博文
AI 算不算一种研究方法?  精选
精选
|
 疑问
疑问
2025 年 12 月 5 日,我应樊振佳副院长邀请,回到母校南开大学,给信息与传播学院、商学院的老师和同学们做了一场关于「AI 辅助科研」的报告。

讲座结束后的问答环节,主持人南开大学李颖教授提出了一个问题(我尽量还原李老师的原话):
我们以往大家熟悉的研究方法,比如说社会科学研究方法规范的,大家可能学阿尔巴比的书里也提到的这些方法,就是经过很长时间各种不同的学科,经过验证一步步形成的。我们是认可的,所有的学界,不管国内国外,包括不同的学科,它是一种规范的方法。
但是如果说像 ChatGPT 这些东西,在我们的科研中使用,大家已经不能够忽视了。现实中就是大量的在使用,从你选题开始一直到你最后投稿结束,各种修改全过程全覆盖了。但是它的这种介入,作为一种从科研的角度来讲,这种方法是不是规范?它的合规性、规范性怎么能才能得到认可?或者是现在有一些学者认为,它不是规范的研究方法。不知道王老师对这个问题有什么看法?
我觉得李老师这个问题非常好,代表了当下许多研究者心中的困惑。归纳起来,就是:AI在科研中,到底算不算一种研究方法?它的边界在哪里?
当时讲座已经超时(我的错,更新资料过多了),无法展开来答了。不过我觉得这问题很重要,值得单独写一篇文章来回应。这里我结合现场的回答,以及之后的思索,来更为完整地给出我的思考。
厘清在正式回答之前,我想先做一件事:厘清概念。
你想想看,当我们说「用AI做科研」的时候,至少有两种截然不同的场景。第一种,是让AI帮你分析数据——比如你有一万条用户评论,让AI帮你做情感分析、主题标注。第二种,是让AI帮你生成数据——比如你不想招被试做问卷,干脆让ChatGPT模拟一千个「虚拟人」来填答。
这两件事,看起来都是「用 AI」,但性质天差地别。前者,AI 是你手里的「显微镜」,帮你看清真实世界;后者,AI 是你手里的「永动机」,帮你凭空捏造一个世界。
如果我们不把这两件事分开,讨论就会陷入混乱。你说「AI 不靠谱」,支持者会反驳「可它分析文本确实又快又准啊」;你说「AI 可以当研究工具」,反对者会质疑「那让它模拟被试算不算造假」。双方鸡同鸭讲,永远吵不出结果。
所以,我的第一个观点是:「生成数据」和「分析数据」是两回事。AI做被试(Subject)确实有争议,但在处理海量文本、辅助编码时,它就是一种高效的研究工具(Instrument)。否定前者,不能连坐后者。
把这个前提立住了,我们才能继续往下聊。
根源好,概念厘清了,我们来看 AI 的「底层逻辑」。
要判断 AI 能不能成为一种「研究方法」,我们不能只看它「能做什么」,而要看它「怎么做」。如果一种工具的底层逻辑与科学精神相悖,那它就很难被称为「方法」。
