博文
如何用 GPT-4 全模式(All Tools)帮你高效学习和工作?
|
「十项全能」的 ChatGPT ,用起来感受如何?

之前,作为 ChatGPT Plus 用户,如果你集齐下面这五个模式,就会成为别人羡慕的对象。
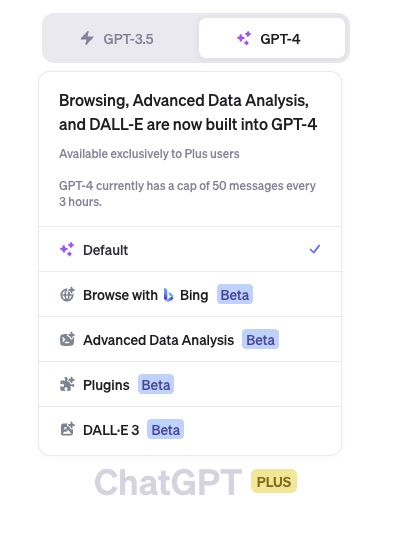
但现在,人们更加期盼的,是下面这个提示的出现:
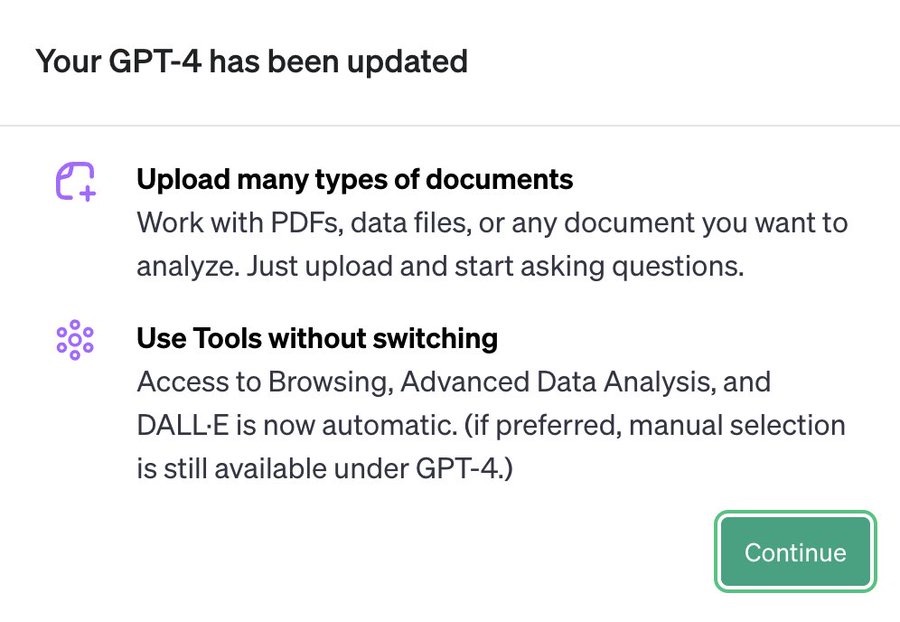
这个提示,意味着你的 GPT-4 已经不再是「一专」(只能使用某一模式),而是「多能」(根据需要自动调用不同模式的功能)。
例如你可以让 ChatGPT 看到一幅图(原本的基础模式),然后让它自动理解总结图片的内容,并且要求它绘制出类似的图片(原本的 DALLE)模式。当然,你还可以让它自动编程(原本的 Advanced Data Analysis 模式)或者访问网络(原本的 Browse with Bing 或者插件模式)。
这样一来,用户的想象力就可以变成特别有趣有用的实践过程。例如王佩老师,就让 ChatGPT 绘制简笔画。他对绘制结果很满意。

见贤思齐,于是我又把自己的微信头像传上去了。要求 ChatGPT (GPT-4 All Tools):
画成皮克斯风格

于是,我获得了这样的图像:

呃,除了人物不像我,以及背景多了一只狐狸,我没有啥可抱怨的……
同时生成的,还有另外一幅作品。咱们也放大看看。

可这…… 也太不像我了啊。于是,我提出了这样的要求:
画成皮克斯风格,注意人物一定要像。

这次 GPT-4 全模式 (All Tools) 的绘图结果是这样的:

这个…… 你要非得说像我,我无话可说。
我查看了对应的提示词:
Photo of a cheerful man outdoors, wearing a light blue polo shirt and a backpack. He is Asian, with short black hair, smiling warmly with a backdrop of mountains covered with green and reddish trees under a cloudy sky. The image should be transformed into a Pixar-style animation, maintaining the likeness and expression of the person, but with the enchanting and whimsical characteristics typical of Pixar animations.
对应的翻译为:
一张快乐男子在户外的照片,他穿着浅蓝色的 Polo 衫,背着背包。他是亚洲人,有短黑发,背景是山脉,山上覆盖着绿色和红色的树木,天空多云。他的笑容温暖。这张图片应该被转化为皮克斯风格的动画,保持人物的相似性和表情,但具有皮克斯动画典型的迷人和异想天开的特点。
我旋即明白了,图片画得不像我,就是 ChatGPT 识图后总结提示词的原因。这里只描述为「亚洲人」、「快乐男子」和「短黑发」,至于脸型、五官之类的,丝毫没有涉及,那当然没有办法「完美复刻」了。
我在视频中提到了这个问题。有观众提示我说可能是在上传人像的时候,ChatGPT自动做了面部模糊化处理以保护人物肖像权,我觉得非常有道理。回头我准备找个卡通头像上传上去试试看。
看完了这个有趣的例子,咱们该讲讲严肃的事儿了 —— 如何利用 GPT-4 全模式 (All Tools) 帮助你更好地学习和工作?
学习
咱们先从一个最常见的场景开始 —— 上课的时候,看到课件里面的英文不会,该怎么办?

