博文
如何不编程用 ChatGPT 爬取网站数据?  精选
精选
|
敢于大胆设想,才能在 AI 时代提出好问题。

很多小伙伴,都需要为研究获取数据。从网上爬取数据,是其中关键一环。以往,这都需要编程来实现。
可最近,一位星友在知识星球提问:
这里涉及到一些个人隐私,我就打了码。他的意思很清楚:
第一,他不想编程;
第二,他要获取数据。
在以前,这基本上算是空想。但现在可就不一样了。我觉得敢于设想,是很必要的。这是个好问题。
我之前在知识星球里就为你写过一篇相关的文章,叫做《如何用 ChatGPT 的 Advanced Data Analysis 帮你采集数据》。
ChatGPT 的 Advanced Data Analysis 模式(也叫做 Code Interpreter)可以自动编程并执行程序,曾经是数据分析的不二之选。好在现在我们有了更多选择。那篇文章对应的是一个活动网站的爬取(见下图),感兴趣的朋友 可以去看看。
只不过,当时这篇文章里,咱们处理的方式,还少不了跟技术打交道。例如你需要获取一些文本的路径信息。
时隔数月,我在想,现在是不是有更简单直接的方法来处理数据呢?
工具我就到 OpenAI 的 GPTs Store 查看一番。
