博文
Claude Skill 快照:给你的 AI 技能迭代加个「后悔药」  精选
精选
|

之前 我的一篇介绍 Claude Skill 的文章 很受大伙欢迎。很多小伙伴看过之后都跃跃欲试。
不知你都做了几个 Claude Skill 出来了?
假设为了完成某项任务,你 参考我的教程 创作了一个 Claude Code 的技能,并且不断迭代改进。折腾了好几天,技能终于调通了,效果也不错。你长舒一口气,想着「太好了,终于搞定」。
然后,你有了一个新想法:「要不,再加个功能?」
手悬在键盘上方,却迟迟不敢落下。
万一改坏了呢?万一新功能没加成,反而把原来能用的逻辑给弄崩了呢?你不记得之前是怎么调通的了,那些试错的弯路、那些灵光一现的小修改,全都模糊了。
于是你做了一件事:复制整个文件夹,改个名字。
my-skill-backup。
过了两天,你又改了一版,又备份一次:my-skill-v2。
再过几天:my-skill-final。
然后是 my-skill-final-final。
最后,你的文件夹里躺着一排沉睡的文件夹:my-skill-final-final-v2 - 真的最终版。
哪个是能用的?哪个对应哪个功能状态?天知道。
这就是我说的「改进恐惧症」——技能调通后不敢动,生怕一动就回不去了。
今天要聊的这个工具,是我自己(指导 Claude Code)写的 Skill,叫做 "Skill Snapshot"(技能快照),专门治这个恐惧症,给你提供「后悔药」。
背景在往下讲之前,咱们先对齐一下背景知识。
Claude Code 是什么?你可以把它理解为一个住在命令行里的 AI 助手。它不只是聊天,还能帮你写代码、操作文件、执行命令。它就像一个坐在你电脑里的实习生,你说什么,它就去做什么。
