博文
Grok:超大数据的大模型为何能收敛?
||
—— 驯服“巨兽”的科学与艺术
让 Grok 写了篇科普,让 4o 新版配了插图,话题是困惑过无数人(包括很多从业者)的老问题:大模型那么多 moving parts 凭什么能收敛(百炼成精)??

(一个庞大神经网络的“巨兽”被科学家用数据流和数学符号引导着,走向稳定。)
想象一下,你面前有一头由亿万根神经、千亿字节数据构成的“巨兽”——一个 大型语言模型 (Large Language Model, LLM),如 xAI 的 Grok 或 OpenAI 的 GPT 系列。它拥有上百层深度交织的网络、数以百亿甚至千亿计的可调参数,吞噬的数据量堪比整个互联网的历史快照。
这头“巨兽”按理说本该是混沌和随机性的集合体,但它却展现出惊人的能力:流利地回答问题、创作逻辑连贯的文章,甚至进行复杂的推理。为什么它能够“收敛”? 为什么这样一个极其复杂的系统没有在训练中崩溃或发散,反而演变成为了人类强大的认知助手?
这看似不可思议的现象,并非魔法或天启,其背后是 数学原理、工程巧思和海量数据 巧妙结合的成果。让我们一步步揭开这头“巨兽”被成功驯服的秘密。
什么是“收敛”?
在机器学习领域,“收敛 (Convergence)” 指的是模型在训练过程中,通过不断迭代调整其内部参数,使得衡量预测错误程度的指标——损失函数 (Loss Function)——逐渐降低并最终稳定在一个可接受的低值。
简单来说,收敛就是模型从一个初始的、随机的、“什么都不懂”的状态,通过学习数据中的模式,逐渐变成一个能够有效执行任务(如理解和生成文本)的“聪明大脑”的过程。对于 LLM 而言,收敛意味着它成功地从海量文本数据中提炼出了语言的结构、语法、语义甚至某种程度的“世界知识”,从而能够生成类似人类表达的、有意义的句子。
然而,核心的挑战在于:
规模巨大:数据量动辄达到数千亿乃至万亿 token。
参数众多:模型参数量从百亿级别起步。
深度惊人:网络层数可达上百层。
如此多的“活动部件 (moving parts)”同时进行调整,如何在这样一个高维、复杂的参数空间中找到一个稳定的、性能良好的状态?这就像在大雾弥漫、地形极其复杂的巨大山脉中寻找最低的那个山谷,稍有不慎就可能在某个局部洼地停滞不前,甚至彻底迷失方向。
为什么“巨兽”能被驯服?
答案并非某个单一的“银弹”,而是多个关键机制协同作用的结果。让我们借助比喻、图示和技术细节,逐步解析这个看似奇迹的过程。
1. 反向传播:盲人摸象的“指南针”
比喻:训练 LLM 就像一个蒙着眼睛的人(模型)在一片广阔崎岖的山坡(损失函数的曲面)上寻找最低点(最优参数)。他无法看到整个山脉的全貌,只能依靠脚下的触感(梯度)来判断当前位置的坡度是向上还是向下,然后朝着“下坡”的方向小心翼翼地迈出一小步。
技术细节:
反向传播 (Backpropagation):这是计算梯度的核心算法。利用微积分中的链式法则,它能够高效地计算出损失函数相对于模型中 每一个 参数的偏导数(即梯度)。对于一个拥有 100 亿参数的模型,每一步训练都需要计算出 100 亿个梯度值,指明每个参数应该调整的方向和幅度。
梯度下降 (Gradient Descent):根据计算出的梯度,沿着梯度的 反方向 更新参数。基本公式如下:# Pseudo code for Gradient Descent updateparameter = parameter - learning_rate * gradient_of_loss_wrt_parameter这里的 学习率 (Learning Rate)(例如,一个很小的值,像 0.001)控制着每一步调整的“步长”。即使单步调整微小,经过数十万甚至数百万步的迭代,参数的累积调整量也可能非常显著(例如,累计调整达到 100 个单位)。
图示 1:梯度下降寻优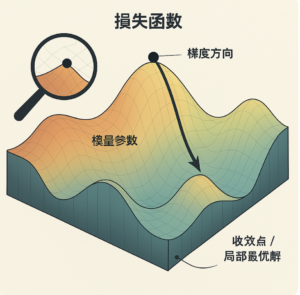
(一个表示损失函数的三维曲面,上面有一个点代表模型当前参数状态,该点正沿着指示梯度的箭头向下移动,最终停在一个低洼处,标注为“收敛点”。)
