博文
AI 比你懂太多时,还能「人机协同」吗?  精选
精选
|
 疑问
疑问
周四下午,我听了武汉大学梁少博老师讲座。题目是《多通道交互情境中的用户复杂行为》。

我的感觉是新颖、详细、幽默、实在。讲座后我也提出了问题,获得了满意的答复。但是,我其实还有另一个问题,因为时间关系没有来得及提出。可这问题,在我脑海中挥之不去。

少博老师讲座中,有一段说到医疗场景。他提到医生和 AI 的协同诊疗。比如影像诊断,可以先让 AI 看片子,医生再判断;也可以医生先看,再参考 AI 的分析结果。AI 背后可能接入大量医学论文、诊疗指南和病例经验,在某些场景下,它给出的提示与判断确实可能比单个医生凭个人经验想出来的更系统。这时他提到,对于偏远地区、缺乏资源的医生来说,AI 赋能的效果更为显著。
这个描述,让我突然激灵一下子。我们常说 AI 可以给人赋能,所谓「人机协同」。但如果 AI 的知识更新速度和广度远远超过人,那人和 AI 还能达成协同效果吗?
假设 AI 已经读过大量最新论文、指南和案例,而做决定的医生,可能因为处在不发达地区,条件所限知识可能有一段时间没有更新。这时医生仍然要做关键判断。他看 AI 的建议,看得懂吗?如果看不懂,完全照着做,那不就变成 AI 在前面指挥,人只是在后面签字吗?
可是反过来,如果他因为看不懂就拒绝 AI,坚持用自己已经过时的经验,那 AI 赋能又从何谈起呢?
这或许才是人机协同里真正棘手的地方。
悖论「低经验者从 AI 中受益更多」,当然并不是一句空泛判断。
Erik Brynjolfsson、Danielle Li 和 Lindsey Raymond 研究过一个大规模客服场景,研究覆盖 5,179 名客服人员。根据 NBER 工作论文的摘要,获得生成式 AI 助手访问的员工,整体生产率平均提高 14%。更有意思的是,新手和低技能员工的提升更明显,问题解决量提高了 34%。新员工借助 AI,也能更快接近更有经验员工的表现。
这个结果很符合直觉。客服工作里有大量隐性经验:什么样的说法更容易安抚客户,什么问题应该先问,遇到某类故障,资深员工通常会怎么处理。这些经验本来藏在老员工的脑子里、对话记录里、组织惯例里。AI 把它们压缩成即时建议,递到新手手边,新手当然受益很大。
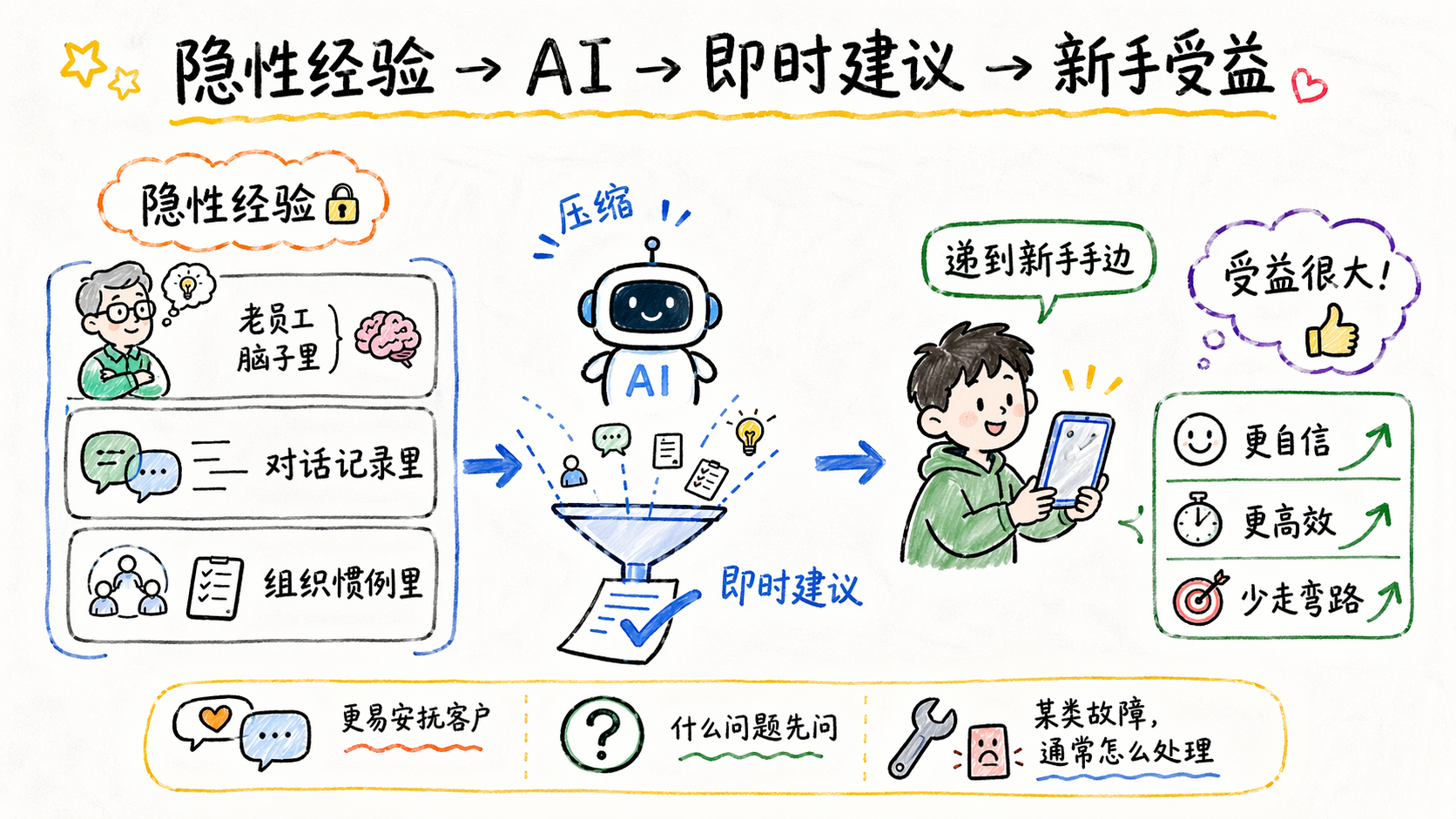
我得插一句,这也是为什么现在不少大厂员工,有被「蒸馏成 Skill」,从而遭到替换的焦虑。
不过这里你一定要看到场景限定。客服这类任务,边界相对清楚,反馈相对快,错误后果也比较可控。客户满意不满意,问题有没有解决,主管能不能复盘,通常很快就能看到。
可惜,关键决策不是这样。医疗方案、重大投资、公共政策、科研方向、组织改革、学生评价、人员任用……这些事情的反馈往往很慢,代价可能很高,因果链又很长。你今天做了一个决定,半年后才看见结果;等发现不对,恐怕已经很难回头。
所以,更准确的说法不是「AI 让低水平者变强了」,而是:AI 可能迅速拉高一个人的输出能力,但不一定同步拉高他的判断能力。

