博文
AI 端到端做研究、写论文,你能署名发表吗?  精选
精选
|
 疑问
疑问
星友「记往开来 | 邓岳」发来了一个很长的问题。我是个懒人,干脆把知识星球自动生成的提问图片放在这里,你先看看。

我简单转述一下,邓岳遇到的具体瓶颈是,他用 AI 工具验证了选题的学术潜力,完成了论文初稿,还做了多轮交叉评估 —— 结果都不错。然后他卡住了,卡在了发表环节。
没有高校学术身份,不熟悉期刊规则,邓岳不知道怎么把一份「AI 说很好」的初稿变成一篇真正的发表论文。
他主要问了这三个问题:
• 没有高校学术身份的普通人,除了难度极高的独立发表,有没有合规可落地的发表路径?
• 普通人能不能对接高校科研团队,以「核心选题 + 产业视角 + 初稿基础」的方式合作发表?这种模式合规吗?
• AI 驱动的「产业端出题+学术端深研发表」协作模式,未来会不会成为趋势?在逐一回答邓岳的问题之前,咱们有必要先看看这些问题背后更大的图景。
学术研究是一件有门槛的事。
大型仪器、长期的理论浸润、机构资源 —— 在很多领域,缺了任何一样,你连基本数据都拿不到,更别提提出有方向感的假设。这些门槛不是摆设,它们在维护研究质量。而且在大多数领域,这些门槛今天仍然牢固 —— 你不会因为有了 AI 就能绕过粒子对撞机或者冷冻电镜。
但在另一些领域 —— 数据公开、假设可以被计算验证的领域 —— 格局确实在变。
想想 AlphaFold。它把蛋白质结构预测从需要巨额经费和大型设备的缓慢探索,加速到了计算机可以在分钟级完成的程度。当然,AlphaFold 能做到这一点,离不开几十年实验积累出来的蛋白质结构数据库 —— 它不是凭空替代了科学共同体,而是站在了整个实验传统的肩膀上。但它展示了一种新的范式:门槛并没有消失,而是从实验资源转向了计算能力和开放数据 —— 而后者正在快速普及化。当计算能力足够充沛、探索可以自动迭代,原来那些需要逐一探测的笨拙路径就有可能被绕过。
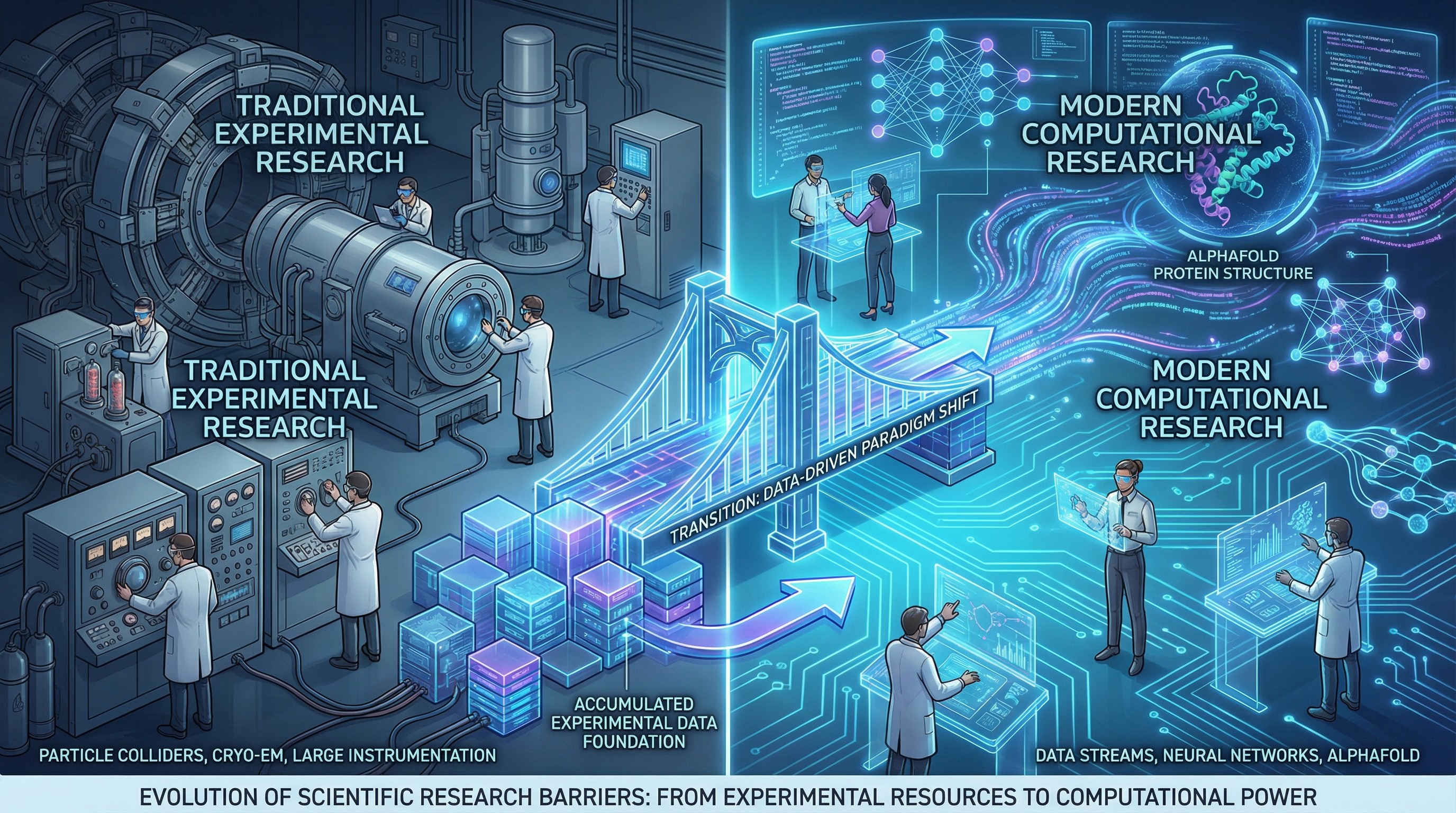
