博文
清华大学集成电路学院——面向片上学习系统的 ADAM 算法加速器 | MDPI Electronics
||
文章导读
近年来,片上学习系统成为了重要的研究热点。以自适应矩估计 (Adaptive moment estimation, ADAM) 为代表的二阶优化器在神经网络训练中具有显著的收敛优势。如图1所示,此类优化器的实现需要计算二阶矩,依赖于复杂的平方、开方、除法等运算,因此大幅提高了片上部署的时间、空间复杂度。针对此问题,来自清华大学集成电路学院的张春研究员及其团队在Electronics期刊“Artificial Intelligence Circuits and Systems (AICAS)”栏目中发表了文章,提出了Hardware-ADAM这一包含两种ADAM算法的加速器设计。
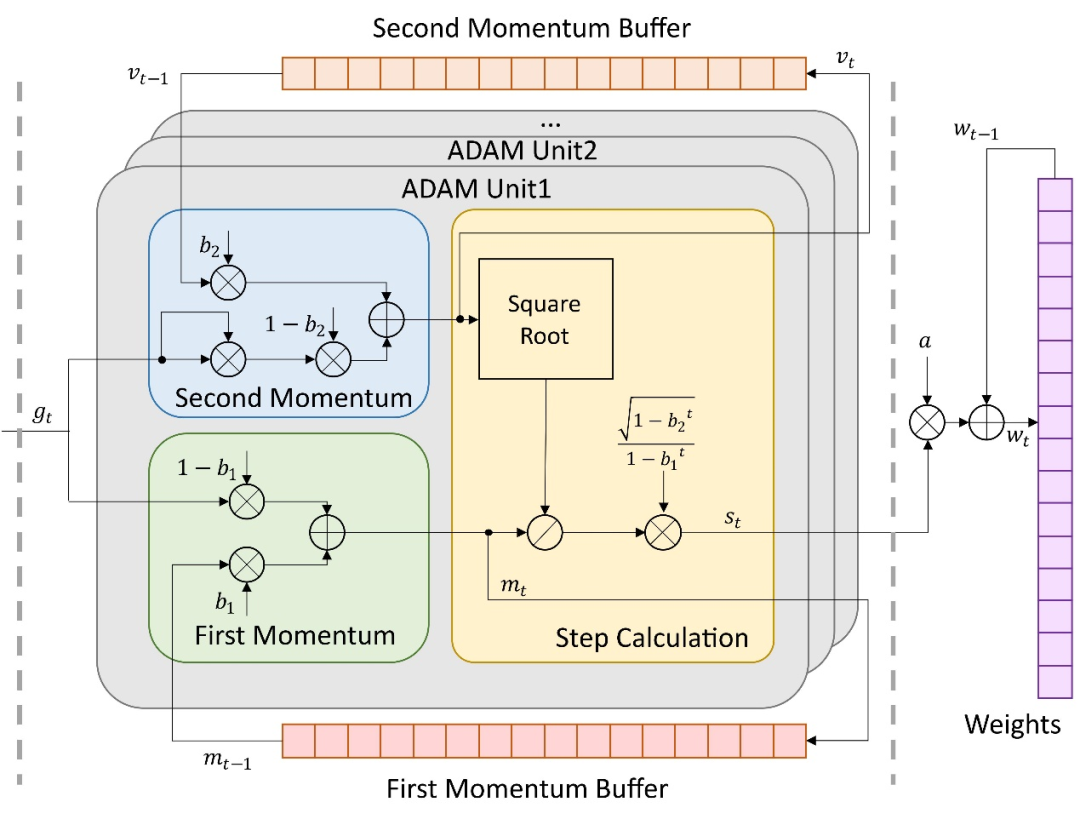
图1. ADAM算法原理图。
研究过程与结果
首先,为减小ADAM算法所涉及到的平方、开方运算产生的资源、时间开销,作者提出了Efficient-ADAM (E-ADAM) 优化器,并引入了近似运算,如图2所示。研究中所引入的近似最大误差为5.72%,能够满足神经网络训练过程中的精度需求。同时,如图3所示,对于定点数形式的运算,此近似在低位宽的情况下,能够避免出现绝对误差为100%的计算“盲区”,从而使E-ADAM算法具有比原算法更广的输入范围。在E-ADAM的基础上,为进一步提高系统吞吐率,作者引入快速平方根倒数原理并应用于除法中,提出了Fast-ADAM (F-ADAM),对系统中的除法运算进行了优化。

图2. 对平方与开方运算的近似公式及证明。
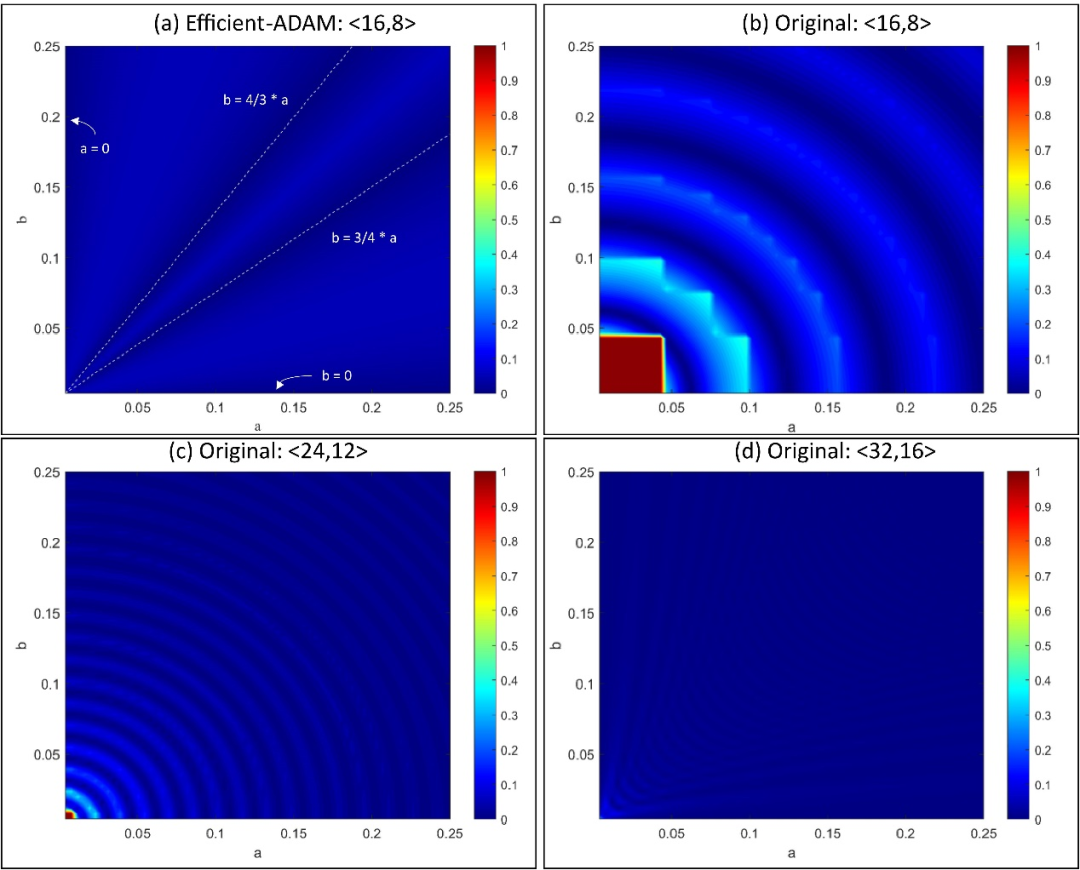
图3. 近似算法 (a) 与原始算法 (b)、(c) 和 (d) 的相对误差分析。
为验证设计的功能可行性与性能水平,作者使用Vivado 2018.3高层次综合工具对所提出的设计进行部署,部署平台为Ultra96-v2开发板。训练环境为PyBullet Gymperium提供的强化学习环境HalfCheetah。
