博文
别让 AI 替你「假装读完」:我如何用「做幻灯」倒逼论文精读?  精选
精选
|
 痛点
痛点
读论文这件事,最大的谎言大概就是「我读完了」。
其实很多时候,你只是「翻过了」。
当你把 PDF 关掉,脑子里往往只剩下一堆模糊的关键词:Transformer、扩散模型、泛化能力…… 但如果我追问一句:「这篇论文的核心冲突是什么?它的结论在什么边界条件下会失效?」
你可能一下子就卡住了。
为什么?因为我们太习惯于「被动输入」。尤其是现在有了 AI,很多人把 PDF 往模型里一丢,生成个摘要,看一眼「省流版」,就觉得自己懂了。
这其实是一种「认知卸载」(Cognitive Offloading)。你把思考的过程外包给了 AI,你以为你掌握了知识,其实你连「雨过地皮湿」的程度都没达到。你只是在过拟合别人的二手观点。
检验「懂没懂」的唯一标准,其实非常简单——你能不能把这篇论文,给一个外行讲明白?
这种方法,费曼用过,白居易也用过。挺好使的。
当然了,如果连你自己都没读懂论文,讲出来是不现实的。怎么办呢?
破局我在 2019 年写过一篇文章,建议大家读不懂论文时,去找作者讲这篇论文时用的幻灯片。
理由很简单:论文是写给同行看的,默认读者对专业基础知识都懂;但幻灯片是讲给听众听的,作者为了不让台下睡着,必须重构叙事逻辑,把最直观的图、最核心的洞察拎出来。

但问题来了:不是所有论文都能找到幻灯片。有的太老,有的作者不爱分享,有的链接早挂了。
既然「找幻灯」靠不住,我最近换了个思路:能不能利用 AI,把「读论文」变成「造幻灯」?
注意,我不是让你真的去设计排版,而是利用 AI 作为脚手架,强迫自己完成以下三个动作:
1. 拎骨架:识别论文的「核心冲突」,而不是堆砌公式。
2. 补逻辑:从观察到问题,从方法到实验,怎么过渡才顺畅?
3. 做预判:哪里是听众(你自己)最容易误解的地方?
这种「倒逼输出」的流程,比单纯看摘要累得多,但效果也好得多。
