博文
RAG 过时了吗?  精选
精选
|

来信此 RAG 已非彼 RAG
知识星球上,星友 momo 提问。

他说自己最近在用 Codex 和 Claude Code 搭建基于 RAG 的本地知识图谱,做着做着回头翻了翻我之前写的 RAG 相关文章,发现已经是好几年前的东西了。他想问的是:RAG 是不是已经被更新的技术路线替代了?还是说仍然值得继续做,只是可以结合新工具在本地搭一个属于自己的系统?
这个问题问得好。我猜不少人心里也有类似的困惑 ——RAG 这个词,最近确实不怎么被单独拿出来讲了。但「不怎么提」和「已经没用了」,是两回事。
RAG 过时了吗先给你一个直截了当的回答:没过时,但此 RAG 已非彼 RAG。
你要是还记得 2023 年那阵子的 RAG 教程,基本都长一个样:把文档切成小块,用 embedding 模型转成向量,存进向量数据库,用户一提问就找出最相关的几块拼进 prompt 里喂给大模型。这套流程的好处是简单直接,坏处也很明显 —— 检索质量粗糙,上下文容易断裂,答案经常牛头不对马嘴。
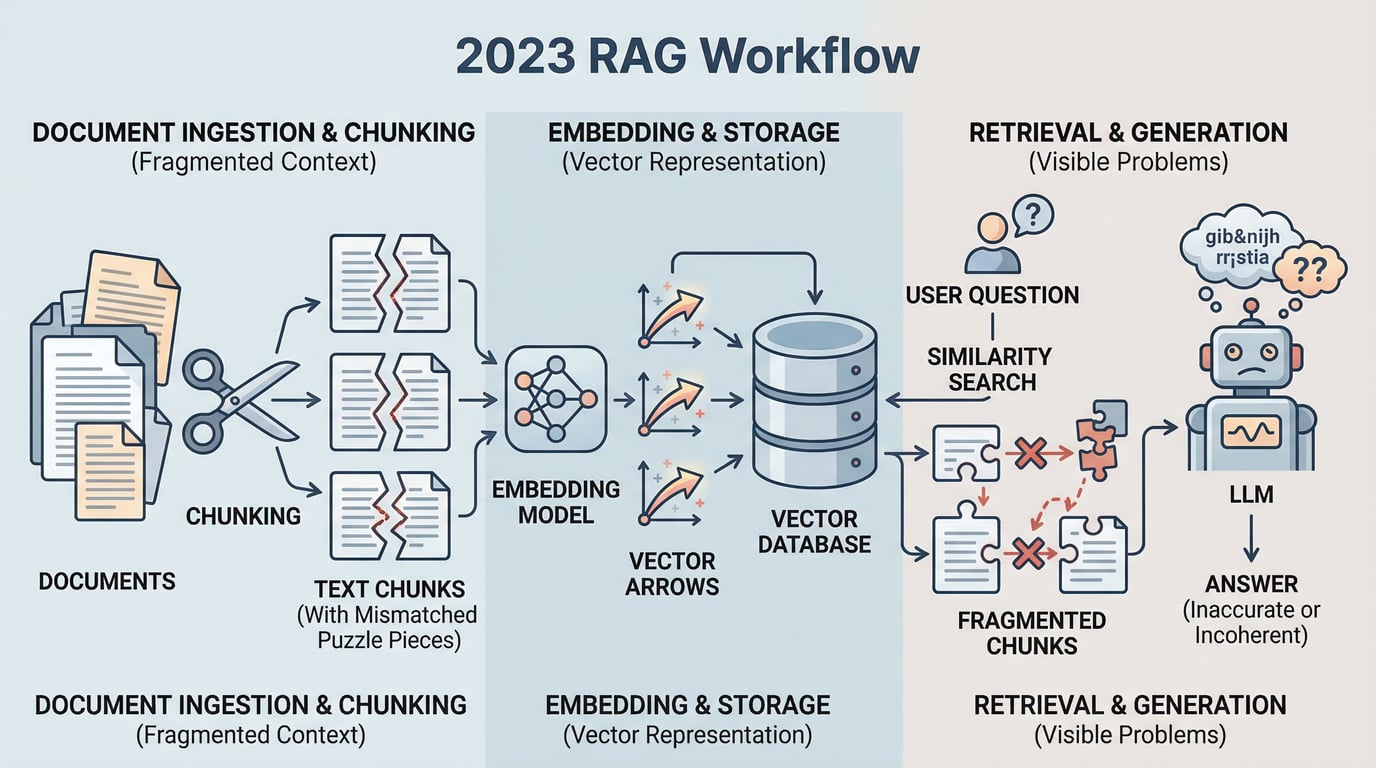
这种「入门版 RAG」确实已经过时了。