这时候,你可以拍张照或者截屏,让 GPT-4 全模式 (All Tools) 帮助你来翻译。上面这张幻灯截图,它的翻译如下:
描述了使用大语言模型(LLM)时的提示(prompting)能做什么。图片中提到,如果给一个刚刚毕业的大学生一些指导,他们是否能够完成任务。为了更加清晰明了,假设情况如下:
没有互联网或其他资源的访问权限
对你的公司 / 业务没有特定的培训
没有完成先前任务的记忆
每次都会得到一个不同的新毕业的大学生
图片旨在探讨在没有额外资源和指导的情况下,一个新毕业的大学生是否能够根据给定的指导完成任务。
你可能对此不屑一顾 —— 这简单的翻译功能,我手机上的 XX 应用,早就有了。
没错,但是 ChatGPT 可不仅仅会翻译哦。你看到一页幻灯,如果对其中内容有不清楚的地方,可以立即呼唤你的这个「私人助教」来帮忙总结和解答。例如下面这页幻灯,是吴恩达老师在新课程 Generative AI for everybody 中对「监督学习」应用的总结。

我截图发给 GPT-4 全模式 (All Tools) ,要求用中文总结图中内容。

这是 GPT-4 的回答:
这张图片是 Andrew Ng 在讲解监督学习的应用。图片中列出了不同的输入、输出和相应的应用场景。例如,输入可以是电子邮件,输出是判断这封邮件是否为垃圾邮件,应用场景是垃圾邮件过滤。其他的应用还包括在线广告、自动驾驶车辆的其他车辆位置识别、医疗诊断、视觉检测、语音识别和餐厅评论的情感分析等。每个应用都涵盖了将输入数据(如图像、广告和用户信息、音频记录等)转换为有意义输出(如诊断、缺陷检测、文本转录等)的过程。
