ВЉЮФ
ЮЊКЮНёФъХЕБДЖћЮяРэбЇНБАфИјСНЮЛШЫЙЄжЧФмбЇепЃПЬИШЫЙЄжЧФмЕФРњЪЗБфЧЈМАЖдШЫРрЩчЛсЕФгАЯь  ОЋбЁ
ОЋбЁ
|
2024Фъ10дТ8ШеЃЌЙњЧьНкЗХМйЭъЕквЛЬьЃЌ2024ФъЕФХЕБДЖћЮяРэбЇНБАфИјСЫСНЮЛШЫЙЄжЧФмбЇепЃЌдМКВЁЄЛєЦеЗЦЖћЕТ(John Hopfield)КЭНмИЅРяЁЄаСЖй(Geoffrey Hinton)ЃЌвђЮЊЫћУЧЭЈЙ§ШЫЙЄЩёОЭјТчЖдЛњЦїбЇЯАЗНУцаЮГЩЕФЕьЛљадЙБЯзЁЃЮвЯраХетНсЙћШУДѓЖрЪ§ЮяРэбЇМвДѓЪЇЫљЭћЃЌБЯОЙЮяРэбЇЗНУцЕФГЩОЭвВВЛЩйЁЃзд1901ФъЪзДЮАфНБПЊЪМЃЌРњНьЕФЮяРэбЇНБвВДгЮДИјЙ§ЦфЫќзЈвЕЕФПЦбЇМвЃЌЕЙЪЧЗДЙ§РДЕФгаЃЌБШШчОгРяЗђШЫЃЌ1911ФъвђЗЂЯждЊЫиюЧЃЈPoloniumЃЌЖдЫ§ГіЩњЙњВЈРМЕФМЭФюЃЉКЭРиЛёЕУХЕБДЖћЛЏбЇНБЃЌГЩЮЊЕквЛИіСНЛёХЕБДЖћНБЕФШЫЁЃ

ЭМ1: дМКВЁЄЛєЦеЗЦЖћЕТЃЈзѓЃЉКЭНмИЅРяЁЄаСЖйЃЈгвЃЉЃЈЭМРДздЭјТчЃЉ
ВЛЙ§ЃЌдМКВЁЄЛєЦеЗЦЖћЕТКЭНмИЅРяЁЄаСЖйЛёЕУХЕБДЖћЮяРэбЇНБЃЌЙРМЦШУШЫЙЄжЧФмбЇепвВЭЌбљДѓГдвЛОЊЁЃБЯОЙШЫЙЄжЧФмНчЕФзюИпНБЭЈГЃЪЧЭМСщНБЃЌЪЧЮЊМЭФюШЫЙЄжЧФмЭМСщЫљЩшЁЃаСЖйдк2018ФъКЭЫћСНбЇЩњYoshua Bengio, Yann LeCunЃЈбюСЂРЅЃЌжавыУћЃЉвђЖдЩюЖШбЇЯАЕФЙБЯзЛёЕУЭМСщНБЃЌЙРМЦвбОжЊзуСЫЃЌУЛЯыЕНЛЙгаДѓНБдкКѓУцЁЃЖјСэвЛШУШЫЙЄжЧФмбЇепГдОЊЕФПЩФмЪЧЃЌЮЊЩЖЛєЦеЗЦЖћЕТФмФУХЕНБЁЃДг1936ФъЭМСщЬсГіЯыФЃФтШЫРржЧФмЕФЭМСщЛњПЊЪМЃЌНмГіЕФШЫЙЄжЧФмбЇепВуГіВЛЧюЃЌЮЊЩЖЛєЦеЗЦЖћЕТФмЙЛЪЄГіФиЃПЯТУцвдЮвИіШЫЕФРэНтЃЌРДМђЕЅСФСФСНЮЛШЫЙЄжЧФмПЦбЇМвЕФЙБЯзЁЃ