但 RAG 这个思路本身并没有退场。你之所以觉得它「不怎么被单独讲了」,背后有两个原因。
第一,长上下文模型确实吃掉了一部分原本属于 RAG 的场景。 现在的模型动不动就支持几十万 token 的上下文窗口。如果你的知识库不大——比如就是几百页讲义,或者一个中等规模的文档集——直接全部塞进 prompt 可能就是最省事的方案,根本用不着做什么检索。对于这类场景,确实没必要再折腾 RAG 了。
我们最近刚刚正式发表了一篇论文《大语言模型的长文档处理能力实证研究》,讨论的就是不同模型这方面的能力对比。你可以 点击这个链接下载。
不过我也想分享这类研究目前遇到的问题 —— 模型进展太快。论文写就的时候,实验用的模型还是主流旗舰。但是正式刊出的时候,基本上已经都被各大厂商更新了一轮。
第二个原因更关键:RAG 没有消失,而是融入了更大的体系。 现在行业里更常说的是 "context engineering"——上下文工程。RAG 只是其中一个环节,它和重排序、查询改写、记忆系统、工具调用放在一起协同工作。你不会单独讨论一辆车的轮子好不好用,但每辆车都有轮子。RAG 就是这个角色——不再被单独拎出来讲,但哪个认真做知识问答的系统都少不了它。
