博文
告别高熵与算力浪费:Mogan STEM 如何重塑 AI 时代的数学排版
||
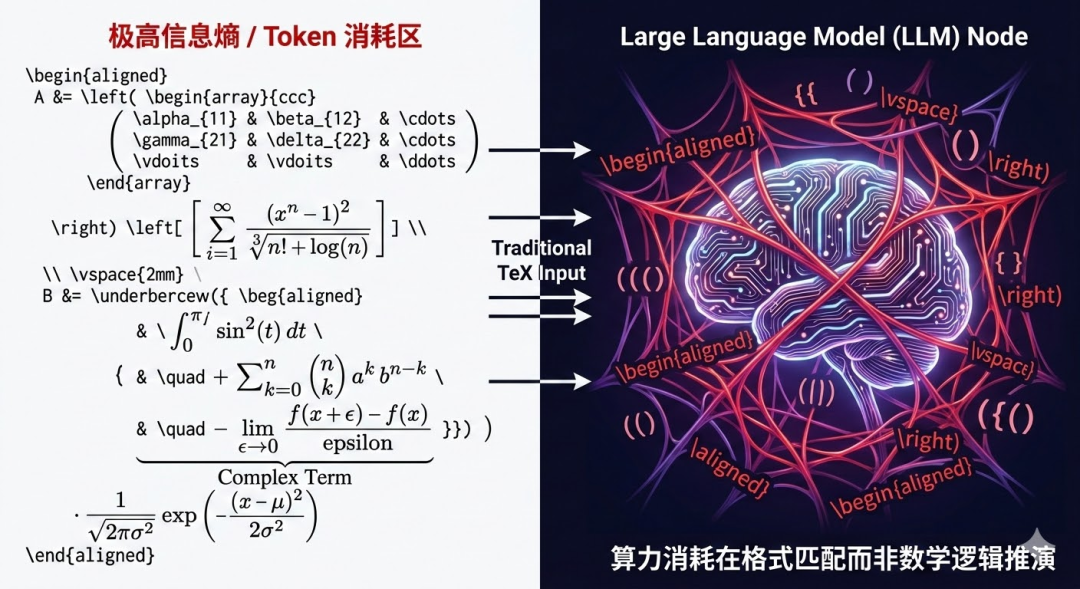
就在全网都在死磕怎么让大模型用传统 TeX 写出更长、更复杂的数学推导时......
近期,三鲤团队在 arXiv 上低调发布了一项探讨排版底层架构的研究(2603.02873)。该论文客观审视了传统排版系统在与机器交互时所面临的底层局限,并顺应大语言模型(LLM)时代的发展需求,提出了一种更为轻量、结构化的数学排版新范式:Mogan STEM 及其专属的 .tmu 格式。
这直击了当前 AI 数学推理的痛点:Token 成本与高信息熵。在以往的理解中,排版系统的尽头就是 LaTeX。但这篇文章尖锐地指出,TeX 源代码对于机器而言,意味着极高的"信息熵"。其主要面对的问题如下:
一、Token 成本:昂贵的"排版流水账"在大语言模型(如 GPT-4、DeepSeek 等)的世界里,它们不认识"字"或"公式",它们只认 Token。Token 是模型处理信息的最小计费单元和计算单元。
传统 TeX 语法的致命缺陷在于:它极其啰嗦,表达效率极低。
当你需要推导代数几何中凝聚层张量积的全局截面时,从纯数学逻辑出发,核心信息只有三个实体:截面函子 Γ、层 𝓕 和层 𝓖。但在 LaTeX 中,为了让它在 PDF 里看起来漂亮,你需要写成这样:
Γ(X, 𝓕 ⊗𝓞X 𝓖)
其背后的源码是:
\Gamma(X, \mathscr{F} \otimes_{\mathcal{O}_X} \mathscr{G})
对于大模型而言,这段代码会被切分成十几个甚至几十个 Token(包括反斜杠、花括号、下划线等)。如果推演一个包含多重上同调群的长正合序列,或者画一个稍微复杂一点的交换图(比如使用 tikz-cd 宏包),短短几步数学逻辑,就会膨胀成数千个 Token 的"排版流水账"。
这带来的直接后果是:
挤占上下文窗口:模型的记忆长度是有限的(比如 128K)。如果一半的容量都被 {, }, \begin{aligned} 这种毫无数学价值的排版符号占满,模型就无法进行超长篇幅的复杂定理证明。
生成极度缓慢且昂贵:模型的计算是自回归的(逐字生成)。为了吐出那些控制排版的字符,GPU 需要执行海量的矩阵乘法,这不仅拖慢了整体推演的输出速度(TPOT 飙升),也让算力成本呈指数级上升。
如果说 Token 成本是"量"的问题,那么高信息熵就是"质"的问题。
在信息论中,"熵"代表着系统的不确定性和混乱程度。一段文本的"信息熵"越高,意味着下一个字符越难被预测,噪音越大。
对于 LLM 来说,TeX 源码就是一个极高熵值的噩梦。
1. 信号与噪音的严重失衡在数学推演中,真正的"信号"是代数变形、同构映射、函子作用等逻辑步骤;而 TeX 源码中充斥的 \vspace{2mm}, &, \\ 以及嵌套极深的花括号,全都是"噪音"。
当模型在预测下一个 Token 时,它必须在"下一步的数学逻辑是什么"与"这里是不是该闭合一个花括号"之间反复横跳。大量的注意力(Attention)权重被消耗在了维持排版语法的合法性上,导致其数学推理的专注力被严重稀释。
2. 极度脆弱的语法结构(容错率极低)TeX 是一门基于宏展开的语言,其语法是极其刚性且脆弱的。
在嵌套了三四层的公式中,仅仅漏掉了一个右花括号 },或者在环境拼写中敲错了一个字母(比如把 \end{pmatrix} 写成了 \end{pamtrix}),整个编译引擎就会彻底崩溃,输出一堆 Fatal Error。