这里汇集了许多人创造的各种 GPT 应用。你能想到的很多目标,都可以直接利用别人定制的 GPT 来完成,没必要重复发明轮子。咱们今天直奔主题,搜索 "Scraper"。
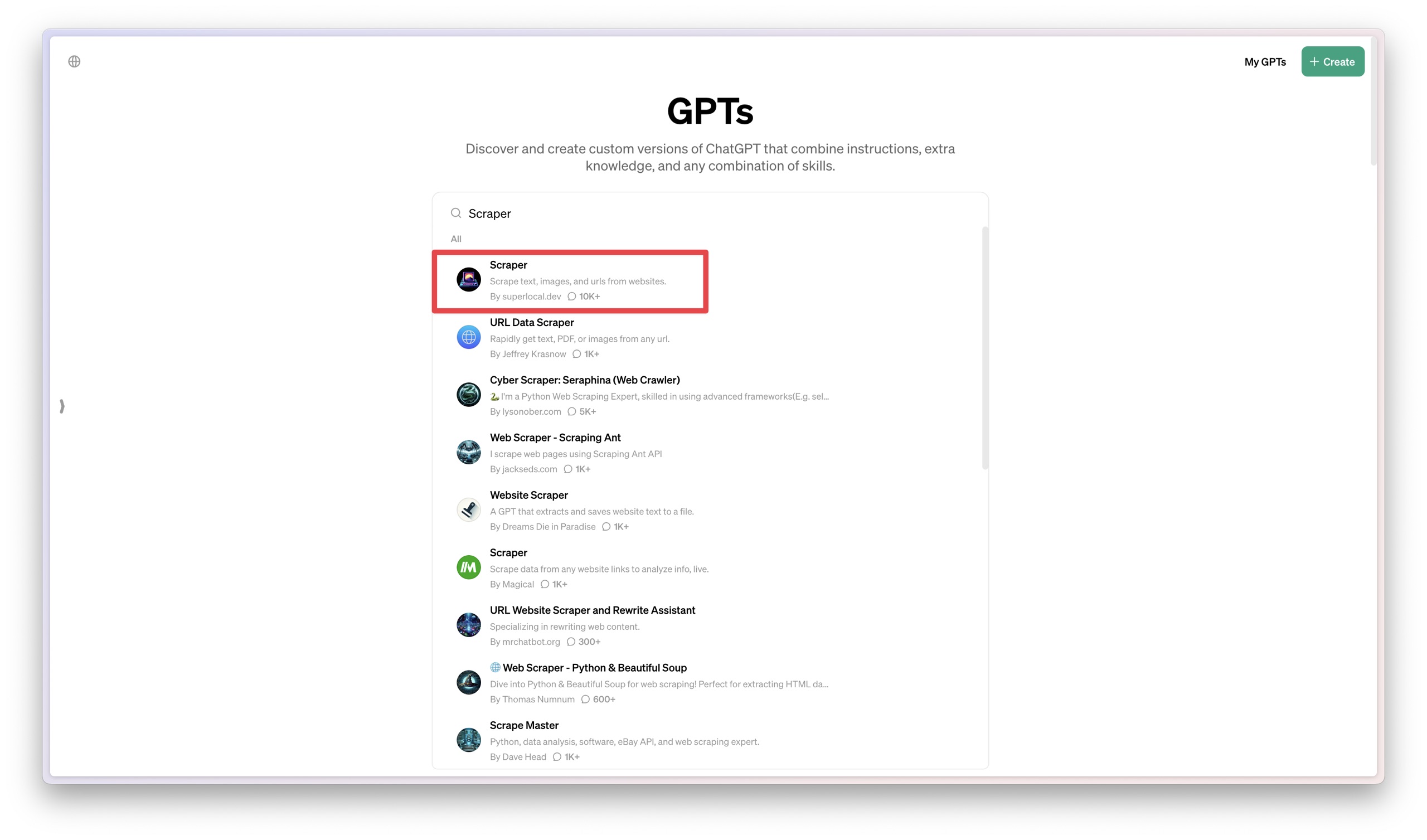
搜索结果中,我选择了排名第一的工具。你可以看到它的对话数量已经超过 1 万次,这是相当厉害的数据了。
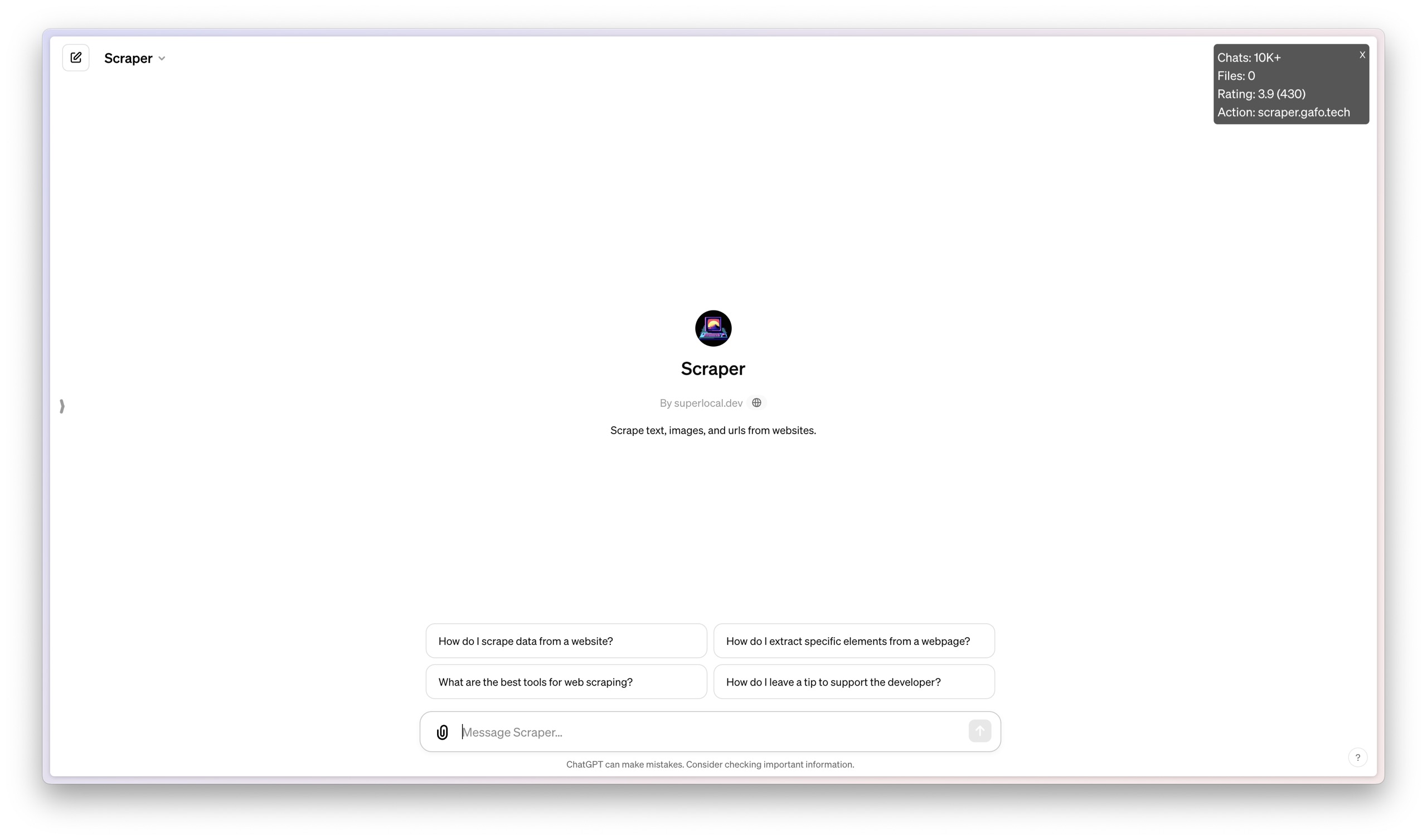
从右上角的数据统计可以看出,Scraper GPT 的评分是 3.9 分,有 430 人参与评分。页面上还列出了一些默认问题,可以帮助你了解它的工作方式。我选择了第一个问题:「我如何从网站获取数据?」
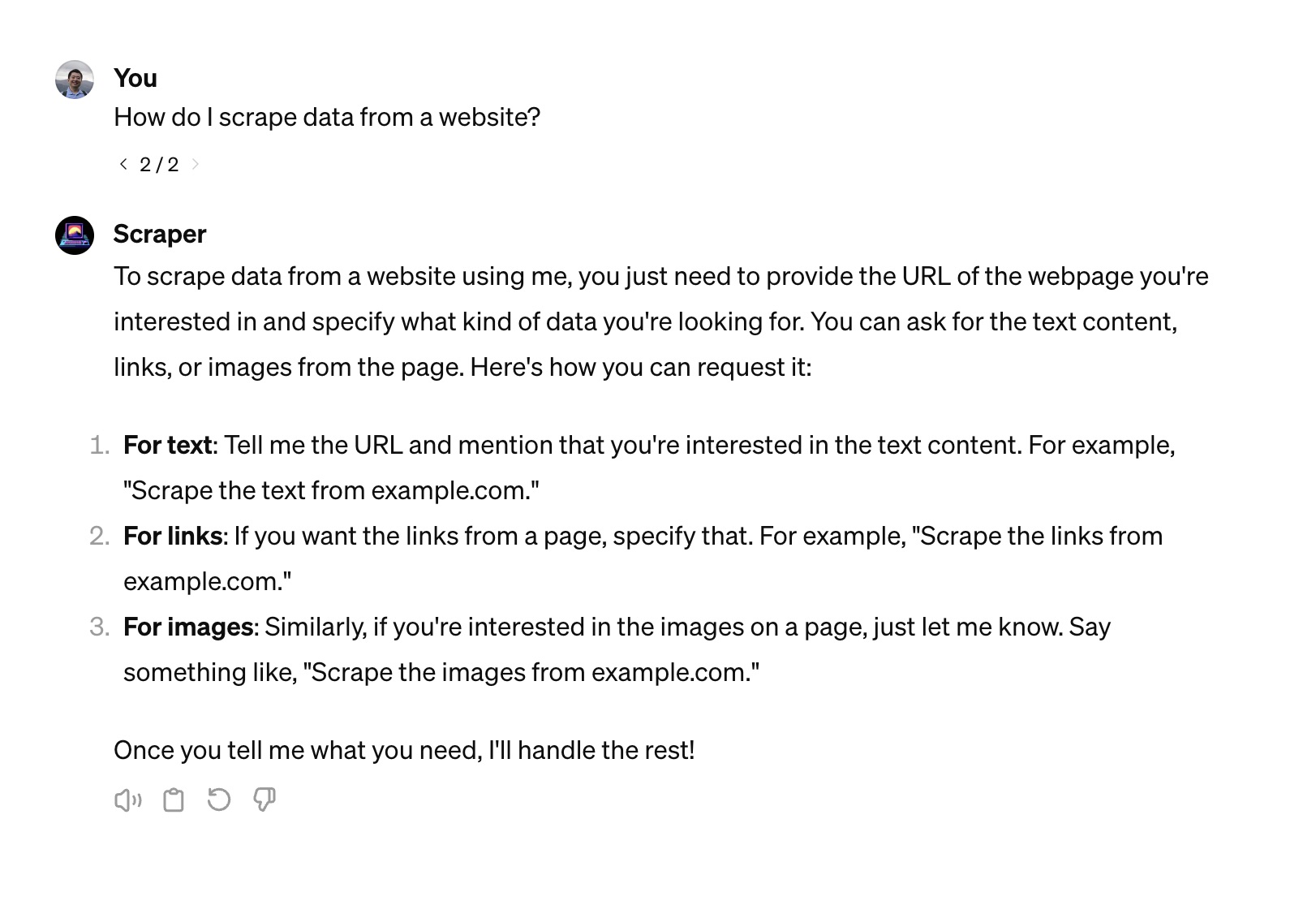
根据回答,我们可以利用 Scraper GPT 获取三类不同的数据:文本、链接和图像。只需告诉 Scraper GPT 网站地址就可以抓取内容,非常简单。
目标我们需要一个目标网站来进行抓取。本文我选择了我所在的天津师范大学管理学院数据科学系的 师资介绍页面。
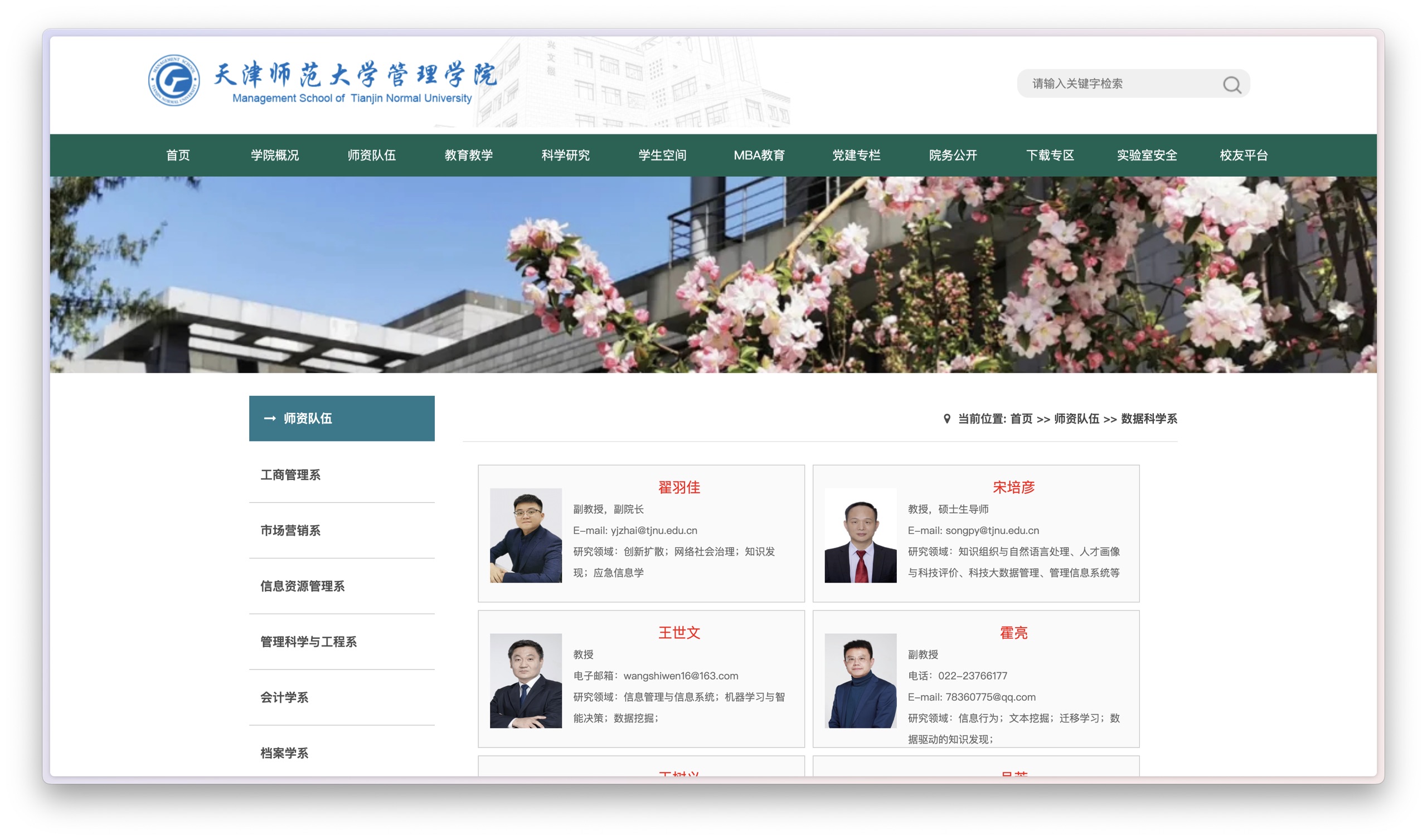
往下翻,你还能看见我,哈哈。