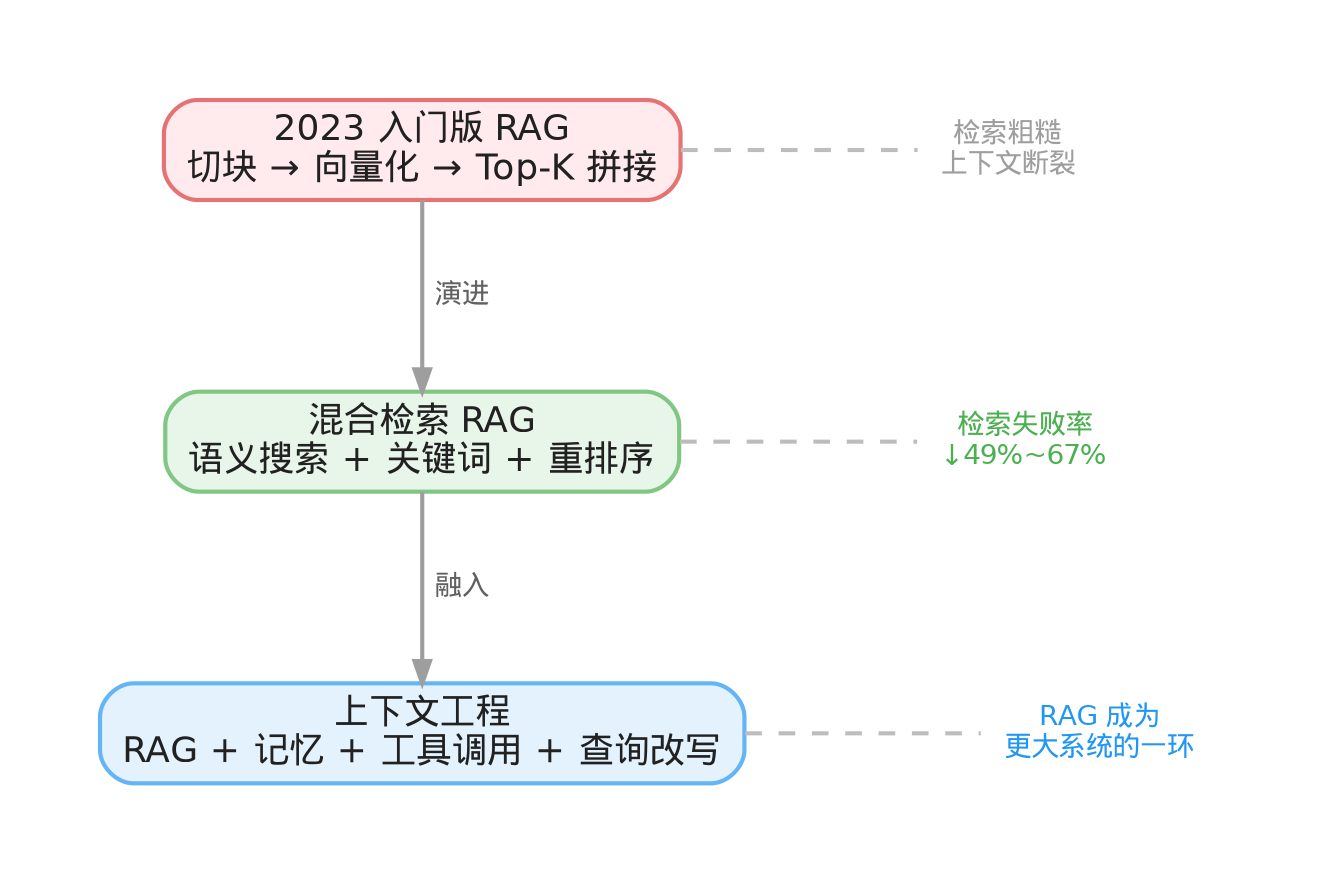
从产品层面看就更明显了。OpenAI 的 API 里到现在还内置着 file search 功能,做的就是语义搜索加关键词的混合检索。Anthropic 在 2024 年推出了 Contextual Retrieval,专门在 RAG 的基础上加了上下文信息和重排序,官方报告混合检索把检索失败率降低了将近一半,叠上重排序之后降了三分之二。这些大厂不是在告别 RAG,它们是在把 RAG 从一个向量库 demo,做成一套工业级的检索工程。
所以我的判断是:RAG 还值得做,但今天值得做的,已经不是 2023 年那种「切块加向量加 top-k」的入门版,而是混合检索、智能重排、能自己判断什么时候该去查资料的进化版。
知识图谱值不值得做你提到了我之前写的那篇 《GraphRAG GPT-4o mini 低成本构建 AI 图谱知识库》。这里给没有看过该文的读者简单回顾一下:GraphRAG 是微软推出的一个项目,思路是在普通 RAG 之上再加一层知识图谱,用图结构来表达文档之间的实体和关系。