你看,ChatGPT 打通各个模式之后,拿来当助教非常合适,讲解耐心不厌其烦。更妙的是,你不仅可以让它识别幻灯帮你讲解,还能要求它立即给你写出对应例子的程序代码来。
编程
例如我刚刚听完 GPT-4 全模式 (All Tools) 的总结,依然对监督学习没有形象的概念。于是我下面的提示语为:
就找上面的一个例子,给我写一段监督学习的 Python 代码
ChatGPT 就立即开始干活儿了。
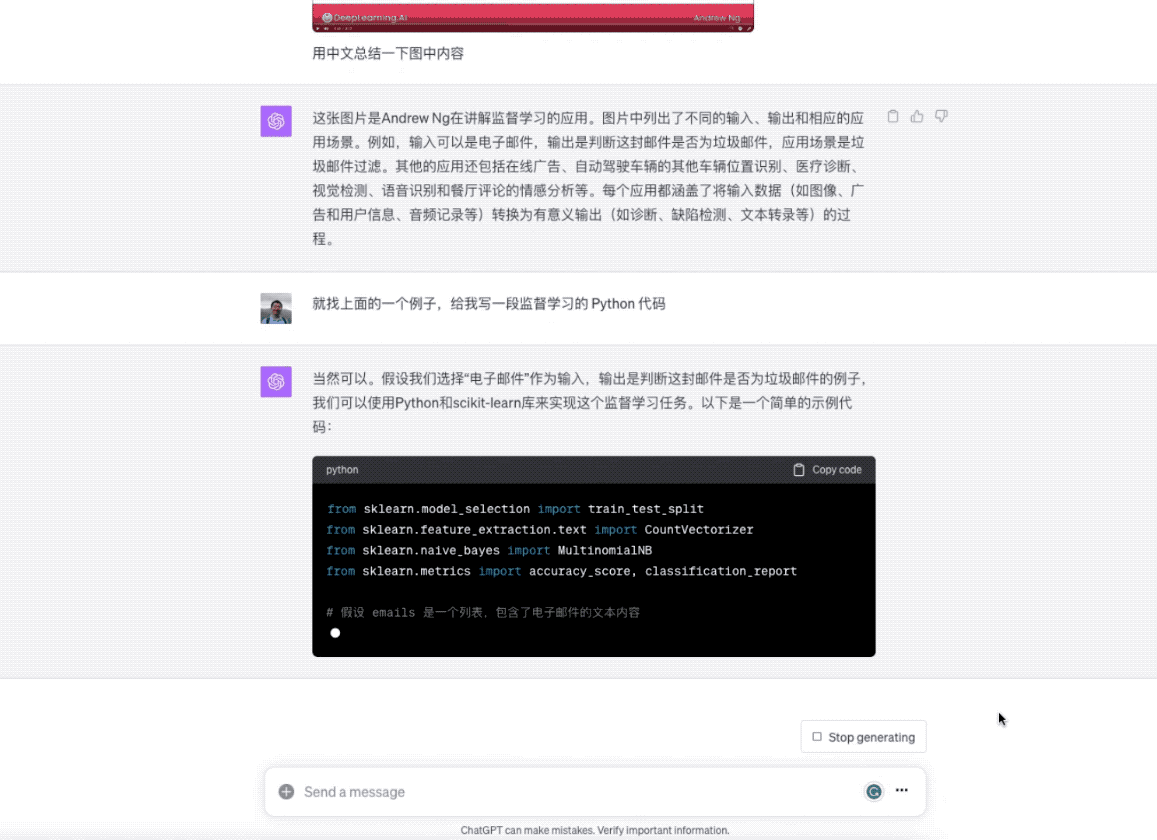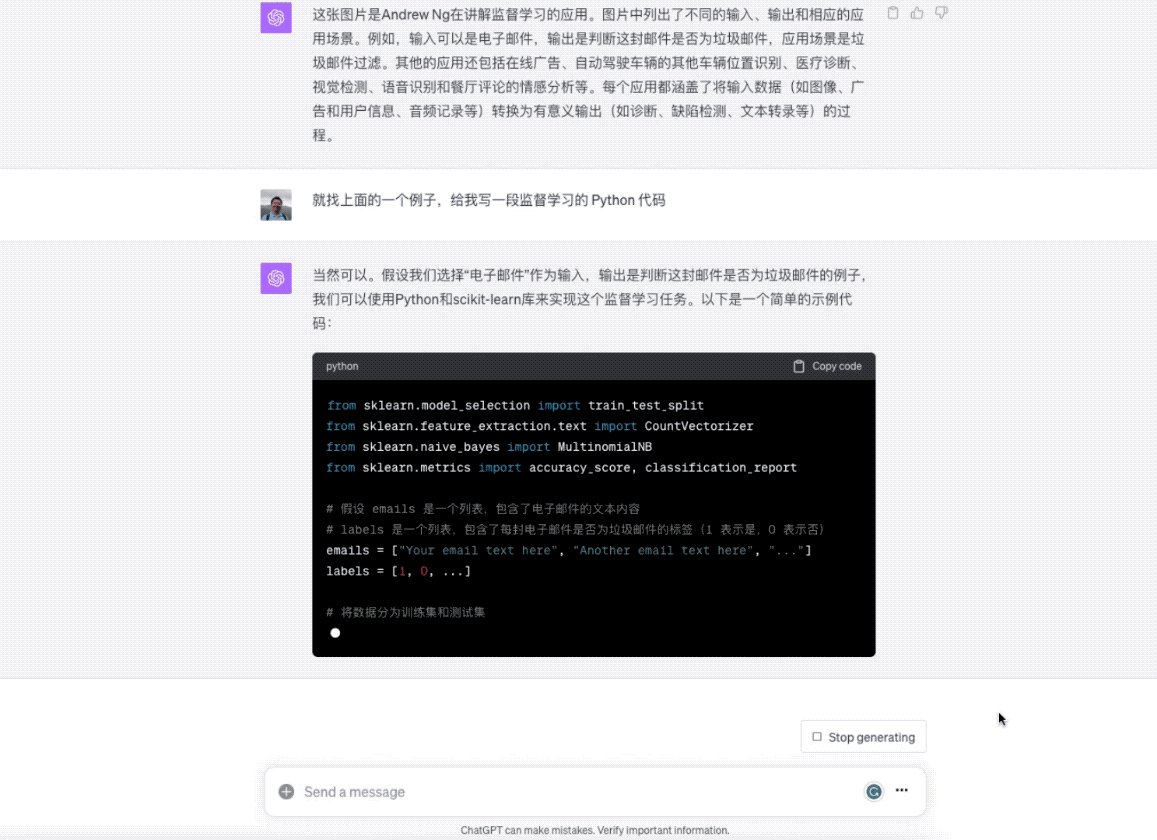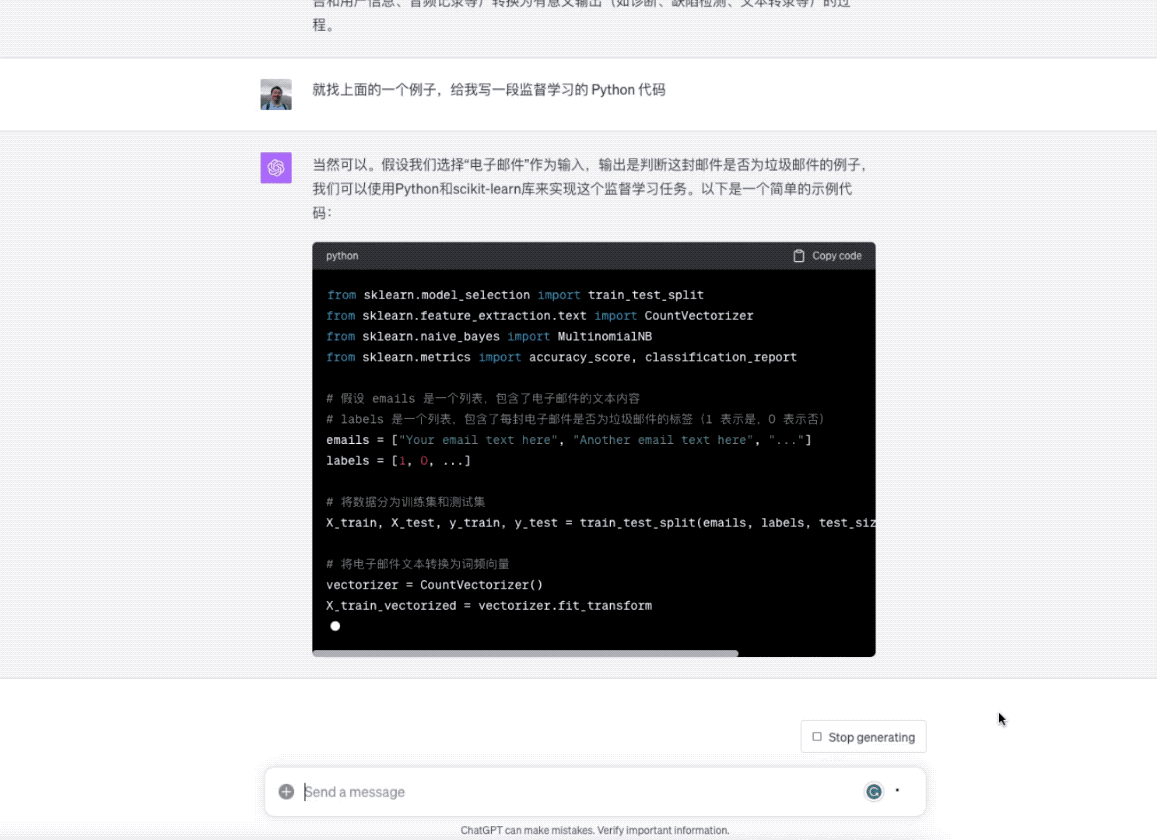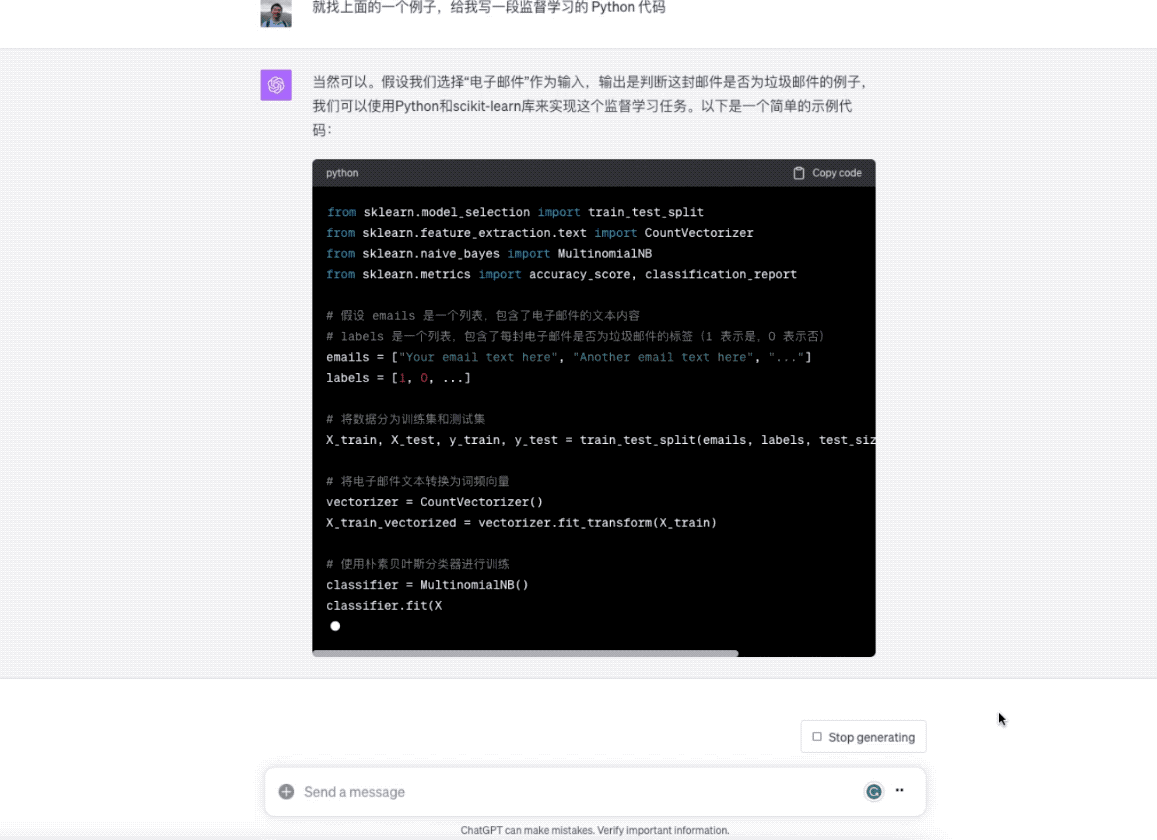
在你看到代码之后,是不是对监督学习的模型训练流程概念理解更加清晰了呢?有了这种快速支援,相信你学东西会更加扎实,疑问也能更及时得到解决。
况且你不要忘了,GPT-4 全模式 (All Tools) 还包含了 Advanced Data Analysis 模式,也就是可以把程序直接作用在数据集上面,帮助你实验,甚至解决实际的问题。下面我们就来看看如何用 ChatGPT 来「看到」实际的数据,并且进行分析。
数据分析
我这里举的例子,也来自于吴恩达老师的新课。他提到了很有意思的问题 ——LLM 对结构化数据处理不好。

