博文
量子计算机跨越关键的错误阈值  精选
精选
||
量子计算机跨越关键的错误阈值
研究者史无前例地证实往量子计算机添加更多“量子比特”会让她更加坚韧。这是通往实际应用的漫漫长路中的必要步骤。
Ben Brubaker 著
左 芬 译
【译注:原文2024年12月9日刊载于QuantaMagazine,链接见文末。】

如何用不完美的零件构造出一台完美的机器来?这是建造量子计算机的研究者们面临的核心挑战。麻烦在于他们的基础构建模块,也就是所谓量子比特,对外部世界的干扰极为敏感。当前的量子计算机原型机太容易出错,还排不上什么用场。
1990年代,研究者们为所谓量子纠错这种克服这些错误的方法奠定了理论基础。其关键思想是,将一团物理量子比特组装成单个高品质的“逻辑量子比特”。计算机接着会使用许多这样的逻辑量子比特来执行运算。就这样把大量有瑕疵的零件转化为少量可靠的,他们就能制造出完美的机器来。
“就我们所知这确实是建造大尺度量子计算机的唯一途径。”谷歌量子人工智能实验室的纠错研究者Michael Newman称。
这一计算性魔术有其局限性。如果物理量子比特过分易错,纠错就会适得其反——添加更多的物理量子比特会让逻辑量子比特更差,而非更好。可是一旦错误率低于一个特定的阈值,天平就会向另一侧倾斜:你添加的物理量子比特越多,每个逻辑量子比特就会越坚韧。
如今,在今天发表于《自然》的一篇文章中,Newman与其在谷歌量子人工智能实验室的同事最终越过了这一阈值。他们将一团物理量子比特转换成单个逻辑量子比特,接着证实,当向团中加入更多物理量子比特时,逻辑量子比特的错误率急剧地下降。

谷歌量子人工智能实验室的一名研究者正在谷歌超导量子计算机前工作。
“整个故事都取决于这种规模化,”量子计算公司量子统【译注:即Quantinuum】的一名物理学家David Hayes说道,“看到这得以实现真的令人激动。”
多数派规则
最简单的纠错版本运作于常规的“经典”计算机上,其中信息以比特串来表示,也就是一些0和1。任何翻转比特值的随机故障都会导致错误。
你可以把信息扩散到多个比特来抵御错误。最基本的方法是将每个0重写为000,每个1重写为111。每当三比特组不是统一取值时,你就知道发生了错误,并且可以通过多数派投票来修正出错的比特。
但这一程式并不总是可行,如果三元组中的两个比特同时遭受了错误,多数派投票会返回错误的答案。

Michael Newman(左), Kevin Satzinger(右)与谷歌量子人工智能实验室的同事们证实对量子纠错码加以扩展可改进性能。
为了避免这一点,你可以增加每个组中比特的数目。例如,在这种“重复码”的五比特版本中,每个组可以忍受两个错误。不过尽管这一扩大后的编码可以处理更多错误,你也引入了更多可能出错的方式。只有当单个比特的错误率低于一个特定阈值时,净效果才会是有益的。如果没有实现这一点,增加更多的比特只会使出错情况更加糟糕。
一般来说,在量子世界里,情况会更加棘手。相比于经典的同伴,量子比特受制于更多类型的错误。这使得操控它们更加困难。量子计算中的每一步都是错误的又一个来源,包括纠错过程本身。此外,测量量子比特的态会不可逆转地扰动它——你必须设法在不直接观察它们的前提下诊断出错误。这一切意味着量子信息必须非常小心地加以处理。