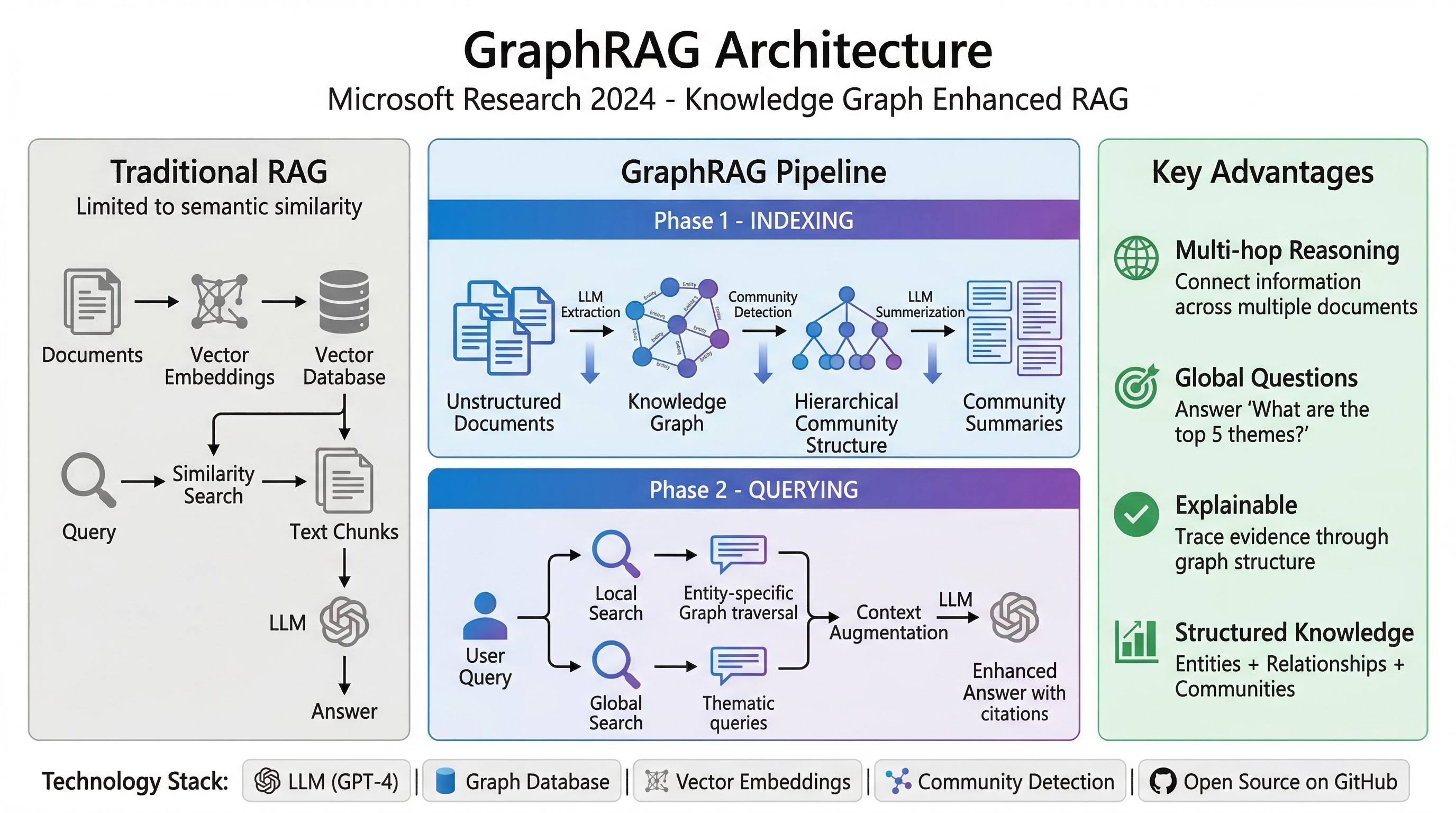
这个项目到现在还在活跃更新,GitHub 上持续有新版本在发。
知识图谱增强 RAG 值不值得做?值得。但我的建议是:别把它当起点。
GraphRAG 解决的是一类特定的问题。当你问的不是那种靠关键词就能命中的问题 —— 比如「过去两周我的笔记里有哪些主题在反复出现」「某个概念在不同论文之间是怎么演变的」「帮我梳理一条跨文档的关系链」—— 这类全局性的、抽象的、需要在多个文档之间做关联推理的问题,普通的向量检索确实够呛,图结构在这里能发挥独特的作用。
但同样重要的是,GraphRAG 不是「必然比普通 RAG 更强」的升级版。 有评测专门做过对比,结论是两者各有优势。在很多日常的问答任务上,GraphRAG 反而不如标准 RAG 准确,而且延迟更高。你可以把图谱理解成一个「第二层索引」——它帮你做关系推理,但它不是地基。
我的实战建议是这样的:先把基础的混合检索做好。 语义搜索加关键词检索,再加一个重排序模型——这套组合在绝大多数场景里就够用了。「这篇论文里某个定义在哪」「这份讲义里某个概念怎么解释」「帮我找出处并给引文」——这些需求,混合检索就能覆盖。