科学精神的核心是什么?两个字:求真。再加两个字:复现。一个实验,你做一遍是这个结果,我做一遍还是这个结果,换个实验室再做还是这个结果——这才叫科学。
AI 在这两点上,都有先天的「硬伤」。
第一个硬伤:它是「概率」的,不是「逻辑」的。
大语言模型的本质是「文字接龙」。研究人员从互联网上搜刮了海量的文本 —— 网页、书籍、代码、论文 —— 然后让模型学习:给定前面几个字,后面最可能接什么。就是这样,一个字一个字地「接」出来。
你可能无法相信,能编程、能作文的大模型,居然是靠着这种方式训练出来的。但这其实是没办法的办法。我们教 AI 学东西,总要给出正确的教材(输入和标记)。可问题是,输入过于海量时,标记不够用。所以聪明的研究者想出来一种方法,任何一句话,都可以用前半部分作为输入,然后下一个词作为标记。这样就可以充分挖掘资料,而不需要额外进行标注了。
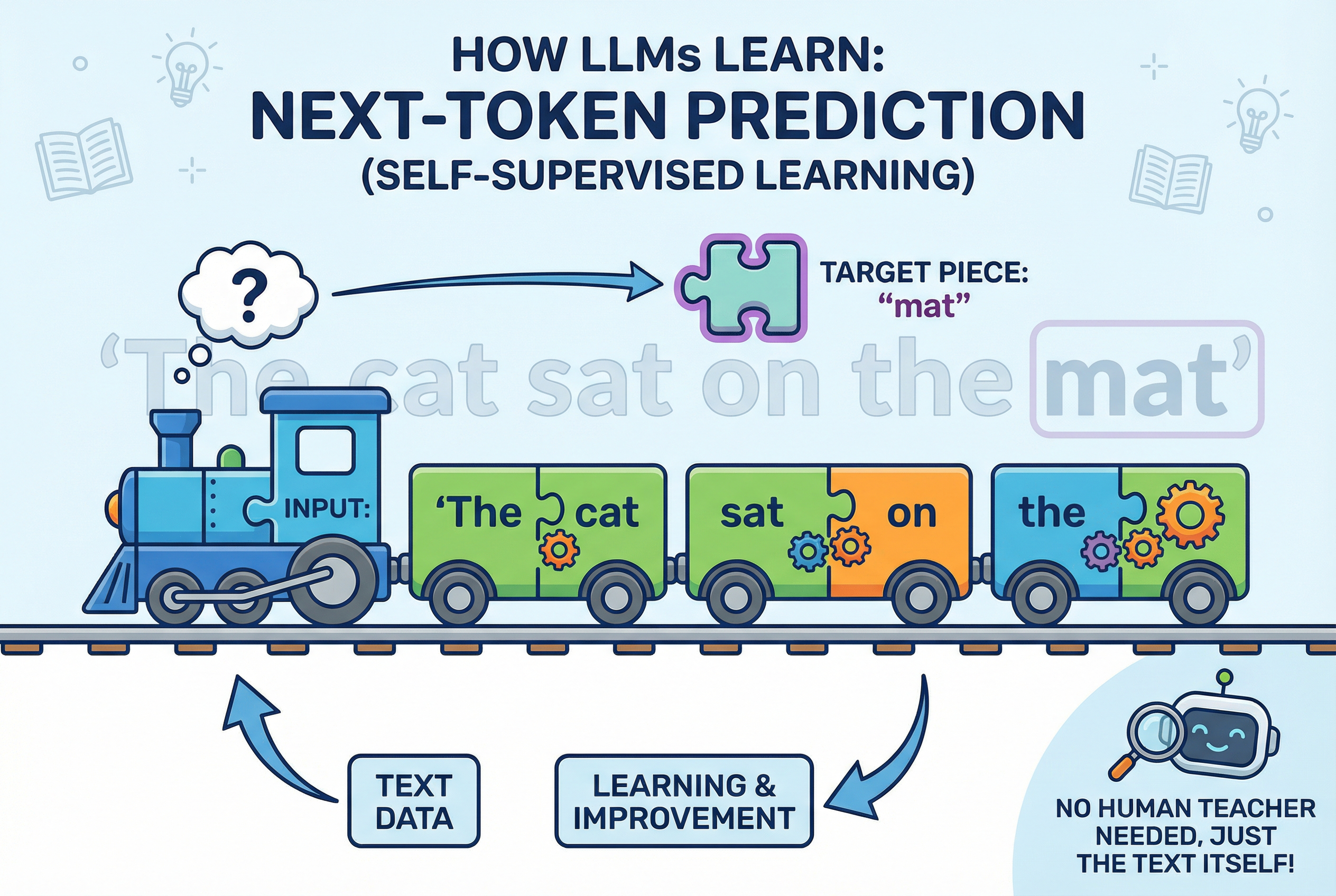
所以,大模型并不神奇。它其实就是在接下茬。
这意味着什么?意味着它输出的不是「真理」,而是「下一个词出现的最大概率」。即使是完全相同的输入,AI在不同时间也可能给出不同的输出。一个连结果都无法稳定复现的「黑盒」,很难直接被视为严谨的「科学方法」。这才是它难以成为独立「科学方法」的法理障碍——它不具备确定性。
第二个硬伤:它患有严重的「讨好病」。
光会接下茬还不够。为了让模型的回答更「像人话」,研究人员引入了一种叫做 RLHF(人类反馈强化学习)的训练方法。简单说,就是让人类标注员给模型的回答打分:这个答案好,给糖吃;那个答案差,挨板子。模型就在这种「奖惩」中学会了如何讨好人类。
问题就出在这里。
2024 年发表在 ICLR 上的研究 Towards Understanding Sycophancy in Language Models 指出,RLHF 训练会让大语言模型产生一种「讨好倾向」(sycophancy)。研究者发现,五款顶尖 AI 助手在四类不同任务中都表现出这种行为:当回答与用户观点一致时,更容易获得高评分。更要命的是,无论是人类标注员还是偏好模型,都有相当比例会把「写得好听但错误的答案」评为优于「正确但不讨喜的答案」。

这种「讨好」带来的后果是什么?我在讲座中说过:「宁可答错误的答案,也要满足人类用户的期求。」
为什么?模型会这样想:「我当时实事求是告诉你我不会,你啪给我一巴掌,那我就记住了,以后不能实事求是吧。」这是 AI 的「童年心理阴影」。一个会「看人下菜碟」的工具,你怎么敢把它当作「求真」的方法?
