博文
联邦学习赋能稀缺异构数据场景下的合成数据生成优化
||
医疗健康领域的研究长期受困于数据稀缺与分布不均,尤其在资源匮乏地区,这一问题尤为突出;同时,隐私保护法规限制了跨机构原始数据共享,传统匿名化、加密传输方案也仍存在隐私泄露风险。合成数据生成 (SDG) 技术虽为隐私安全的数据利用提供了新路径,但其效果高度依赖原始数据的规模与质量,在数据稀缺、非独立同分布 (非IID) 的异构场景下表现严重受限。来自马德里理工大学信息处理与电信中心的Patricia A. Apellaniz博士及其团队在Big Data and Cognitive Computing (BDCC) 期刊发表的最新研究中,提出基于合成数据共享 (SDS) 的联邦学习 (FL) 方法,有效破解了医疗场景下稀缺异构数据的合成数据生成难题,对推动公平、隐私安全的医疗科研创新具有重要意义。
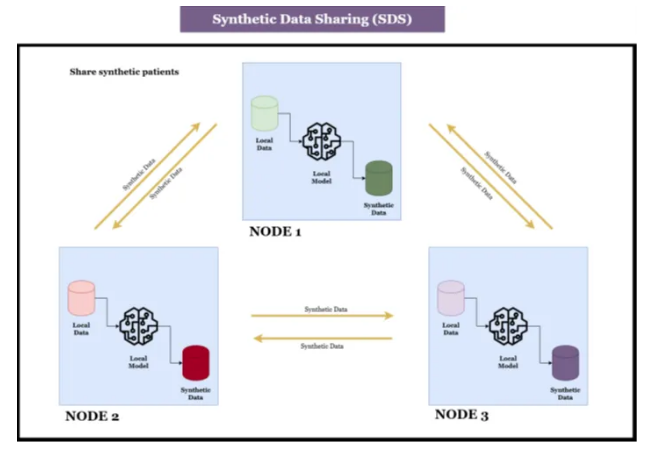
联邦学习中的SDS方法流程示意图
研究过程与结果
作者针对传统联邦学习算法在非IID数据场景下的性能短板,以及现有联邦合成数据生成方案的不足,提出了基于合成数据共享的SDS联邦学习方法。该方法深度融合元学习中域随机搜索 (DRS) 的核心思想,摒弃了传统FedAvg算法的模型参数加权聚合模式,转而通过各节点本地生成合成患者数据并跨节点共享的方式实现联邦知识聚合。方法以表格数据生成领域表现优异的VAE-BGM模型为基础生成器,核心流程分为三步:各节点先基于本地私有数据训练本地VAE-BGM模型,生成初始合成数据;随后各节点将本地合成数据在联邦网络内共享,形成多分布的增强数据集;最终各节点采用本地真实数据与其他节点共享的合成数据组成的混合数据集,完成模型优化训练。
为验证SDS方法的实用性,作者构建了包含3个节点的联邦学习环境,分别模拟仅100个样本的资源匮乏机构、1000个样本的中等资源机构、10000个样本的资源充足机构,基于糖尿病健康指标、心脏病指标两个权威医疗数据集,在IID与非IID两种数据分布场景下,将SDS方法与经典FedAvg算法、孤立训练模式进行系统性对比。实验采用JS散度验证合成数据与真实数据的统计相似度,采用下游分类任务准确率验证合成数据的临床实用性。
实验结果表明,无论是IID还是非IID场景,SDS方法均持续优于孤立训练与FedAvg算法。在极具现实挑战的非IID异构场景中,传统FedAvg算法仅能将数据分布散度降低13%-27%,而SDS方法在表现最差的节点实现了超过50%的散度降幅;在平均倒数排名 (MRR) 指标上,非IID场景下SDS方法在两个数据集中均达到1.000的满分表现,展现出绝对的性能优势。同时,作者通过最小成对距离分析验证,SDS方法生成的合成数据无真实样本的直接复刻,从根本上规避了原始数据泄露风险,具备完善的隐私保护能力。
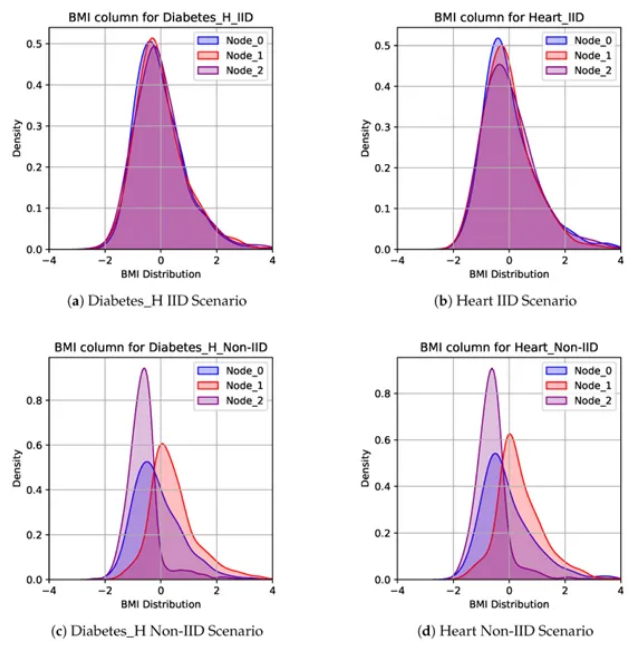
IID与非IID场景下糖尿病、心脏病数据集各节点BMI分布的核密度估计图
研究总结
本文系统完成了稀缺异构数据场景下联邦合成数据生成方法的构建与全维度验证,详细剖析了传统FedAvg算法在医疗非IID数据场景下的性能局限,明确了合成数据共享模式在联邦学习中的核心价值。通过统计相似度与临床效用的双维度验证,证实SDS方法生成的合成数据,既能精准拟合真实数据的分布特征,也能满足下游医疗科研任务的实用性要求。
研究详细分析了方法的不确定度来源,包括数据分布异质性、样本量差异带来的模型训练偏差等,同时通过多组对照实验完成了方法的鲁棒性验证。该方法有效打破了医疗数据地域与资源壁垒,大幅缩小了数据富裕与匮乏机构间的科研能力差距,为医疗资源薄弱地区的科研创新提供了可行的技术路径,同时也为金融、能源等其他隐私敏感、数据分布不均领域的合成数据生成与跨机构协作提供了重要参考范式。
阅读英文原文:https://www.mdpi.com/2504-2289/9/1/18
BDCC 期刊介绍
主编:Min Chen, South China University of Technology, China
期刊主要发表与大数据、云计算、认知计算、人工智能通信、数据分析、移动大数据、认知学习、机器学习等相关主题的原创研究论文。期刊旨在将大数据理论与智能云新兴技术结合起来,并探索超级计算机的新应用。
2024 Impact Factor:4.4
2024 CiteScore:9.8
Time to First Decision:23.1 Days
Acceptance to Publication:4.6 Days
期刊主页: https://www.mdpi.com/journal/bdcc

https://blog.sciencenet.cn/blog-3516770-1532543.html
上一篇:Veterinary Sciences 探索犬类过敏治疗新境界:特异性免疫疗法对犬生活质量的显著提升