我觉得这个观察很有意思,但是将信将疑,于是立即就把数据截取出来尝试。我问 ChatGPT :
这个表格里面有对应的面积和价格,那么 900 sqft 的房子,对应的价格是多少?请一步步思考,并且详细说明你的解题过程
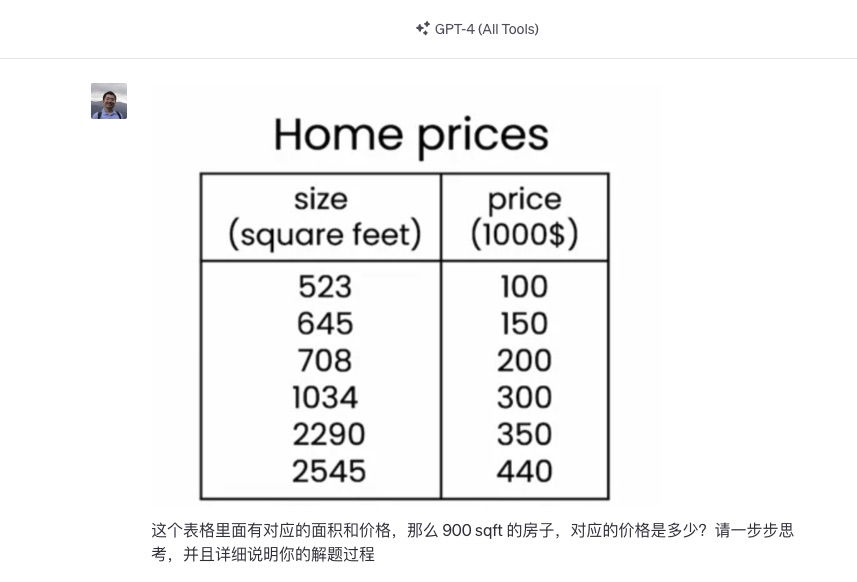
下面是 ChatGPT 的回答:
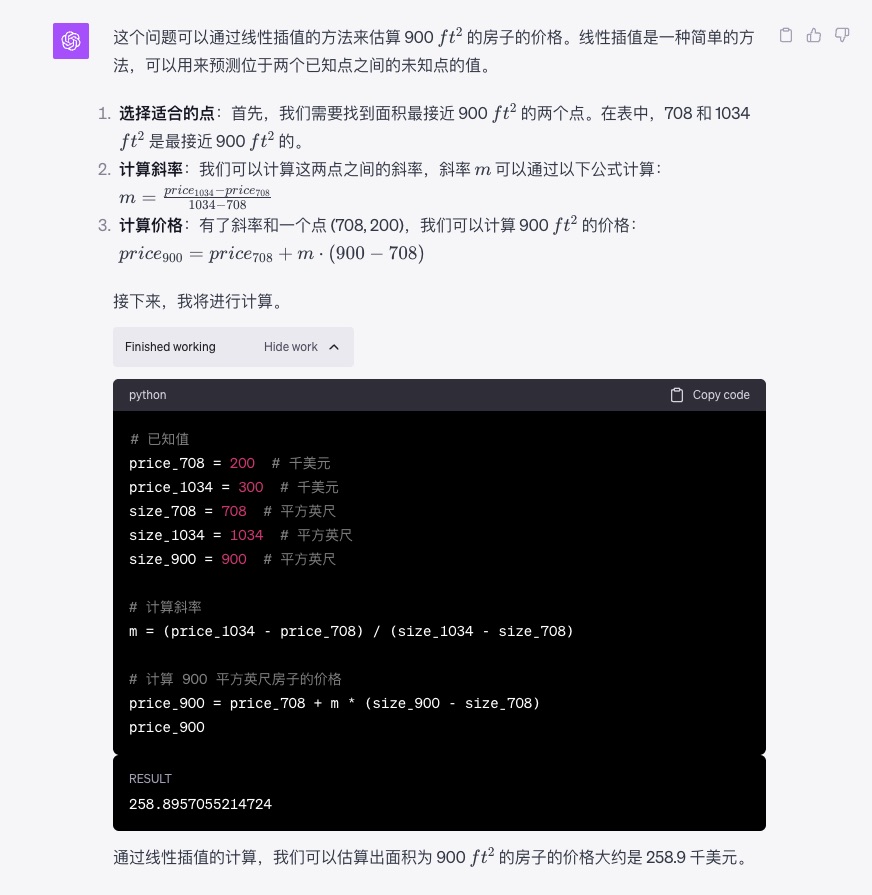
你看,要公式有公式,要代码有代码。数据齐全,分析清晰。只可惜,这个线性插值计算方法并不完美,因为利用数据太少了。为了帮助 ChatGPT 改进结果,咱们还可以这样来追问:
好,但是你能否充分利用上全部数据来建模并且测算呢?
ChatGPT 旋即给了答案。