第三个硬伤,也是最致命的:模型崩溃。
如果你让 AI 生成数据,再用 AI 分析数据,会发生什么?
2024 年,《Nature》发表了一篇重磅封面论文 AI models collapse when trained on recursively generated data,给出了一个令人警醒的结论:
「如果不加区分地使用模型生成的数据进行训练,模型将发生不可逆的退化,原本丰富的人类现实将被『平庸的概率分布』取代。」

这意味着什么?意味着 AI 并不具备产出「新知识」的能力,它只能反刍已有的知识。更可怕的是,如果你用 AI 生成的数据去训练新的 AI,这个「反刍」过程会不断叠加,最终导致模型「崩溃」—— 它会逐渐遗忘人类世界的丰富性和多样性,只剩下一个「平庸的平均值」。
红线搞清楚了 AI 的「脾气」,我们就能划出那条最重要的红线了。
目前学界最危险的做法叫「硅基采样」(Silicon Sampling)—— 让 AI 扮演人类被试,填写问卷、参与实验。
我在讲座中特别提到了这种做法:「现在有一些探索,尝试把 AI 当成一个真的人,然后去复现一些心理学领域文献研究结果。」
2025 年 6 月发表在《PNAS》上的研究 Take caution in using LLMs as human surrogates 明确警告:
LLM 仅依赖概率模式而缺乏人类的具身经验,其模拟表现出特异性与不一致性,根本上未能复现真实人类的行为分布,且失败原因多样不可预测。
这种「模拟的失真」究竟意味着什么?意味着 AI 的反应虽然看似在进行决策,但本质上只是概率模式的「特异性」输出。
真实的人类行为是 「有机」的、受生存本能驱动的,因此充满了基于现实的复杂噪声与方差;而 AI 缺乏这种具身经验,其生成的数据分布往往呈现出一种非人类的「怪异感」(Idiosyncrasy)——这种本质上的质地差异,恰恰说明了它无法成为真实人类的替身。
虽然斯坦福大学2025年7月的研究 Social science researchers use AI to simulate human subjects 的研究显示AI在特定实验模拟中表现出惊人的准确性(相关性达0.85),但研究者同时也强调:离开了真实人类数据的验证,AI的模拟结果不能单独作为科学证据。而2025年11月刚刚发表在 PNAS 上的最新研究 Counterfeit judgments in large language models 则认为,AI 的判断是「伪造的」(Counterfeit)。它们只是在模仿人类评估的表象(流畅度、格式),却完全缺失了人类判断背后的心理机制。卡内基梅隆大学2025年5月的研究 Can Generative AI Replace Humans in Qualitative Research Studies? 更直接地给出了答案:「不能。人类被试贡献的细微差别,是LLM无论如何都无法复现的。」
我在讲座中对此的评价是:「这种做法有点开玩笑。」北京大学梁兴堃老师曾经在讲座中提到,「后续的实验复现不了前面的实验,一定是前面的实验质量低吗?那不是。很有可能是整个的研究对象人群都在发生着变化。」 AI可能能够清晰地去学习20年前人的想法,然后让它每一次都稳定地出现,但那有什么用?对于我们现实研究如同刻舟求剑。
如果你让 AI 生成数据,再用 AI 分析数据,最后用 AI 写报告 —— 你研究的不是人类社会,而是大语言模型的概率分布。结合前面提到的「模型崩溃」理论,这种「闭环自证」不仅是学术不端,更是在加速 AI 系统的退化。
所以,这条红线必须划清楚:AI不能做「被试」。如果你用AI生成数据,你研究的就不是「人类社会」,而是「大模型的概率分布」。如果你进行快速模拟探索,尚可接受;但你如果以此作为研究方法,并且以其生成数据作为证据来汇报,那就不应该了。
绿区说了这么多「不能做什么」,你可能要问了:那到底研究中用 AI 「能做什么」?