这种范式正在向更多领域扩散,尤其是那些已经有了开放数据基础设施的领域。我们搞了这么多年的开放数据、开放获取,现在有了 AI agent 能自动在这些数据上做假设 - 检验循环 —— 也许这正是它们发挥价值的时候。
如果你对 AI 端到端的研究能力有疑虑,建议你看看 Andrej Karpathy 做的 AutoResearch 项目,短时间内已经获得了超过 6 万颗星。
它能干啥?
你给 AI agent 一份研究指令,它就会在设备上反复修改语言模型的训练代码、跑 5 分钟实验、看效果好不好、决定保留还是回滚 —— 然后循环往复。一晚上能自动跑上百轮实验,相当于让 AI 替你做「调超参、改架构、看指标」这种重复性的 ML 研究苦力活。人类只需要写好「研究方向」的指令文件,剩下的探索过程全部自动化。核心理念是把研究者从「亲手改代码跑实验」变成「编程指挥 AI agent 去跑实验」。
它是邓岳提到的 AutoResearchClaw 的灵感来源。

AutoResearchClaw 比 Karpathy 的 autoresearch 野心大得多 —— 它不只是跑实验,而是把「从一个想法到一篇可投稿论文」的完整科研流程全自动化了。
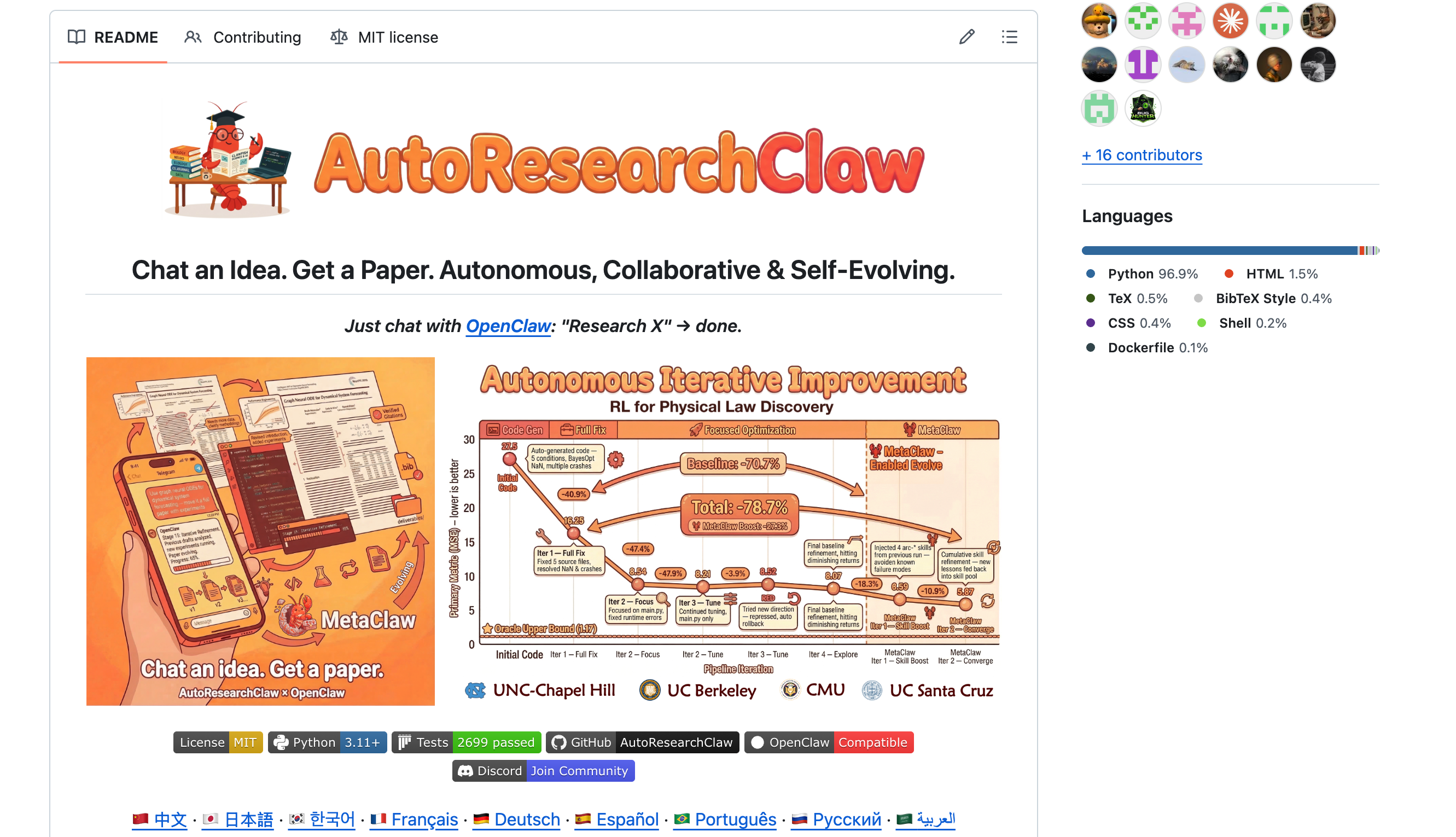
你输入一个研究主题,它通过 23 个阶段、8 个大步骤,自动完成:文献检索(对接 OpenAlex/Semantic Scholar/arXiv 真实论文库)→ 多 Agent 辩论生成假设 → 自动写实验代码并在沙箱里跑(能自动检测 GPU 类型、自动修 bug)→ 分析结果(不行就自动换方向重来)→ 按 NeurIPS/ICML 模板写论文 → 输出可编译的 LaTeX。
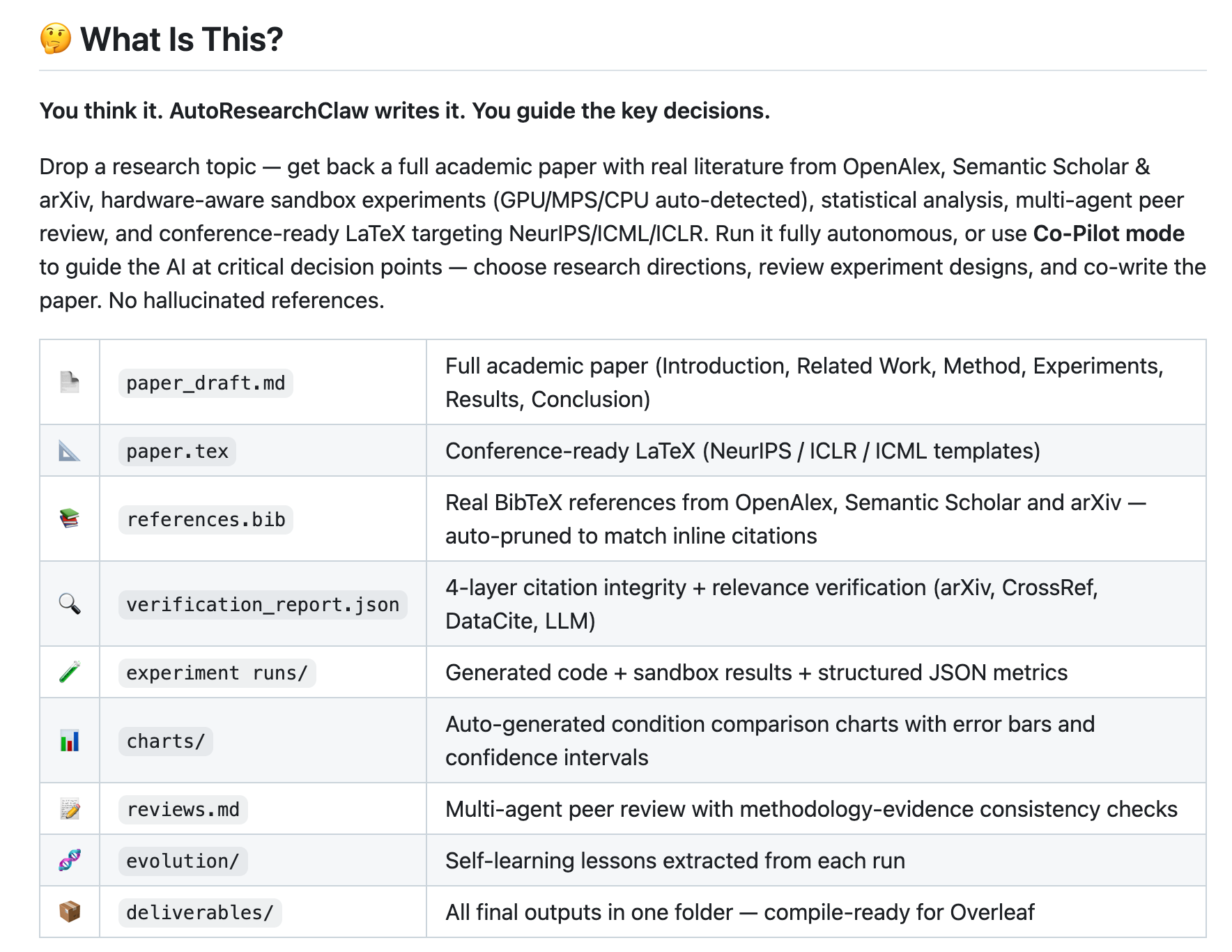
核心卖点是反造假:引用经过四层验证确保真实存在,实验数据有注册表追踪防止编造。支持全自动跑完,也可以在关键节点让人介入把关。
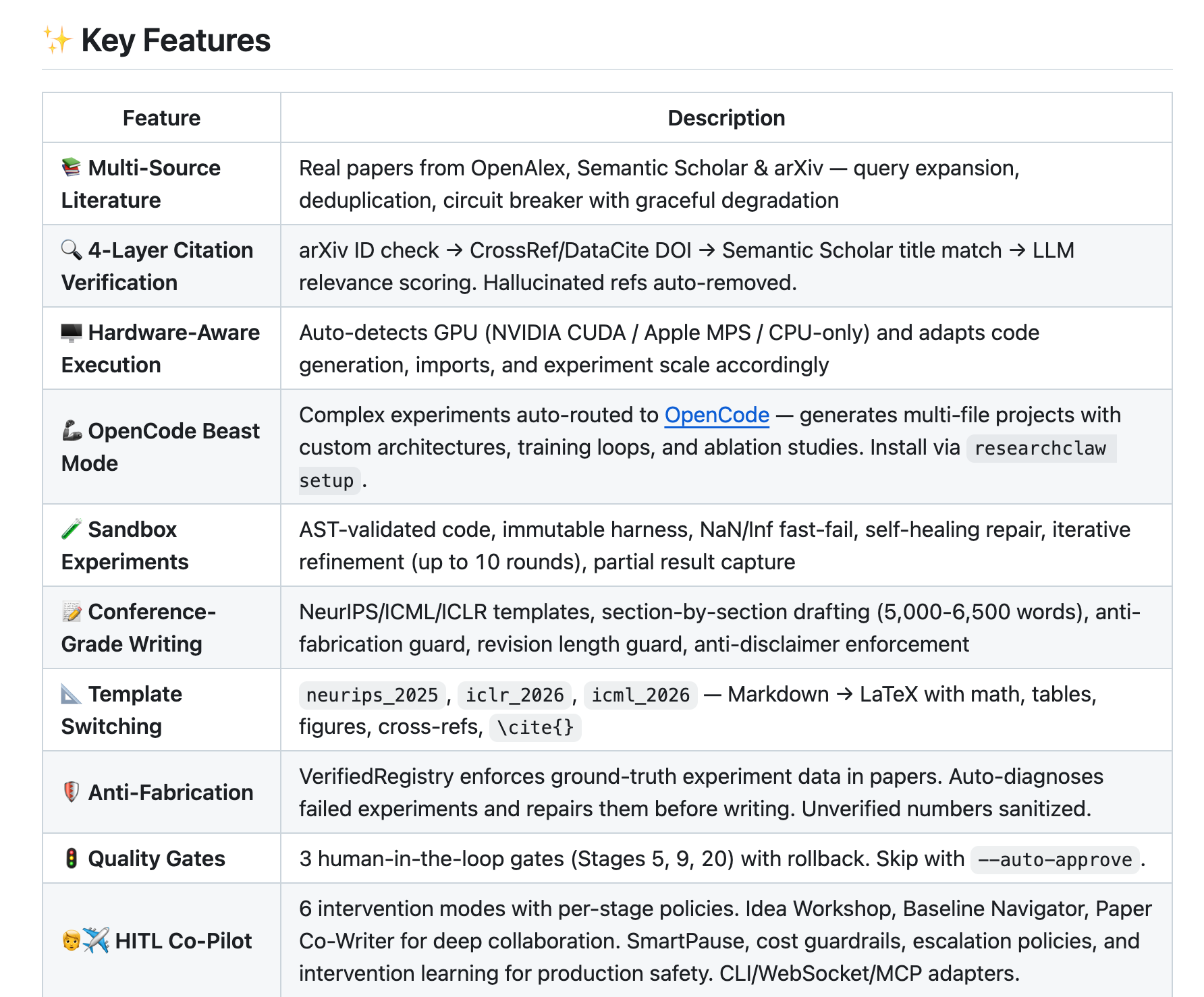
简单说:Karpathy 那个项目是「AI 自动调参」,这个 AutoResearchClaw 则是「AI 自动当研究生写论文」。
于是你可能会想到一个类比:既然我们已经有了「一人公司」,那在数据密集、计算驱动的研究领域,有没有可能出现某种「一人研究团队」?
正是在这样的背景下,我们才会见到邓岳提出的这种新问题。
不过需要说清楚:上面展示的这些能力,目前主要集中在计算密集型的机器学习领域 —— 工具能自动化的是流程(检索、编码、排版),但研究的创新性和严谨性能否达到发表标准,还远未被证明。端到端的 AI 科研能力才刚刚起步而已。我们今天讨论的这些内容,其实还不适用于大多数人、也不适用于大多数科研场景。学术研究毕竟是专业的事,仓促的热情替代不了严谨的训练。但正因如此,邓岳提出的这些具体的问题才更值得逐一厘清。因为如果我们对正在发生的技术条件剧变当作房间里的大象视而不见,不加以思考、分析和合理引导,那技术被误用或滥用的结果,恐怕是学术界根本无法承受的。
下面咱们就来逐一分析和尝试回答这些问题。
独立问题一:没有高校学术身份的普通人,除了难度极高的独立发表,有没有合规可落地的发表路径?