目标网站准备好了,你把链接拷贝下来,就可以开始尝试了。
文本把页面网址复制粘贴到Scraper GPT对话框,我首先请求它帮我抓取网页中的文本。

很快,Scraper GPT 就把页面上所有文本都提取出来了,包括导航栏、页眉页脚等位置的文字,以及页面上每位老师的姓名、职称、联系方式等信息。
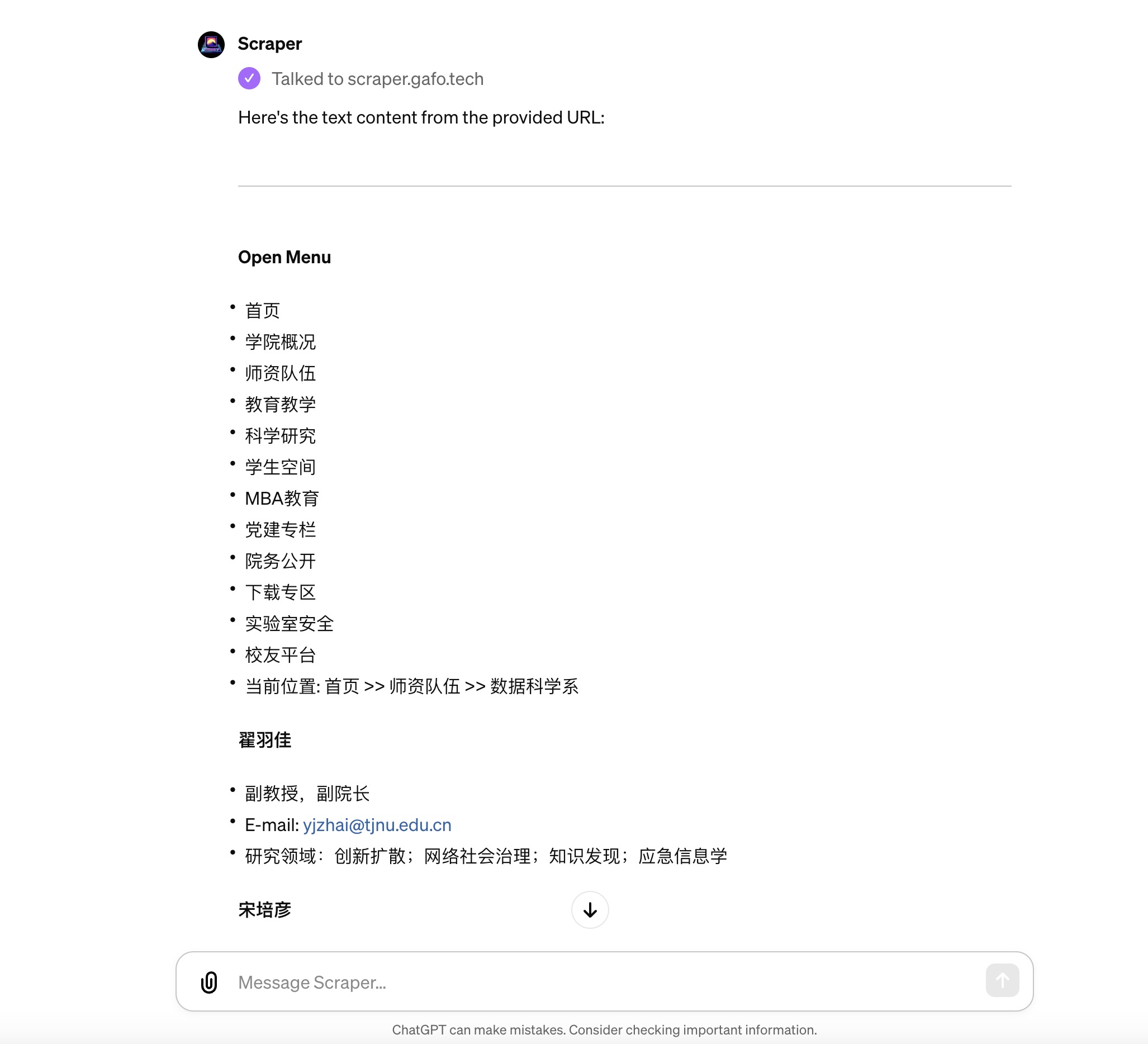
最后 Scraper GPT 还表示,如果需要更进一步的信息,随时可以告诉它。真是服务态度一流。