Skill(技能)又是什么?你可以把它理解为给 Claude Code 加装的「专业模块」。就像手机里的 App,每个 Skill 让 AI 学会一项新本领。比如,你可以创建一个「写作助手」技能,专门帮你按照特定风格写文章;或者创建一个「代码审查」技能,专门帮你检查代码质量。
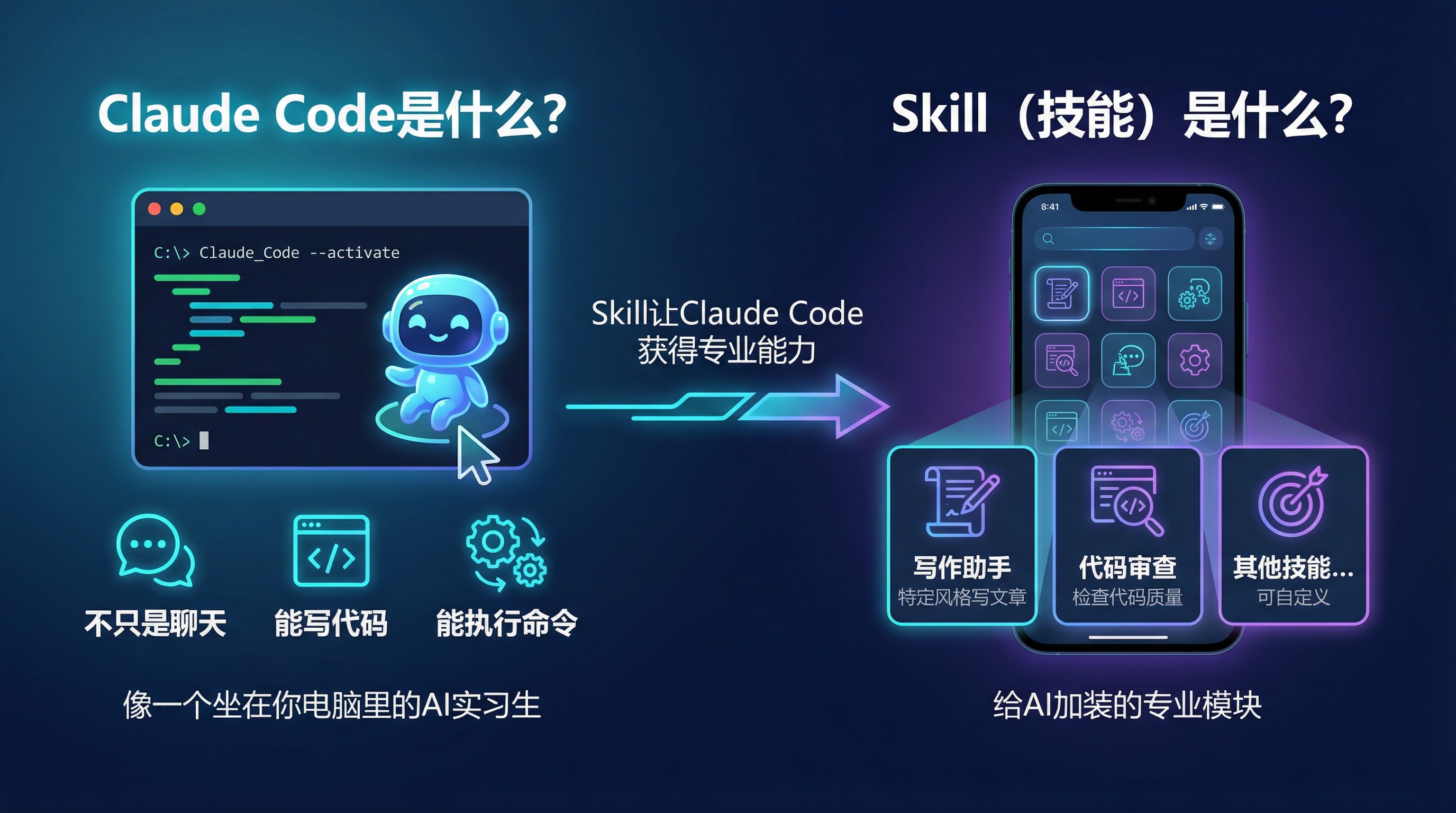
每个技能本质上就是一个文件夹,里面有一个叫 SKILL.md 的说明书,告诉 Claude Code:这个技能叫什么、能做什么、怎么触发。如果你想详细了解 Claude Skills,欢迎查看我的这篇文章。
就在几天前 ——2026 年 1 月 7 日 ——Claude Code 发布了 2.1.0 版本,带来了一波重大更新。Skills 功能大幅增强:支持热重载、支持自定义代理、可以用 / 直接调用。越来越多人开始创建自己的 Skills,技能的数量在快速增长。
但技能多了之后,一个新问题浮出水面:版本管理。
你有 10 个技能,每个都在不断迭代。哪个改过了?改了什么?改坏了怎么办?
这就是我做的 Skill Snapshot 要解决的问题。
程序员写代码有 Git,设计师画图有版本历史,连 Word 文档都有「修订记录」。但 Claude Code 的技能呢?之前没有现成的方案。
现在有了。
破局我做 Skill Snapshot 的设计思路很简单:不重新发明轮子。
版本管理这件事,Git 已经做了几十年,是业界公认最成熟的方案。云端存储和同步,GitHub 也做得很好。既然有现成的基础设施,为什么要自己从头写?