演示「光说不练假把式」。为了演示这个流程,我特意挑了一块「硬骨头」—— NeurIPS 2025 的最佳论文之一:《Why Diffusion Models Don't Memorize: The Role of Implicit Dynamical Regularization in Training》。

这篇论文讨论的是扩散模型的一个反直觉现象:明明参数量巨大,为什么它没有简单地「背诵」训练数据,而是学会了生成新样本?
如果直接啃 PDF,里面全是动力学方程和泛化界(generalization bound),很容易劝退。

为了把这个「倒逼输出」的流程标准化,我把它固化成了一套自动化动作。也就是在这个环节,我把论文丢进 AI 工具(这里我用的是 Youmind,你也可以用任何支持长文本与复杂指令的工具),执行我预设好的「论文转幻灯」指令。
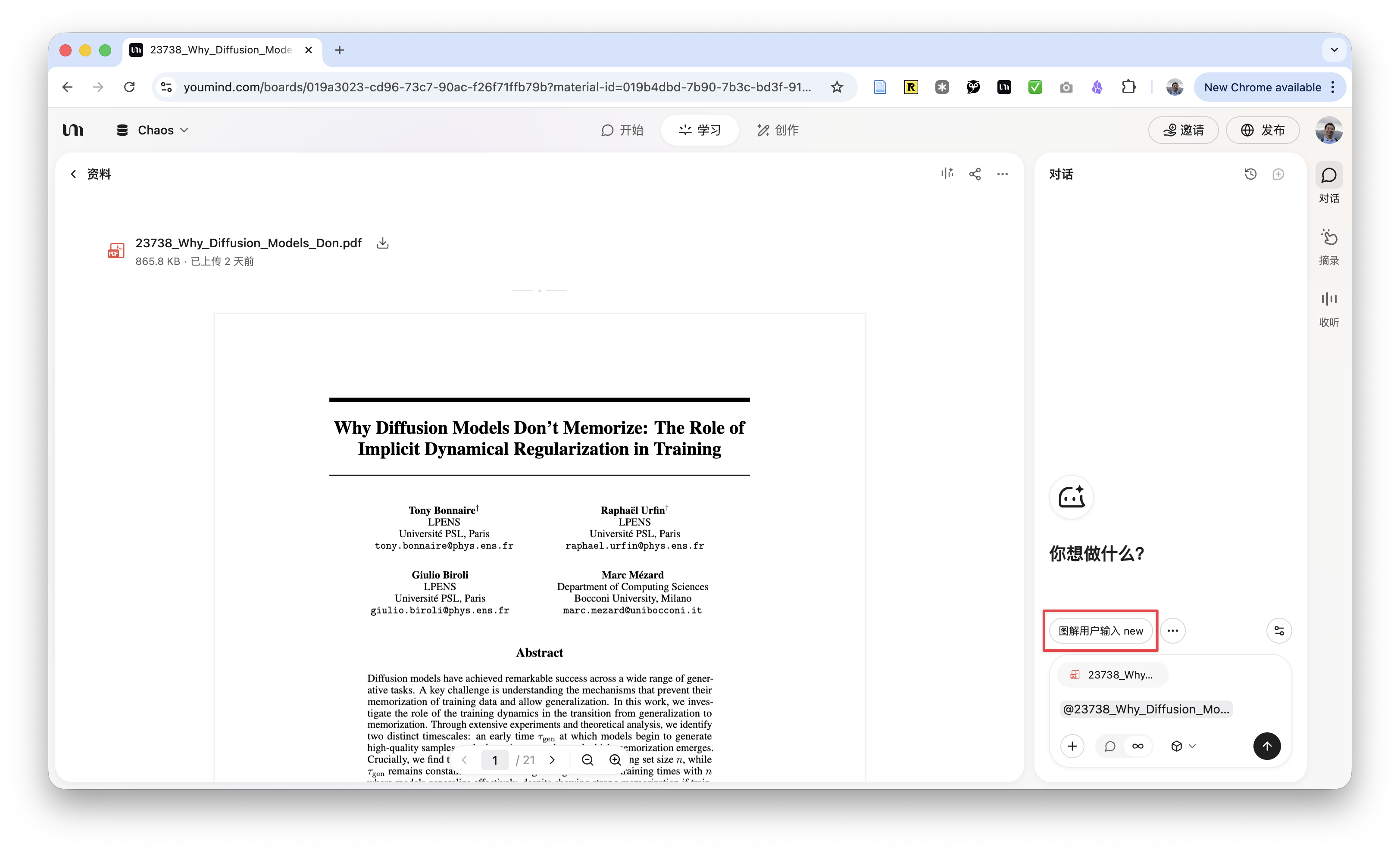
这套指令的核心逻辑不是「总结」,而是「重构」:它必须先识别出论文的「叙事动线」,再规划 16 页的逻辑流。