ЭМ2: 2018ФъЭМСщНБЛёЕУеп
аСЖйЪЧДѓМвЪьЯЄЕФЃЌЫћЕФГЩУћзїЪЧгыRumelhartвдМАWilliamsгк1986ФъдкЁЖNatureЁЗЩЯЗЂБэЕФЮѓВюЗДЯђДЋВЅЫуЗЈЁЃИУЫуЗЈШУЩёОЭјТчОРњЕквЛВЈКЎЖЌКѓЃЌжиаТзпЯђШЫЙЄжЧФмЕФЮшЬЈЁЃОЁЙмИУЫуЗЈдкЪ§бЇНчКмдчОЭгаЯрЙиЕФбаОПЃЌЕЋгІгУгкЩёОЭјТчдђЪЧДг1986ФъПЊЪМЁЃжЛЪЧЃЌЗДЯђДЋВЅЫуЗЈв§ЗЂЕФШШГБЃЌдк1995ФъзѓгвКмПьгжБЛЭГМЦЛњЦїбЇЯАИЧЙ§ШЅЃЌвђЮЊКѓепдкЕБЪБМШгабЯИёЕФРэТлБЃжЄЃЌвВгаБШЕБЪБЕФЩёОЭјТчИќЮЊГіЩЋЕФадФмЁЃНсЙћЃЌгаНЋНќ20ФъЕФЪБМфЃЌШЫЙЄжЧФмЕФжїСїбаОПепЖМдкЭГМЦЛњЦїбЇЯАЗНУцЩюИћЁЃМДЪЙ2006ФъаСЖйдкЁЖScienceЁЗЩЯЪзДЮЬсГіЩюЖШбЇЯАЕФИХФюЃЌбЇепУЧШдШЛНЋаХНЋвЩЃЌИњНјЕФВЛЖрЁЃ
жБЕН2012ФъЃЌаСЖйДјзХЫћЕФбЇЩњAlexдкРюЗЩЗЩЙЙНЈЕФImageNetЭМЯёДѓЪ§ОнЩЯЃЌгУЬсГіЕФAlexЭјТчНЋЪЖБ№адФмБШЧАвЛНьвЛДЮадЬсИпНЋНќ10ИіАйЗжЕуЃЌетВХШУДѓВПЗжЕФШЫЙЄжЧФмбЇепеце§зЊЯђЩюЖШбЇЯАЃЌвђЮЊвджЎЧАУПНьгУЭГМЦЛњЦїбЇЯАЗНЗЈНЯЩЯвЛНьЬсЩ§адФмЕФЫйЖШЙРМЦЃЌетДЮЕФЬсИпашвЊгУ20ЖрФъЪБМфЁЃ
