博文
人工智能与物理学(3)—— 认识规律(之一)
||
人工智能与物理学(3)—— 认识规律(之一)
【一年之计在于春。早春二月(阳历三月)也是科研“播种”的季节。是否能结出丰硕的果实?现在的努力是第一步,所以开学后的前几个星期格外繁忙。这个周末总算是告一段落,但研究生的面试周和答辩季又开始了(周五、周六在北京,下周在学校)。忙里偷闲,接着讲“昨天的故事”。】
上次说到:人工智能是建立在大数据基础上的,基于大数据、建立大模型,发展新应用。这与物理学在数据积累的基础上发展模型、总结规律的认识过程是一脉相承的。
今天再细说一下这个认识规律:数据积累à发展模型à总结规律。
还是从2010年世界杯数据说起。
先看看这组零星的数据:
【图】 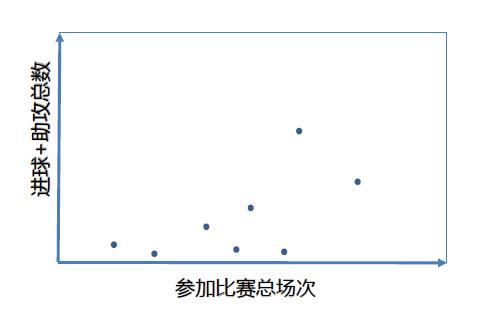
横坐标(简称x)是参加比赛的场次,纵坐标(简称y)是进球总数。踢足球嘛,进球才是硬道理!显然,平均每场进球数定理表征了一个球员的水平:在图上从原点到某球员的数据点画一条直线,斜率(y/x)就是该球员的“场均进球数”;斜率越大(线的位置越高)球员越优秀。这组数据可以两两比较球员的高下,却无法找到一个统一的标准。但下面这组数据就不一样了:
【图】 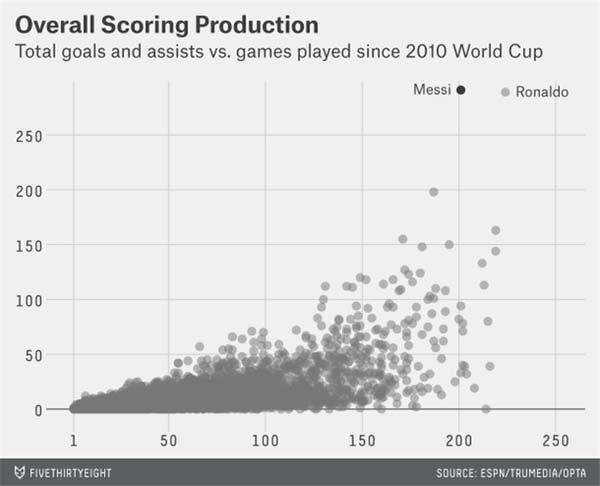
从这组数据(包括了所有参赛球员)可以明显看出存在着清楚的分界线(而且是一条直线!),绝大多数球员处于这一分界线下面:这条分界线可以作为区分一般国际级球员(处于线下方)和优秀国际级球员(处于线上方)的标准。
还可以找到另外一条上限(y = 0.87x),几乎所有球员都在这条上限之下,只有三位(Messi、Ronaldo和一位“不具名”的)在这条线之上。
画出来(下图):区分优秀和一般:y = 0.45x;区别优秀和杰出::y = 0.87x。
【图】 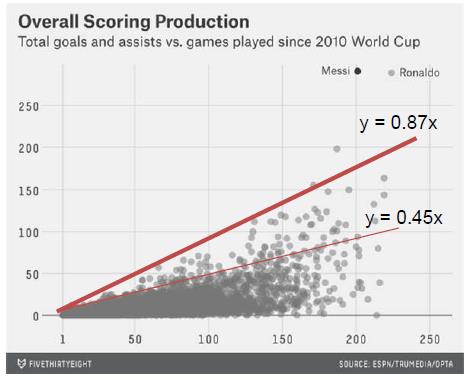
定量结果,听起来也很合理:平均起来,两场比赛能进一个球就是优秀、每场比赛都进球就是前三!