所以 Skill Snapshot 的核心思路是:复用 Git + GitHub,用自然语言包装一层。
假设你的技能名称为 my-skill。你不需要记住 git commit -m"message" 这种命令,只需要说「保存 my-skill 快照」,工具会帮你翻译成具体的 Git 操作。
存储位置选的是 GitHub 私有仓库。你可以把它理解为上了锁的保险柜——只有你自己能看到里面的内容,别人看不到。免费,安全,还能跨设备同步。
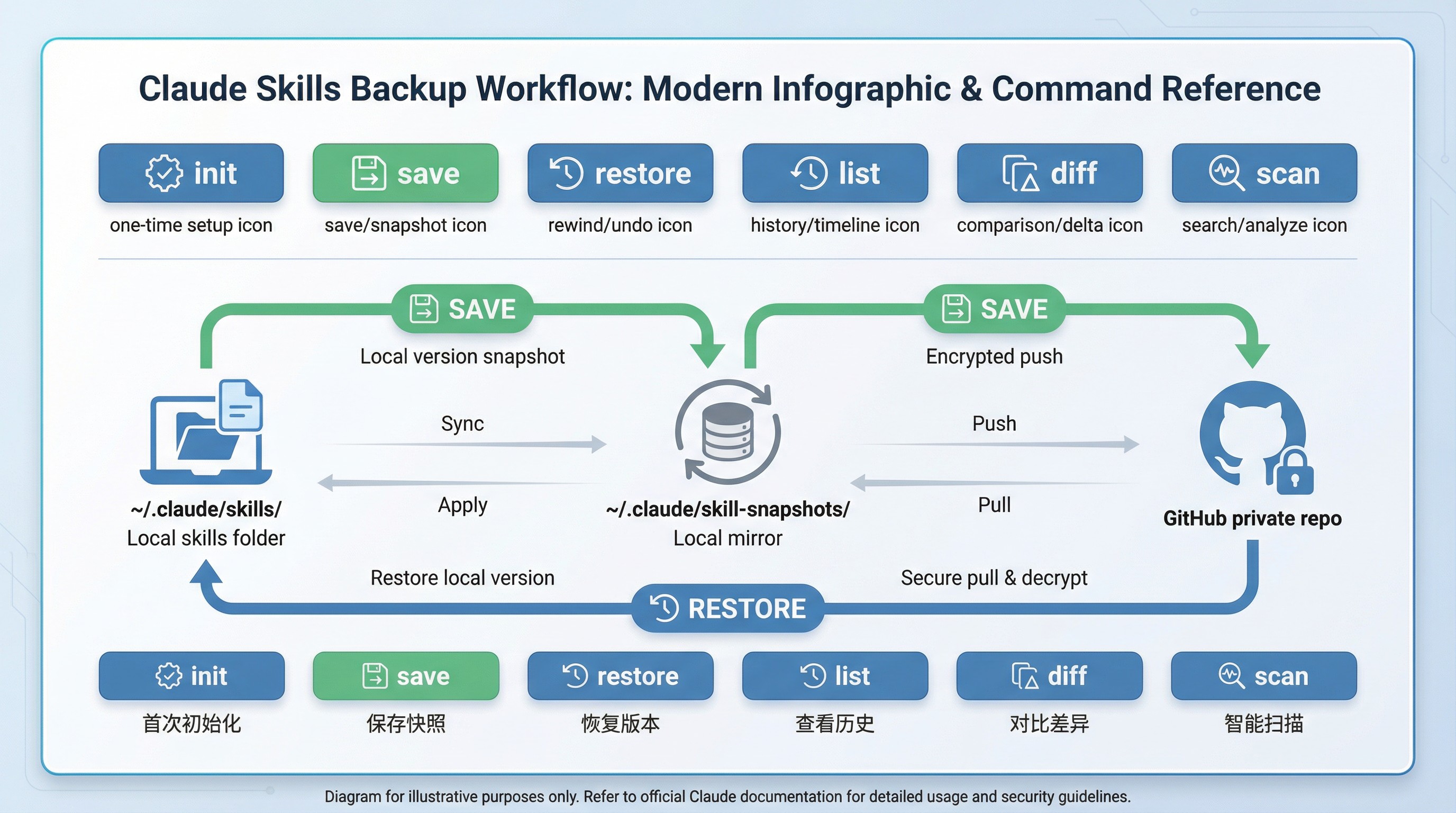
整个工具提供了 6 个命令,每个解决一个具体痛点:
init 负责初始化 —— 首次使用时执行一次,自动在 GitHub 上创建私有仓库,然后把它克隆到本地。这是一次性的设置,之后不用再管。
save 负责保存快照 —— 在你修改技能之前,跑一下这个命令,当前状态就被存档了。就像游戏里的「存档」功能。
restore 负责恢复版本 —— 改坏了?没关系,一键退回到之前保存的某个版本。这是整个工具的核心价值所在。
list 负责列出历史 —— 查看某个技能有哪些版本,每个版本是什么时候保存的,当时写的说明是什么。对抗记忆衰退。
diff 负责对比差异 —— 当前版本和某个历史快照之间改了什么?一目了然。
scan 负责智能扫描 —— 自动判断你的技能目录里,哪些需要备份,哪些可以跳过。减少决策负担。
数据流是这样的:你本地的技能文件夹(~/.claude/skills/)通过 save 命令同步到 GitHub 私有仓库,需要恢复时再通过 restore 命令拉回来。中间有一个本地镜像(~/.claude/skill-snapshots/)作为中转站。
以上这些你了解就好,因为你从来不需要像写 Bash 脚本一样去可钉可铆调用这些功能,而是用自然语言跟它对话。甚至可以像我一样弄个话筒,随时拿起来跟 AI 一通「布置工作」。
 上手
上手原理说得够多了,下面咱们不如直接上手试试。
第 0 步:安装首先,请你执行以下命令,完成该技能的初始安装:
git clone https://github.com/wshuyi/skill-snapshot-skill.gitcp -r skill-snapshot ~/.claude/skills/之后,启动 Claude Code 的一个新对话,就可以继续了。
第一步:初始化首次使用需要对已有技能的快照初始化,这一步只做一次。
你在 Claude Code 中,说一句「初始化技能快照」。
背后发生了什么?工具会用 GitHub CLI 的 gh repo create 命令,在你的 GitHub 账号下创建一个私有仓库,名字叫 skill-snapshots。然后把这个仓库克隆到本地 ~/.claude/skill-snapshots/ 目录。
