博文
AP-IS: 面向多模态数据的智能高效索引选择模型
|
引用本文
乔少杰, 刘晨旭, 韩楠, 徐康镭, 蒋宇河, 元昌安, 吴涛, 袁冠. AP-IS: 面向多模态数据的智能高效索引选择模型. 自动化学报, 2025, 51(2): 457−474 doi: 10.16383/j.aas.c240196
Qiao Shao-Jie, Liu Chen-Xu, Han Nan, Xu Kang-Lei, Jiang Yu-He, Yuan Chang-An, Wu Tao, Yuan Guan. AP-IS: Intelligent and efficient index selection model for multimodal data. Acta Automatica Sinica, 2025, 51(2): 457−474 doi: 10.16383/j.aas.c240196
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c240196
关键词
智能数据库,多模态数据,索引选择,强化学习,执行计划
摘要
现有的索引选择方法存在诸多局限性. 首先, 大多数方法考虑场景较为单一, 不能针对特定数据模态选择合适的索引结构, 进而无法有效应对海量多模态数据; 其次, 现有方法未考虑索引选择时索引构建的代价, 无法有效应对动态的工作负载. 针对上述问题, 提出一种面向多模态数据的智能高效索引选择模型 APE-X DQN (Distributed prioritized experience replay in deep Q-network), 称为 AP-IS (APE-X DQN for index selection). AP-IS 设计了新型索引集编码和 SQL 语句编码方法, 该方法使 AP-IS 在感知多模态数据的同时兼顾索引结构本身的特性, 极大地降低了索引的存储代价. AP-IS 集成新型索引效益评估方法, 在优化强化学习奖励机制的同时, 监控数据库工作负载的执行状态, 保证动态工作负载下 AP-IS 在时间和空间上的优化效果. 在真实多模态数据集上进行大量实验, 验证了 AP-IS 在工作负载的延迟、存储代价和训练效率等方面的性能, 结果均明显优于最新索引选择方法.
文章导读
在当今的信息社会, 各行各业数据量呈现爆炸式增长, 数据的模态也越来越多样化[1], 如非结构化文本、时序数据、半结构化JSON、空间数据等. 多模态数据库[2]能够存储、查询及管理当前多种行业相关的多模态数据, 然而, 多模态数据库尚未普及, 大多数场景和需求仍使用成熟而稳定的关系型数据库存储多模态数据. 当采用关系型数据库存储多模态数据时, 往往由于跨模态数据关联, 引发查询复杂性过高、针对多模态数据的索引优化等问题, 导致查询和管理性能较差. 因此, 如何高效地查询和管理多模态数据成为一个重要研究问题.
索引是一类用于提高数据库查询效率的数据结构, 良好执行计划的生成和选择很大程度上取决于数据表是否存在合适的索引. 数据库索引是提高多模态数据查询效率的重要手段之一, 它可以根据查询条件快速访问数据库表中的特定信息. 一个索引可以在一个数据表的一个字段或多个字段上创建, 每个表上可以同时存在多个索引. 同时, 存在多种基于不同方法实现的索引类型. 例如, 在PostgreSQL数据库中共存在6种索引类型, 包括B-tree、Hash、GiST (Generalized search tree)、SP-GiST (Space-partitioned generalized search tree)、GIN (Generalized inverted index)和BRIN (Block range index).
在没有索引的情况下, 数据库必须执行全表扫描来查找特定的数据. 这意味着数据库将查看表中的每条数据, 直到找到所需的数据, 导致执行查询、排序、聚合等操作时效率极低, 消耗大量的时间和内存资源. 在建立索引后(以B + 树索引为例), 数据库通过维护一个多级树状结构, 其中每个节点包含了数据项的键值和指向数据存储位置的指针, 使得数据的查找、插入和删除操作能够在对数时间复杂度内完成. 然而, 索引本身也需要占用硬盘空间, 同时需要在数据更新(插入、删除、修改)时进行维护, 消耗一定时间和资源. 因此, 创建索引需要综合考虑数据模态、存储开销、工作负载变化、数据库中的数据分布等因素. 不同的索引类型适用于不同的应用场景和数据模态. 如图1所示, 在时序数据模态下, 采用BRIN索引在多个方面的性能评估均优于B-tree索引.