здДЫвдКѓЃЌШЫЙЄжЧФмПЊЪМЯраХЃЌДѓЪ§ОнЁЂЫуСІЁЂЩюЖШФЃаЭЃЌЪЧзпЯђЭЈгУШЫЙЄжЧФмЕФЙиМќШ§вЊЫиЁЃПЦбЇМвУЧЯыЕНСЫИїжжИїбљЕФЗНЪНРДдіЙуЪ§ОнЃЌДгЖдЭМЯёБОЩэЕФа§зЊЁЂЦНвЦЁЂБфаЮРДЩњГЩЪ§ОнЁЂРћгУЩњГЩЖдПЙЭјРДЩњГЩЁЂРћгУРЉЩЂФЃаЭРДЩњГЩЃЛДгШЫЙЄБъзЂЕНАыШЫЙЄЕНШЋздЖЏЛњЦїБъзЂЁЃЖјЖдЫуСІЕФПЪЭћвВДйНјСЫGPUЯдПЈадФмЕФПьЫйЬсЩ§ЃЌвђЮЊЫќЪЧМЋЮЊЗНБуВЂааМЦЫуЕФЁЃЕЋЫќвВЕМжТСЫЖдЮвЙњШЫЙЄжЧФмбаОПЕФПЈВБзгЃЌвђЮЊФПЧАМИКѕОјДѓЖрЪ§бЇепКЭШЫЙЄжЧФмЯрЙиЦѓвЕЖМШЯЮЊгВМўЪЧЖдДѓЪ§ОнбЇЯАЕФКЫаФБЃеЯЁЃЩюЖШФЃаЭЕФЗЂеЙвВДгзюдчЕФОэЛ§ЩёОЭјТчЃЌОРњСЫШєИЩДЮЕФЕќДњЃЌШчЕнЙщЩёОЭјТчЁЂГЄЖЬЪБМЧвфЭјТчЁЂЩњГЩЖдПЙЭјЁЂзЊЛЛЦїЃЈTransformerЃЉЁЂРЉЩЂФЃаЭЃЌЕНЛљгкTransformerЗЂеЙЖјРДЕФдЄбЕСЗЩњГЩЪНзЊЛЛЦї(GPT)ЃЌвдМАИїжжGPTЕФБфЬхЁЃ
ЛиЙ§ЭЗРДПДЃЌетаЉбаОПгыаСЖйдкШЫЙЄжЧФмСьгђЁЂгШЦфЪЧШЫЙЄЩёОЭјТчЗНУцЕФМсГжЪЧУмВЛПЩЗжЕФЁЃ
ЕБШЛЃЌаСЖйЕФМсГжВЂВЛвтЮЖзХЫћжЛШЯЖЈвЛИіЗНЯђЁЃЪЕМЪЩЯЃЌЫћЖдШЫЙЄжЧФмецкаЕФЬНЫївЛжБЪЧгазЊБфЕФЁЃМЧЕУФГФъЩёОаХЯЂДІРэЖЅЛсЃЈNIPSЃЌNeural Information Processing SystemsЃЉЛсвщдјзіЙ§вЛИіИуаІЪгЦЕЃЌНВЪіаСЖйЖдДѓФдШчКЮЙЄзїЕФРэНтЃЌДг1983ФъЕФВЃЖћзШТќЛњЁЂЕН86ФъЕФЗДЯђДЋВЅЁЂЕНЖдБШЩЂЖШЁЂдйЕН06ФъЕФЩюЖШбЇЯАЃЌОРњЙ§ЖрДЮЕФБфЧЈЁЃШчЙћгУЛњЦїбЇЯАЕФБэЪіРДРэНтаСЖйЕФЙлЕуЃЌПЩвдЫЕвРФГИіаЁгк1ЃЈ1БэЪОШЗЖЈЃЌ0БэЪОЗёЖЈЃЉЕФИХТЪГЩСЂЁЃ
