao Yang, Fang Jian-Wu, Cheng Hong, Lv Chen. Toward trustworthy policy optimization for autonomous driving: An adversarial robust reinforcement learning approach. Acta Automatica Sinica, 2025, 51(11): 2473−2485 doi: 10.16383/j.aas.c250193
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c250193
关键词
自动驾驶,智能交通,强化学习,可信人工智能
摘要
虽然强化学习近年来取得显著成功, 但策略鲁棒性仍然是其在安全攸关的自动驾驶领域部署的关键瓶颈之一. 一个根本性挑战在于, 许多现实世界中的自动驾驶任务面临难以预测的环境变化和不可避免的感知噪声, 这些不确定性因素可能导致系统执行次优的决策与控制, 甚至引发灾难性后果. 针对上述多源不确定性问题, 提出一种对抗鲁棒强化学习方法, 实现可信端到端控制策略优化. 首先, 构建一个可在线学习的对手模型, 用于同时逼近最坏情况下环境动态扰动与状态观测扰动. 其次, 基于零和博弈建模自动驾驶智能体与环境动态扰动之间的对抗性. 再次, 针对所模拟的多源不确定性, 提出鲁棒约束演员–评论家算法, 在连续动作空间下实现策略累积奖励最大化的同时, 有效约束环境动态扰动与状态观测扰动对所学端到端控制策略的影响. 最后, 将所提出的方案在不同的场景、交通流及扰动条件下进行评估, 并与三种代表性的方法进行对比分析, 验证了该方法在复杂工况和对抗环境中的有效性与鲁棒性.
文章导读
自动驾驶作为智能网联新能源汽车的核心技术之一, 深度融合人工智能、电子信息、车辆工程与自动化等多个学科, 已成为新一轮科技革命和产业变革中的关键突破方向以及具身智能的重要研究领域. 虽然近年来自动驾驶技术取得显著进展, 但实现高智能、高可信的自动驾驶仍面临诸多基础理论与技术难题, 亟须持续深入的跨学科创新与系统性突破.
传统自动驾驶系统通常采用分层架构设计, 包括感知、预测、决策、规划、控制等多个独立子模块. 尽管这种方法在可解释性、可调试性和工程实现方面具有一定优势, 但由于各模块间的信息传递存在误差累积与信息丢失, 且各模块的独立优化缺乏全局信息支持, 难以确保整个系统的全局最优性[1−2]. 近年来, 神经网络驱动的自动驾驶范式通过多模型联合优化实现梯度信息的全局传递. 特别是基于一段式神经网络模型的端到端自动驾驶系统, 能够通过梯度信息的无损传递构建全局优化框架, 深度融合感知、决策与控制, 理论上具备更强的智能涌现能力, 有助于实现类人驾驶的智能学习与自主决策, 并有望克服传统模块化架构的局限性[3]. 策略优化作为神经网络驱动的自动驾驶系统核心技术之一, 目前相关研究主要围绕模仿学习(Imitation learning, IL)和强化学习(Reinforcement learning, RL)两大范式展开.