为什么有效?即使神经网络结构极其深邃复杂,反向传播通过链式法则巧妙地将整体的优化问题分解为局部的梯度计算。模型在每一步只关注当前的“局部地形”,通过亿万次微小的、基于局部信息的调整,“积跬步以至千里”,参数集合体逐渐逼近损失较低的区域。这不是一步到位的全局搜索,而是基于局部信息引导的迭代优化过程。
2. 海量数据:从噪声到信号的“炼金术”
比喻:海量的训练数据就像无数张微小的、看似杂乱无章的拼图碎片。单独看每一片(单个数据点或小批次数据),可能充满随机性或噪声。但当你有足够多的碎片并将它们汇集在一起时,隐藏在其中的宏观图案(语言的统计规律)就会逐渐显现出来。
技术细节:
统计规律的涌现:数千亿 token 的文本数据中蕴含着极其丰富的语言使用模式,包括词语搭配、语法结构、语义关联等。虽然单个句子可能有个性化或错误,但在巨大的样本量下,这些模式会以极高的频率重复出现。统计的力量使得随机噪声(如罕见用法、笔误)在平均效应下被抵消,而稳定、通用的语言规律(信号)则被强化。
批次训练 (Batch Training):实际训练中,模型并不是一次性处理所有数据(这在计算上不可行),而是将数据分成许多小的 批次 (Batches)(例如,每批包含 1024 或 4096 个序列)。模型在每个批次上计算梯度并更新参数。通过遍历足够多的批次,构成一个 轮次 (Epoch),模型就能“看到”整个数据集的统计特性。
例子:在训练数据中,“我喜欢吃苹果”这句话可能以各种形式出现成千上万次。通过反复接触这类样本,模型会逐渐学习到“喜欢”后面常常跟动词“吃”,以及“吃”的对象可以是“苹果”等食物名词的概率模式。
图示 2:数据提炼规律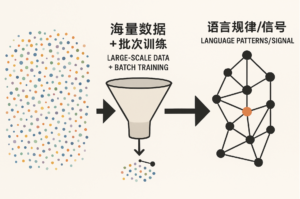 (左边是混沌的点云,代表原始数据。一个箭头指向中间的“数据处理引擎”(“海量数据+批次训练”),最终输出到右边形成清晰的结构化模式,代表被模型学到的语言规律。)
(左边是混沌的点云,代表原始数据。一个箭头指向中间的“数据处理引擎”(“海量数据+批次训练”),最终输出到右边形成清晰的结构化模式,代表被模型学到的语言规律。)
为什么有效?对于 LLM 来说,庞大的数据量非但不是负担,反而是其能够成功收敛的关键优势。海量数据提供了足够丰富和带有冗余的“证据”或“线索”,使得模型能够从看似混乱的输入中,通过统计学习稳健地提炼出语言的内在秩序和结构。
3. 多层网络结构:分而治之的“流水线”
比喻:一个深度 LLM 就像一个拥有上百名专家的庞大团队(或一条精密的流水线),共同协作完成一项复杂的任务(如理解一段文字)。每个专家(网络层)不需要处理所有细节,而是专注于任务的某个特定方面,并将处理结果传递给下一位专家。最终,通过层层递进的处理,团队能够拼凑出对原始输入的完整理解或生成恰当的响应。
技术细节:
分层抽象 (Hierarchical Abstraction):深度网络天然地倾向于学习数据的分层特征表示。在 LLM 中,靠近输入的底层网络可能主要学习识别词根、词缀、词性等局部语法特征;中间层可能学习短语结构、依存关系等句法信息;而更深的高层网络则可能负责捕捉长距离依赖、语义关联、语篇逻辑甚至进行某种程度的推理。例如,处理句子“我喜欢吃苹果”时,信息在网络中逐层传递并被抽象:字符 → 词元 → 词嵌入 → 句法结构 → 语义表示。
关键架构创新:残差连接 (Residual Connections):在像 Transformer 这样的现代 LLM 架构中,广泛使用了 残差连接。其结构通常是 Output = Input + Layer(Input)。这种设计允许梯度信号更容易地“跳过”某些层直接向后传播,极大地缓解了在非常深的网络中常见的 梯度消失 (Vanishing Gradients) 问题,使得训练数百层甚至更深的网络成为可能。
参数初始化 (Parameter Initialization):合理的初始参数设定对于训练初期的稳定性至关重要。它们旨在确保信号(前向传播中的激活值和反向传播中的梯度)在网络层间传递时,其方差既不会爆炸式增长也不会迅速衰减为零,为后续的梯度下降优化奠定良好基础。