有。而且路径不止一条。但注意,每一条都有门槛,这个门槛不是「身份」,而是「责任」。
咱们先说最直接的路:以独立研究者身份投稿。很多人以为没有大学 affiliation (单位)就不能投稿——这是误解。主流出版商并没有硬性要求作者必须有高校编制。你完全可以使用 "Independent Researcher" 作为署名单位,如实填写研究进行时的真实机构归属。身份不是硬门槛。真正的门槛是后面那些东西:你的论文能不能通过同行评审?你的数据能不能经得起审查?你的方法能不能复现?
第二条路:先发预印本(preprint),建立优先权,吸引合作者。这条路特别适合你现在这种「选题已成型、初稿已完成、但缺实证落地团队」的状态。 Nature Portfolio 明确说预印本不构成 prior publication,大多数主流期刊不将其视为 prior publication,不影响后续正式投稿(但投稿前应确认目标期刊的具体政策)。你可以把初稿挂到 arXiv 或 OSF 上。不过要注意,arXiv 首次提交需要获得已有作者的背书(endorsement),而且 2026 年 1 月起政策进一步收紧,仅凭机构邮箱已经不够了。预印本不是正式发表,但它做三件事:为你的选题打上时间戳,让潜在合作者看到你的工作,以及——如果你的选题确实好——把「你找人」变成「人找你」。
第三条路:换一种文章类型。如果你的核心资产不是理论推演,而是独特的行业数据、真实的应用场景、或者一手的部署经验,那么 data article、perspective、application paper 可能比硬冲完整原创实证论文更务实。Elsevier 旗下的 Data in Brief 就专门接收这类文章,要求数据公开入库、可链接、可复用。找对文章类型,比死磕一种格式效率高得多。
第四条路:走 Registered Report 格式。这个格式是先审研究问题和方法设计,通过后再去收数据做实验。COS 推动的这一框架已被数百家期刊采纳,包括 Scientific Reports 等。它天然适合「选题强、场景真、但实证设计还没定型」的项目——先让方法过审,再找团队合作执行。
路说完了,现在说说路上的红灯 —— 这部分同样重要。买作者位、借高校 affiliation 挂名、让 AI 署名、把 AI 生成的内容不做披露就提交 —— 这些都是红线。 ICMJE 明确规定 AI 不能作为作者,因为它无法对论文的准确性、原创性和完整性承担责任。 Nature 不接受 LLM 署名,还禁止在正式发表中使用 AI 生成的图像。 Elsevier 更进一步:AI 产出不能直接作为手稿文本,只能作为灵感来源,且所有 AI 辅助环节必须在专门声明栏中披露。
这些政策还在加速收紧。2026 年 1 月,ICMJE 发布修订版建议,新增专门的 Section V 处理 AI 问题,覆盖编辑、作者和审稿人全链条。同期,多个国际学术组织联合启动了 "Vancouver Standard" 全球 AI 披露报告标准 的制定工作,首轮需求调研已于 2026 年 2 月结束,后续将进入第二轮内容与分类标准咨询。AI 使用的披露正在走向全球标准化。
谈完了国际学术界的情况,咱们再来关注一下国内的政策环境。
2026 年 3 月,多所国内高校集中发布了针对 AI 使用的学术规范。据 科技日报 3 月 24 日报道,这些规范针对的是 AI 对核心学术环节的替代 —— 禁止 AI 生成核心论点、研究方法和结论,禁止 AI 替代学生的学术思考和逻辑推理,直接搬用 AI 生成的段落 —— 哪怕做了小幅修改 —— 也视为学术不端。但使用 AI 追踪研究动态、整理文献仍被允许,前提是人工核实并如实声明。
国家自然科学基金委的 2026 年项目申请须知也指向同一方向:如果使用生成式 AI 追踪研究动态或整理文献,必须人工核实所有信息的真实性和准确性,并且必须完整如实地声明 AI 使用情况。
这意味着什么?「AI 写的初稿」不能直接拿来用 —— 这一点的根本约束来自前面已经讨论过的国际期刊政策(Nature、Elsevier 等),不管你是独立投稿还是与高校团队合作都必须遵守。而如果你的合作团队包含在校师生,国内高校的规范还会叠加额外约束。两层约束指向同一个结论:AI 初稿必须被彻底重构为人类主导的研究成果,AI 的角色必须被准确披露。这不是锦上添花,这是底线。如果你对「AI 辅助文献综述怎样才算不翻车」这个问题感兴趣,可以看看我之前写的 这篇文章。
合作问题二:普通人能不能对接高校科研团队,以「核心选题 + 产业视角 + 初稿基础」的方式合作发表?这种模式合规吗?