输出大概长这样:
=== Skill Snapshot 初始化 ===→ 创建私有仓库: your-username/skill-snapshots✓ 私有仓库已创建→ 克隆到本地: ~/.claude/skill-snapshots✓ 已克隆到本地=== 初始化完成 ===私有仓库: https://github.com/your-username/skill-snapshots本地路径: ~/.claude/skill-snapshots看到这个输出,初始化就完成了。以后不用再跑这一步。
其实你完全可以不用显式地执行这一步。只要你下达备份某项技能的指令,如果系统发现该技能尚未初始化,它就会自动替你完成这一操作。
第二步:扫描技能初始化完成后,你可能想知道:我有哪些技能需要备份?
你不需要挨个地打开技能去翻找,只需要说一句「扫描技能」。
工具会遍历你的 ~/.claude/skills/ 目录,用一套规则自动判断:哪些是你自己写的、需要备份的技能;哪些是外部安装的、不需要管的。
输出大概长这样:
=== 技能快照扫描 ===【需要备份】○ my-skill (5 files, 68K) [未备份]○ another-skill (3 files, 12K) [未备份]✓ third-skill (4 files, 24K) [已有: v1]【跳过】✗ archive - 归档目录✗ external-plugin - 符号链接(外部安装)✗ git-managed-skill - 自带 Git 版本控制需要备份: 3 个跳过: 3 个这个扫描很聪明。它会跳过几类技能:归档目录(archive)不管;符号链接(你可以理解为「快捷方式」)指向的外部安装插件不管;本身已经有 .git 目录、自带版本控制的技能也不管 —— 它们自己有办法。
剩下的,就是你真正需要关心的技能。
第三步:保存快照看到「未备份」的技能了?在修改它之前,可以先存个档。
你说一句「保存 my-skill 快照」即可。如果你想加一句说明,可以说「保存 my-skill 快照,说明是『添加 XX 新功能前』」。
输出:
=== 保存快照 ===技能: my-skill版本: v1说明:添加 XX 新功能前✓ 快照已保存: my-skill/v1→ 可用 'restore my-skill v1' 恢复完成。这个技能的当前状态已经被保存到 GitHub 私有仓库了,打上了 my-skill/v1 的标签。
如果你连续保存两次,但中间没有修改任何文件,工具会告诉你「无变化,不需要保存」—— 它不会创建无意义的版本。