дйЫЕЫЕЛєЦеЗЦЖћЕТЁЃЫћЕФжївЊЙБЯзЪЧ1982ФъЬсГіЕФHopfieldЭјТчЃЌШчЙћДгЗЂБэЕФЪБМфНкЕуРДПДЃЌЕБЪБУЛгаЗДЯђДЋВЅЫуЗЈЃЌетИіЭјТчЕФГѕЦкАцБОздШЛЪЧЮоЗЈЭЈЙ§ЮѓВюЗДЯђРДЕїгХЕФЁЃ
ЕЋетИіЭјТчЕБЪБЗЂБэдкPNASЦкПЏЩЯЃЌЮФеТЕФБъЬтРягавЛИігыЮяРэЯрЙиЕФЕЅДЪЁАPhysical SystemsЁБЁЃЭјТчЕФжївЊЯыЗЈЪЧЃЌШчЙћАДЮяРэбЇНВЕФФмСПКЏЪ§зюаЁЛЏРДЙЙдьЭјТчЃЌетИіЭјТчвЛЖЈЛсгаШєИЩзюжеЛсЫцФмСПВЈЖЏЮШЖЈЕНзюаЁФмСПКЏЪ§ЕФзДЬЌЕуЃЌЖјетаЉЕуФмАяжњЭјТчаЮГЩМЧвфЁЃЭЌЪБЃЌЭЈЙ§бЇЯАЩёОдЊжЎМфЕФСЊНгШЈжЕКЭШУЭјТчНјааЙЄзїзДЬЌЃЌИУЭјТчгжОпБИвЛЖЈЕФбЇЯАМЧвфКЭСЊЯыЛивфФмСІЁЃ
СэвЛИігыЮяРэЯрЙиЕФЪЧЃЌЙЙдьИУЭјТчЕФЩшМЦЫМТЗФЃФтСЫЕчТЗНсЙЙЃЌМйЖЈЭјТчУПИіЕЅдЊОљгЩдЫЫуЗХДѓЦїКЭЕчШнЕчзшзщГЩЃЌЖјУПвЛИіЕЅдЊОЭЪЧвЛИіЩёОдЊЁЃ
ВЛЙ§ЃЌетИіЭјТчДгЕБЪБПДЃЌЛЙЪЧДцдкжюЖрВЛзуЕФЁЃБШШчжЛФмевЕНОжВПзюаЁжЕЁЃЕЋИќбЯжиЕФЮЪЬтЪЧЃК
ОЁЙмДгЩёОЩњРэбЇНЧЖШРДПДЃЌетИіЭјТчЕФМЧвфФмЖдгІгкдаЭЫЕЃЌУПИіЩёОдЊПЩвдПДГЩЪЧвЛИіОпгаФГИіЙЬЖЈМЧвфЕФРыЩЂЮќв§зг(Discrete Attractor)ЃЌЕЋЫќЕФМЧвфЪЧгаЯоЕФЃЌЧвВЛОпБИСМКУЕФМИКЮЛђЭиЦЫНсЙЙЁЃ
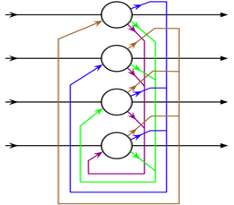
ЭМ3ЃКHopfieldЭјТчНсЙЙЭМЃЌ1982ЁЃдВаЮНкЕуДњБэПЩаЮГЩМЧвфЕФЩёОдЊЃЌЯрЛЅСЊНгЕФЯпЗДгГСЫЩёОдЊжЎМфСЊЯЕЕФШЈжиЁЃ
