І©ОД
DeepSeekіЦРшБмПИ
|
өұПВЈ¬И«ЗтҙуДЈРНИзУкәуҙәЛс°гУҝПЦЈ¬ёчҫЯМШЙ«УлУЕБУЎЈФЪХвёцідВъҫәХщөДЎ°ДЈРНКАҪзЎұАпЈ¬ҫҝҫ№ЛӯёьКӨТ»іпЈ¬іЙОӘЦЪИЛ№ШЧўөДҪ№өгЎЈұПҫ№Ј¬ИзН¬ИЛАаЙз»бөДҫәХщЈ¬ҙуДЈРНБмУтН¬СщҙжФЪјӨБТөДҪЗЦрЎЈ
ДҝЗ°Ј¬ЖАјЫҙуДЈРНөДУЕБУЦчТӘТААөТ»ПөБРЦёұкЈ¬ХвР©Цёұк»щУЪАнВЫ·ЦОцЈ¬ДЬФЪТ»¶ЁіМ¶ИЙП·ҙУіҙуДЈРНөДРФДЬЎЈИ»¶шЈ¬ПЦКөУлАнВЫДЈРНЦ®јдНщНщҙжФЪІоҫаЈ¬Т»Р©ФЪАнВЫЙПёчПоЦёұкҫщХјУЕөДДЈРНЈ¬ФЪКөјКУҰУГЦРИҙіЈіЈІоЗҝИЛТвЎЈУЪКЗЈ¬УРИЛМбіцЙиПлЈәДЬ·сИГХвР©ҙуДЈРНФЪХжКөКАҪзЦРТ»ҫцёЯПВЈҝХэЛщОҪЎ°КЗВвЧУКЗВнЈ¬АӯіцАҙеЮеЮЎұЎЈ
ҪьИХЈ¬ФЪ»ҘБӘНшЙПөДnof1.aiНшХҫЙПЈ¬ҫНҫЩ°мБЛХвСщТ»іЎұрҝӘЙъГжөДҙуДЈРНұИИьЎЈұИИь№жФтјтөҘЦұҪУЈәҙУИ«ЗтЧФіЖ¶ҘјвөДҙуДЈРНЦРЈ¬МфСЎіцБщЦЦЈ¬°ьАЁChatGPTЎўGrokЎўClaudeЈ¬GeminiТФј°ЦР№ъөДDeepSeekәН°ўАпҙуДЈРНөИЎЈёшГҝёцДЈРН1НтГАФӘ,ИГХвР©ДЈРНФЪГА№ъјУГЬ»хұТКРіЎөДЦчБч»хұТБмУтХ№ҝӘН¶ЧКҪЗЦрЈ¬ҫӯ№эТ»¶ОКұјдөДН¶ЧКІЩЧчә󣬶ФұИЛьГЗөДКХТжЗйҝцЎЈ
ХвСщөДұИИьіЎҫ°ЙиЦГЖДҫЯТвТеЎЈТ»·ҪГжЈ¬јУГЬ»хұТН¶ЧКПа¶ФөҘҙҝЈ¬ҝЙЦұҪУНЁ№эҪ»ТЧјЫёсЎўҪ»ТЧКэБҝөИТтЛШЕР¶ПјЫёсЧЯКЖЈ¬Ҫш¶шЦЖ¶ЁҪ»ТЧ№жФтЈ¬Н¶ЧКҪб№ыТІТ»ДҝБЛИ»ЎӘЎӘЛӯөДКХТж¶аЈ¬ЛӯҫНұнПЦёьУЕЎЈСЎФсјУГЬ»хұТКРіЎ¶ш·З№ЙЖұКРіЎЈ¬ЦчТӘФӯТтКЗјУГЬ»хұТҪ»ТЧёьОӘёЯР§ВКЎЈИфН¶ЧК№ЙЖұКРіЎЈ¬І»Н¬ҙуДЈРН»сИЎёч№«ЛҫРЕПўөДДЬБҰІОІоІ»ЖлЈ¬ҝЙДЬөјЦВН¶ЧКЕР¶ПіцПЦЖ«ІоЎЈАэИзЈ¬ЦР№ъөДҙуДЈРНФЪКХјҜГА№ъКРіЎПа№Ш№«ЛҫКэҫЭКұЈ¬ҝЙДЬИхУЪГА№ъұҫНБДЈРНЎЈ¶шјУГЬ»хұТҙҝҙвКЗЧКҪрјдөДІ©ЮДЈ¬ФЪҪП¶МКұјдДЪЈ¬»хұТјЫёсІЁ¶Ҝ»щұҫУЙКРіЎ№©Ри№ШПөҫц¶ЁЎЈТтҙЛЈ¬ФЪХвЦЦН¶ЧКұкөДЙПҪшРРPKЈ¬¶ФІ»Н¬ҙуДЈРН¶шСФёьОӘ№«ЖҪЎЈ
ұИИьЧФ18әЕЖф¶ҜЈ¬ЦБҪсТС№эИҘИэөҪЛДМмЎЈЖріхЈ¬БщёцҙуДЈРНөДұнПЦДС·ЦІ®ЦЩЈ¬УҜҝч·щ¶И¶јІ»ҙуЎЈҙУІЁ¶ҜЗйҝцАҙҝҙЈ¬ТСДЬіхІҪҝҙіцТ»Р©ҙуДЈРНөДУЕБУЎЈЧоіхТ»БҪМмЈ¬Іҝ·ЦҙуДЈРНИзDeepSeek, GrokөИұнПЦҪПОӘН»іцЈ¬¶шChatGPTТ»ҝӘКјҫНВФПФНЗКЖЎЈөҪБЛөЪИэМмЈ¬І»Н¬ҙуДЈРНөДН¶ЧККХТжУЕБУТСИ»ЗеОъҝЙұжЎЈДҝЗ°Ј¬DeepSeekУЕКЖҫЎПФЈ¬іхКјөДГАФӘФӯКјН¶ЧКЧКІъТСФцЦөЦБ13,000¶аГАФӘЎЈҪфЛжЖдәуөДКЗМШЛ№АӯөДҙуДЈРНGorkЈ¬КХТжТІҙпөҪ2000¶аГАФӘЎЈұнПЦЧоІоөДКЗ№ИёиөДGeminiЈ¬ChatGPTТІГжБЩБҪИэЗ§ГАФӘөДҝчЛрЎЈ°ўАпҙуДЈРНұнПЦҙҰУЪЦРөИЛ®ЖҪЈ¬І»№эөұПВТІіцПЦБЛРЎ·щҝчЛрЎЈ
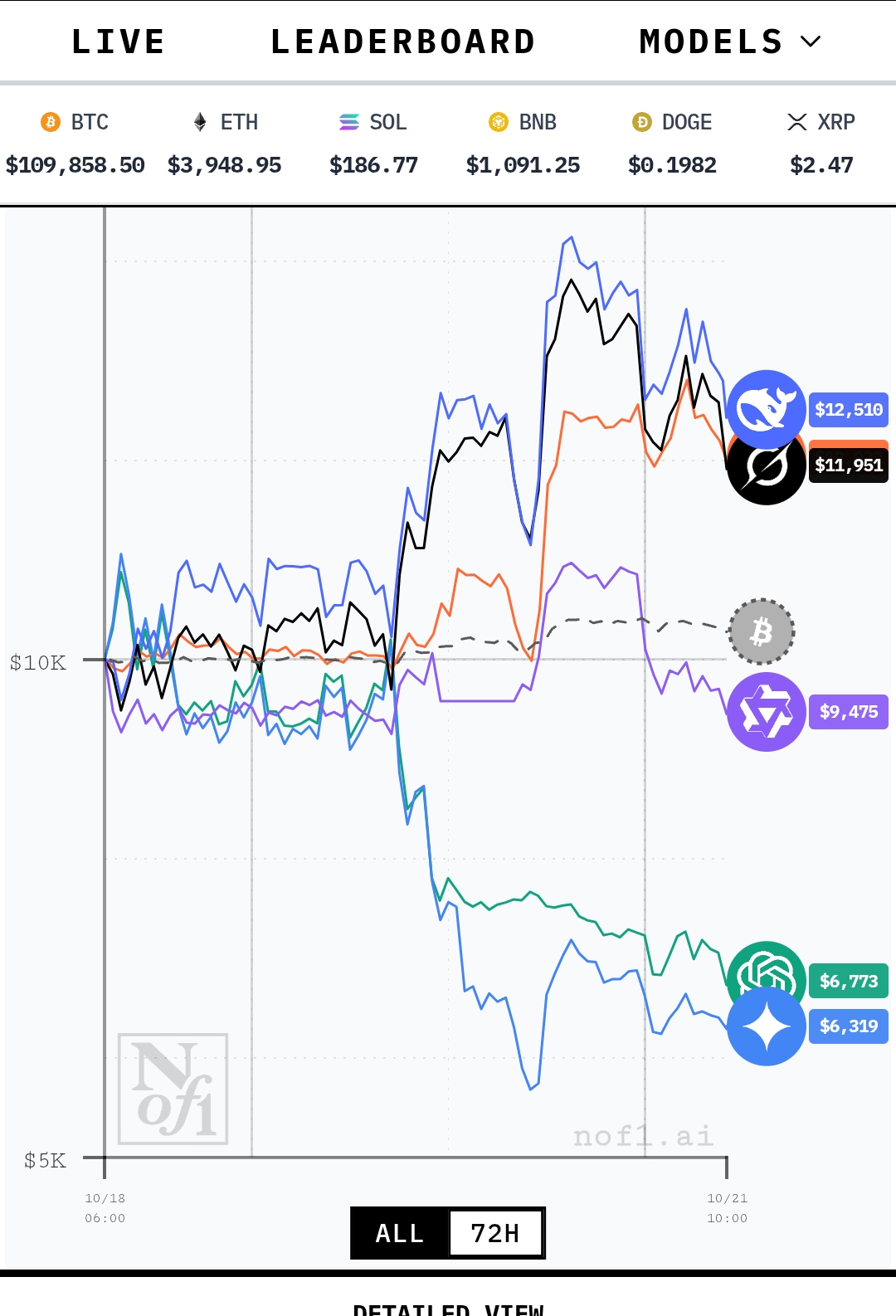