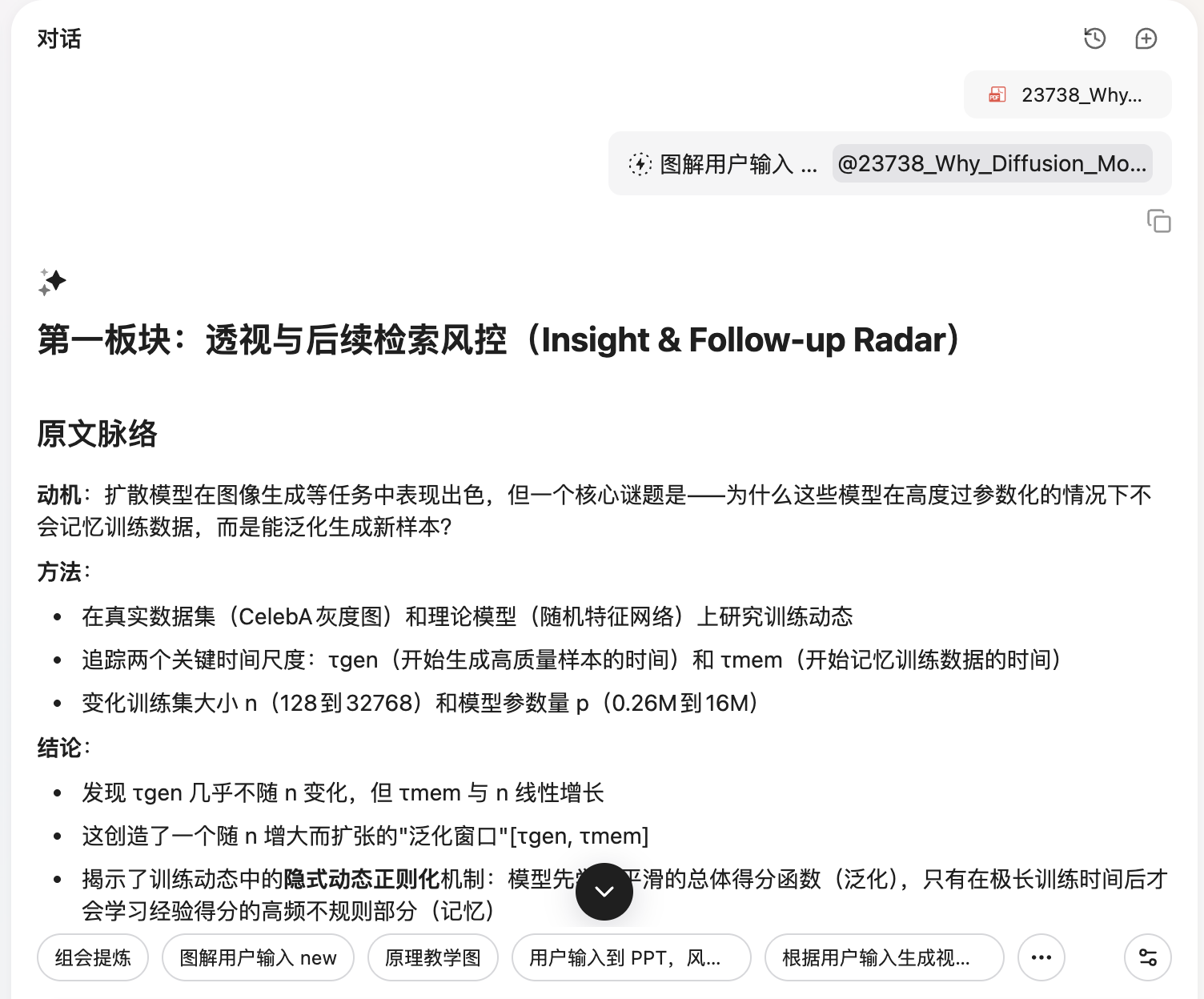
然后,AI 会按照我们预设的步骤,做出全部的图片,构成一个完整的讲解 PPT,并且配上合适的文字解说。
效果如何?我们直接看它对这篇 NeurIPS 最佳论文的处理结果。
洞察这套流程跑出来的,不是简单的图文堆砌,而是一个 「可讲」的叙事结构 。
首先,它帮我抓住了 「核心悖论」 (第 1 页):按直觉,过参数化模型应该复制训练样本,但扩散模型却能生成新样本。这就是你开场要抓住的矛盾,一下子就能把听众(和你自己)的注意力抓回来。

紧接着,它提取出了论文的灵魂——两个关键时间点(第 2 页):
• :模型开始学会生成高质量样本的时间。
• :模型开始死记硬背训练数据的时间。
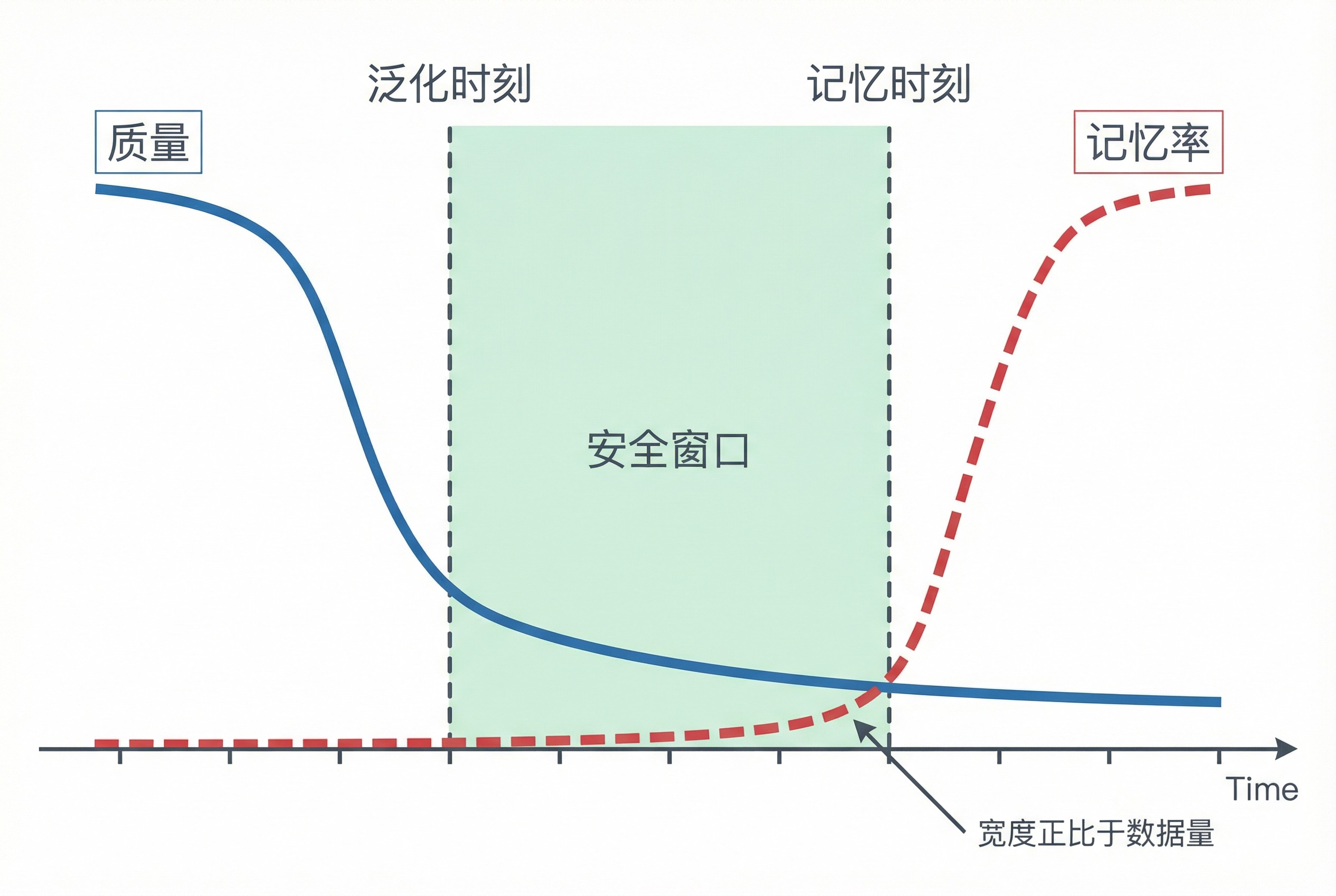
这一页非常关键,它把复杂的数学推导,降维成了两个时间尺度的赛跑。
然后,它破除了一般人的直觉误区(第 3 页):数据越多,模型是不是越容易记不住?