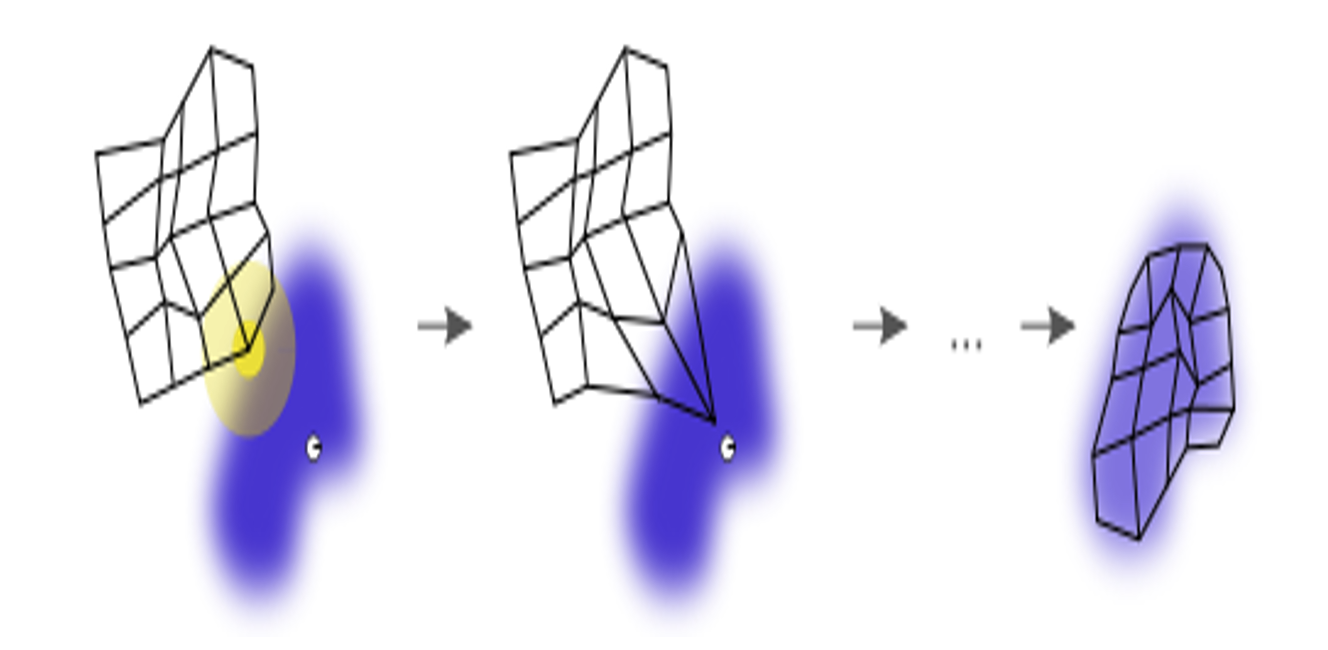
ЭМ4: KohonenЭјТчЃЌ1989
ЫљвдЃЌБугаСЫКмЖрдкДЫЛљДЁЩЯЕФаТЗНЗЈЕФЬсГіЁЃБШШч1989ФъЕФKohonenЭјТчдкЩшМЦЪБОЭМйЩшгавЛеХЭјРДгыЪ§ОндЦНјааЦЅХфЃЌЭЈЙ§ЫуЗЈЕФЕќДњзюжеПЩвдНЋЭјТчЭъКУЕиФтКЯЕНЪ§ОнЩЯЃЌЖјЭјЩЯЕФУПИіНкЕуБуПЩвдШЯЮЊЪЧвЛИіМЧвфдЊЃЌЛђРыЩЂЮќв§згЁЃетбљЕФЭјТчгаИќКУЕФЭиЦЫЛђМИКЮБэеїЁЃ
СэЭтЃЌЙигкШЫЕФМЧвфЪЧВЛЪЧгІИУЪЧРыЩЂЮќв§згЃЌжСНёвВУЛгажеНсЕФД№АИЃЌБШШч2000ФъзѓгвОЭгавЛЯЕСаЕФСїаЮбЇЯАЮФеТЗЂБэЃЈManifold learningЃЉЁЃетаЉЮФеТдкЩёОЩњРэбЇЗНУцЕФвЛИіживЊМйЩшЪЧЃЌШЫЕФМЧвфПЩФмЪЧвдСЌајЮќв§згаЮЪНДцдкЕФЁЃБШШчвЛИіШЫВЛЭЌНЧЖШЕФСГЃЌдкДѓФдМЧвфЪБЃЌЮќв§згПЩФмЪЧвЛЬѕЧњЯпЕФаЮЪНЃЌЛђепЧњУцЁЂЛђепИќИпЮЌЖШЕФГЌЧњУцЁЃШЫдкЛЙдВЛЭЌНЧЖШЕФШЫСГЪБЃЌПЩвддкЧњУцЩЯздгЩЛЌЖЏРДЩњГЩЃЌДгЖјЪЕЯжИќгааЇЕФМЧвфЁЃдкДЫРэФюЯТЃЌНіПМТЧРыЩЂЮќв§згЕФHopfieldЭјТчМАЦфБфЬхЃЌздШЛОЭЩйСЫКмЖрИњНјЕФбаОПепЁЃ
ЕБШЛЃЌСїаЮбЇЯАЕФбаОПЪЕМЪЩЯКѓЦквВЭЃЖйСЫЃЌвђЮЊетЗНУцЕФБфЯжФмСІВЛЧПЁЃ
ЫцзХЩюЖШбЇЯАЕФаЫЦ№ЃЌДѓМвЗЂЯжЭЈЙ§ЬсИпЪ§ОнСПЁЂМгЧПЫуСІНЈЩшЁЂРЉДѓЩюЖШФЃаЭЕФЙцФЃЃЌзувдБЃжЄЩюЖШбЇЯАФмЪЕЯжКУЕФдЄВтадФмЃЌЖјдЄВтадФмВХЪЧБЃжЄШЫЙЄжЧФмТфЕиЕФЙиМќвЊЫиЁЃжСгкЪЧЗёвЛЖЈвЊгыДѓФдНЈСЂФГжжЙиСЊадЃЌЪЧЗёвЛЖЈвЊгаКУЕФПЩНтЪЭадЃЌдкЕБЧАНзЖЮВЂВЛЪЧШЫЙЄжЧФмПМТЧЕФжиаФЁЃ
