博文
基于隐式解码对齐的空地行人重识别方法
|
引用本文
贝俊仁, 张权, 赖剑煌. 基于隐式解码对齐的空地行人重识别方法. 自动化学报, 2025, 51(9): 1988−2000 doi: 10.16383/j.aas.c240705
Bei Jun-Ren, Zhang Quan, Lai Jian-Huang. Implicit decoder alignment for aerial-ground person re-identification. Acta Automatica Sinica, 2025, 51(9): 1988−2000 doi: 10.16383/j.aas.c240705
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c240705
关键词
行人重识别,图像检索,图像识别,自注意力网络
摘要
空地行人重识别任务旨在包含地面与空中视角的监控相机网络中, 实现对特定行人的精确识别与跨镜关联. 该任务的特有挑战在于克服空地成像设备之间巨大的视角差异对于学习判别性行人身份特征的干扰. 现有工作在行人特征建模方面存在不足, 未充分考虑跨视角特征对齐对识别与检索性能的提升作用. 基于此, 提出一种基于隐式解码对齐的空地行人重识别方法, 主要包含两方面的创新: 在模型设计方面, 提出基于自注意力解码器的隐式对齐框架, 通过在解码阶段利用一组可学习的口令特征挖掘行人判别部件区域, 并提取和对齐行人局部特征, 从而实现判别性行人表征的学习; 在优化目标方面, 提出正交性和一致性损失函数, 前者约束口令特征以多样化判别性行人部件为关注点, 后者缓解了跨视角特征表达的偏置分布. 在当前可用的最大空地重识别数据集CARGO上进行实验, 结果表明所提方法在检索性能上优于现有重识别方法, 实现显著的性能提升.
文章导读
行人重识别(Person re-identification, ReID)任务旨在非重叠视域的多摄像头监控网络中实现对特定对象的准确识别和跨摄像头跟踪[1−7]. 随着“智慧城市”和“雪亮工程”等项目的实施, 在深度学习和计算机视觉的支持下, 该技术已在城市安防、边境监控、园区管理等领域中发挥关键作用. 尽管现有研究在纯地面视角[8−12]和纯无人机视角[13−17]的监控网络中取得显著进展, 但这些研究往往假设监控系统由相同类型的摄像头组成, 成像风格较为一致, 因此可以将问题简化为同构相机网络下的图像检索任务. 然而, 这一简化与现实中的监控网络存在显著差距, 实际部署的监控系统通常包含不同类型和视角的摄像头.
为解决上述不足, 本文关注一种更贴近实际应用且更具挑战性的空地行人重识别任务(Aerial-ground person re-identification, AGPReID), 即在监控网络中同时融合地面摄像头和无人机摄像头的视角. 该任务不仅拓宽行人重识别的研究范围, 也更加符合实际监控的需求. 如图1所示, 地面摄像头覆盖人流密集的城市区域, 而无人机摄像头则覆盖市郊、农田、森林等人流稀疏的区域. 这种组合不仅提升了传统行人重识别研究的适用性, 还显著扩展了其在实际部署场景中的应用潜力. 空地行人重识别任务作为现有研究的重要补充和扩展, 提供新的研究视角, 助力实现更全面的监控覆盖和更高效的目标识别检索. 与传统行人重识别相比, 该任务的独特挑战在于跨镜头视角差异显著, 这对判别性身份表征的学习带来较大干扰. 然而, 空地行人重识别研究仍处于起步阶段, 现有方法未能有效解决这一挑战. 此外, 直接迁移传统行人重识别方法[18−20]至该场景会导致明显的性能下降, 因为空地视角差异引起的行人形变使得传统的对齐方法难以生效. 这一现状促使设计新的对齐方法, 以缓解空地视角间的巨大差异.
