博文
ChatGPT“智能”测试:ChatGPT 对逻辑谬误拉丁文名称的“解释”
||
[敬请读者注意] 本人保留本文的全部著作权利。如果哪位读者使用本文所描述内容,请务必如实引用并明白注明本文出处。如果本人发现任何人擅自使用本文任何部分内容而不明白注明出处,恕本人在网上广泛公布侵权者姓名。敬请各位读者注意,谢谢!
ChatGPT“智能”测试:ChatGPT 对逻辑谬误拉丁文名称的“解释”
程京德
笔者对 ChatGPT 之功能进行第四次测试的报告,仅供参考。
在逻辑学中,有些古典的逻辑谬误一般都有一个拉丁文名称,一个偶然的机会让笔者发现似乎 ChatGPT 在翻译逻辑谬误拉丁文名称时居然还给出它“创造”的解释,于是便有了下面的测试实验。
测试数据:笔者手边几本逻辑学名著中的古典逻辑谬误拉丁文名称(总计13个)。
测试方法:针对每个拉丁文名称,让 ChatGPT 翻译并解释,并且也用Google翻译和百度翻译查询中文意思,每个拉丁文名称仅测试一次。
从逻辑学的角度(亦即,不仅仅从语言字面角度)来评价,测试结果如下(OO表示很好,回答基本上完全正确,即便有多余的陈述但仅仅是冗余并没错;O表示合格,回答即便不够准确完整,但是没有错误;X表示不合格,回答中有错误,尽管可能也有对的成分;XX表示很差,回答错的离谱,毫无正确性可言):
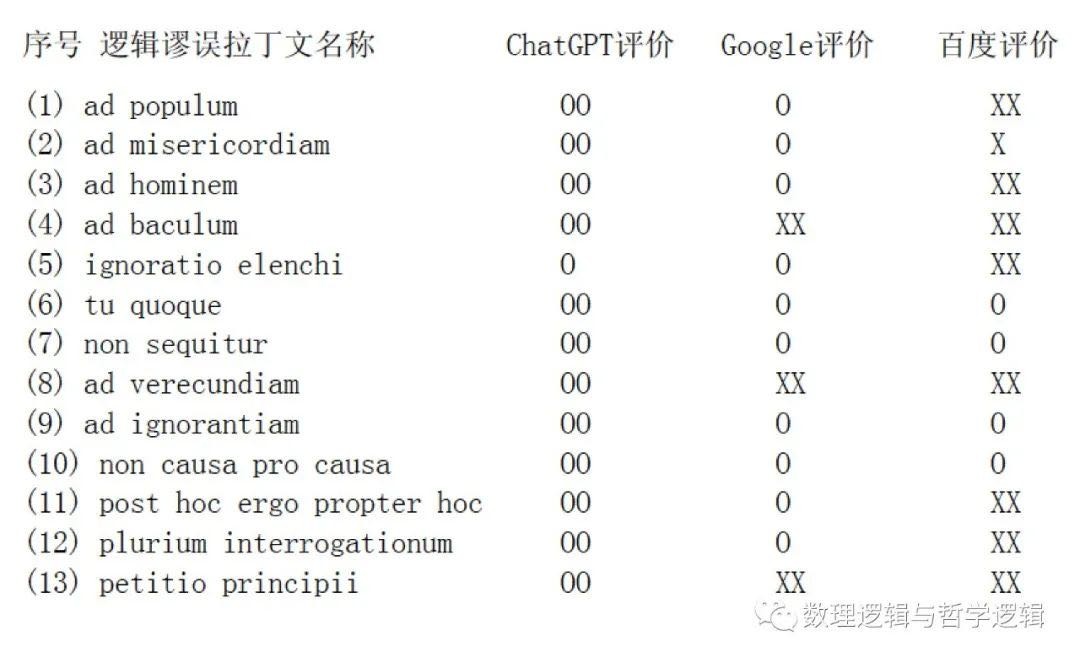
从上面的测试结果可以看出,ChatGPT 的表现极其优秀,几乎对每一个逻辑谬误拉丁文名称的翻译解释都堪称完美,并且,针对每种逻辑谬误,它还几乎都举出一个相当恰当的例子来说明。仅从本次测试结果来看,似乎 ChatGPT 的表现足以被用作为一个逻辑学教学辅助工具。
这个测试实验的有趣之处在于对比。相对于 ChatGPT 在逻辑学知识(加上拉丁文语言知识?)上的优秀表现,百度翻译的表现可以说是相当糟糕,对不少拉丁文词汇的翻译似乎也很不靠谱。而Google翻译的表现大约介于前两者之间。因为Google翻译和百度翻译都仅仅是给出一个对应中文词汇(或词汇组合),再没有其它和逻辑学直接相关的内容,所以笔者没给它们打一个“OO”分数。
对于上面的测试结果及其对比怎么看,大概是个见仁见智的问题。但是,无论如何,ChatGPT 的表现极其优秀应该是毋庸置疑的事实。问题在于:它的这种优秀表现是怎么来的?为什么它会在这个测试实验中表现的如此完美?为什么它会在这个测试实验中完全没有信口开河地胡编乱造?(不了解 ChatGPT 的“创造”会怎样信口开河地胡编乱造的读者请参阅笔者上一篇测试报告)
微信公众号“数理逻辑与哲学逻辑”

https://blog.sciencenet.cn/blog-2371919-1377477.html
上一篇:ChatGPT“智能”测试:请您问问 ChatGPT 您自己的成就
下一篇:ACM 图灵奖历届获奖者 -- 1966-1970