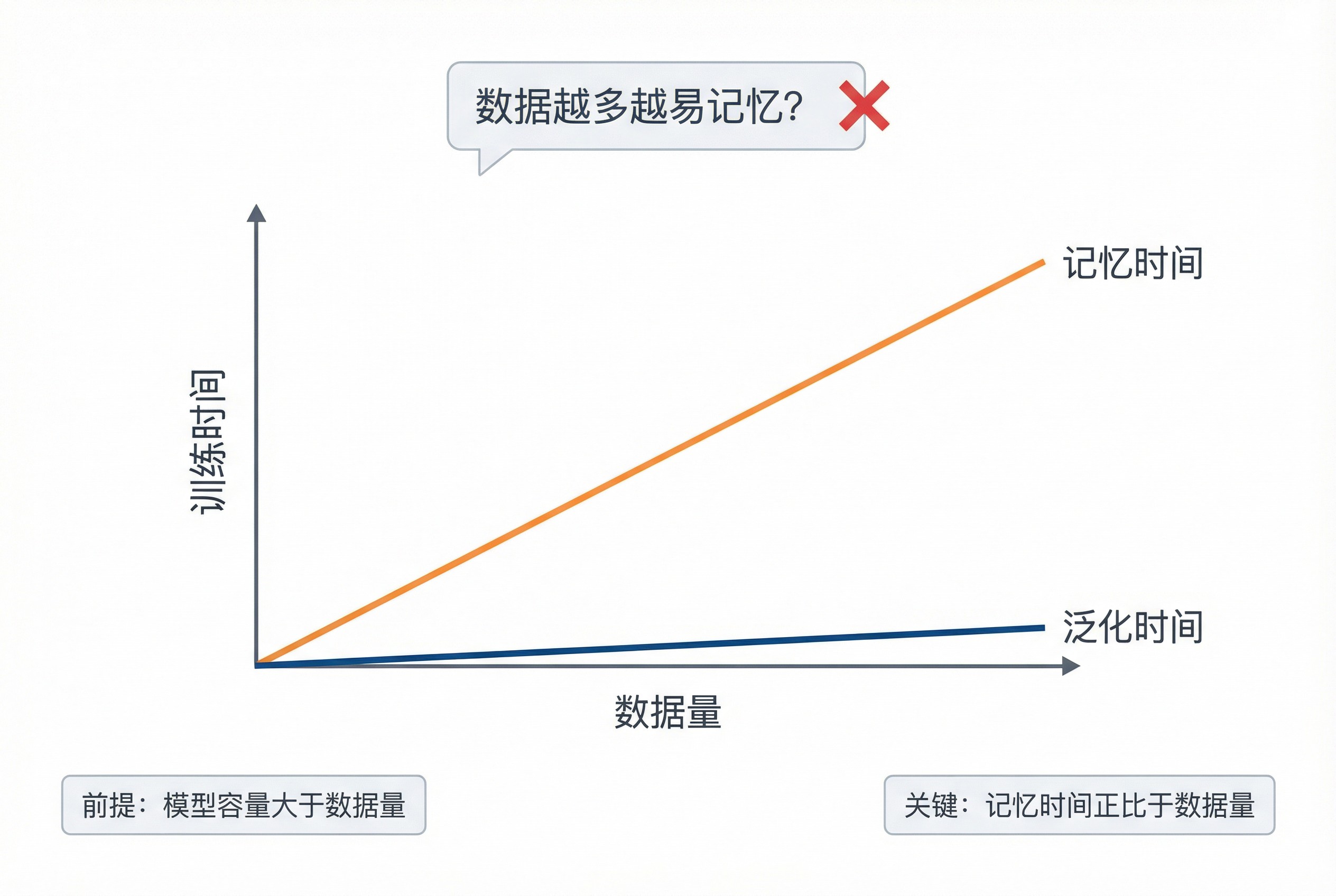
AI 生成的这张斜率对比图,非常直观地展示了一个「剪刀差」:随着数据量 的增加, 几乎不变,但 线性增长。这意味着,数据越多,中间那个安全的「泛化窗口」就越宽。
你看,有了这几页垫底,后面的实验验证(第 4 页)、相图分析(第 