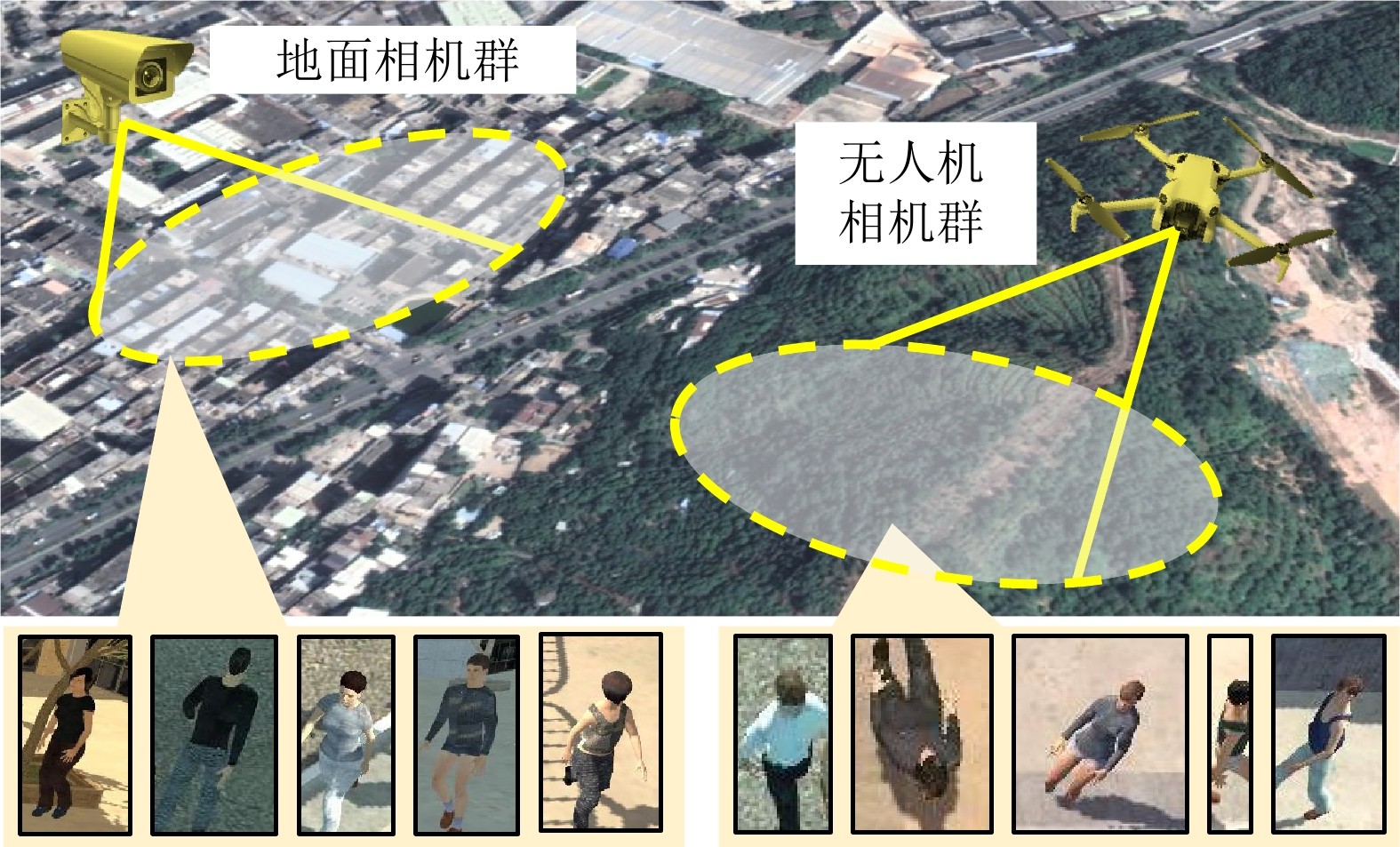
图1 空地行人重识别任务示意图
针对上述问题, 本文提出一种基于隐式特征对齐的空地行人重识别方法, 主要在模型设计和优化目标上进行创新: 1)在模型设计上, 提出基于解码对齐的纯自注意力框架IDA (Implicit decoder alignment framework), 该框架包含自注意力编码器和解码器模块, 编码器负责提取输入图像的特征, 解码器通过设计一组可学习的部件对齐口令特征, 对编码器特征进行查询、挖掘和对齐, 从而识别出关键行人部件区域, 实现判别性行人表征的学习; 2)在优化目标上, 设计正交性损失和一致性损失, 用于监督口令特征的学习, 其中正交性损失约束口令特征关注不同且具有判别性的行人部件区域, 一致性损失调整视角间的特征相似度分布与视角内的特征相似度分布一致, 从而缓解跨视角特征的有偏分布.