这两件事,差别很大。输出能力,是你能不能给出一个看起来像样的方案、报告、诊断建议、研究综述、战略分析。而判断能力,则是你能不能知道这个方案的前提是什么,哪里可能错,遇到什么证据应该改主意,出了问题该怎么止损。
AI 常常能先把输出能力抬高。它能让一个没怎么读过前沿文献的人,拿出一份像模像样的前沿综述;让一个经验不多的人,拿到一套看起来很专业的行动方案;让一个原本说不清楚的人,突然拥有了流畅、有条理,甚至正确应用术语的表达。
但如果判断能力没有跟上,它也会给人们制造一种危险的错觉:我已经会了。
仔细想想,你自己真的会了吗?
边界危险的地方,不是 AI 有时会错。任何人都会错,同样任何工具都会错。只要错误明显,人还有机会警觉。
更危险的是:人不知道 AI 什么时候会越界。
这就是所谓「锯齿状技术前沿」。AI 的能力边界不是一条光滑的线,不是说「简单任务它都会,复杂任务它都不会」。现实更麻烦。有些看起来复杂的任务,它做得很好;有些人类以为机器应该轻松处理的事情,它却会翻车。
Dell'Acqua 等人与 Boston Consulting Group 合作的研究,就把这件事做成了实验。他们让 758 名知识工作者完成真实感很强的咨询任务。在 18 个落在 AI 能力内的任务上,使用 AI 的人完成任务更多,速度更快,质量也更高。可是到了一个被设计为 AI 能力边界外的复杂管理任务上,使用 AI 的参与者反而比不用 AI 的人更不容易给出正确答案,正确率低了 19%。