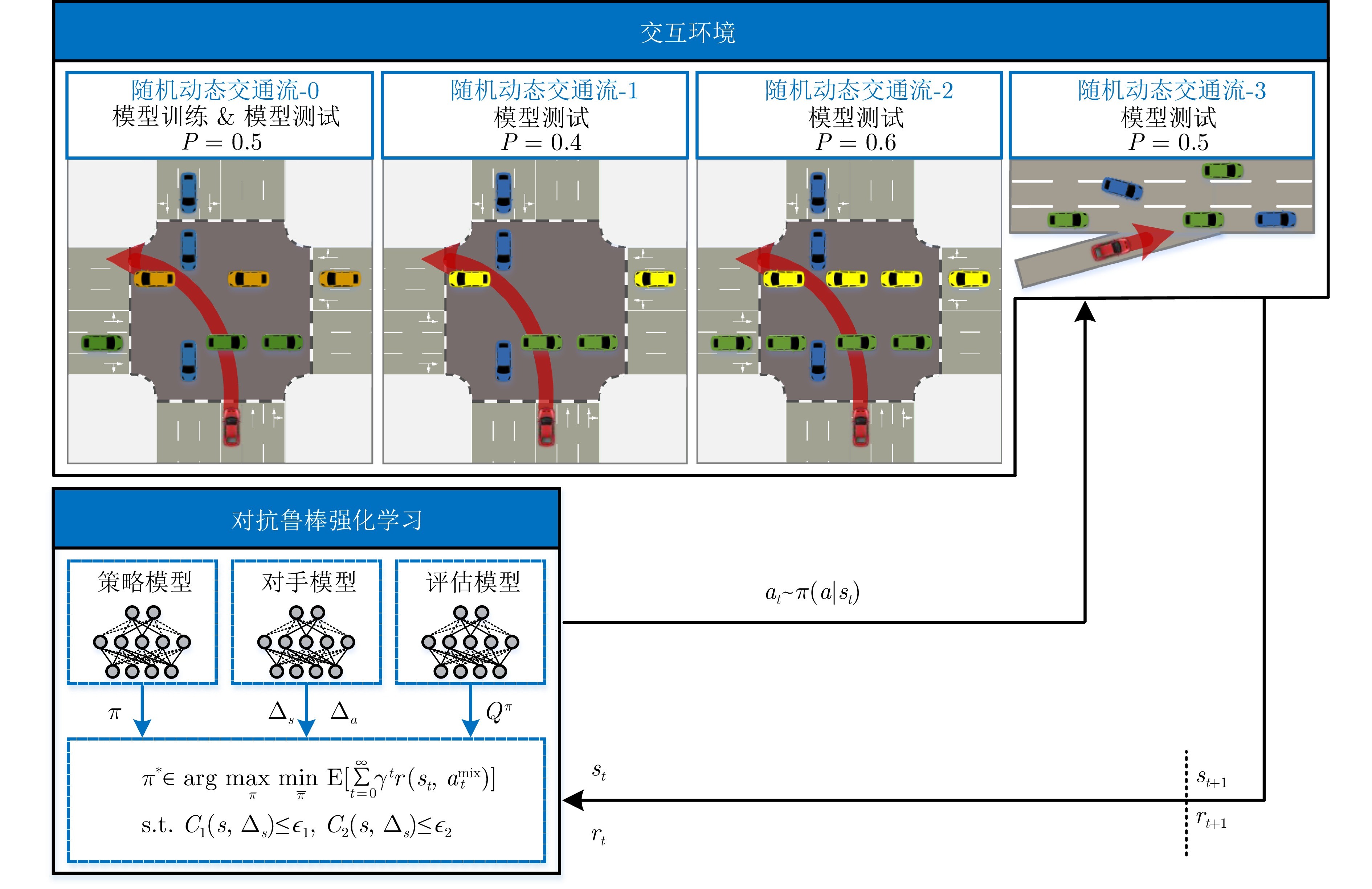
图1 面向可信自动驾驶策略优化的对抗鲁棒强化学习框架

图2 自动驾驶策略模型的评估方案((a)和(b)分别表示自动驾驶智能体在无对抗观测扰动和 存在对抗观测扰动下的评估方案)
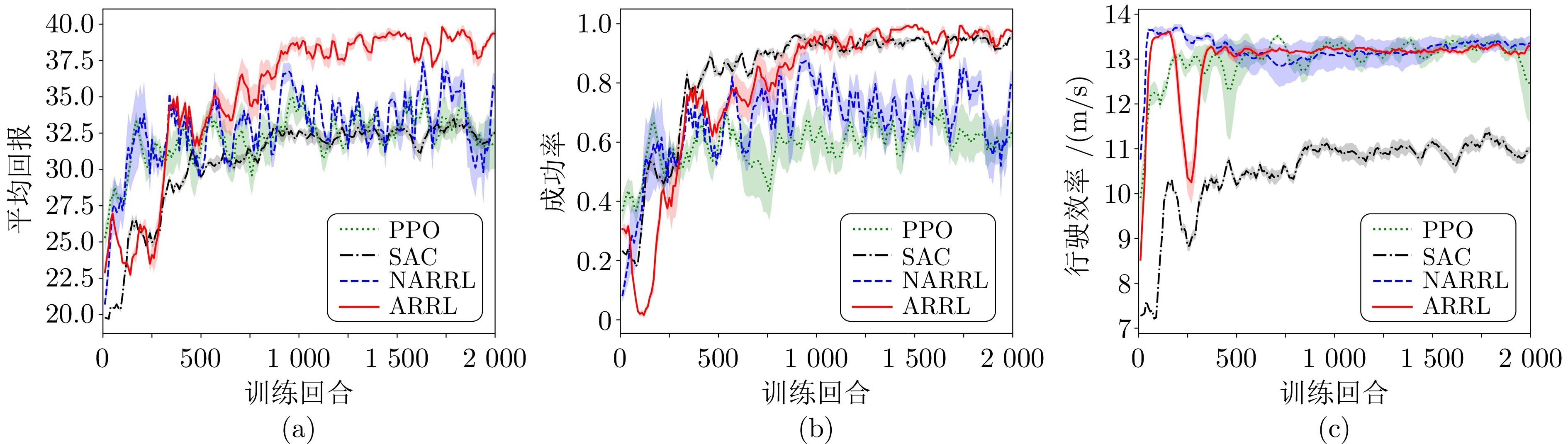
图3 不同强化学习方法训练的策略模型性能对比((a) ~ (c)分别展示各模型在平均回报、成功率及行驶效率方面的性能)
本文针对多源不确定性挑战, 提出一种面向自动驾驶的对抗鲁棒强化学习方法, 实现可信端到端控制策略优化. 本研究在具有连续动作空间的交叉口场景和匝道汇入任务中, 评估了所提出的 ARRL 方法对环境动态扰动和状态观测扰动的鲁棒性. 通过在不同场景、交通流密度和攻击条件下与三种代表性方法的对比分析, 验证了ARRL方法的有效性与性能优势. 尤其在碰撞率和鲁棒性方面, 本文所提出的方法展现出显著优越性, 体现其在提升模型可信性方面的有效性.
尽管本研究为实现可信端到端自动驾驶策略优化提供了一种有潜力的解决方案, 但仍存在三方面的局限性: 目前的工作缺乏可验证的理论保障, 且依赖于相对小规模的模型与仿真环境. 