最后, 在当前最大规模的空地行人重识别数据集CARGO上进行实验验证. 结果表明, 所提出的IDA方法在多种空地检索模式下均表现优异, 尤其是在跨空地重识别设定中, mINP实现5.04%的提升, 显著超越当前最佳方法.
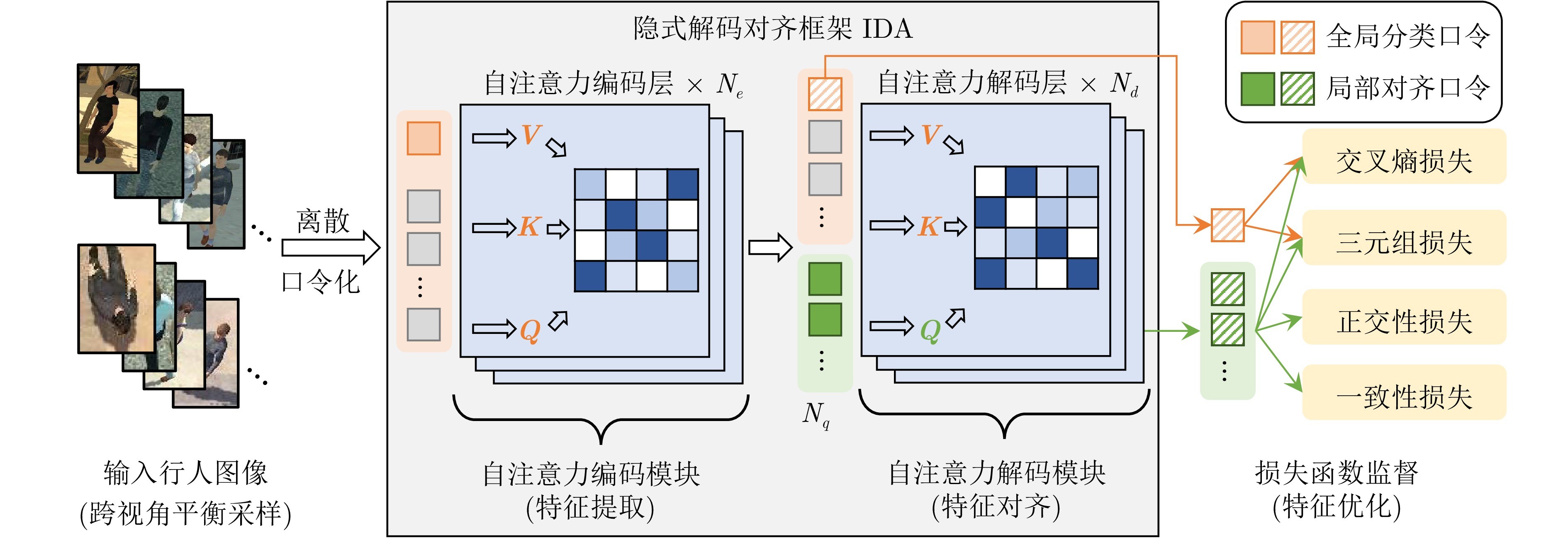
图2 隐式解码对齐框架示意图
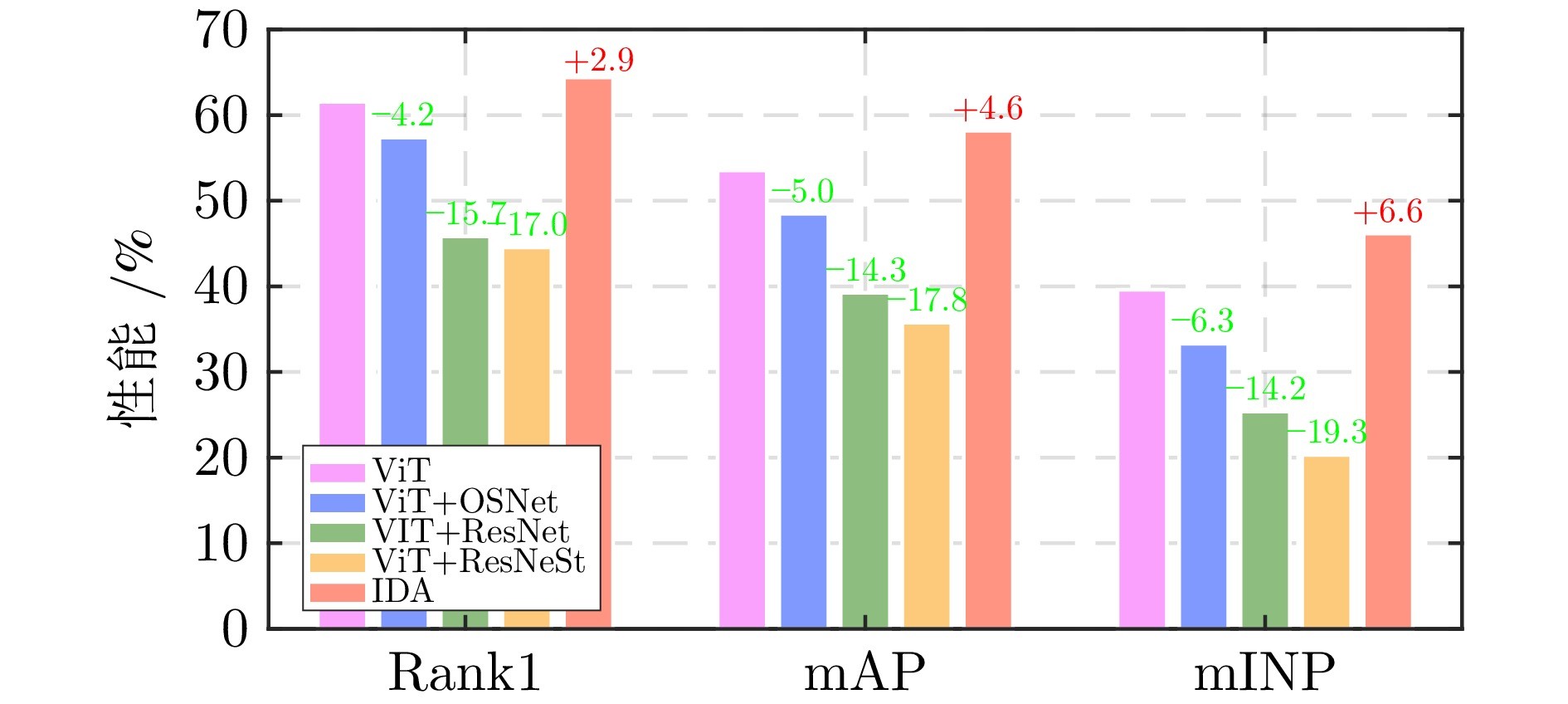
图3 模型性能增益分析, 其中结果来自CARGO数据集的协议1
在本文中, 关注跨空地行人重识别这一任务, 并提出基于隐式解码特征对齐的特征提取框架以缓解该场景下显著的视角差异挑战. 具体来说, 首先设计基于解码对齐的自注意力模型, 通过在自注意力编码器的基础上引入解码模块和一系列的可学习口令特征自主挖掘和提取判别性行人局部特征, 实现具有判别性的行人表征学习. 其次, 设计正交损失函数和一致性损失函数来进一步指导特征的学习与分布. 最后, 在CARGO数据集上评估方法, 结果表明IDA框架实现了当前最优的模型性能, 所提出的隐式对齐策略显著超越已有的重识别方法.
此外, 也必须指出, 尽管本文提出的方法能够显著提升在具有大视角差异场景中的表现, 但在空地视角差异不显著的场景(例如AG-ReID数据集)中, 性能提升存在一定限制. 在这些场景中, 方法的潜力未能完全发挥. 针对这一局限性, 计划在未来的工作中进一步研究并扩展方法的应用场景与泛化能力, 以更好地应对更广泛的任务需求.
作者简介
贝俊仁
中山大学计算机学院硕士研究生. 主要研究方向为行人重识别与计算机视觉. E-mail: beijr@mail2.sysu.edu.cn
张权
中山大学系统科学与工程学院博士后. 主要研究方向为行人重识别与计算机视觉. 本文通信作者. E-mail: zhangq689@mail.sysu.edu.cn
赖剑煌
中山大学计算机学院教授. 主要研究方向为计算机视觉与模式识别. E-mail: stsljh@mail.sysu.edu.cn
https://blog.sciencenet.cn/blog-3291369-1506321.html
上一篇:城市固废焚烧过程神经网络控制研究综述
下一篇:有向图同构判定方法