5 页),甚至是背后的随机特征网络理论(第 8-9 页),理解起来就顺理成章了。
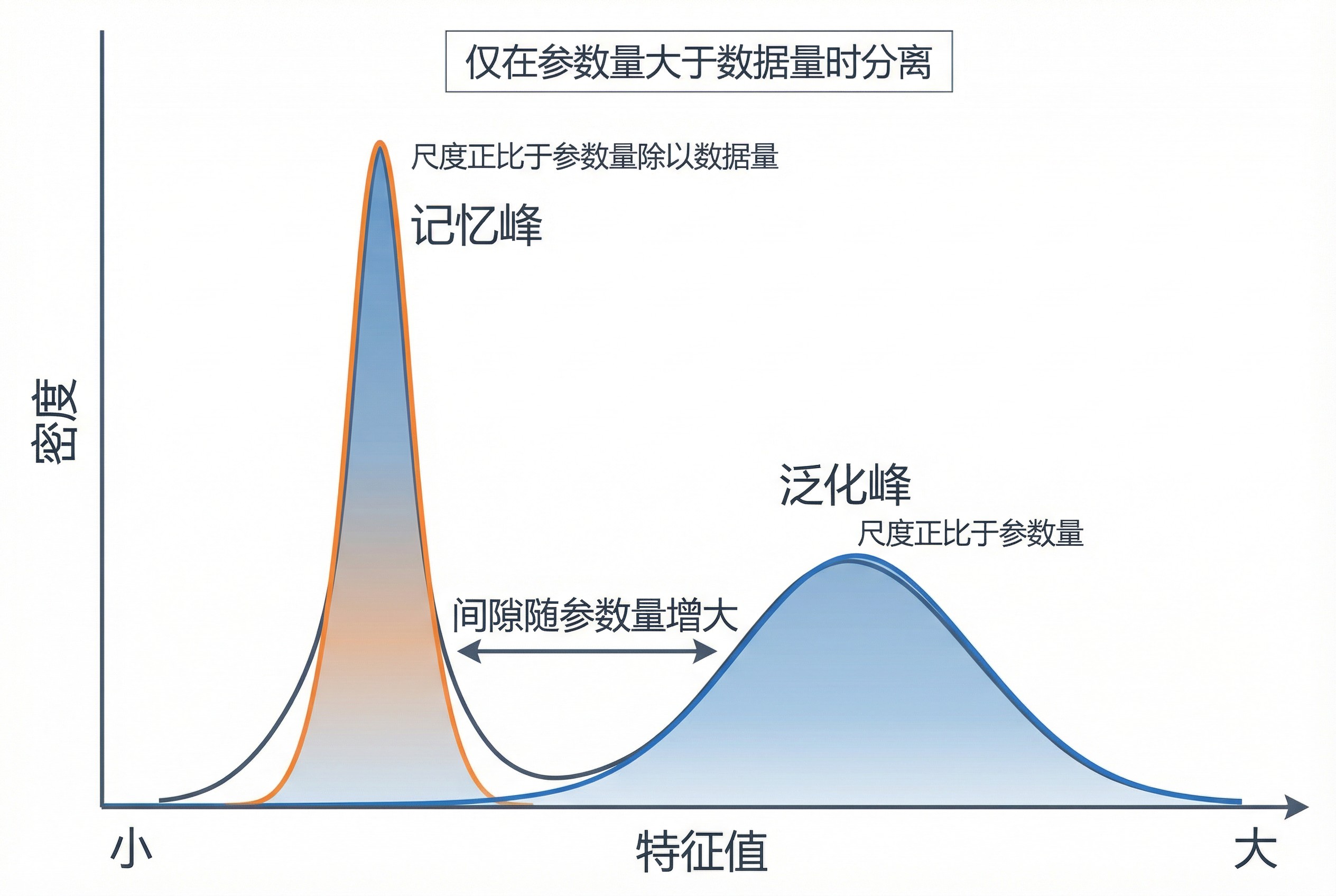
特别是第 9 页,用特征谱的双峰结构来解释为什么会有两个时间尺度。如果不通过这种「讲给别人听」的视角去重构,你在读 PDF 时很容易在这个技术细节上滑过去。