未来的研究将围绕以下三个方向展开: 首先, 从理论层面开展对ARRL鲁棒性的形式化验证方法研究; 其次, 探索将大语言模型或其他基础模型与ARRL框架高效融合机制; 最后, 在真实自动驾驶平台上部署ARRL策略模型, 通过实车测试, 评估其在现实场景中的有效性与可行性.
作者简介
何祥坤
电子科技大学研究员. 主要研究方向为自动驾驶, 强化学习, 可信AI, 决策与控制. E-mail: xiangkun.he@uestc.edu.cn
赵洋
电子科技大学副研究员. 主要研究方向为模式识别与机器学习, 计算机视觉, 智能汽车. E-mail: yzhao@uestc.edu.cn
房建武
西安交通大学研究员. 主要研究方向为交通场景理解与智能驾驶. E-mail: fangjianwu@mail.xjtu.edu.cn
程洪
电子科技大学教授. 主要研究方向为模式识别与机器学习, 计算机视觉, 机器人. E-mail: hcheng@uestc.edu.cn
吕辰
南洋理工大学副教授. 主要研究方向为自动驾驶, 机器人, 人机系统. 本文通信作者. E-mail: lyuchen@ntu.edu.sg
https://blog.sciencenet.cn/blog-3291369-1515010.html
上一篇:工业垂域具身智控大模型构建新范式探索
下一篇:基于深度语义扩散的深度图修复: 缺陷数据集与模型