为了避免这种崩溃,模型必须在内部构建极其复杂的隐式逻辑来"数括号"、对齐环境。这使得预测过程的熵值居高不下,极大地增加了模型发生"幻觉(Hallucination)"和逻辑断裂的概率。
这篇论文的核心在于解决大模型在科学文本与数学排版场景下的语义解析瓶颈。打个比方:以前让大模型推导公式,就像让它一边解题,一边还要分心去背诵如何控制印刷机的指令代码。稍微漏掉一个用来排版的括号,整个过程就会全盘死机。
现在这篇论文提出的新技术,直接剥离了所有用来控制格式的"废话"。它把复杂的数学公式变成了一套直观的"逻辑拼图",让 AI 彻底卸下排版工人的包袱,把脑力百分之百地集中在数学推导本身。
它改变了过去强行让机器去啃复杂宏展开和单向编译 TeX 源码的传统路径,引入了基于树状底层数据结构的所见即所得(WYSIWYG)编辑器。
通过利用更为高效的底层数据结构、快速的渲染引擎以及按需加载的插件架构,Mogan 实现了排版计算资源的极大释放。
在 LLM 的实测对比中,表现惊人:
机器解析的信息熵大幅降低,模型微调与训练的效率成倍提升。在处理极其繁复的逻辑排版时,错误定位能力大幅优化,而生成准确性几乎不受传统宏包冲突的干扰。
顺便提一句:为什么大模型最爱的 Markdown 救不了数学?
读到这里,熟悉大语言模型底层的读者可能会产生一个疑问:当前所有的主流智能体(包括 DeepSeek、GPT-4),不都是基于 Markdown 格式进行海量数据预训练和输出的吗?Markdown 本身不就是一种用来对抗冗余排版的轻量级、低熵语言吗?
确实如此。这篇论文在附录部分也特意探讨了 Markdown 的角色与局限。对于普通的科学文本排版(如章节结构、列表、粗体),Markdown 无疑是极其高效的,它让机器摆脱了繁杂的 HTML 或富文本标签。大语言模型之所以在日常对话中表现出色,正是吃到了 Markdown 结构简明的红利。
然而,Markdown 的致命软肋在于:它缺乏对深层数学结构的内建表达能力。
当大模型在 Markdown 环境中遇到数学推演时,它的做法是妥协的——直接将传统的 TeX 宏代码用 $ 或 $$ 强行包裹起来(即我们熟知的 Markdown + MathJax/KaTeX 模式)。换句话说,Markdown 只是给高熵的 LaTeX 穿上了一件轻量级的外衣。
一旦进入代数几何或拓扑学中那些长篇的同调序列推导,或者需要构建多重映射的交换图表时,Markdown 引擎就会把解析任务原封不动地踢回给 LaTeX。机器依然要一头扎进 \begin{pmatrix}、\left( 和 \right) 的高熵泥潭中,算力浪费与语义断裂的问题并没有得到实质性解决。
从这个维度来看,Mogan STEM 的 .tmu 格式,本质上是将 Markdown 处理纯文本的"结构化与低熵哲学",历史性地推进到了深层数学逻辑的腹地。它不再使用一维字符串去"画"公式,而是让复变函数、层上同调等每一个数学算子,都变成了底层清晰的树状节点,彻底打通了机器解析科学文档的"最后一公里"。
解决方案:告别高熵 (Farewell to High Entropy)总的来说,Mogan STEM 的核心洞见是——
大模型时代,就不该让机器去读人写的传统 TeX 宏代码。
在以往的理解中,排版系统的尽头就是 LaTeX。但这篇文章尖锐地指出,TeX 源代码对于机器而言,意味着极高的"信息熵"。复杂的宏展开机制和单向编译流程,不仅增加了模型训练的难度,也严重拉低了实时交互与生成的效率。
那么,为什么要费这么大劲去替换一套运行了数十年的成熟系统?