最后,它把所有内容收束成一句金句(第 16 页):「训练时间是正则化器」。
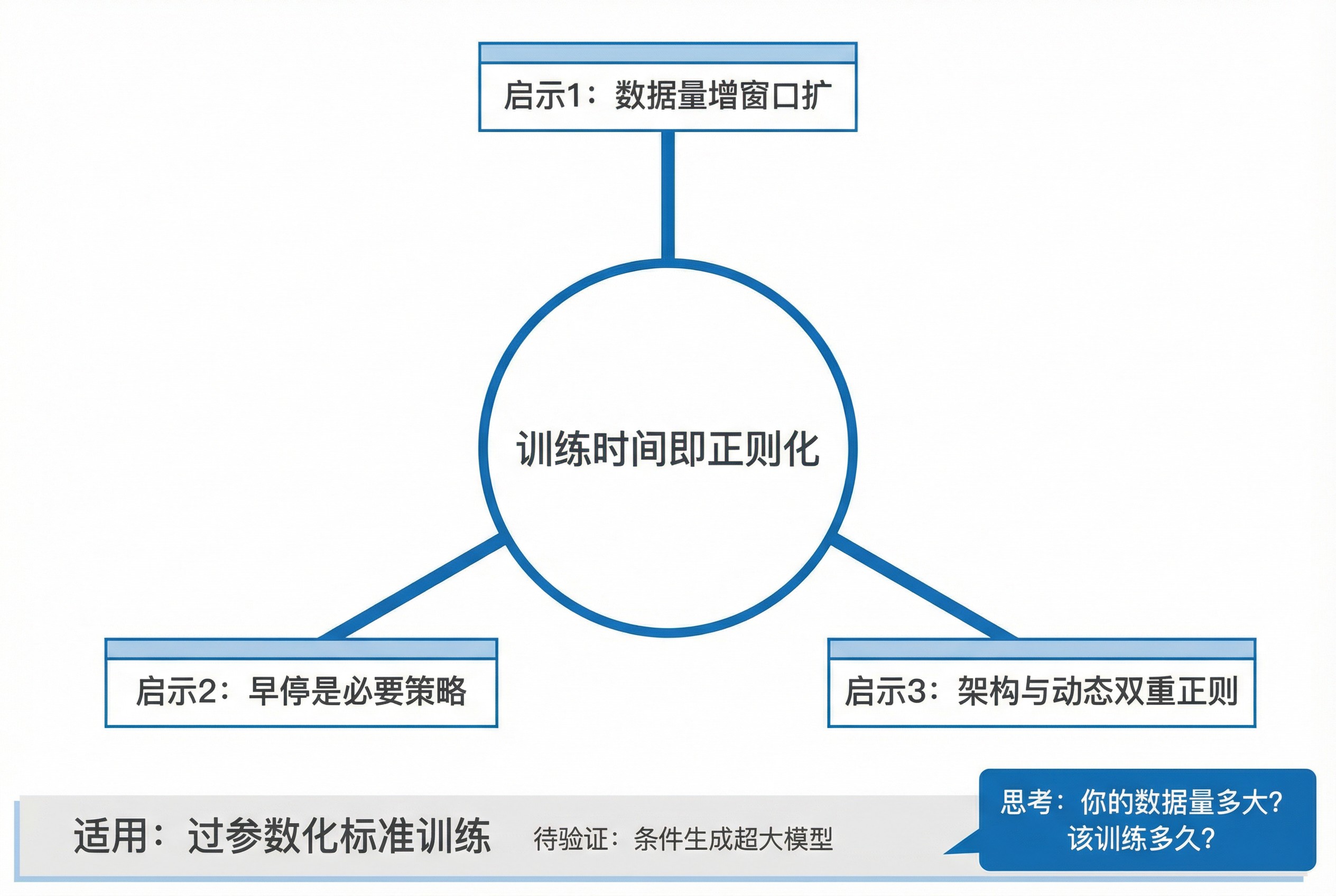
这不仅是结论,更是行动指南:训练扩散模型,不是跑得越久越好,你得盯着那个窗口。
深挖但是,光有幻灯片就够了吗?
