博文
基于异常序列剔除的多变量时间序列结构化预测
|
引用本文
毛文涛, 蒋梦雪, 李源, 张仕光. 基于异常序列剔除的多变量时间序列结构化预测. 自动化学报, 2018, 44(4): 619-634. doi: 10.16383/j.aas.2017.c160707
MAO Wen-Tao, JIANG Meng-Xue, LI Yuan, ZHANG Shi-Guang. Structural Prediction of Multivariate Time Series Through Outlier Elimination. ACTA AUTOMATICA SINICA, 2018, 44(4): 619-634. doi: 10.16383/j.aas.2017.c160707
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.2017.c160707
关键词
时间序列聚类,主曲线,异常序列,多维支持向量回归机
摘要
针对传统多变量时间序列预测方法未考虑变量间依赖关系从而影响预测效果的问题,提出了一种基于异常序列剔除的多变量时间序列预测算法.该算法旨在利用多维支持向量回归机(Multi-dimensional support vector regression,M-SVR)内在的结构化输出特性,对选取到具有相似性的多个变量序列进行联合预测.首先,对已知序列进行基于模糊熵的层次聚类,实现对相似序列的初步划分;其次,求出类中所有序列的主曲线,根据序列到主曲线的距离计算各个序列的异常因子,从而进一步剔除聚类结果中的异常序列;最后,将选取到的相似变量序列作为输入,利用M-SVR进行预测.通过理论分析,证明本文算法在理论上存在信息损失上界与可靠度下界,从而说明本文算法的合理性与可行性.采用混沌时间序列数据与多个实际数据集进行对比实验,结果表明,与现有多个代表性方法相比,本文算法可有效挖掘多变量时间序列的内在结构信息,预测精度更高,数值稳定性更好.
文章导读
在实际应用中, 时间序列数据的变化往往受多种因素影响.传统的时间序列预测算法主要针对影响事物变化的某一种因素进行单个时间变量的预测.而若对事物变化趋势进行更加综合、准确的评估, 则需对多个相关因素进行同时预测, 即多变量时间序列预测.相比于单变量时间序列预测, 多变量时间序列预测可同时预测多个变量的走势, 同时可利用变量之间的相关信息提高动态预测的精度与稳定性, 已得到越来越多学者的关注.但是, 传统预测方法直接应用于多变量时间序列预测中, 容易受变量之间冗余作用、误差累积和缺乏关联信息等特点的影响, 无法取得令人满意的预测效果.因此, 选择一个合适的建模方法对多变量进行更为准确地预测有着重要的理论价值和现实意义.
目前, 多变量时间序列预测研究已取得一定的进展.传统的预测方法将多变量分解为多个单变量, 利用支持向量回归机(Support vector machine, SVM)等方法[1]对每个变量单独进行回归建模.这种方法简单明了, 但是重复建模增加了计算量, 同时未能有效利用变量之间的结构信息.一种典型的改进方法是利用时间序列本身的系统特性信息和数据特点进行预测.其中, 张勇等[2]利用最大Lyapunov指数理论, 选取多个邻近参考点, 实现了对多个混沌序列的同时预测; 针对股指期货价格预测问题, Sun等[3]利用模糊C均值对数据进行预处理, 并结合粗糙集算法建立模糊逻辑关系组, 实现对多个变量走势的预测; 韩敏等[4]利用主成分分析方法实现对输入变量降维, 再将动态储备迟用作核函数充分映射多元混沌时间序列的动力学特性实现了避免过拟合, 提高预测精度.另一种做法是围绕着多变量输出结构的算法改进.例如, Wang等[5]提出基于极限学习机的在线多变量时间序列预测方法, 对多变量序列进行相空间重构后, 建立极限学习机预测模型, 实现在线预测; Han等[6]提出基于SCKF-γESN模型的在线多变量时间序列预测方法, 利用平方根容积卡尔曼滤波算法更新γ回声网络参数, 以实现对多变量序列的在线预测, 同时在滤波算法中加入异常值的检测, 使得预测结果更加稳定; Chen等[7]利用K近邻和互信息获取多变量时序数据的重要性表示, 并据此重构样本, 利用改进的加权LS-SVM进行预测.但是, 这些方法大多通过多变量数据的简单融合构建预测模型, 缺乏在算法结构上针对多变量序列特点的有效改进.