等你用着用着发现需求变了 —— 开始关心文档之间的关系,想要跨材料的时间线和概念网络 —— 这时候再把图谱加上来,也不迟。
保密性怎么保证你说想在本地搭建系统,同时保持比较好的保密性。这个想法完全可行,但有一个区分你一定要想清楚。
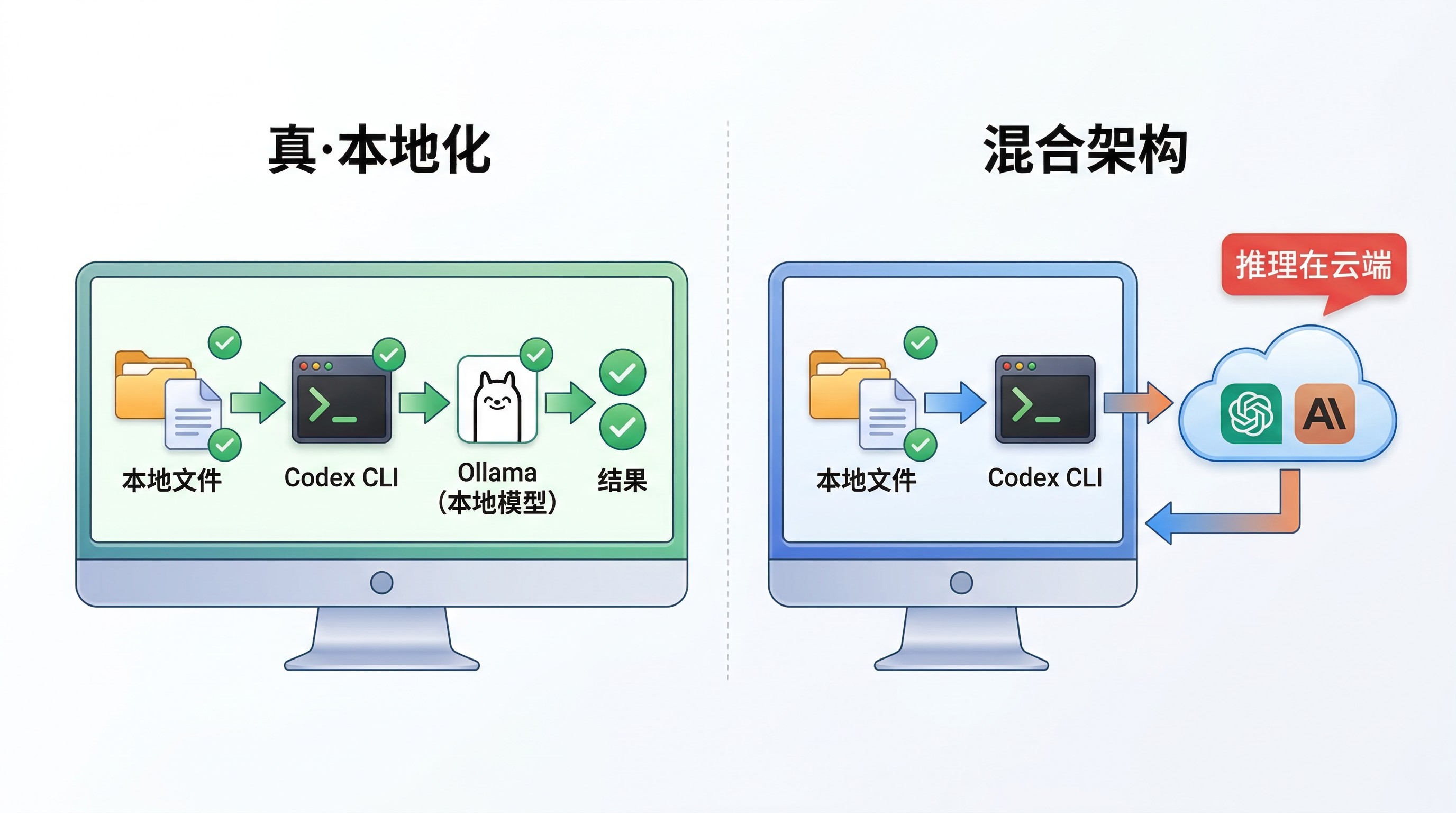
「本地执行」和「本地推理」不是一回事。
Codex CLI 可以在你本地的目录里读文件、改代码、跑脚本 —— 这些操作确实在你自己的机器上完成。它甚至支持接入 Ollama 之类的本地模型 provider。所以拿 Codex 来做你这套知识系统的工程助手和编排工具,是完全没问题的。
但如果你底层推理用的还是云端模型(比如 GPT 或 Claude),那你实际得到的是「本地索引加本地工具,但推理在远端」。你的检索结果、你拼好的 prompt,还是要发到云端去。这不等于全链路本地化。
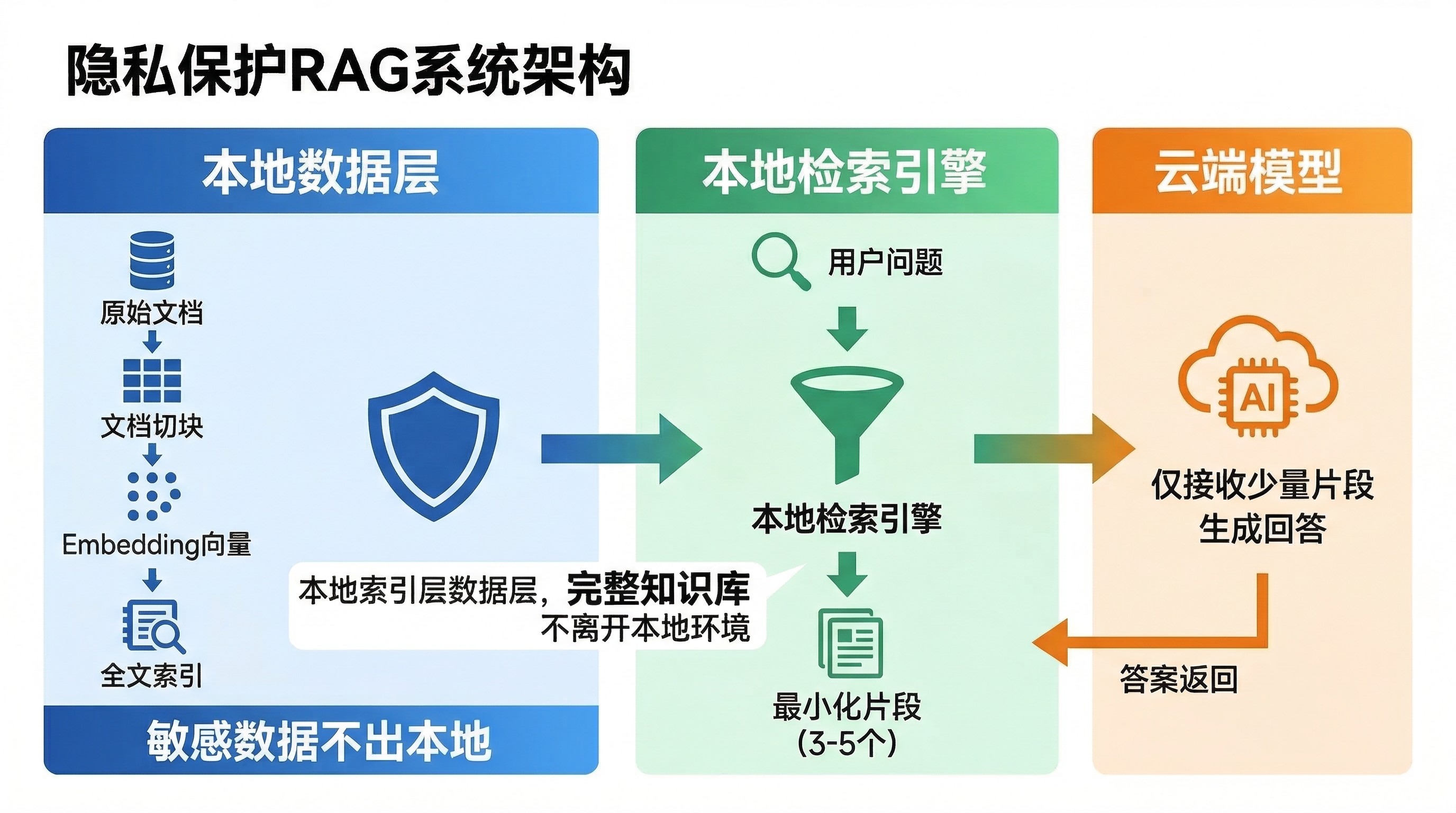
那怎么画这条保密边界?关键是把敏感数据挡在检索层。 你的原始文档、切块、embedding、全文索引——这些全部留在本地。云端模型只看到经过检索筛选后的最小化结果。这样即使模型在云端,它接触到的也只是和当前问题相关的几个片段,不是你的完整知识库。
如果你想做到更彻底 —— 从索引到推理全部私有化 —— 那就把模型 provider 也换成本地的。现在 Codex 和 Claude Code 都支持接入本地模型。代价是本地模型的能力通常不如云端的大模型,但对知识库问答这种任务来说,小模型往往够用。
小结三个问题聊完了。RAG 没有过时,过时的只是 2023 年那种最简版的做法 —— 今天的 RAG 已经和长上下文、重排序、智能检索融合在一起,成了更大系统的一部分。知识图谱也值得做,但别着急 —— 先把混合检索搞扎实,等需求升级了再加图谱。至于保密性,Codex 或 Claude Code 在本地搭系统不是不行,关键是把保密边界画在数据和检索这一层。另外,不要忽视本地部署模型能力上的差别。
你已经在动手了,这比大多数只停留在讨论阶段的人强。继续加油吧。
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1525640.html
上一篇:如何用 YouMind 绘制出你家乡地标景观微缩地图?
下一篇:Get 笔记为什么又回到了我的知识工作流?