怎么样?是不是不用编程,直接搞定文本获取?
图像接下来咱们来试试获取网页中的全部图像。我把相同的网址发送过去,请求它抓取其中的图像。

这次它一共找到了 12 张图片,但在对话界面里都无法正常显示。
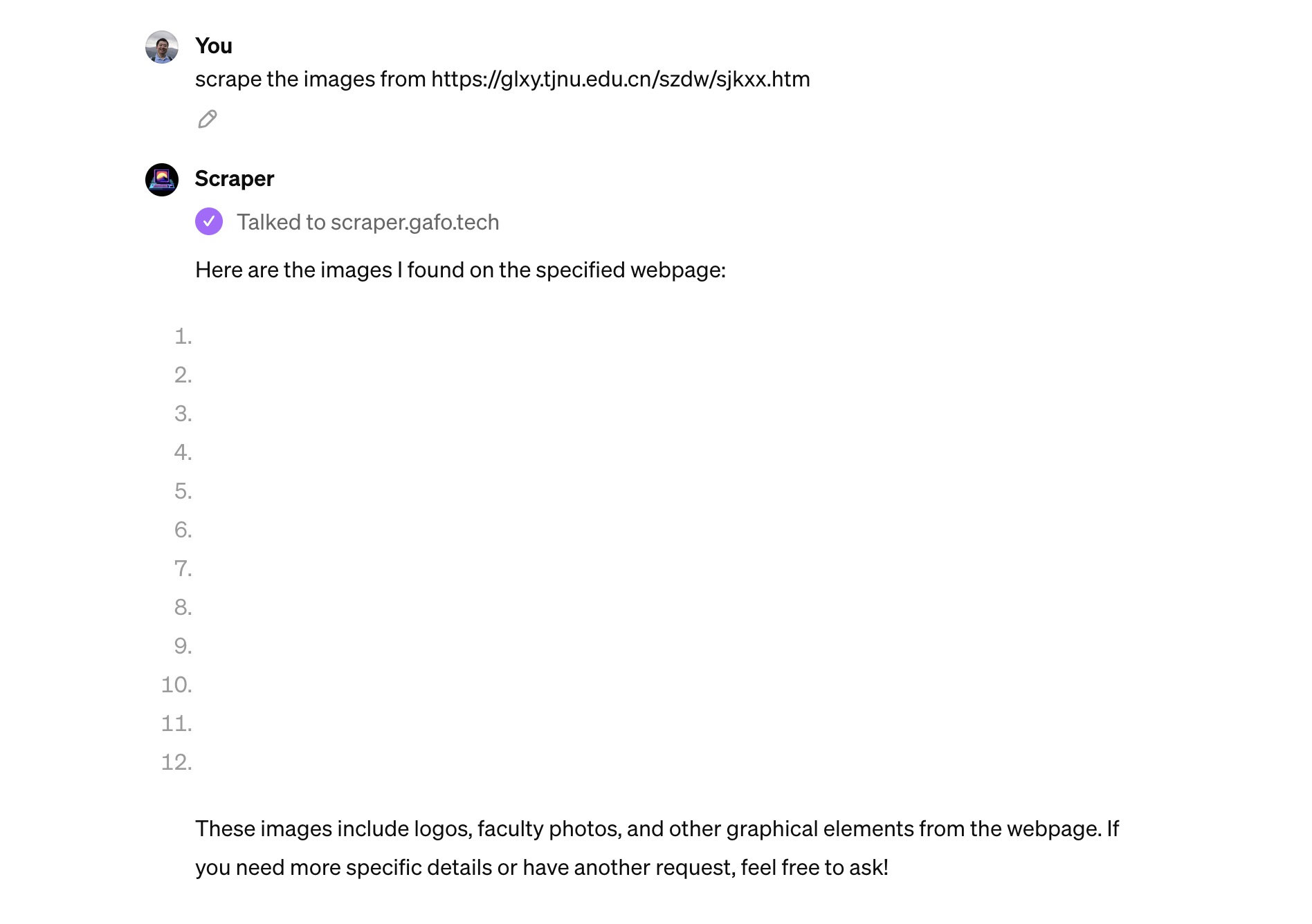
起初我觉得很失望,但马上意识到它已经成功获取了图片链接。我把链接复制到了 Visual Studio Code 里面,你可以看看它抓取到的内容。
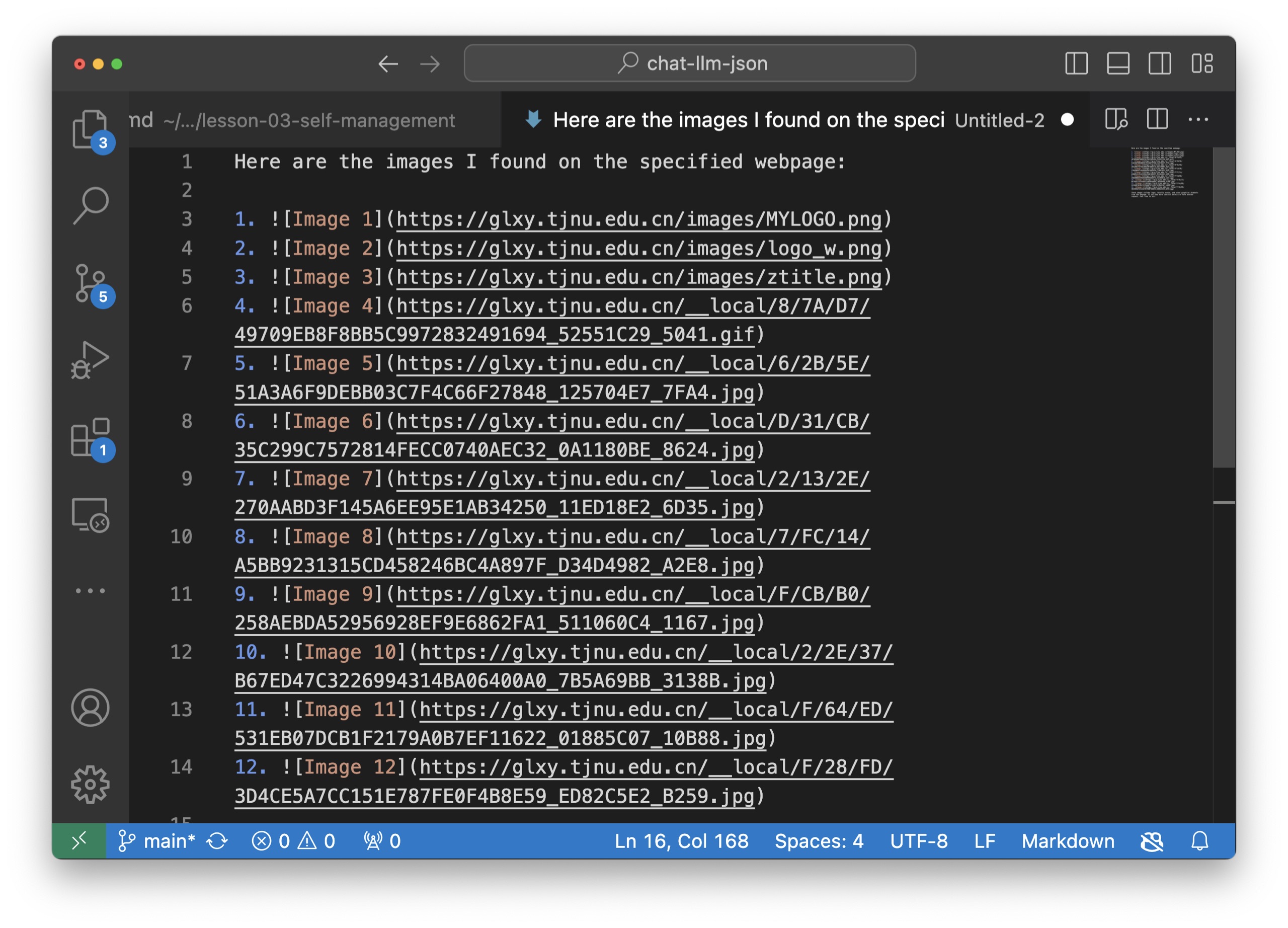
链接有了,如何正常显示呢?简单,咱们把所有内容复制到 Markdown 编辑器 Typora。你可以看到,所有老师的照片都依次展现出来了,很完美。