“它生来就脆弱得多,”加州理工学院的量子物理学家John Preskill说道,“你得考虑到所有可能出错的环节。”
最初,许多研究者认为量子纠错根本不可行。他们的看法在1990年代中期被证明是错的,当时人们构造出了量子纠错码的简单范例。不过这仅仅让情况从彻底无望变为望而生畏。
当研究者弄清楚细节后,他们意识到必须将物理量子比特上每次操作的错误率降到0.01%以下——10000次中仅允许一次错误。而这还只是让他们抵达阈值。他们实际上需要远远超越它——不然的话,当更多的物理量子比特加入时逻辑量子比特的错误率只会极其缓慢地降低,使得纠错在实践中不可行。
根本没人知道如何将一个量子比特做到足够好。不过人们后来发现,这些早期编码仅仅触及了冰山一角。
表面码
1995年,俄国物理学家Alexei Kitaev从新闻报道中得知了量子计算的一个重大理论突破。此前一年,美国应用数学家Peter Shor开发出一个量子算法,可从大的整数分解出其素因子。Kitaev没法获得Shor文章的拷贝,于是从头开始构想出了这一算法的另一版本——甚至比Shor算法用途更为广泛。Preskill对此兴奋不已,于是邀请Kitaev来加州理工学院访问。

Alexei Kitaev首次提出了一种有望的量子纠错理论方法,即表面码。
“Alexei是个真正的天才,”Preskill称,“我极少见到有人达到他那种程度的聪慧。”
1997年春天的这次短暂访问收益颇丰。Kitaev告知Preskill他正在探索的两个新想法:完全无需主动纠错的一种“拓扑”量子计算方法,以及基于类似数学的一种量子纠错码。起初,他并不认为这一编码会对量子计算有用。Preskill对此更加看好,并说服Kitaev去对他原始想法的一种细微变种加以深究。
这一变种,即所谓表面码,构建在两套相互交错的物理量子比特晶格之上。第一套晶格上是“数据”量子比特。这些共同编码出一个逻辑量子比特。第二套上则是“测量”量子比特。这些允许研究者间接地窥探错误,而不会干扰计算。
这需要大量量子比特。不过表面码也有其它优点。它的错误检验方案比那些争竞的量子码简单得多。它还仅仅涉及相邻量子比特间的相互作用——这一性质在Preskill看来尤为诱人。
在之后数年里,Kitaev、Preskill与几个同行充实了表面码的细节。2006年,两个研究者证实该编码的一种优化版本的错误阈值在1%左右,比早期量子码的阈值高了100倍。虽然这些错误率对于2000年代中期的原始量子比特来说仍然无法达到,但它们不再那么遥不可及了。
尽管有了这些进展,对表面码的兴趣仍然局限在一小群理论家中间——他们并不真的在实验室中把弄量子比特。他们的文章采用了一种抽象的数学体系,在真正实操的实验家看来有如天书。
“要理解这些进展确实相当困难,”加州大学圣芭芭拉分校一位物理学家John Martinis回忆道。他就是这样一名实验家,“对于我来说就好像在读一篇弦理论文章。”