问题在于,使用者并不总能提前知道自己站在哪一侧。如果你知道这件事 AI 不擅长,你自然会多留个心眼。可当 AI 的回答很流畅、结构很完整、术语很专业、语气很笃定,你就更容易以为它在 AI 「射程」范围内。
尤其当你本来就不熟悉这个领域时,AI 的强大表达能力,反而会掩盖它的脆弱处。错误不再是一个扎眼的洞,而像是一块表面铺得很平的地毯。你走上去,心里很踏实 —— 直到你摔倒之前。
解释有人可能会说,那让 AI 自己解释一下,不就能分辨了吗?
这个直觉有合理之处。有解释当然比没解释好。一个系统如果只扔给你一个结论,连理由都不说,那就很难谈信任。
但「有解释」不等于「人能判断」。Stanford HAI 曾经总结过一组关于 AI 过度依赖 的研究。一个很重要的发现是,解释能不能减少过度依赖,取决于它有没有降低人的识错成本。任务很难,而解释又很复杂,那解释未必是在帮人判断,反而可能只是让人更安心地相信。

这就如同一个初学者问专家:「你为什么这么判断?」专家讲了一大段专业理由。初学者听完,真的更会判断了吗?不一定。他可能只是更相信甚至仰慕专家了,因为那段话听起来好深奥,好有道理啊。
同样,当人看不懂 AI 的答案时,他也未必看得懂解释。解释可能不是一盏灯,而是一层更漂亮的包装纸。尤其是大模型擅长把话说得清楚、有层次、有信心。读者很容易把「读起来顺」误认为「逻辑上对」,把「术语够多」误解成「证据过硬」。
另外有 风险决策研究 发现,人们可能会过度依赖来自 AI 的建议。哪怕这个建议和上下文信息、甚至是自己的原始判断相冲突,参与者仍然可能跟着 AI 走。

所以,问题不是让不让 AI 解释,而是要把解释设计成一种可以追问、可以验证、可以反驳的东西。它不能只是在结论后面补一段更像样的话。
门槛很多人把「人类监督 AI」想得过于刻板。好像人必须比 AI 更懂,才有资格监督它。这个要求不现实。病人不可能完全理解医生的全部医学训练,法官不可能完全理解每个技术鉴定背后的全部实验细节,大学校长也不可能完全理解每个学科的最前沿争议。现实世界里的很多责任,本来就建立在不完全理解之上。
关键是,人要达到一个最低门槛,也即「最低可负责理解」。
一个人不必懂所有论文、所有模型、所有技术细节,但至少要能说清几个问题:目标是什么,底线在哪里,假设靠不靠得住,最容易在哪儿失败,什么证据出现时应该改判,如果真的错了怎么止损。