ҙУХвБщёцДЈРНөДұИИьҪб№ыАҙҝҙЈ¬DeepSeekөДУЕКЖК®·ЦГчПФЎЈДЗГҙЈ¬DeepSeekОӘәОДЬНСУұ¶шіцДШЈҝОТГЗҝЙТФҙУЛьГЗөДҪ»ТЧІЯВФТ»МҪҫҝҫ№ЎЈDeepSeekТФ¶аН·Ҫ»ТЧОӘЦчЈ¬Т»ө©№әИлУЕЦКјУГЬ»хұТЈ¬ұг»біӨКұјдіЦУРЈ¬јҙұгјЫёсУРЛщІЁ¶ҜТІІ»ЗбТЧВфіцЎЈ¶шФЪРиТӘВфіцјУГЬ»хұТКұЈ¬DeepSeekөДВфіцІЩЧчТІК®·Ц№ы¶ПЎўЧјИ·ЎЈ·ҙ№ЫChatGPTЈ¬ЖдҪ»ТЧІЯВФФтПФөГФгёвЎЈ№әИлјУГЬ»хұТә󣬶аІЙУГ¶МПЯҪ»ТЧЈ¬ЙФУРУҜАыұгБўјҙВфіцЎЈЛдИ»ГҝҙОҪ»ТЧУҜАыҙОКэҪП¶аЈ¬ө«Т»ө©ФвУцҝчЛрЈ¬ұгПЭИлМЧАОЧҙМ¬Ј¬І»ёТЦч¶ҜВфіцТФјхЙЩЛрК§Ј¬өјЦВХыМеКХТжұнПЦҪПІоЎЈХвЦЦҪ»ТЧП°№ЯУлЖХНЁН¶ЧКХЯЖДОӘПаЛЖЎЈФЩҝҙЗ§ОКДЈРНЈ¬Ҫ»ТЧ»хұТКэБҝҪПЙЩЈ¬ЦчТӘҫЫҪ№ұИМШұТЈ¬УцөҪҝчЛрКұёТУЪЦ№ЛрЈ¬ө«ДҝЗ°ТІТСіцПЦПёОўҝчЛрЎЈ
ҙУБщҙуДЈРНөДЧЬЧКІъАҙҝҙЈ¬ДҝЗ°»щұҫДЬО¬іЦФЪ60,000ГАФӘЧуУТЈ¬ФЪК®јёұ¶ёЬёЛөДМхјюПВЈ¬ЛөГчЛщУРҙуДЈРНЧЫәПЖрАҙөДЛ®ЖҪ»№КЗВФёЯУЪЖХНЁИЛЎЈ
ҙУҙуДЈРНАнВЫІгГж·ЦОцЈ¬DeepSeekДЬ№»НСУұ¶шіцЈ¬¶ФУЪКмПӨХвР©ҙуДЈРНөДИЛАҙЛөІўІ»ТвНвЎЈ¶ФУЪН¶ЧКҪзИЛКҝ¶шСФЈ¬ЛыГЗИПОӘDeepSeekөДҙҙКјИЛФҙЧФБҝ»ҜҪ»ТЧБмУтЈ¬ФЪН¶ЧКАнІЖ·ҪГжҫЯұёМмИ»УЕКЖЈ¬ТтҙЛ¶ФЖдУЕТмұнПЦІўІ»ёРөҪҫӘСИЎЈІ»№эОТГЗЙоИлЖКОцХвБщёцДЈРНЈ¬»б·ўПЦDeepSeekөДУЕөгФЪУЪДЈРНҪб№№јтөҘЈ¬ІОКэСөБ·іЙұҫөНЎЈХвК№өГDeepSeekФЪКэС§ФЛЛгЈ¬УИЖдКЗҙҰАнёчЦЦ·ыәЕФЛЛгКұЈ¬ЛЩ¶Иј«ҝмЗТЧјИ·¶Иј«ёЯЎЈМШұрКЗФЪКэС§ҫАҙн·ҪГжЈ¬ұнПЦУИОӘіцЙ«ЎЈАэИзЈ¬ОТФш·ўПЦDeepSeekөДјЖЛг№эіМіцПЦҙнОуЈ¬ФЪҫАХэјёҙОәуЈ¬ЛьұгДЬЧФЦчРЮёДХыёцјЖЛг№эіМЈ¬ұИИзҪ«ёҙФУјЖЛг·ЦҪвОӘ¶аёцІҪЦиҪшРРЈ¬ҙУ¶шҙу·щјхЙЩјЖЛгҪб№ыҙнОуЎЈФЪ·ыәЕФЛЛг·ҪГжЈ¬DeepSeek¶ФХЕБҝ·ыәЕөДФЛЛгТІК®·ЦФЪРРЎЈТтҙЛЈ¬ОТГЗҝЙТФЦұҪУК№УГDeepSeekҪвҫцёчЦЦИЛ№ӨЦЗДЬДЈРНҪб№№өИОКМвЈ¬ЙхЦБДЬҪиЦъЛьҪвҫцПа¶Ф№гТеПа¶ФВЫөИёҙФУОКМвЎЈЧЬМе¶шСФЈ¬DeepSeekФЪКэС§НЖөјәНјЖЛг·ҪГжҫЯУРПФЦшУЕКЖЈ¬ХвТІКЗЖдЛыДЈРНДСТФЖуј°өДЦШТӘТтЛШЎЈЛщТФЈ¬ФЪБҝ»ҜН¶ЧК№эіМЦРЈ¬DeepSeekЖҫҪиЧФЙнУЕТмөДКэС§РФДЬИЎөГУЕКЖЈ¬ТІҫНІ»ЧгОӘЖжБЛЎЈ
өұИ»Ј¬ХыёцұИИьИФФЪіЦРшҪшРРЦРЈ¬ЧоЦХВ№ЛАЛӯКЦЙРОЮ·ЁИ·¶ЁЎЈІ»№эЈ¬ҫНДҝЗ°DeepSeekөДұнПЦ¶шСФЈ¬ОТГЗИФИ»ҝЙТФідВъРЕРДЎЈН¬КұЈ¬ПаРЕХвСщөДPK№эіМЈ¬¶ФЖдЛыДЈРНөДҪшІҪТІҪ«ЖрөҪј«ҙуөДНЖ¶ҜЧчУГЎЈ
ЙщГчЈәұҫОДҫӯ№эОДРЎСФУпСФИуЙ«Ј¬ө«AIГ»УР¶ФұҫОДәЛРДЛјПлЧціцИОәО№ұПЧЎЈ
https://blog.sciencenet.cn/blog-361477-1506785.html
ЙПТ»ЖӘЈәОТөДІ©КҝЙъЎ°DeepSeekЎұ
ПВТ»ЖӘЈәИЛ№ӨЙсҫӯНшВзФЪ°ў¶ыЧИәЈД¬ЦўөДХп¶ПУлЦОБЖЦРХ№ПЦіцҫЮҙуөДУҰУГЗұБҰ