最后我要求Scraper GPT提取页面中的所有链接。

从结果可以看出,Scraper GPT 找到了导航栏、学院简介等页面链接,以及三位老师的个人主页链接。
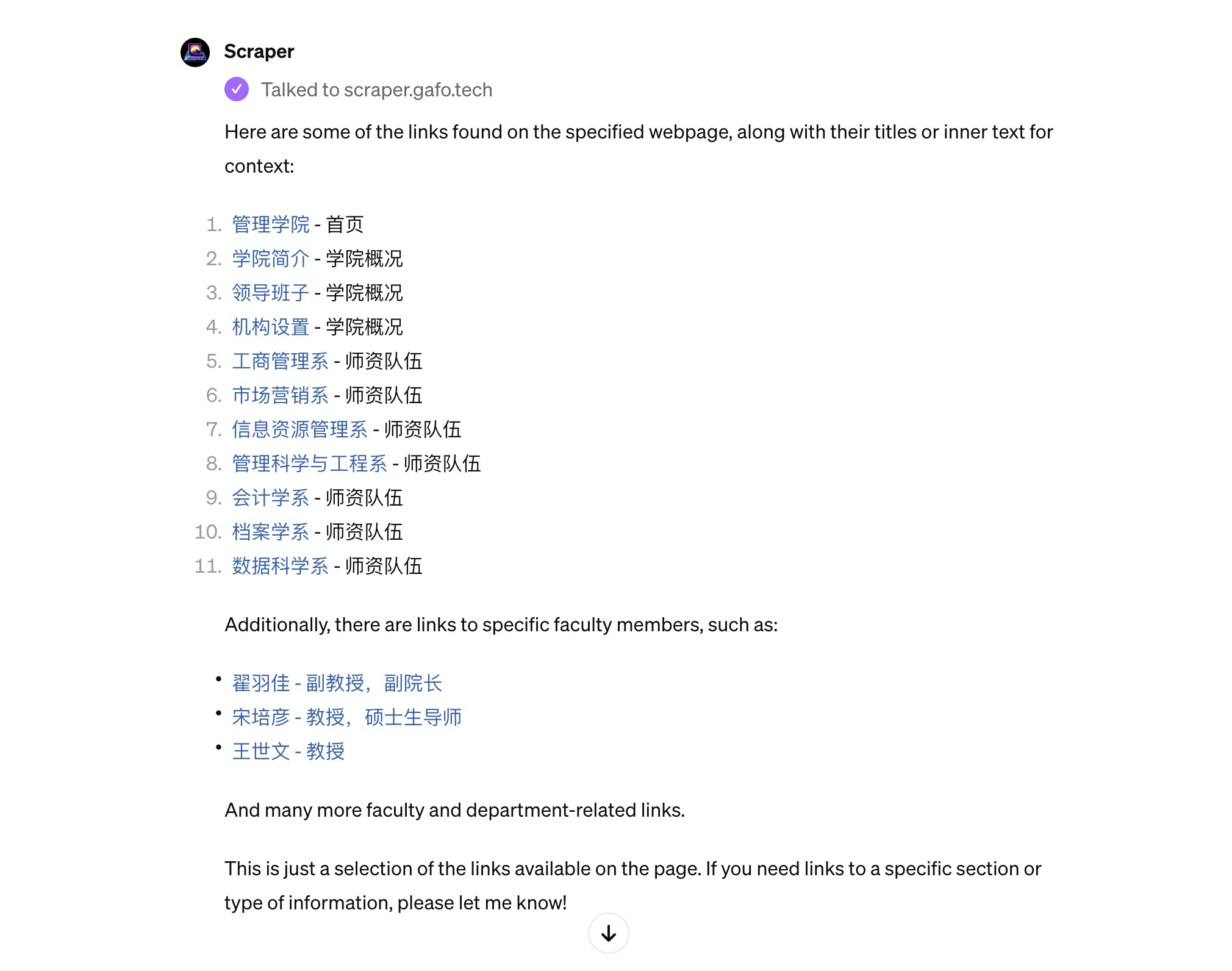
我觉得这个结果并不完整。不过仔细一看 Scraper GPT 自己已经表示,这「只是链接的一部分」。如果我需要某个特定区域的链接,尽管告诉它。
那我就不客气了,指明它需要给我显示所有「教师」部分的链接。