比如「目标」,最容易被忽略。你本来要解决的是「患者如何更快找到合适科室」,AI 可能一路把你带到「如何最大化分诊效率」。效率当然重要,但如果因此牺牲了弱势患者的可达性,问题就变质了。
「底线」也一样。医疗场景里不能牺牲安全、公平、隐私和尊严;组织管理中不能牺牲程序正义。AI 可以优化路径,但价值排序不能交给它悄悄决定。
之后,「假设、失败、改判、止损」其实是一串连续追问。我们需要仔细检查「默认假设」里,究竟藏了什么。例如方案的数据完整吗?指南是否适用于当地资源条件?患者愿意透露全部信息吗?执行者是否有足够训练?这些实际条件是否和假设一致?另外执行过程里最可能出现的问题,究竟会出在数据偏差、设备不足、工作流不匹配,还是患者不信任?什么指标异常就必须停?谁负责监测?谁有权叫停?……
这些问题没有要求你比 AI 更博学。可如果一个人完全说不清上述关键点,他就不是在和 AI 协同。他是在把判断权交出去。此时再高呼「人在环中」(human in the loop),就有点自欺欺人了。人在不在环中,不应看流程图上有没有设定一个「人类」节点,而看这个人是否还保有可负责的判断能力。
角色能力差距真的很大时,AI 还能帮人吗?
我觉得能,但 AI 的角色要变。不能只让 AI 扮演「答案机器」。因为答案机器越强,人越容易变成橡皮图章。更好的做法,是让 AI 帮人建立判断能力,把决策过程变得可审计。
第一种用法,是把 AI 当成认知脚手架。
它不是上来就说:「你应该选 A。」它应该先告诉你:「要做这个决定,你至少要理解几件事。第一件我用高中水平讲一遍;第二件我用本科水平讲一遍;第三件给你专家版;你现在卡在哪一层?」这种做法,应用于文献理解上,我在这篇文章里给你展示过。
这和直接给答案差别很大。直接给答案,是把人的短板遮起来。认知脚手架,是把短板暴露出来,再一层层补上。一个基层医生、一个新手管理者、一个刚进入研究领域的学生,都不可能一夜之间变成专家,但他可以借助 AI 知道自己缺哪块,该先补哪块,哪些地方必须请人复核。
再一种用法,是让 AI 当反方辩手。
我们不能只问 AI:「为什么这个方案好?」还要问:「反对这个方案最强的理由是什么?」「如果它失败,最可能是哪一个假设错了?」「有没有一个不那么先进、但更稳健的做法?」「哪个利益相关方会受到伤害?」
这一步很重要。因为很多关键错误不是信息不足,而是框架错了。
还有一种用法,是让 AI 做证据管理员。
这是指让 AI 把事实、推测和价值判断分开。哪些来自研究?哪些来自指南?哪些是模型自己的推断?哪些证据过时了?哪些证据有争议?哪些结论只适用于特定人群、特定地区、特定资源条件?
因为当人看不懂专业结论时,至少可以先检查证据结构。证据结构清楚了,人就有机会问出更好的问题,也有机会把不确定部分交给更合适的人(例如领域专家)复核。
最后一种用法,是让 AI 做流程审计器。
它不替你拍板,而是帮你预演:如果采纳这个方案,三个月后可能发生什么?三年后可能发生什么?最坏情况是什么?哪些指标一旦异常就要停?谁负责监测?谁有权叫停?
当然,这个任务用普通的对话机器人可能并不适合。不过你可以试试 Mirofish 这类的以 AI Agent 为节点的复杂系统仿真方式。
这时,AI 的价值不在于「比人更像专家」,而在于让人的盲区变少,让责任链条更清楚。
分级强调一下,你应该对需要处理的任务分级处理,不可眉毛胡子一把抓。
如果只是低风险、可逆、反馈快的任务,比如整理资料、处理会议纪要、梳理初步材料等,AI 可以高度参与。人做抽查,问题不大。错了也能改,反馈也很快。
中等风险任务就不一样。比如课程设计、研究选题初筛、市场方案、组织流程优化等。此时 AI 可以给建议,但你实施前最好先做三件事:先复述关键假设,再让 AI 提最强反对意见,最后用小范围试点验证。
而对于高风险、不可逆、影响他人的任务,就不能再靠一个看不懂 AI 的人单独拍板。医疗、法律、重大投资、公共政策、人员去留、学生评价、科研伦理,都属于这一类。这里的 AI 可以参与分析,可以帮忙找证据,可以提供候选方案,可以提醒盲区。但最终流程必须有专业人士参与、有制度审查、有责任链条,也要有事后监测。

不管是 WHO 的医疗 AI 伦理与治理指南、FDA 关于 AI 医疗器械的指导草案,还是 NIST 的 AI 风险管理框架,实质上都在提出一个基础但重要的要求:不能因为 AI 很聪明,就取消责任门槛。
AI 确实可以降低新手进入某个专业领域的门槛。它让原本没有机会接触前沿知识的人,得到更系统的参考;让边远地区医生多一个获取最新研究结果的平台;让年轻学生更早看见高手的工作方式。
但进入门槛降低,不等于责任门槛消失。毕竟最后如果出了问题,要负责、承担代价的还是具体的「人」,而不是机器。
小结回到最初的问题:当人与 AI 的能力差距太大时,AI 还能提供帮助吗?
我的答案是:能。但这时的协同,不能再理解成「AI 给答案,人来采纳」。它必须变成「AI 帮人建立足够的判断能力,并让决策过程可审计」。
如果做不到这一点,能力差距越大,越容易滑向两个失败方向。一个方向是,人变成 AI 建议的橡皮图章。出了事,人负责;平时,AI 支配。另一个方向是,人因为听不懂,干脆拒绝 AI。这样,AI 背后那些更新的知识、系统的证据、跨案例的经验,也进不了决策环节。
真正好的协同,不要求人永远比 AI 更懂。人需要能确定价值目标,理解关键假设,识别失败条件,设置止损方案,并知道什么时候必须请更专业的人介入。
如果这些问题你大体说得清,那可以继续谈协同。如果完全说不清,也不是不能用 AI。只是这时就要诚实一点:这不是协同,而是委托。
委托不是罪过。现实世界里,我们也经常把事情委托给更专业的人和系统。关键是,委托一定要采用与委托匹配的治理方式,包括提前约定边界、复核、责任、记录、退出机制等。
总之,判断一个人是否还在与 AI 协同,不取决于他是否比 AI 更懂,而在于他是否仍然站在一个有信心来签字负责的位置上。
你觉得呢?
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1531993.html
上一篇:还纠结他人作品「纯人工」还是掺了 AI ?你可能需要适应混合智能
下一篇:GPT Image 2 让图文并茂不再稀罕