可是,为啥?原因是什么?说不请,就是看数据、“凭感觉”而已!
这种知其然,不知其所以然的定量关系,有个名字:经验公式。
再举一例:各国经济发展趋势和适应性(fitness)的关系
这是发表在Nature Physics的一组数据 [Tacchella, Mazzilli, and Pietronero, Nature Physics 14, 861–865 (2018). https://doi.org/10.1038/s41567-018-0204-y ]:
【图】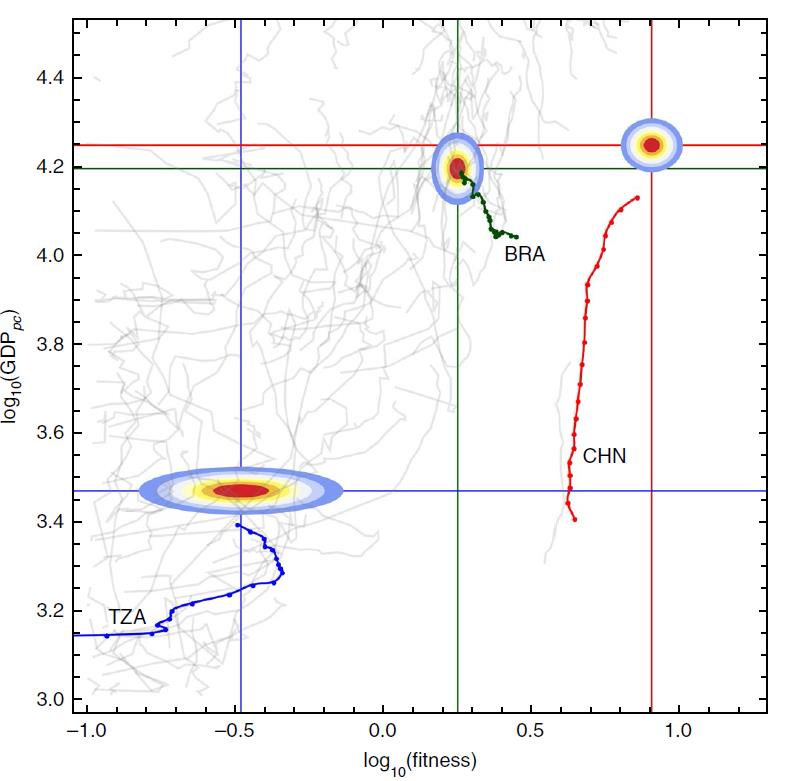
从图中数据的时间发展“轨迹”,我们可以发现:大部分发展中国家(包括所有落入“中等收入陷阱”的国家)都分布在左边的区域,而中国(红色点线)却在图中远离该区域的右边。由此我们可以得到掉入“中等收入陷阱”的判据(下图):x < y/3 - 1.1(y > 3x + 3.3),即“经济适应度”小于一定阈值时,就有可能掉进“中等收入陷阱”。
【图】 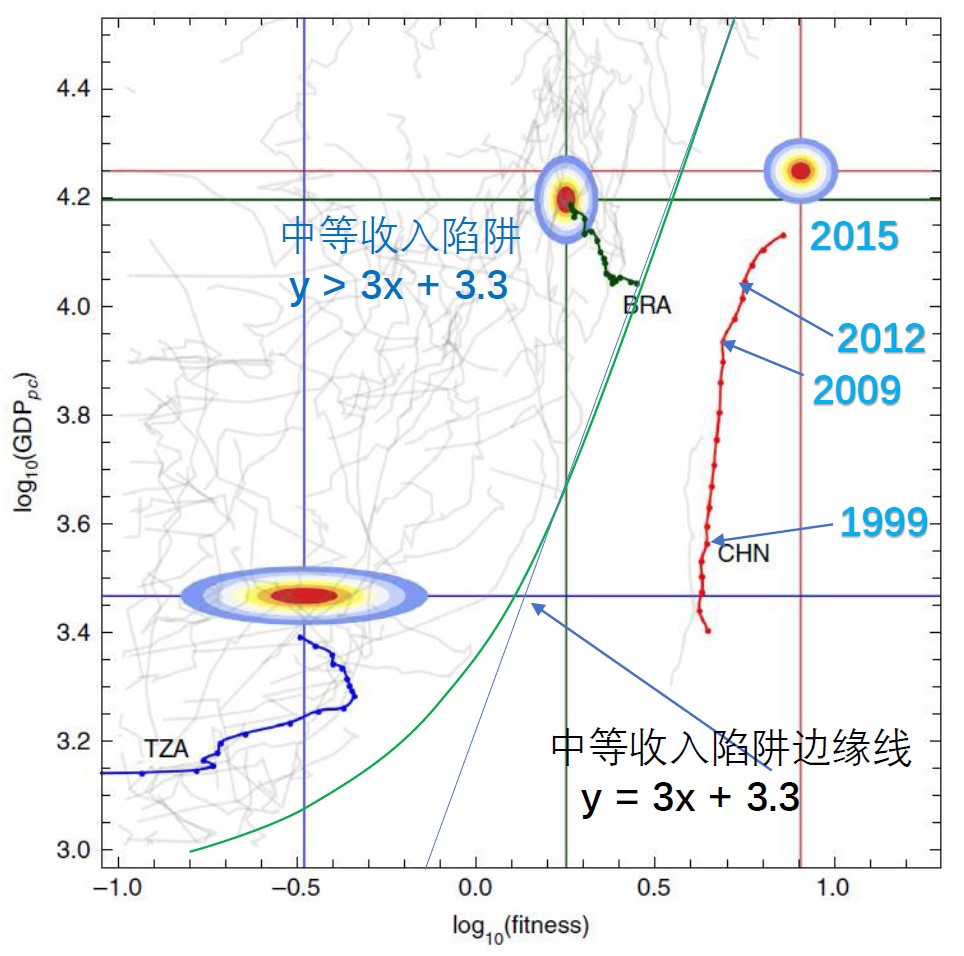
虽然中国曲线的函数值(y=人均GDP的对数)与大多数发展中国家相差不大(到2015年的预期也仅仅是中上水平),但其fitness(经济发展对变化的适应性)却远远高于其它国家,使得中国的经济发展曲线远离绝大多数发展中国家所在的区域。所以,中国经济的发展非常健康(直线向上),远离“中等收入陷阱”。