为什么有效?网络的深度不是训练的累赘,而是实现复杂功能和有效学习的手段。通过将复杂的学习任务分解到多个层次,每一层只需承担相对简单的转换功能。结合残差连接等架构创新,深度网络能够以一种“分而治之”的方式处理信息和传播梯度,使得整体虽然庞大,但训练过程仍然是可控和趋于收敛的。
4. 亿级参数:冗余带来的“魔法”
比喻:想象一下,你需要在画布上绘制一个相对简单的图案。如果你使用的是一张非常非常巨大的画布,即使你在绘制过程中某些笔触稍微偏离了理想位置(部分参数不是最优),或者画布本身有一些微小的瑕疵(噪声),对最终图案的整体效果影响也不会太大。巨大的空间提供了足够的“缓冲”和“容错性”。
技术细节:
过参数化 (Overparameterization):现代 LLM 通常是高度过参数化的,即模型的参数数量(如 100 亿)远超理论上拟合训练数据或捕捉语言基本规律所需的最小参数量。出乎意料的是,研究(理论和实证)表明,这种过参数化现象反而有助于优化。它使得损失函数的“地形”在高维空间中变得更加平滑,减少了陷入糟糕的局部最优解(尖锐的谷底)的可能性,增加了找到良好泛化性能的“平坦”解区域(宽阔的谷底)的机会。
隐式正则化与稀疏性:尽管参数众多,但在训练过程中,尤其是在梯度下降类算法的作用下,模型可能展现出某种形式的隐式正则化。例如,许多参数的最终值可能非常接近于零,或者参数之间存在某种低秩结构。这意味着实际有效驱动模型行为的“核心”参数维度可能远小于总参数量。大量的“冗余”参数提供了极大的灵活性,同时也可能在某种程度上起到了类似“集成学习”或“容错备份”的作用。
例子:一个拥有 100 亿参数的 Grok 模型,可能只需要其中(假设)10 亿参数就足以捕捉到语言的核心语法和常见语义模式。剩余的 90 亿参数则提供了表示更细微差别、罕见知识、特定领域术语或仅仅是作为优化过程中的“润滑剂”和“备用容量”的能力。
为什么有效?巨大的参数量并非导致混乱,反而赋予了模型极大的表达能力和优化上的灵活性。过参数化改变了损失函数的几何景观,使其更容易被基于梯度的优化算法所导航。这种“冗余的魔法”让模型有更多的路径和更大的可能性走向一个良好性能的收敛状态。
5. 工程与算法的“魔法”:加速与稳定
比喻:如果那位在山坡上寻找谷底的盲人,不仅有了基本的“指南针”(梯度),还穿上了一双能自动调整速度和缓冲的“跑鞋”(优化器),并且手中持有一张能动态更新、指示大致方向和推荐路线的“地图”(学习率调度、分布式策略),那么他寻找谷底的过程无疑会更快、更稳健、也更不容易迷路。
技术细节:
高级优化器 (Advanced Optimizers):相比朴素的梯度下降,现代 LLM 训练广泛采用如 Adam、AdamW 等自适应优化算法。这类优化器结合了动量 (Momentum)(累积过去的梯度信息以加速在稳定方向上的移动并抑制震荡)和 RMSProp(根据梯度历史调整每个参数的学习率,对稀疏梯度更友好)的思想。它们能够自动适应不同参数的梯度大小和噪声水平,通常能显著加快收敛速度(有时是数倍提升)并提高训练的稳定性。
学习率调度 (Learning Rate Scheduling):训练过程中,学习率并非一成不变。常用的策略包括学习率预热 (Warm-up)(在训练初期使用较小的学习率,然后逐渐增加到预设值,以稳定起步阶段)和学习率衰减 (Decay)(在训练后期逐渐降低学习率,如按 Cosine 函数或线性衰减,以便在接近最优解时进行更精细的微调)。这就像驾驶汽车,在开阔地带加速,在接近目的地时减速慢行。
大规模分布式计算 (Large-Scale Distributed Computing):训练如此庞大的模型,单块 GPU 远远不够。需要利用 数据并行 (Data Parallelism)、模型并行 (Model Parallelism - Tensor/Pipeline Parallelism) 等分布式训练技术,将计算任务和模型参数/数据切分到数百甚至数千块 GPU 上并行处理。这不仅是必要的算力支撑,其本身的设计和优化(如高效的通信、负载均衡)也是保证训练能够顺利进行并收敛的关键工程挑战。