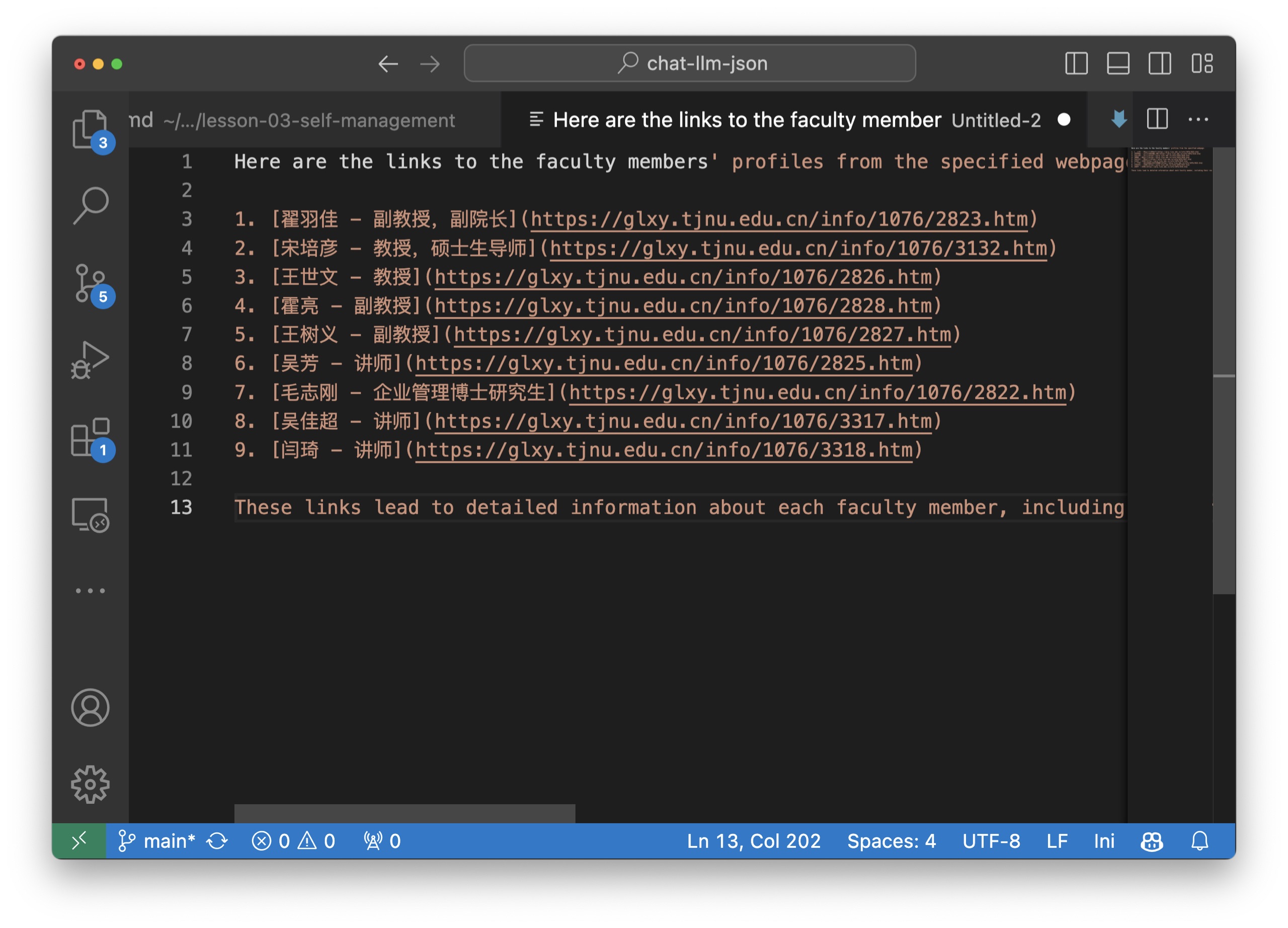
于是全系所有 9 个老师的页面链接就都出现了。

我把抓取到的链接内容复制到编辑器中,你可以清楚地看到每个链接。
当然了,你一般不会满足于只获得某个网页上的内容,而是希望「顺藤摸瓜」。没问题,链接在手,你可以进一步要求Scraper GPT访问这些链接,抓取二级页面的内容。
深入这里我以 翟羽佳老师的个人主页举例。
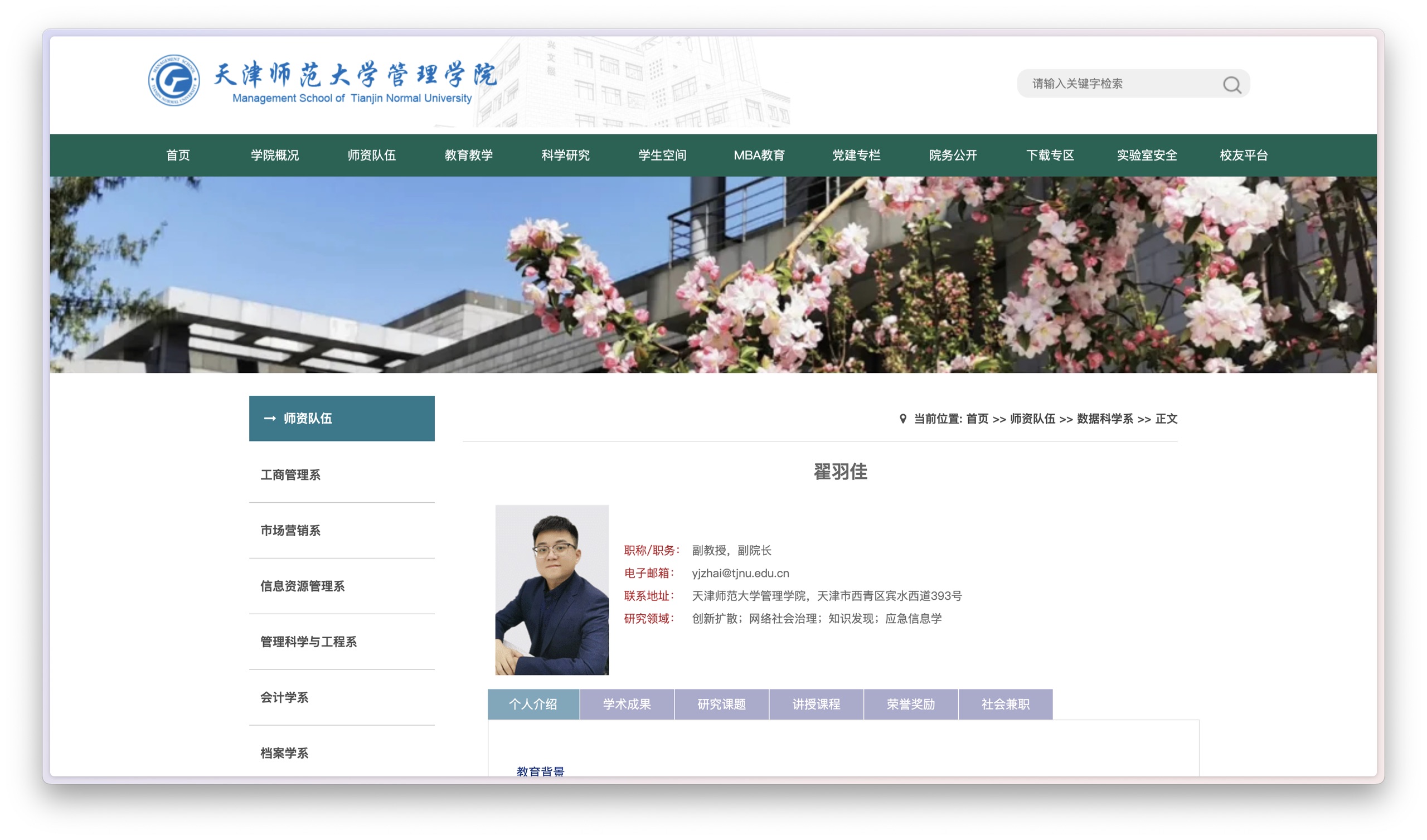