2008年,一位名叫Austin Fowler的理论家开始着手改变这一局面,向全美的实验家们推销表面码的优点。四年后,他在Martinis的圣芭芭拉团队这里找到了忠实的听众。Fowler,Martinis与其他两位研究者共同撰写了一篇50页的长文,概述了表面码的实施过程。他们估计,只要工艺足够巧妙,最终可将物理量子比特的错误率降至0.1%,远在表面码的阈值之下。这样一来,原则上他们就可以通过扩大晶格的规模来将逻辑量子比特的错误率降至任意低的水平。这便是全规模量子计算机的蓝图。

John Martinis(左)与Austin Fowler设计了基于表面码的量子计算机蓝图。
当然,建造一台可不那么容易。粗略的估算表明,Shor的因数分解算法实际运行起来需要万亿级的操作。其中任何一个操作出错而未能纠正的话,都会破坏整个过程。出于这一限制,他们得将每个逻辑量子比特的错误率降至万亿分之一以下。为此他们需要一个相当庞大的物理量子比特晶格。圣芭芭拉团队的早期估计表明,每个逻辑量子比特可能需要数千个物理量子比特。
“这吓到了所有人,”Martinis说道,“连我也有点吓到了。”
不过Martinis和他的同事们义无反顾,在2014年发表了基于5个量子比特的一项原理验证性实验结果。这一结果引起了谷歌一位主管的注意。他很快将Martinis招募过来领导一个内部量子计算研究团队。在尝试同时对话数千个量子比特之前,他们先得让表面码在一个更小的尺度下运作。实现这一点将付出十年艰辛的实验工作。
跨越阈值
当你尝试去实现量子计算理论时,第一步或许是最为关键的:你要采用什么硬件?许多不同的物理系统都可以充当量子比特,而每种都有不同的优缺点。Martinis与同事们专注于所谓超导量子比特,也就是硅芯片上由超导金属构成的微小电路。单个芯片上可以容纳排成晶格的多个量子比特——正好是表面码所需的架构。
谷歌量子人工智能团队花了数年来改进他们的量子比特设计与生产流程,逐步将数个量子比特扩展到数十个,并且打磨了同时操控多个量子比特的能力。2021年,他们终于做好了准备工作,开始尝试首次使用表面码来进行纠错。他们知道已经可以构建出错误率在表面码阈值之下的单个物理量子比特。但他们得弄清楚,这些量子比特是否可以协同起来,给出性能优于其部件之和的逻辑量子比特。具体来说,他们想证实,当扩展编码时——通过采用更大号的物理量子比特晶格来编码逻辑量子比特——错误率会变得更低。
他们首先考虑最小的表面码,即所谓“距离-3”编码。它使用3*3晶格上的物理量子比特来编码一个逻辑量子比特(加上另外8个用于测量的量子比特,总共17个量子比特)。接着他们上升一步,考虑距离-5的表面码,它总共需要49个量子比特。(只有奇数码距才有意义。)
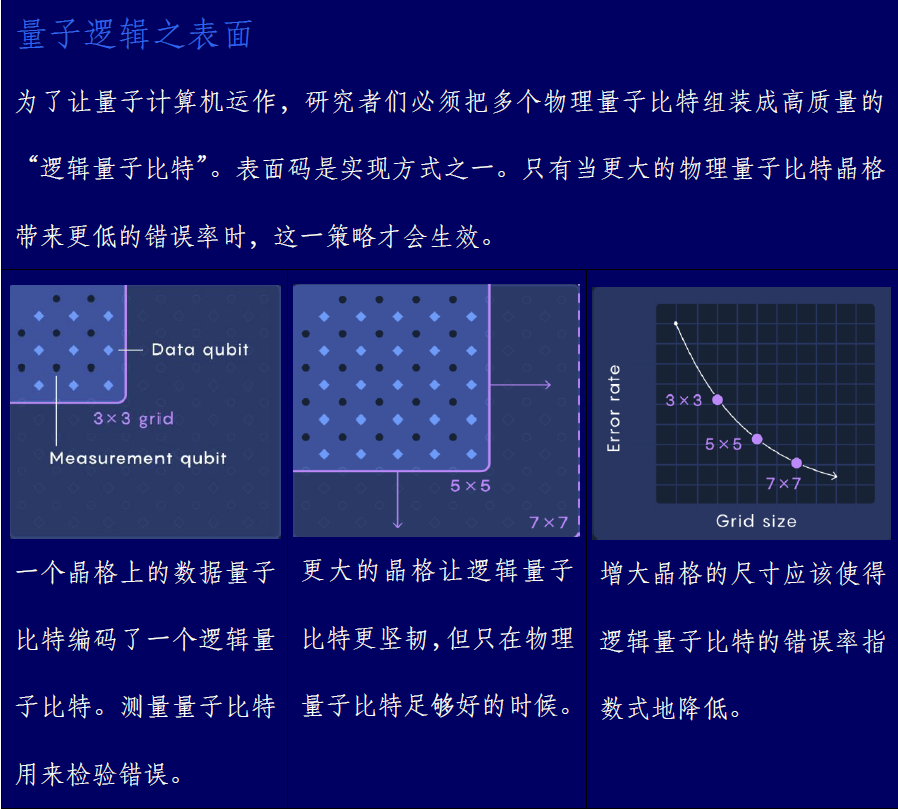
在2023年的一篇文章中,团队报告距离-5编码的错误率比距离-3的稍微低那么一点点。这是一个积极的结果,但还不足以下结论——他们还不能宣告胜利。并且在实施层面上,如果每一步仅仅把错误率降低一点点,扩大规模就不可行。要取得进展,他们还需要更好的量子比特。
团队把2023年余下的时间都用到了另一轮硬件的改进上。2024年年初,他们有了一块全新的72-量子比特芯片,代号垂柳,可以用于测试。他们花了几个星期安装测量和操控量子比特所需的所有设备。接着在二月,他们开始收集数据。数十个研究者挤到一个会议室观看获得的首批数据。