其他技术:还包括梯度裁剪 (Gradient Clipping) 防止梯度爆炸、混合精度训练 (Mixed Precision Training) 加速计算并节省显存、正则化技术 (如 Dropout, Weight Decay) 防止过拟合等。
图示 3:工程加速优化
(下山的盲人穿上了带有涡轮的动力鞋 “Adam优化器”,手持一个显示动态路线的GPS设备“学习率调度”,似乎有多个分身在并行下山,整体速度飞快且稳定。)
为什么有效?这些先进的优化算法和复杂的工程技术,是将收敛的数学原理从理论转化为可在有限时间和资源内实现的现实的关键。它们显著提高了训练的效率和鲁棒性,使得驯服“巨兽”级别的 LLM 成为可能。没有这些“工程魔法”,即使理论上可行,实际训练也可能因为耗时过长或过程不稳定而失败。
收敛的真相:实用主义的胜利,而非完美主义的终点
需要强调的是,LLM 训练的“收敛”通常并不意味着找到了理论上全局最优的参数解(即损失函数的绝对最低点)。在如此高维且非凸的参数空间中,找到全局最优几乎是不可能的任务。
实际上的收敛,是指模型达到一个性能足够好、实用性很强的“局部最优解”或“平坦区域”。在这个状态下,模型的 困惑度 (Perplexity)(衡量语言模型预测能力的常用指标)显著降低(例如,从初始的几百几千降到个位数),生成的文本流畅、连贯且具有逻辑性,能够满足预期的应用需求。对于工程实践而言,这就是成功的收敛。
为什么这不是“上帝的天启”?
在 LLM 展现出惊人能力之初,即使是领域内的研究者也曾对其有效性感到惊讶甚至怀疑:如此复杂的系统,凭什么就能 work?会不会是某种难以解释的“炼金术”或者需要特殊的、未知的“秘方”?
但随着研究的深入和实践的积累,事实证明,LLM 的成功收敛并非无法解释的奇迹,而是建立在坚实的科学基础之上:
数学保证:尽管损失函数非凸,但高维空间(参数极多)的几何特性与低维空间有很大不同。研究表明,在高维空间中,大部分鞍点 (Saddle Points)(梯度为零但非局部极值点)的“逃逸方向”远多于“陷入方向”,基于梯度的算法有很大概率能成功逃离鞍点,继续寻找更低的损失区域。同时,高维空间中好的局部最优解往往分布在宽阔平坦的盆地中,更容易被找到且具有良好的泛化性。
数据驱动:如前所述,海量、高质量、多样化的数据是基石。语言本身存在的强统计规律和冗余信息,使得模型能够从中学习到稳健的模式。
工程实践:先进的优化器、巧妙的网络架构设计(如 Transformer 的自注意力机制和残差连接)、强大的硬件算力以及无数研究者和工程师在训练技巧、超参数调优、分布式策略等方面的经验积累和试错,共同将理论上的可能性转化为了工程上的现实。
我们是先观察到了 GPT、Grok 等模型的成功运行和收敛现象,然后反过来更加深入地理解和验证了其背后的原理。这并非先知先觉的预言,而是实践反哺理论、工程验证科学的典型过程。
结语:从不可思议到可理解、可复制
大型语言模型(LLM)的成功收敛,是 基础数学原理、数据科学洞察、精妙算法设计与大规模工程实践 相结合的产物,是一门科学与艺术的融合。
反向传播 巧妙地分解了优化的复杂度;
海量数据 提供了学习所需的丰富信号;
深度网络 通过分层结构承担了复杂的表示任务;
过参数化 赋予了模型灵活性和更好的优化景观;
工程与算法 则为整个过程提供了强大的加速和稳定保障。
这头曾经看似难以驾驭的“巨兽”,并非天生的神兽,而是人类智慧通过严谨的科学方法和不懈的工程努力,一步步“驯服”并使其服务于我们的工程奇迹。
【相关】
https://blog.sciencenet.cn/blog-362400-1479457.html
上一篇:Gemini Deep Research:用“Logits Lens”洞察神经网络的奥秘
下一篇:《“蜜蜂巢”里的子弹:JFK档案解密后》