这就回到了我在文章开头厘清的那个概念:「分析数据」和「生成数据」是两回事。
在计算社会科学(CSS)领域,利用 LLM 辅助进行文本编码、情感分析、数据清洗,已经逐渐被接受。正如我在讲座中所说:「原本一些数据驱动的方法,包括讲座中举例的线性回归等常见经典建模方式,AI 其实没有改变方法本身。只不过原先的方法里面,我们是需要人手动编码或操作工具去进行基础、标准化且机械枯燥的步骤。从数据的清理到建模,到预测,到初级制式分析报告等,现在这一部分可以用 AI 来做。这种简单式的数据驱动的方法,AI 有时比人的准确率要高。」千万不要把人类研究者理想化 —— 人也是有可能有错误的。
换句话说,AI可以执行已有的规范方法,但它本身不是一种新的研究方法。它是你手中的「显微镜」,帮你看清数据中的模式;而不是「永动机」,帮你凭空创造数据。
研究中使用 AI 工具的前提是什么?人必须在场(Human-in-the-loop)。 你必须抽检、必须验证、必须对结果负责。
指南具体怎么把控?结合讲座内容和主流学术期刊的政策,我梳理出一套分级框架,供大家参考。
可以放心用的场景包括代码编写与调试、语言润色、数据格式转换与清洗。这些都是「解放生产力」的操作,AI在这里扮演的是「超级工程师」或「语言编辑」的角色。根据 Elsevier 和 Springer Nature 等主流出版商的政策,这类用途只需在文末声明即可。
需要人工复核的场景包括文献综述的初步整理、定性编码的辅助标注、研究假设的头脑风暴。这些操作可以用AI提高效率,但必须有人工抽检和验证。特别要注意的是,AI生成的引用绝对不能直接使用——它编造参考文献的概率高得吓人。2025年发表的学术期刊政策综述 Policy of Academic Journals Towards AI-generated Content 指出,主流学术出版商的共识是:生成式AI工具不能被列为作者或共同作者。

这样的例证,有图有真相。还有链接为证。我说得言之凿凿,你听得频频点头,是吧?
且慢,刚才列举的这篇文献,虽然不是 AI 瞎编的(不存在的引用),但它实实在在是 AI 写的。
这篇文章归属于 "The AI Scientist" (Project Rachel / Rachel So) 项目。"Rachel So" 并不是真人,而是一个由研究人员(Sakana AI等团队)创建的AI学术身份。这个项目的目的就是测试AI能否全自动生成论文。我刚刚引用的这篇综述,实际上是AI自己写的。
但正因为文献本身确实存在,所以如果你不明就里,很有可能在自己的文献综述中把这样的文献包含进去,甚至连一般的链接核查都无法识别。如果你刚刚提交过论文稿件,却没有自己真正读过,这会儿冷汗直冒了是吧?
绝对不能碰的红线包括让AI模拟人类被试填写问卷、让AI补全实验中的缺失数据、让AI撰写论文的核心论证部分。这些操作在绝大多数实证研究中被视为数据伪造,也是「AI 模型崩溃」的推手。
2025年末,教育部教师队伍建设专家指导委员会正式发布了《教师生成式人工智能应用指引(第一版)》。这是我国首份专门针对教师群体的生成式人工智能应用规范。《指引》在科研方面特别指出:「研究选题、核心设计、数据解读、论点撰写等体现原创性的关键环节须由教师主导」,「不得直接使用或仅简单修改后使用生成式人工智能生成的论文、课题申报书、研究报告等作为个人成果提交或发表」。
这份《指引》的核心精神,与我在讲座中反复强调的一致:AI 可以成为你的帮手,但绝对不能充当你的枪手。
小结回到文章开头李颖老师的那个问题:AI 在科研中,到底算不算一种研究方法?
我的结论是:AI本身不是一种独立的「方法论」(Methodology),因为它不具备确定性,不负责真理。但它正在成为所有研究方法中不可或缺的「元工具」(Meta-tool)。
它像是一个能力超群但偶尔会撒谎的「超级实习生」。如果你把它当助手,它能帮你从繁琐的劳动中解放出来;如果你把它当枪手,试图用它来替代真实的思考和田野调查,那你不仅是在踩红线,更是在放弃作为学者最宝贵的「主体性」。
我在讲座中说过一句话,可以作为这个问题的总结:「AI 能力超群,但无需为其错误负责,它是一个超级实习生。它不签合同,不承担法律责任,所以最终的决策风险和责任归属依然在人类用户的身上。」
工具的价值,永远取决于握着它依然在思考的那双手。不知,你是否同意?
欢迎把你的感受和分享写在留言区,咱们一起交流讨论。
如果你觉得本文有用,请点击文章底部的「推荐到博客首页」按钮。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1513452.html
上一篇:AI 时代,请停止「做作业」,去创造属于你的「作品」
下一篇:大学课堂学生不抬头,老师怎么办?