能。而且我认为这是你当前最值得走的主线。
但 —— 作者资格不是靠「我有好题目」「我先写了初稿」自动获得的。
前面提到 ICMJE 的 AI 署名红线,这里要看的是它的另一条规定 —— 作者资格标准。它要求同时满足四个条件:对研究的构思 / 设计或数据的获取 / 分析 / 解释有实质性贡献;参与论文的起草或关键性修订;批准最终发表版本;愿意对论文的所有方面负责。四条全部满足才算作者。缺一条,你就应该进致谢(Acknowledgements)而不是作者栏。
所以,如果你只是把选题和 AI 初稿交出去、之后不再参与研究设计、不参与结果解释、不参与关键修改、也不愿意对全文的准确性负责 —— 那你的贡献更适合放在致谢里,而非作者栏。
反过来,如果你继续参与研究问题的界定、变量定义、场景约束、结果解释、稿件修改,并且愿意对全文负责 —— 署名作者就是完全正当的。这在当前的学术规范里是合规且被认可的;不被认可的是「题目外包+论文代工+学者挂名」。
这类合作要落地,最稳的做法是一开始就把贡献和边界写清楚。
首先,用 CRediT(NISO 的贡献者角色分类法)在项目启动时就写好贡献表 —— 谁负责 Conceptualization,谁负责 Methodology,谁负责 Formal Analysis,谁负责 Writing。这套框架的设计初衷就是让真实贡献透明化,学术界的最佳实践建议在研究初期就分配并确认角色。
然后,把数据权属、匿名化方式、保密边界、发表权、审阅周期写进正式协议。Nature Portfolio 把数据、材料、代码和协议的可获得性作为发表条件,任何限制都要在投稿时告知编辑。如果你的产业数据有保密要求,这些必须在合作之初就谈清楚。
伦理审批、知情同意、隐私保护和利益冲突声明也必须前置。通信作者通常还要负责 AI 使用披露和伦理审批的详细说明。
还有一件特别重要的事:把 AI 使用日志留下来。你的情况是「AI 已经生成了完整初稿」,这显然超过了简单的语法检查或拼写纠正,属于必须披露的范畴。做好详细的 AI 使用记录(用了什么工具、在哪些环节使用、人工做了哪些核实和修改),是对合作团队和期刊编辑的负责任交代。
不过,「提供核心选题+产业视角+初稿基础」虽是很强的合作起点,却不是一张自动兑换作者身份的门票。 能不能进作者栏,取决于你是否继续作为研究共同体的一员——把问题做实、把证据做硬、把文本做准,并且要满足最重要的一条,即承担发表后的责任。
关于对接高校团队的实际操作,别说「我有一篇 AI 写好的论文,找人帮我发」。把你的材料重组为一个**「合作对接包」**—— 一页问题说明(为什么这个问题真、急、重要)、一页场景与可提供资源说明、一页研究雏形(可做成什么 empirical design / registered report / data paper)、一页 CRediT 贡献提案、以及一份 AI 使用说明和经人工核验的参考文献清单。
是不是很像写项目申请书?对,逻辑是一样的 —— 让对方一眼看到合作价值。
关于 AI 辅助科研工作流怎样搭建才不翻车,以及 AI 检测与学术原创性的边界在哪里,我以前都写过,有兴趣你也不妨看看。
趋势问题三:AI 驱动的「产业端出题+学术端深研发表」协作模式,未来会不会成为趋势?
我认为会。但被接受的版本不是「AI 替代学术训练」,而是「AI 降低前期摩擦,真实协作抬高证据标准」。
学术界的制度已经有向这个方向收敛的迹象,只是还不够明显而已。例如 Nature、Elsevier 等主流学术出版和会议体系都不再把 AI 视为绝对禁区,而是明确允许一定范围内的 AI 辅助,同时要求人类作者承担全部责任并做披露。 Springer Nature 2026 年 3 月的公告 说,2025 年有超过 150 万篇论文在其近 60 个 AI 工具的支持下进入出版流程,但始终强调人类监督(human oversight)和问责(accountability)。AI 辅助研究与写作正在被制度化,而不是被简单排斥。
但你也必须看到趋势的另一面同样明显:人们越能用 AI,验证门槛越高。所谓「水涨船高」,道理相似。
Springer Nature 的同一份公告里提到,他们的 AI 工具在 2025 年识别出数以万计的存在图像操纵、伪造参考文献等问题的稿件。与此同时,AI 编造的虚假引文正在大量涌入投稿系统 —— 期刊编辑现在已经把参考文献列表作为审查的第一道关卡。不只是投稿端在收紧,连审稿端都在严查 AI 使用。 ICML 2026 在论文中嵌入水印短语来检测审稿人是否直接搬运 AI 生成的评审意见,结果抓到 500 多名违规审稿人。另一方面,ICLR 2026 的独立审查也发现,超过五分之一的同行评审完全由 AI 生成。
这组数据指向一个清晰的趋势:整个学术生态都在加强 AI 使用监管。对你来说,这意味着未来拼的不是「谁更会让 AI 出稿」,而是谁能拿出更强的证据链和合规链。 AI 让「写出一篇看起来像论文的东西」变得极其容易,但这恰恰倒逼了期刊把审查标准拉得更高。对你来说,这其实是好消息——因为你的优势在于你有学术界轻易拿不到的一线问题、真实约束和独特数据。
我之前在 《AI 算不算一种研究方法?》 里讨论过一个核心区分:AI 做「分析工具」(Instrument)是完全合规的研究方式,但 AI 做「被试」(Subject)—— 也就是让 AI 凭空生成数据 —— 是高风险操作。这个区分在产学合作中同样适用。你的价值是提供真实场景和真实数据的「入口」,让学术团队用严谨方法来分析和论证。AI 负责降低沟通成本和初稿起步的摩擦,但真正稀缺的 —— 可验证的问题、可获取的数据、可站得住的研究设计、以及能对全文负责的人 —— 仍然需要人来承担。
所以我对这种模式的判断是:会被接受,也会越来越重要。 但方向不是「普通人用 AI 独立发表」,更不是前面提到的「一人研究团队」——至少短期内不是。更可行的方向是:产业方带着问题和数据、AI 负责降本提速、学术团队负责研究设计和因果论证。三方各有分工,谁也替代不了谁。
小结回到你的具体情况。你已经走过了最有价值的第一步 —— 发现了一个产业端的真实问题,并且做了初步验证。但接下来的路不是继续打磨那篇 AI 初稿,而是把它转化为一个「合作邀约」。
你手里真正值钱的东西不是初稿本身,而是选题背后的产业洞察、你能触达的一线数据、以及你对这个问题为什么「真、急、重要」的一手理解。这些是学术团队坐在办公室里拿不到的。
把这些打包好,用对接合作的方式而非论文代工的方式去联系高校团队。怎么找?学术会议的 poster session、ResearchGate 上搜索目标领域的活跃学者、或者先把预印本挂出来让潜在合作者主动找上门 —— 都是可行的渠道。然后在合作中持续参与、承担责任、学习学术规范。
这条路走起来比你想象的要扎实得多,也需要更多耐心。不过,那些带着真实问题和一线洞察认真走进来的人,恰恰是学术研究最需要的新鲜血液,这一点你不必有任何疑虑。
祝 AI 辅助的(合规)学术合作顺利,成果丰硕。
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1528804.html
上一篇:Get 笔记为什么又回到了我的知识工作流?
下一篇:还纠结他人作品「纯人工」还是掺了 AI ?你可能需要适应混合智能