如果你希望了解 ChatGPT 如何计算,还可以点开被折叠的工作区,查看对应代码。
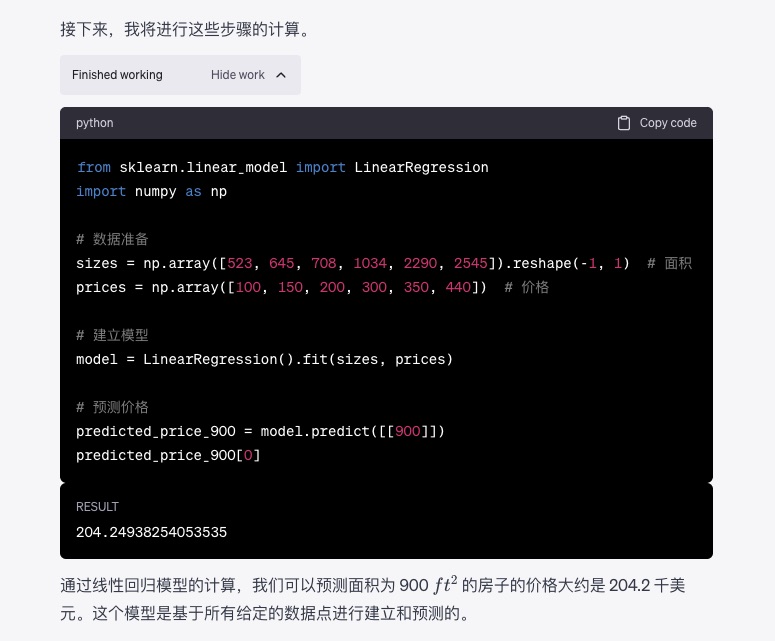
你看,原先表格中的所有数据,确实都被使用了进来。但是,这个计算的结果是否正确?希望你能够检验一下,然后在留言区给出自己的判定答案。
论文阅读
下面这个功能,更是很多小伙伴期待已久的 —— 你可以直接把 PDF 格式的文档扔给 ChatGPT 了。GPT-4 全模式 (All Tools) 可以自动识别其中的内容,并且进行分析和回答你提出的问题。
例如,我从 arxiv.org 下载了 MemGPT 论文的全文。

然后,我把它扔给 GPT-4 全模式 (All Tools) ,提出的要求为:
给我介绍一下这篇文章的亮点

这是 ChatGPT (速度很快)读过文章后,给出的结果。

我们让 ChatGPT 简单翻译一下前面几段:
论文《MemGPT: 朝着作为操作系统的 LLMs》介绍了一种旨在克服当前大型语言模型(LLMs)的有限上下文窗口限制的新系统。以下是其亮点的详细说明:
1. 虚拟上下文管理:作者引入了一种技术,通过借鉴传统操作系统中的分层存储系统,扩展了LLMs的可用上下文范围,超越了标准固定长度上下文窗口的限制。这种技术被称为虚拟上下文管理,通过在快速和慢速存储层之间的数据移动,实现了更大内存的幻象。
2. MemGPT系统:基于这种技术,派生出了MemGPT系统,它利用分层存储结构和中断来管理LLM、存储器和用户之间的数据流和控制。该系统可以在任务进行过程中调整上下文,更有效地利用有限的上下文。
3. 在文档分析和对话代理方面的性能:论文展示了MemGPT在文档分析和多会话聊天领域的增强性能。它能够分析大量文档并保持长期交互,超越了LLM的上下文窗口限制。
很好,这至少证明 ChatGPT 看懂了 PDF 论文全文内容。你也可以就文本内容提出问题,让它来回答。不过类似的内容,我在讲 Chatdoc 的时候都演示过了。这回咱们要充分利用它的全模式功能,搞点儿新花样。
我要求:
把上述内容,用图展示出来,要求让一个中学生能够看懂
于是 ChatGPT 这样绘制:


我们放大一下第一张图。
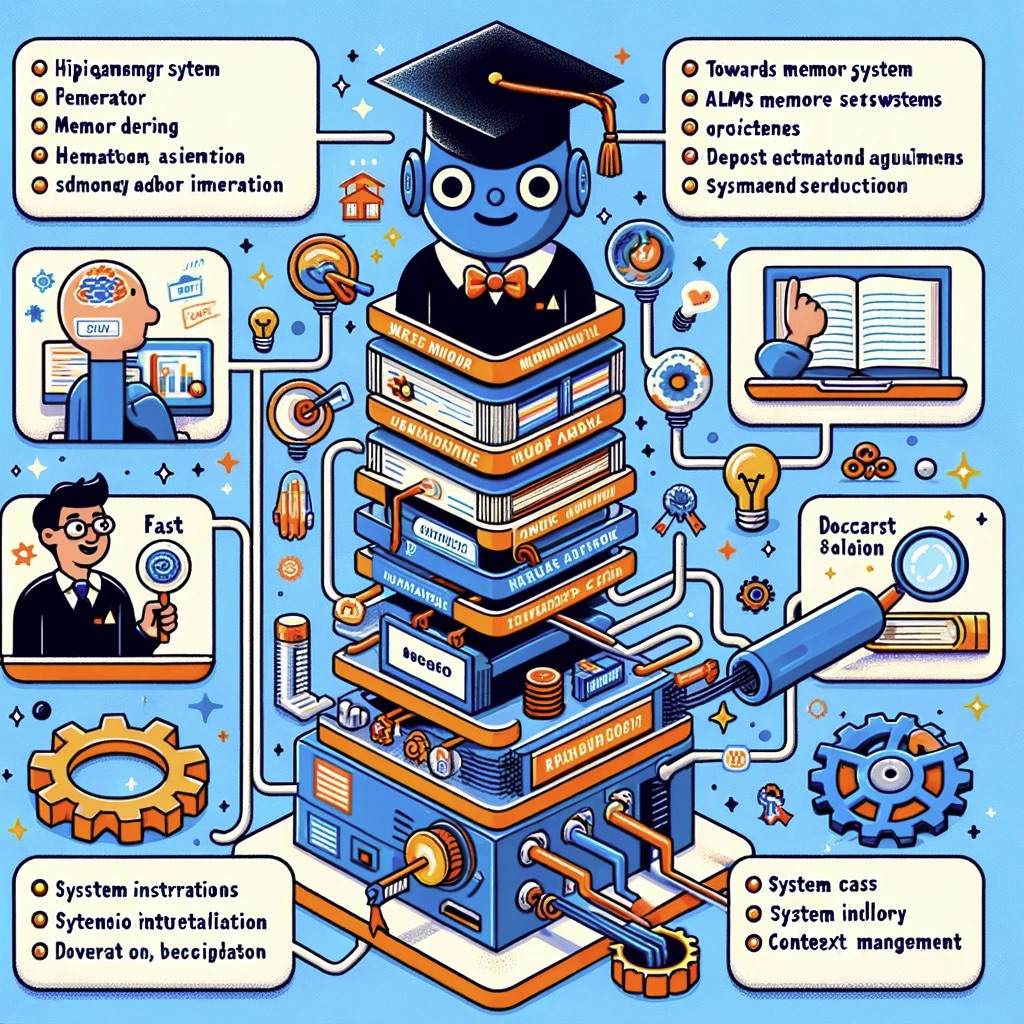
这张图非常有趣。它知道论文主角是一个机器大脑,要解决的问题是记忆体的限制。图中主体设计成一种类似操作系统的架构,上面是个戴学士帽的机器人。联接的小图都是与上下文、记忆体、检索能力相关,还提到了「快速」等特性。另外还有很多相关的文字作为讲解介绍。
当然了,这个图的毛病,也是显而易见的。例如说里面出现了很多奇怪的单词,都像是半文盲写的 —— 有很多拼写错误。不过你不用担心,这只是个开始。你要相信 LLM 的演进速度。
绘图做完了,咱们尝试一下表格数据的读取。这里我选择了 Table 2 的内容作为样例。
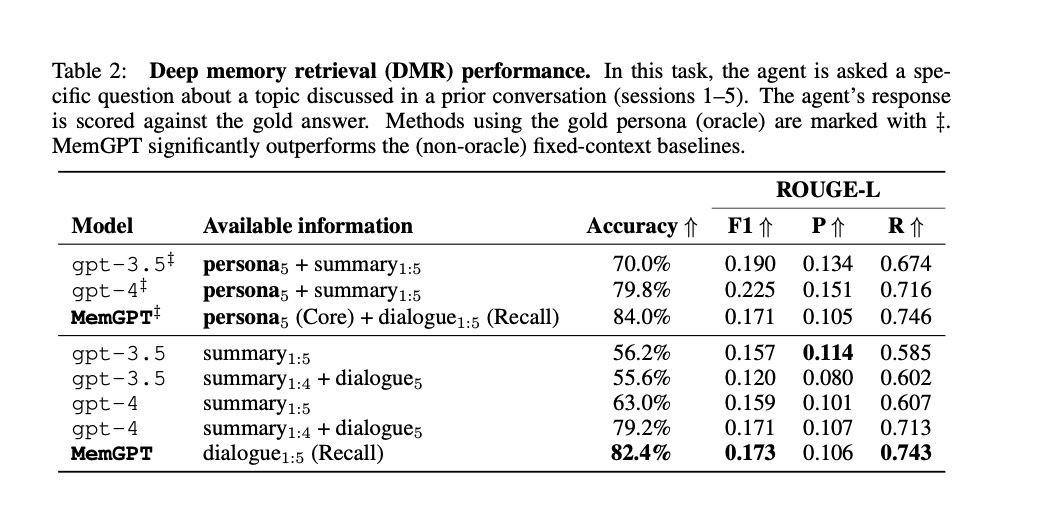
我要求 ChatGPT 来总结其内容,并且进行可视化:
这里咱们看看其操作过程的细节。
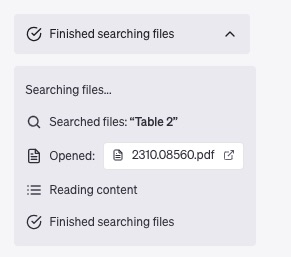
首先, ChatGPT 确实在上传的 PDF 里面,找到了表格 2 对应的位置和内容。