研究总结
本研究提出了应用于片上学习系统的Hardware-ADAM设计,并验证了所提出设计的功能与性能。其中E-ADAM相比于原始ADAM节约了90%的资源占用,并达到了2.8倍的吞吐率;F-ADAM实现了16.4倍的吞吐率,同大幅节约了寄存器、查找表的资源占用。针对不同需求应用E-ADAM与F-ADAM能够在片上学习任务中有效减少优化器部分产生的时间、资源开销。同时,本研究所引入的运算近似思想,包括对平方、开方算法的改进,以及对快速平方根倒数算法的化用,能够作为其他算法的硬件部署的参考,应用于各种算法的硬件设计。
原文出自 Electronics 期刊:https://www.mdpi.com/2050604
Zhang, W.; Niu, L.; Zhang, D.; Wang, G.; Farrukh, F.U.D.; Zhang, C. HW-ADAM: FPGA-Based Accelerator for Adaptive Moment Estimation. Electronics 2023, 12, 263.
Electronics 期刊介绍
主编:Flavio Canavero, Politecnico di Torino, Italy
期刊涵盖的研究包括但不限于以下领域:电子材料、微电子学、光电子电、工业电子、电力电子、生物电子、微波和无线通信、计算机科学与工程、系统与控制工程、电路和信号处理、半导体器件、人工智能、电动和自动驾驶汽车、量子电子等。期刊致力于快速发表与广泛电子领域相关的、最新的技术突破以及前沿发展。
2021 Impact Factor:2.690
2021 CiteScore:3.7
Time to First Decision:14.4 Days
Time to Publication:34 Days


https://blog.sciencenet.cn/blog-3516770-1378727.html
上一篇:米面主食偏好与肥胖表型的关联——基于十余万中国人的研究 | MDPI Nutrients
下一篇:对话JPM客座编辑姜楠博士——骨感染的发病机制 | MDPI 人物专访