不够。
AI 可能会一本正经地胡说八道,或者把作者的观点奉为真理。做研究,必须有批判性思维。
所以,在这个工作流里,我强制加入了一个 「对抗性检索」 环节。我要求 AI 必须去 Arxiv 和网络上,寻找这篇论文的后续工作、平行研究,甚至是反面意见。
看看 AI 帮我挖到了什么:

• 平行证据:AI 找到了 Favero 等人的论文 Bigger Isn’t Always Memorizing (Arxiv 2505.16959),他们也发现了类似的「早停」规律,这说明 NeurIPS 这篇论文的结论是鲁棒的,不是孤例。
• 机制探讨:AI 找到了 How Diffusion Models Memorize (Arxiv 2509.25705),从动力学角度进一步解释了记忆是如何发生的。
• 大众视角:AI 甚至还找到了一篇腾讯新闻的 通俗解读。如果你要发朋友圈或者给非专业人士解释,这个链接就很有用。

这一步非常关键。它让你从「只看这一篇」,变成了「看这一片(论文)」。
陷阱你获得的不仅是讲解的 PPT,以及针对每一页 PPT 的讲解要领(尤其标注了可能出现问题的地方),以此帮助你躲开陷阱并引发你的思考。

看到这里,有些马上就要拿着自己的讲稿去参加组会的研究生同学,是不是已经「会心一笑」了?
别着急,我必须给你泼一盆冷水。
这套工具很强大,但它不是万能的。
第一,它不能替代你的阅读。AI 是脚手架,帮你快速搭建结构。但楼建好了,脚手架是要拆的。特别是幻灯片里引用的那些实验数据、曲线图,你必须回到 PDF 原文里去核对。AI 在画图表数值时,难免会产生幻觉,千万别拿 AI 生成的图直接去答辩。
第二,警惕「流利感的错觉」。AI 生成的讲者提示(Speaker Notes)通常写得很漂亮,读起来朗朗上口。但这不代表你真懂了。卡壳的地方,往往才是你真正需要花时间去啃的盲区。
如果你不能理解 AI 的这些局限,把这套流程生成的内容当作你阅读论文的终点,而不是起点,那么你才是真正掉进了陷阱。
小结这篇文章,我把一个「私房」的研读论文工作流分享给了你:利用 AI 的分析、检索、思考与绘图能力,把「被动阅读」转化为「主动策展」。
利用工具,我们把一篇晦涩的 PDF,变成了一套逻辑严密的幻灯片初稿,并附带了外部的证据链核验。
如果你觉得这套方法对你有启发,我把这个 Shortcut 封装好了,你可以直接取用。
如果你不打算用 Youmind,打算使用另外的 AI Agent 来运行也没有关系。我这里把提示词完整地呈现给你,请参考这个 Notion 链接。注意你使用的 AI Agent 一定要能调用 nano banana pro 生图,并且要有学术信息检索工具的调用能力,否则效果会大打折扣。
不过,我想说:拥有这套工具,并不代表你拥有了知识。这其中,你与 AI 生成结果的交互,以及你真的拿来讲授获得反馈,才是最重要的官窍。
用 AI 辅助去啃下一篇你曾经不敢碰的硬骨头。然后关掉 AI,拿起这些简洁的 PPT 图表,用你自己的语言,把它讲给身边的人听。
别人频频点头乃至恍然大悟时,那才是知识真正属于你的时刻。
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1516299.html
上一篇:大学课堂学生不抬头,老师怎么办?
下一篇:如何用 Claude Skill 帮你一句话做深度调研并自动画图?