对于我这样的懒人,会干脆要求 Claude Code「把所有你觉得需要备份的 Skill,都存一下」。完成。
第四步:恢复版本这是整个工具最核心的功能。
假设你改了 my-skill,改坏了,想退回去。说一句「恢复 my-skill 到 v1」。
输出:
=== 恢复快照 ===技能: my-skill版本: v1→ 当前版本已备份到: .snapshot-backup/my-skill-20260110✓ 已恢复到 my-skill/v1→ 技能位置: ~/.claude/skills/my-skill注意看第一行:「当前版本已备份到……」。工具在恢复之前,会先把你当前的版本(哪怕是改坏的版本)备份一份。为什么?万一你恢复后又后悔了呢?万一你发现「其实刚才改的那个版本有个地方是对的」呢?这份备份就是你的后路。
这种「替用户多想一步」的设计,叫做防御性编程。
因为咱们没有实际去编写代码,所以这叫「防御性氛围编程」,哈哈。
发布Skill Snapshot 开发完成后,我决定把它公开分享。让你拿过来直接就能用。
但在发布之前,我必须(让 Claude Code)做一件事:隐私检查。
为什么?因为把技能发布出去的时候,规则和代码里可能藏着敏感信息。你自己用没问题,但公开给别人看就不合适了。
我把这事儿交给了 Claude Code ,于是它立即用 grep 命令搜了一遍:
grep -rn "wsy\|wshuyi\|/Users/" ~/.claude/skills/skill-snapshot/结果找到了 16 处私有技能名的引用,比如 wsy-writer、research-to-diagram。这些是我自己的技能,名字里带着个人标识。
怎么处理?脱敏。
Claude Code 自动把 wsy-writer 换成通用的 my-skill,把 research-to-diagram 换成 another-skill。用 sed 命令全局替换,确保没有遗漏。
发布的时候,当然还有一件事:双语文档。
我的读者有中文用户,也有英文用户。所以我准备了两份 README:
README.md 是英文版,开头第一行就是指向中文版的链接:[中文文档](README_CN.md)。
README_CN.md 是中文版,开头第一行指向英文版:[English](README.md)。
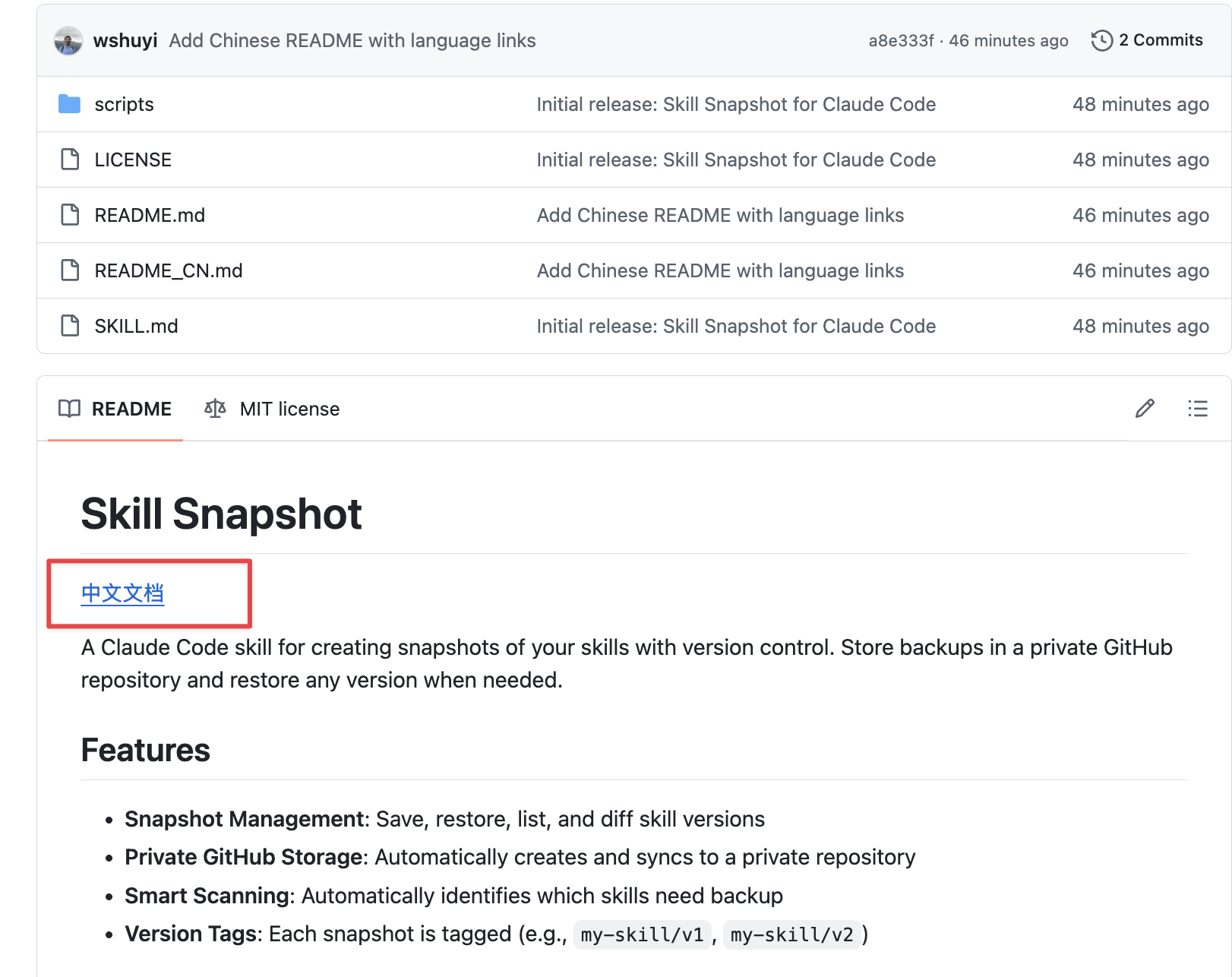
这样做的好处是:无论用户从哪个入口进来,都能一键切换到自己熟悉的语言。这不是锦上添花,是对非母语用户的基本尊重。
最后,Claude Code 自动用 GitHub CLI 创建公开仓库:
gh repo create skill-snapshot-skill --public --source=. --push发布完成。公开仓库地址:github.com/wshuyi/skill-snapshot-skill。你可以直接点击查看。
感觉好用的话,别忘了给加一颗星哦。
小结回过头来看,Skill Snapshot 这个小工具制作的路径,背后,藏着几个可以迁移到其他场景的思维模式。
第一,复用成熟基础设施。版本管理这件事,Git 已经做了几十年,稳定可靠,功能丰富。我没有自己写一套版本控制逻辑,而是直接站在 Git 的肩膀上。在设计新系统时,第一个问题应该是「有没有现成的轮子可以用」。
第二,规则引擎替代人工决策。scan 命令用了 7 条规则来自动判断哪些技能需要备份:归档目录跳过、符号链接跳过、自带 Git 的跳过、体积超过 10MB 的跳过……这些规则一旦定义好,就不需要用户每次自己判断了。把重复性的决策交给规则,人才能专注于真正需要思考的事情。注意我也没有指导 Claude Code 定立这7条规则,我只是让它去思考该如何判定,并把这些判定沉淀、固化下来。
第三,防御性(氛围)编程。恢复版本前先备份当前版本,这是「替用户多想一步」。无变化时友好提示而不是崩溃退出,这是「把用户当朋友而不是敌人」。好的工具应该预见用户可能犯的错误,并提前铺好退路。这里有的时候,Claude Code 不一定能想得很周全,需要你在合适的地方提示一下。
第四,「元技能」的概念。Skill Snapshot 是一个「管理技能的技能」。此时在我的 Claude Code 生态系统中,创建技能有 skill-creator(来自官方),发布技能有 skill-publisher,备份技能有 skill-snapshot。当某类操作变得频繁,就值得把它抽象成一个工具。工具的工具,框架的框架——这种「元」的思维方式,是提升效率的关键。
最后,送你一句话:
没有版本管理的 Claude Skill 技能,就像没有存档的游戏。
你可以一路顺风打到最后一关,但只要失败一次,就得从头再来。
有了存档呢?大胆尝试,随时回退。「嘎」了不怕,读档重来。
这才是我们积极尝试 Skill 创作和修改时,正确的打开方式。

现在,去初始化你的第一个快照,然后放心大胆迭代改进 Claude 技能吧。
你自己创建了哪些新的「元技能」,都解决了哪些痛点?欢迎留言,咱们一起交流讨论。
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1517927.html
上一篇:Claude Skills 入门:一篇文章搞懂 AI 怎么从「嘴替」升级成「打工人」
下一篇:当产品经理遇到 Claude Skills