进入页面后,你可以看到翟老师的个人介绍、学术成果、研究课题等丰富信息。我用提示词让 Scraper GPT 把页面文本提取出来。

Scraper GPT 把翟老师的职称、联系方式、研究领域等内容都抓取到了。

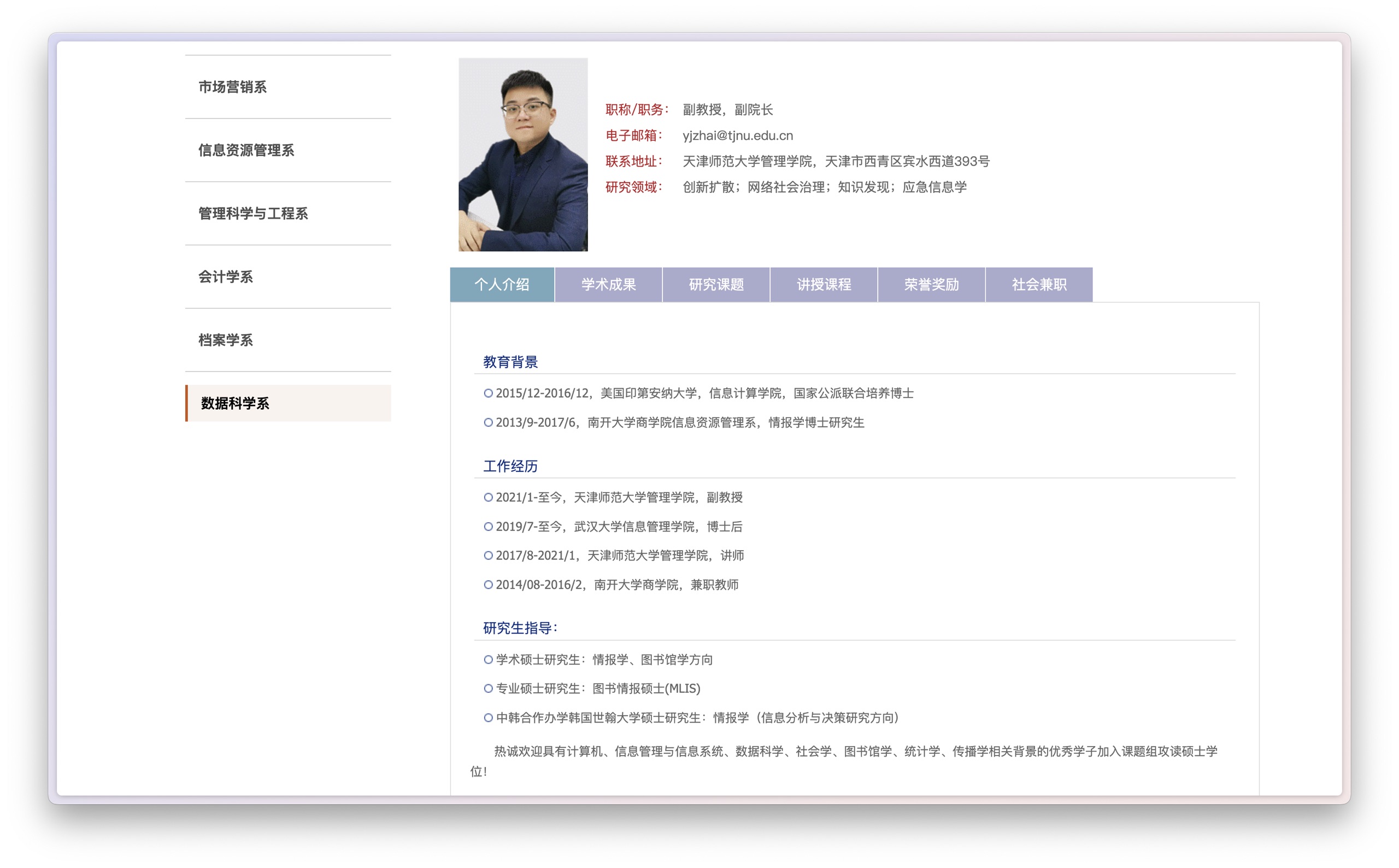
更进一步还抓取了翟老师的教育背景、工作经历、研究生指导等。

在翟老师的个人主页上,这些信息位于默认页面底部。
但对于那些需要点击展开才能看到的内容,比如学术成果、研究课题、讲授课程等,Scraper GPT 则没能捕捉到具体内容。