由上述分析可知, 对多变量时间序列预测来说, 预测效果的好坏直接取决于数据中蕴含的有效信息量.而实际应用多为小样本预测问题, 若能有效利用变量之间的结构化信息, 则可一定程度弥补样本数不足带来的信息缺失, 有利于提高小样本下预测模型的稳定性和精度.因此, 提升多变量时间序列预测效果的关键在于: 1)如何有效挖掘序列之间的依赖关系等结构化信息? 2)如何构建适用于多变量序列预测的预测模型?针对这两点, 本文提出一种基于异常序列剔除的多变量时间序列预测方法.该方法首先给出基于模糊熵的时间序列聚类算法, 实现对相似序列的初步划分, 并引入主曲线, 构建异常时间序列检测算法, 对其中的异常序列进行剔除, 最后采用多维度支持向量回归机(Multi-dimensional support vector regression, M-SVR)[8]对最终得到的相似序列进行多输出时间序列预测. M-SVR是一种具有多输出结构的支持向量机, 不仅对小样本有快速和准确的回归预测效果, 而且, 利用超球损失函数度量多个输出端的的风险损失, 可有效利用输出端之间的结构化信息, 目前已在多步超前时间序列预测[9]等问题取得成功应用.但根据作者文献调研, 尚未发现M-SVR在多变量时间序列预测中的应用.鉴于此, 本文采用M-SVR作为基础建模算法, 旨在利用M-SVR的结构化输出特性, 选择具有相关性的序列同时进行预测, 以达到更好的预测效果.此外, 本文从理论上给出了异常序列剔除的信息损失上界和模型可靠度下界, 从而证明所提算法的合理性.最后采用混沌时间序列数据与五个实际数据集数据进行仿真实验, 实验结果验证了所提算法的有效性.

图 1 算法流程图
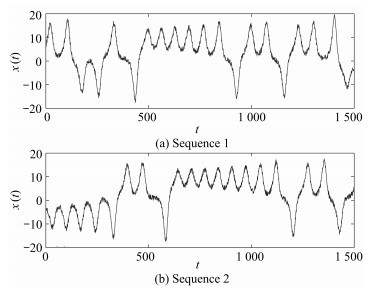
图 2 Lorenz序列数据
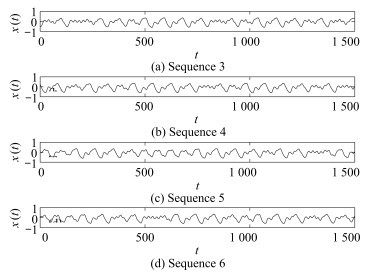
图 3 Mackey-Glass序列数据
基于结构化输出的多变量时间序列预测可通过挖掘变量间蕴含的领域信息同时提高多个变量序列的预测效果.其中的关键问题在于如何提取变量间的依赖关系.本文提出了一种基于异常序列剔除的多变量时间序列预测方法.该方法利用基于模糊熵的层次聚类对时间序列进行初步划分, 提出了基于主曲线的异常序列检测算法, 进一步检测并剔除异常序列, 最终引入多输出SVR进行建模和预测, 同时在理论上证明了该算法的可行性与合理性, 最终利用混沌时间序列数据与实际数据集数据验证了算法的有效性.下一步的工作将集中在算法的泛化性理论分析和不同类型的变量间结构特性的建模.
作者简介
蒋梦雪
河南师范大学计算机与信息工程学院硕士研究生.主要研究方向为机器学习, 时间序列预测.E-mail:jmxhtu@126.com
李源
河南师范大学计算与信息工程学院副教授.主要研究方向为故障诊断, 可靠性预测.E-mail:liyuan2015097@163.com
张仕光
河南师范大学计算与信息工程学院副教授.主要研究方向为机器学习, 大数据处理.E-mail:121114@htu.edu.cn
毛文涛
河南师范大学计算与信息工程学院副教授.主要研究方向为机器学习, 时间序列预测.本文通信作者.E-mail:maowt@htu.edu.cn
https://blog.sciencenet.cn/blog-3291369-1421396.html
上一篇:图像纹理分类方法研究进展和展望
下一篇:基于一般二阶混合矩的高斯分布估计算法