之所以这样做,是因为在当前的 AI 辅助数学推导中,机器需要频繁地生成、验证和修改长篇的公式证明。如果继续使用 TeX,每次都需要耗费海量的 Token,且一旦少了一个 } 就会导致编译全盘崩溃。推理性能的瓶颈,实际上已经从"逻辑推演"转移到了"格式解析与对齐"上。在现有的架构中,解析 TeX 代码让模型承担了不必要的计算负载,造成了严重的算力浪费。
正如当前业界大佬反复强调的:底层的结构决定了上层建筑的效率。
结构化破局 (Structured Breakthrough)针对这些问题,三鲤团队构建了基于 .tmu 原生格式的创新方案:
传统路径(高熵高成本):LLM 生成复杂 TeX 源码 → 经过繁重的底层宏展开 → 渲染引擎单向生成。这其中一旦出错,机器极难进行反向错误定位。
Mogan 路径(低熵高效):LLM 生成结构化的 .tmu 代码 → 直接映射为内存中的树状数据结构 → 实时所见即所得(WYSIWYG)渲染。
在架构组成上:
底层数据结构:彻底抛弃了扁平的字符串解析,改用具有低信息熵的结构化文档树。
渲染引擎:极速的实时渲染机制,取代了传统的单向编译流程,大大缩短了编译与渲染时间。
插件架构:采用按需加载模式,避免了传统 LaTeX 动辄成百上千个宏包的臃肿与冲突。
如上所述,Mogan 系统的核心在于打破了传统排版的"黑盒"属性。在实验阶段,通过大量对比实验,.tmu 格式展现了降维打击般的优势。
三鲤团队研究人员分别使用传统的 TeX 源码和 Mogan 的 .tmu 结构化格式对同级别的大语言模型进行微调(Fine-tuning),并在以下三个核心维度进行了极限测试:
1. Token 消耗与信息熵压缩测试在处理相同的长篇数学推导(例如包含复杂交换图表与多重同调群的正合序列证明)时,实验对比了两种格式的输入/输出体积。
数据表明,.tmu 格式凭借其抛弃了海量排版控制符(如宏包引入、间距微调、环境包裹等)的优势,将单个数学文档的平均 Token 数量削减了近一半。这意味着,在相同的上下文窗口限制下,模型现在可以"读懂"并"写出"比过去长近一倍的纯数学逻辑。
2. 零次命中(Zero-shot)编译成功率对于机器生成的代码,最大的痛点在于"语法崩溃"。传统 TeX 极度脆弱,往往因为漏掉一个 } 或拼错一个 \begin{pmatrix} 导致整段推导无法渲染。
实验证实,在未经人工干预的连续生成测试中:
传统 LaTeX 组:首轮编译一次性通过率仅维持在较低水平,大量算力被迫消耗在后续的 Error 修复循环中。
Mogan STEM 组:得益于底层的抽象语法树(AST)直接接管了结构对齐,即便模型在局部代数变形上出现逻辑瑕疵,其输出的 .tmu 文档依然能保持 100% 的结构完整性,实现近乎完美的编译成功率。模型彻底告别了"数括号"的排版梦魇。

这是最令人振奋的发现。当模型不再被"高熵噪音"干扰,它的数学智商似乎被真正释放了。在针对复杂定理的 Pass@1(单次生成准确率)测试中,基于 .tmu 格式微调的模型,其推演准确率显著反超了基于 LaTeX 训练的对照组。
为了更直观地展现这种差距,我们可以参考以下核心测试数据对比:

总的来说,在 LLM 的微调与训练任务中,由于 .tmu 格式具备更低的信息熵,将其用于训练不仅大幅缩减了 Token 消耗,模型对高阶数学公式的理解与生成能力,也显著优于直接硬啃 TeX 代码。这篇论文证明了通过底层排版架构向着结构化、低熵格式的演进,可以有效突破当前大模型处理科学文本的"语义墙"。
它成功利用了结构化数据的高效性,呼吁学术界在未来的模型训练中,更多地采用 .tmu 格式进行大规模实验,在不增加算力成本的前提下,大幅提升人工智能对数学公式和科学文档的理解与生成能力。
One more thing虽然文章重点探讨了机器视角的优化,但 Mogan STEM 脱胎于经典的 GNU TeXmacs 开源生态。这个背后的开发者群体“三鲤团队”,一直致力于为学者打造真正的"黑客级别"结构化编辑器。
相关资源 [2603.02873] LaTeX Compilation: Challenges in the Era of LLMs, https://arxiv.org/abs/2603.02873 获取原论文。
https://blog.sciencenet.cn/blog-3631244-1526187.html
上一篇:【软件分享】 AI 科技写作平台—— Liii STEM