“没人能确定将会发生什么,”谷歌量子人工智能实验室与Newman共同领导这一项目的物理学家Kevin Satzinger说道,“让这些实验运作要考虑大量细节。”
接着一个图出现在了屏幕上。距离-5编码的错误率不只是稍微地低于距离-3编码。它下降了40%。在之后的数月里,团队将这一数字改进到了50%:每次在码距上的提升会让逻辑量子比特的错误率减半。

Gabrielle Roberts几乎熬了一整夜来让新芯片在截止日之前运作。
“那是个令人异常激动的时刻,”Satzinger称,“就好像整个实验室的空气中都通上了电流。”
团队还想知道如果他们继续扩大规模会发生什么。可是距离-7编码总共需要97个量子比特,比他们芯片上的总数还多。八月,新一批的105量子比特垂柳芯片出产,不过那时团队已经临近一个截止日期了——下一轮设计改进过程的测试周期就要开始了。Satzinger准备让步,觉得他们不会有时间来运行最后这些实验了。
“我在心里已经有点放弃距离-7了,”他说。接着,在截止日前一晚,两个新的团队成员,Gabrielle Roberts与Alec Eickbusch,熬夜到凌晨3点让所有设备运作起来了,并收集数据。当团队第二天早晨回来时,他们看到从距离-5到距离-7编码再一次让逻辑量子比特的错误率减半了。这种指数标度——在码距上提升一步导致错误率降低相同的因子——正好是理论所预言的。这是一个确切无疑的证据,表明他们将物理量子比特的错误率降到了表面码阈值以下相当远了。
漫漫长路
这一结果也让其他量子计算研究者们兴奋不已。
“我觉得很神奇,”代尔夫特理工大学的理论物理学家Barbara Terhal说道,“我真的没想到他们就这样飞跃了阈值。”
与此同时,研究者们也意识到他们还有漫长的一段路要走。谷歌量子人工智能团队仅仅证实了单个逻辑量子比特的纠错。在多个逻辑量子比特间添加相互作用会带来新的实验挑战。
接下来就是扩大规模的问题。要让错误率低到足以执行有用的量子计算,研究者还需要进一步改进物理量子比特。他们还需要采用远大于距离-7的编码来制造逻辑量子比特。最终,他们还需要组合数千个逻辑量子比特——也就是超过一百万个物理量子比特。
与此同时,其他研究者采用不同的量子比特技术也取得了惊人的进展,尽管他们还没能证实可以通过扩大规模降低错误率。这些另类技术或许更易于实现物理量子比特需求更少的全新纠错码【译注:例如,所谓“好”的量子LDPC码。】量子计算仍处在早期。现在判断哪种方法会胜出还为时过早。
2020年离开谷歌量子人工智能实验室的Martinis对这种种挑战保持乐观。“我经历了从几个晶体管到数十亿个的过程,”他说,“时间充足的话,只要我们足够聪明,就一定会成功。”
原文链接:
https://www.quantamagazine.org/quantum-computers-cross-critical-error-threshold-20241209/
https://blog.sciencenet.cn/blog-863936-1478760.html
上一篇:Hans Bethe与完美量子理论之邂逅
下一篇:Bethe拟设七十五年