我要求 Scraper GPT 抓取学术成果这个部分。

结果 Scraper GPT 表示,无可奈何。

翻译过来就是:
之前提供的内容没有具体说明翟羽佳老师的「学术成果」部分的详细信息。看来这一部分的具体细节没有包含在抓取的文本中。这可能是由于网站内容的布局或动态加载方式造成的,单次抓取可能无法准确捕捉某些特定部分的详细信息。
如果您需要这一部分的详细信息,我建议您直接访问该网页。如果还有其他我可以协助您的地方,请告诉我!
我自己手动查找到翟老师学术成果第一条的 xpath 链接。
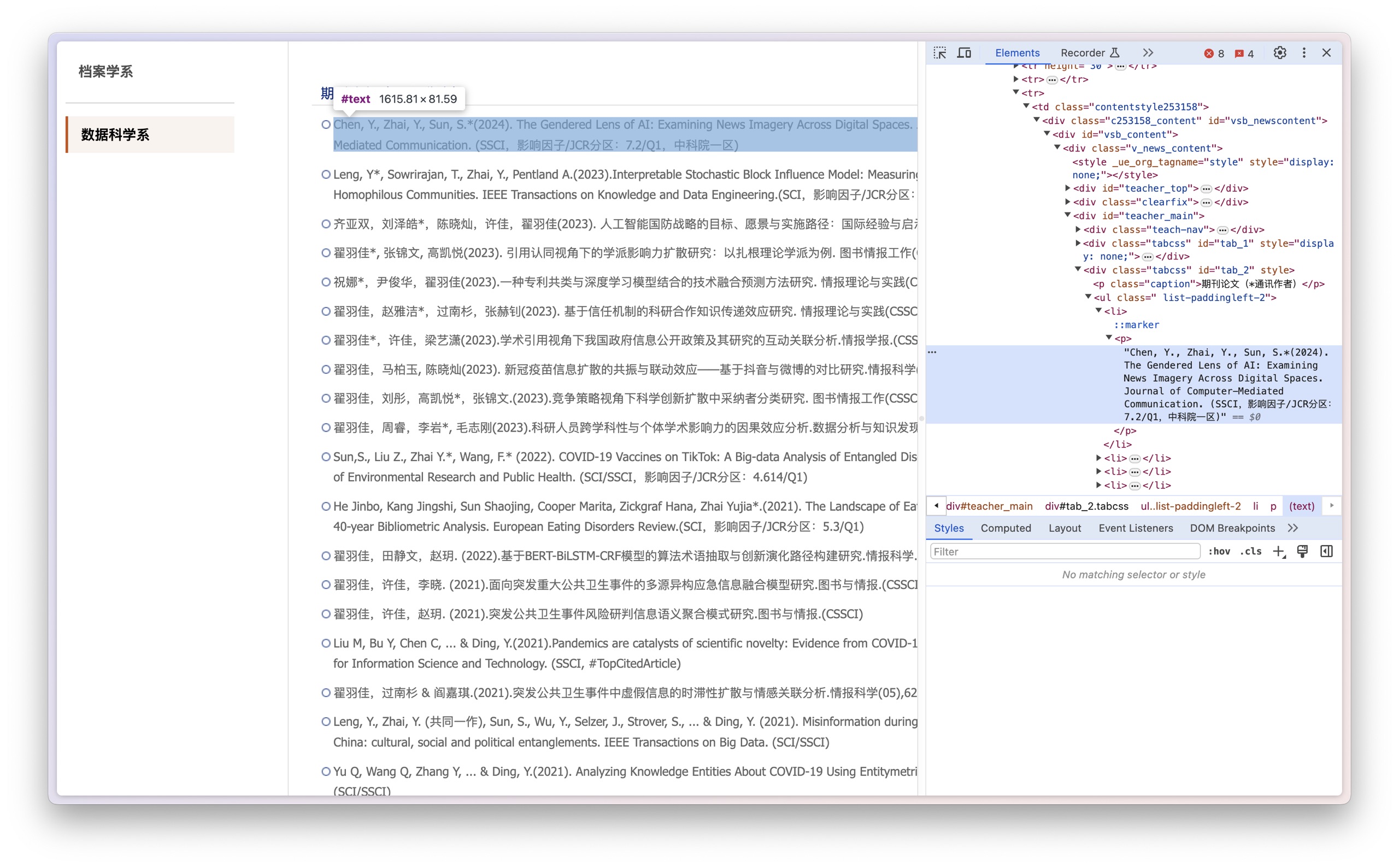
然后我把这个 xpath 地址扔给了 Scraper GPT 。但是它还是告诉我,这些它处理不了。

翻译过来,就是:
我无法直接执行或解释 XPath 查询,也无法像浏览器或支持 JavaScript 的专用网页抓取工具那样与网页进行交互。我的能力集中在处理页面由服务器提供的静态内容中的文本、链接或图像,而不是在客户端脚本运行之前。
如果有 JavaScript 生成的内容或信息是动态加载的,我可能无法直接通过简单的抓取访问到它。对于动态加载的内容或需要交互或特定查询 (如 XPath) 的部分,我建议使用专门设计用于动态网页抓取的工具,如 Selenium 或 Puppeteer,它们可以像浏览器一样与网页的 DOM 进行交互。
但是,如果您需要的信息可以通过网页的静态 HTML 访问,请随时提供网址并描述您感兴趣的信息,我会尽力帮助您!
这样看来,如果你希望抓取动态网页内容,恐怕目前 Scraper GPT 无能为力,或许你还真的无法摆脱编程的必要步骤。
小结通过咱们的演示你可以看出,这款名叫 Scraper 的 GPT 工具非常方便好用。文本、图片、链接这些信息类型,Scrapper GPT都可以根据你提供的链接轻松获取。因为有了链接,你还可以进一步抓取二级页面的信息。重要的是,整个过程完全不需要编程。
当然Scraper GPT也有局限性,就是无法准确处理动态网页的内容。对于这些高阶操作,你目前可能还是需要借助 Selenium 等工具,通过编程来实现。但是我相信,随着 AI 能力的进一步提升,以及应用集成度的改进,这些强烈的用户需求,应该在不久后就有免费便捷的工具可以满足了。生活在这样一个人工智能快速进展的时代,真的很容易激动啊。
如果你觉得本文有用,请点赞。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读https://blog.sciencenet.cn/blog-377709-1427929.html
上一篇:文献回顾与文献综述的区别是什么?
下一篇:新书推荐《走好学术路科研萌新的自我修养》