这里,从数据集合观察出的判据y = 3x + 3.3显然也是“经验公式”——知其然不知其所以然:知道这个定量关系好使,但是不知道其中的道理。
这几个定量关系/经验公式都是人(这里是笔者)根据数据自身的特征或结构“拟合”出来的。像这种简单的数据结构,其内在的定量关系我们可以一眼看出来。但更多是具有更复杂结构的数据,只能通过可以工作者发展起来的各种数据分析方法来处理,非常耗时,而且结果不一定好。但对目前的物理学研究,也只能如此。所以,利用大数据技术处理复杂数据集,快速得到类似“经验公式”的“拟合”结果,是当前人工智能的可以大显身手的主要用武之地。
我们说过:天下武功,唯快不破!“Velocity”(速度)不仅是大数据技术的主要特征之一,也是人工智能的主要特征。
https://blog.sciencenet.cn/blog-39346-1478922.html
上一篇:人工智能与物理学(2)—— 昨天的故事
下一篇:清明的怀念

全部作者的精选博文
- • 清明的怀念
- • 人工智能与物理学(2)—— 昨天的故事
- • 绝知此事要躬行
- • 你好!新学期
全部作者的其他最新博文
- • 清明的怀念
- • 人工智能与物理学(2)—— 昨天的故事
- • 人工智能与物理学 —— 已知与未知
- • 绝知此事要躬行
- • 你好!新学期