вВаэЃЌЕШЯжгаЕФДѓФЃаЭГіЯжРрЫЦМЦЫуЛњвЛбљЕФФІЖћЖЈТЩЪБЃЌШЫЙЄжЧФмЛсЛиЙщЕНбАевКЭНЈСЂгыДѓФдИќЮЊвЛжТЁЂИќМгНкФмЁЂИќМгжЧФмЕФРэТлКЭФЃаЭЩЯЁЃ
дйЛиЕНШЫЙЄжЧФмгыХЕНБЕФЙиЯЕЁЃДгНёФъХЕБДЖћЮяРэбЇНБЕФЕУНБЧщПіЃЌКЭШЫЙЄжЧФмНќФъРДЖдМИКѕШЋбЇПЦЁЂЫљгаСьгђЕФШкШыГЬЖШРДПДЃЌвВаэЃЌЮДРДбЇКУШЫЙЄжЧФмЃЌКмгаПЩФмЛсБШОмОјШЫЙЄжЧФмЕФШЫЃЌФмИќгааЇЕФЙЄзїЁЂЩњЛюЁЂаЮГЩаТЕФживЊЗЂЯжЃЌЩѕжСељЖсИїИіЗНЯђЕФХЕБДЖћНБЁЃ
еХОќЦНаДгк2024Фъ10дТ8ШеЭэ
https://blog.sciencenet.cn/blog-3389532-1454347.html
ЩЯвЛЦЊЃКЪЇПиЃКФдВЙЕФЩњГЩЪНAI
ЯТвЛЦЊЃКЮЊЪВУДХЕБДЖћЛЏбЇНБгжБЛШЫЙЄжЧФмбЇепФУСЫЃКАЂЖћЗЈелЕўЃЌЕААзжЪНсЙЙдЄВтвзЪж

ШЋВПзїепЕФОЋбЁВЉЮФ
ШЋВПзїепЕФЦфЫћзюаТВЉЮФ
ШЋВПОЋбЁВЉЮФЕМЖС
- • ЗтУцЮФеТ|ChemЃКГЃЮТГЃбЙЯТШШДпЛЏКЯГЩАБ
- • ПЦбЇЭј2026Фъ6дТЪЎМбВЉЮФАёЕЅЙЋВМЃЁ
- • 8-9дТЪЎДѓЧАбиСьгђЙњМЪЛсвщЭЌВНеїИхЃЌЭЖИхжИФЯРДСЫЃЁ
- • зюжеШеГЬЙЋВМЃЁЁАЕчФмдДЛЏбЇгыТЬЩЋФмдДЛЏЙЄММЪѕЁБФмдДПЦбЇЯЕСабаЬжЛсЕкЖўЦк
- • жаЙњПЦбЇдКИпФмЮяРэбаОПЫљЭѕЛРЛЊЭХЖгPhoton Science | гУгкЯрИЩXЩфЯпЩЂЩфЕФИпФмЙтдДЕЭЮЌНсЙЙЬНеыЙтЪјЯпеО
- • ПЦбЇМвИДЛюСЫвЛжжГЌМЖЯИОњвбОЛїАмЕФЧПаЇПЙЩњЫи