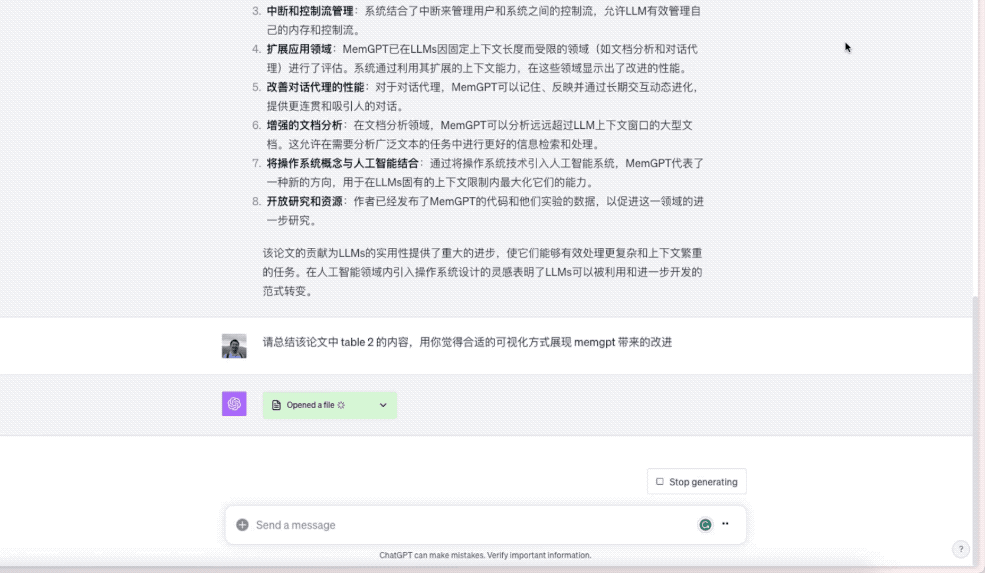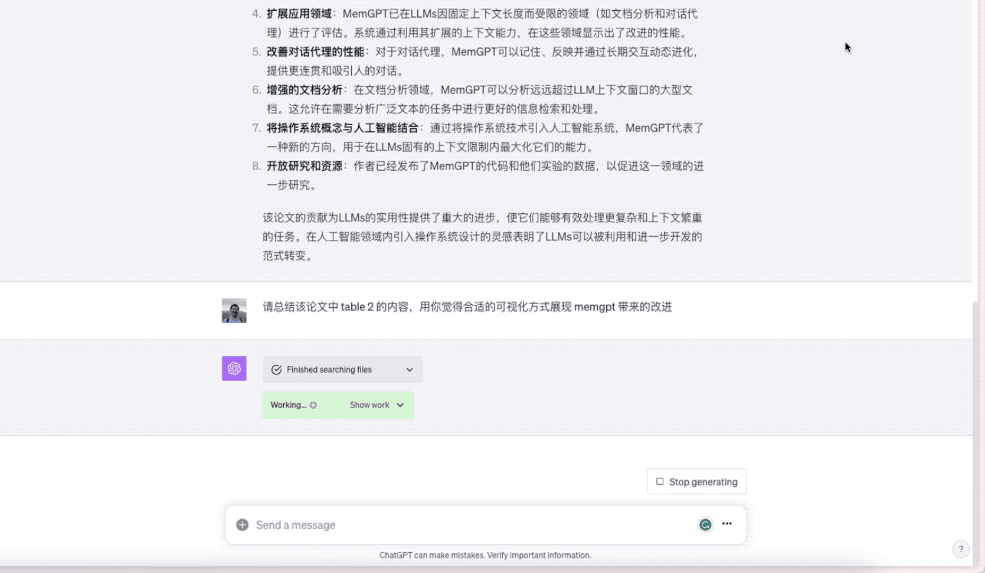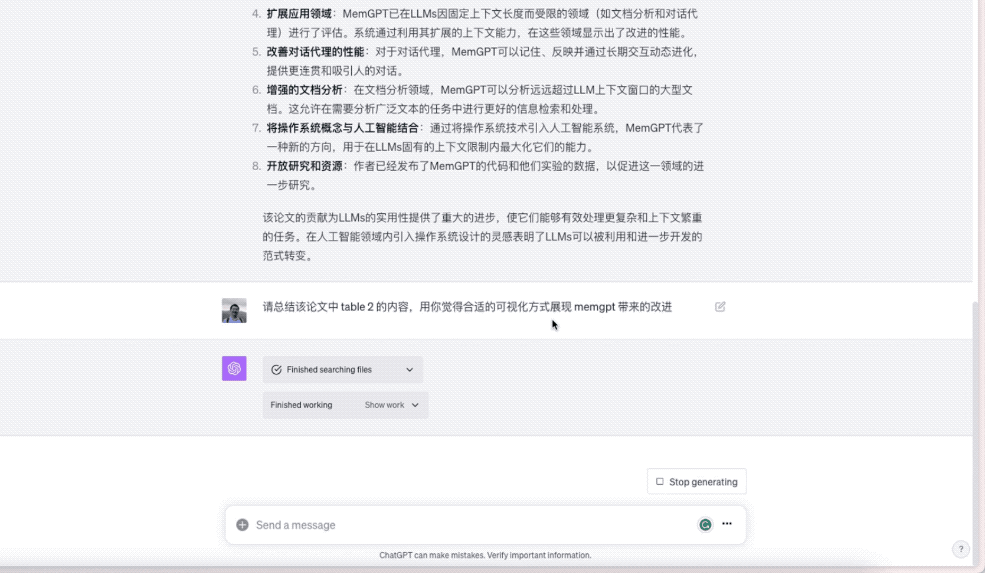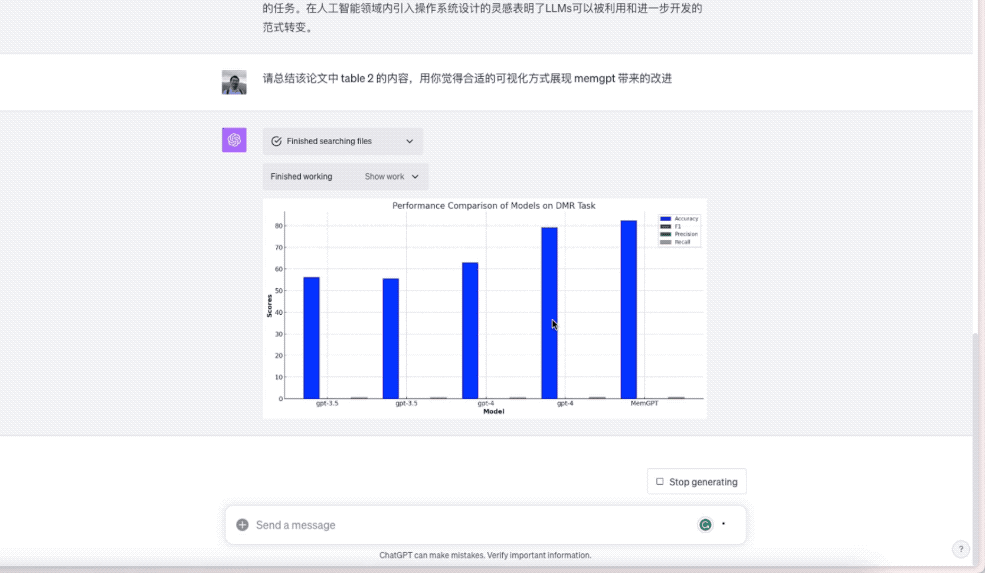
然后,ChatGPT 进行了编程计算,最终给出了下图的结果。
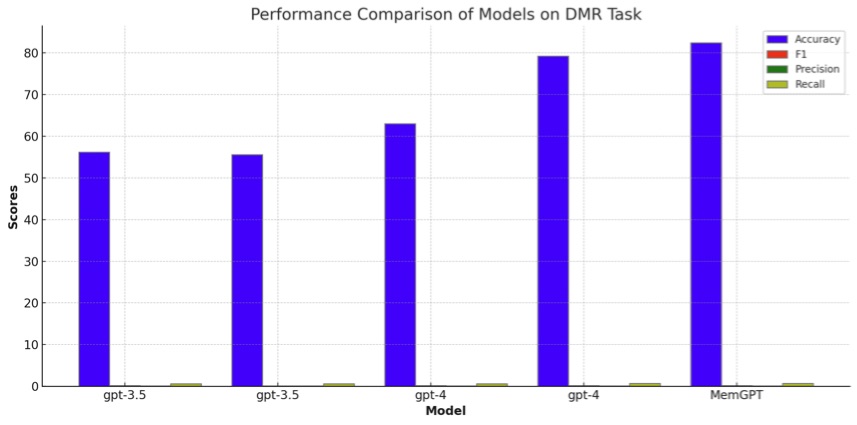
初看这张图,你可能会很不以为然。没错,这张图确实画错了。F1, Precision 和 Recall 如果真的这么惨不忍睹,也就没有汇报的必要了。但是,这错误也是有原因的。
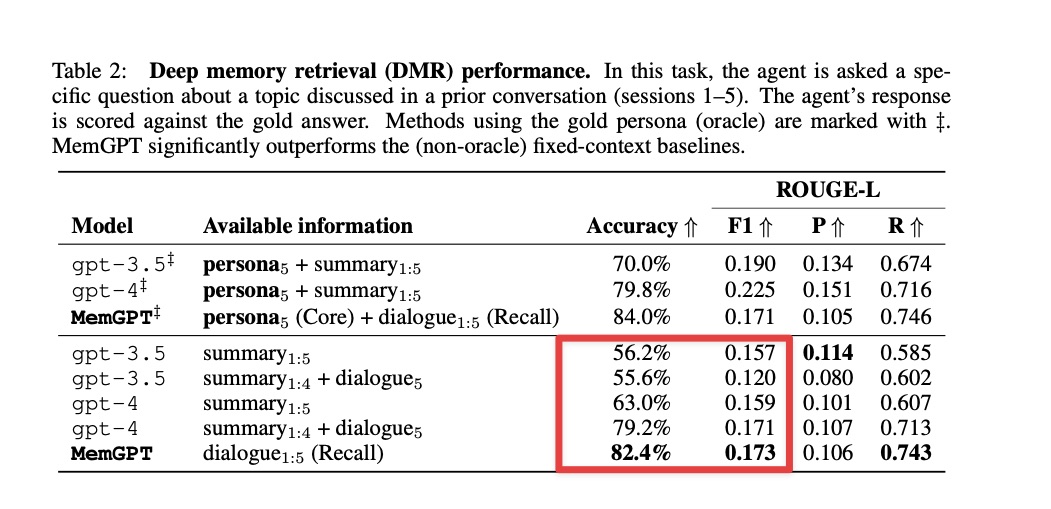
原始论文中,对 Accuracy (准确率)和其他三个指标,表现形式就不一样 —— 前者是百分数,后者是小数。目前 ChatGPT 对于同一表格不同列数据这种转换,还没有做到灵活自如,因此才会出这样的纰漏。
但是你看到,不论是模型类型、图例说明和对应数据,ChatGPT 在读取表格的时候,确实已经尽可能做到了一一对应。因此,只要你在后续对话中稍加提示,绘图效果就会大不一样。
所以,现在的 GPT-4 全模式 (All Tools) 确实是可以「看到」图和表,这对于我们来说,意义很大 —— 论文中出现的数据,你至少可以更为灵活自如地进行二次分析与验证了。
小结
本文我为你介绍了自己使用 GPT-4 全模式 (All Tools) 来辅助工作和学习的一些心得体会。总体来说,ChatGPT 全模式打通之后,可以更方便调用各种「艺能」。它可以帮助你更快速理解消化新信息、按照你的个性化要求给出样例,根据上下文做出总结问答,并且帮你进行自动数据分析。希望这些功用的分享,可以帮助你更高效地完成任务,获得新知。
祝(更强悍的)AI 工具使用愉快!
如果你觉得本文有用,请点赞。
如果本文可能对你的朋友有帮助,请转发给他们。
欢迎关注我的专栏,以便及时收到后续的更新内容。
延伸阅读
https://blog.sciencenet.cn/blog-377709-1408454.html
上一篇:一款笔记工具用着很好,但有部分功能不满足我的需求,怎么办?
下一篇:如何用自然语言 5 分钟构建个人知识库应用?我的 GPTs builder 尝试