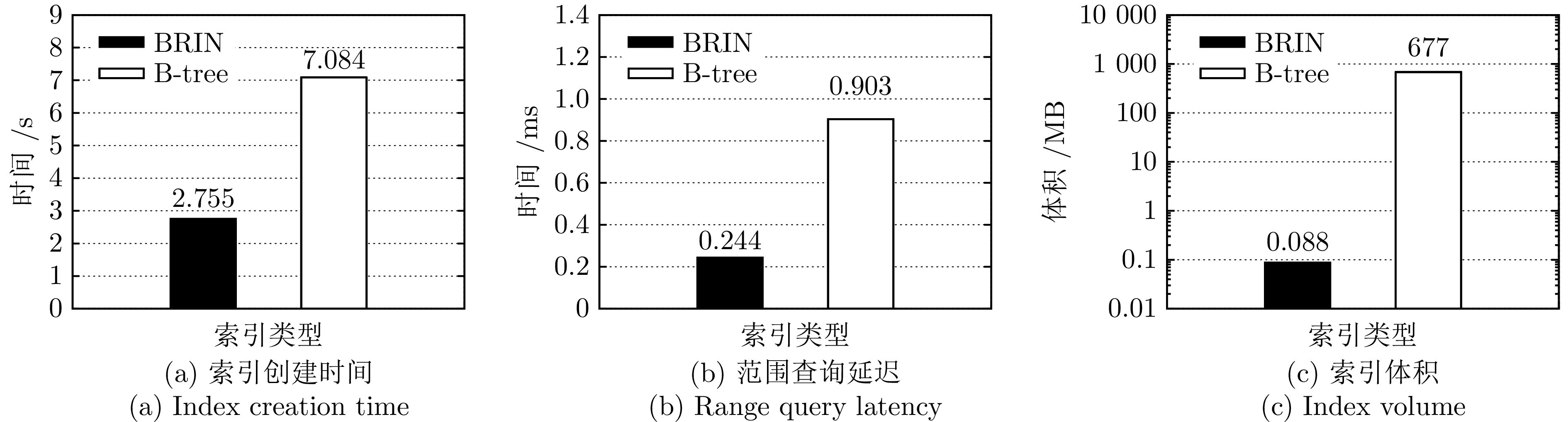
图 1 时序数据模态下BRIN索引和B-tree索引的性能对比
创建索引在优化查询效率的同时, 也会造成一些负面影响, 例如: 1)索引会大量占用磁盘空间; 2)数据库中数据更新的同时, 需要对索引进行维护, 影响数据的更新效率; 3)创建索引的过程需要花费较长时间, 且占用大量磁盘的读写资源. 因此, 需要在一定的索引存储空间约束下, 根据具体的需求和数据特征来选择合适的索引类型和字段组合, 使数据库中工作负载的执行效率最高. 此类问题被定义为索引选择问题[3−4], 其难点还体现在: 1) PostgreSQL中的B-tree、GiST、GIN和BRIN索引支持将几个字段排列起来形成一个索引, 被称为复合索引. 其中, 最常用的B-tree复合索引遵循最左前缀原则, 即查询条件需从左到右进行匹配, 否则会造成索引失效. 复合索引具有减少磁盘开销、防止回表、效率高等优势, 但大大增加了索引选择问题的复杂度. 2)数据库中的工作负载是不断变化的[5], 包括数据的更新以及业务模式的变化, 例如某索引字段从大量查询的工作负载转变为大量插入的工作负载, 这会使执行效率大大降低. 在这种情况下需要对索引进行适当更新来维持索引的优化效果. 3) PostgreSQL数据库默认的索引类型为B-tree, 其无法适应多模态数据的应用场景. 若能为特定的数据字段选择合适的索引类型, 可以大幅度增加索引的效率, 并减少磁盘占用, 但会增加索引选择问题的复杂性.
当前, 学者开始研究数据库索引选择方法, 通过强化学习算法[6−9], 提高索引质量进而优化数据库效率. 然而, 现有的索引选择方法存在诸多局限性, 如当前流行的AutoIndex方法[10] 具有以下局限性: 该方法未根据不同模态数据选择不同的索引类型, 无法使索引优化效果达到最优; 该方法未考虑索引结构本身的特性进行复合索引选择, 可能造成索引失效. 在当前大数据背景下, 索引选择方法更需要适应海量的多模态数据, 选择合适的索引结构, 适应索引结构特性, 使数据库提高运行效率, 减少存储代价[11].
针对现有方法存在的不足, 本文提出一种面向多模态数据的索引选择框架, 可以显著提高数据库效率并降低索引规模. 本文的主要贡献包括:
1)针对现有方法无法适应动态工作负载的问题, 提出一种基于APE-X DQN模型[12]的索引选择框架, 通过异步更新和优先经验回放机制, 优化多模态数据场景下智能体的探索策略和与环境交互能力. 异步更新机制可以显著提高训练效率, 使得算法更快地学习到优秀的策略.
2)针对当前方法不能适应多模态数据场景的问题, 提出一种新型的SQL语句编码方法, 从中提取可索引列并感知其数据模态, 选择最优的索引类型, 避免索引缺失; 针对已有方法无法创建复合索引的问题, 提出一种新型的索引集编码方法, 能够精确编码多种属性的索引集, 适应联合索引特性, 能有效避免索引冗余.
3)为进一步提升推荐索引质量、更加直观地证明所提方法的性能优势, 提出一种索引效益评估方法, 综合考虑索引体积、索引创建时间、索引命中率等性能指标, 使AP-IS在动态的工作负载下, 适时更新索引集, 保持索引的优化效果.
4)针对当前模型训练效率较低的问题, 提出一种混合训练机制: 先通过建立虚拟索引, 利用代价估计值进行训练; 再建立真实索引, 利用执行时间训练. 通过该方法提高训练效率, 缩短收敛时间.
5)在真实的多模态数据集、TPC-H[13]以及TPC-DS数据集[14] 上进行大量实验, 证明AP-IS相较于其他方法能为多模态数据选择更合适的索引集.
本文第1节介绍当前代表性索引选择技术, 包括传统方法和基于学习的方法, 总结各种方法的优点以及存在的局限性; 第2节对多种索引结构进行概述, 介绍索引结构与多模态数据的适用关系; 第3节对AP-IS进行详细介绍, 包括面向多模态数据的索引编码方法和SQL语句编码方法、索引效益评估方法以及基于APE-X DQN的索引选择模型; 第4节采用多种方法进行实验并分析实验结果; 第5节总结全文并展望未来工作.

图 2 AP-IS整体架构
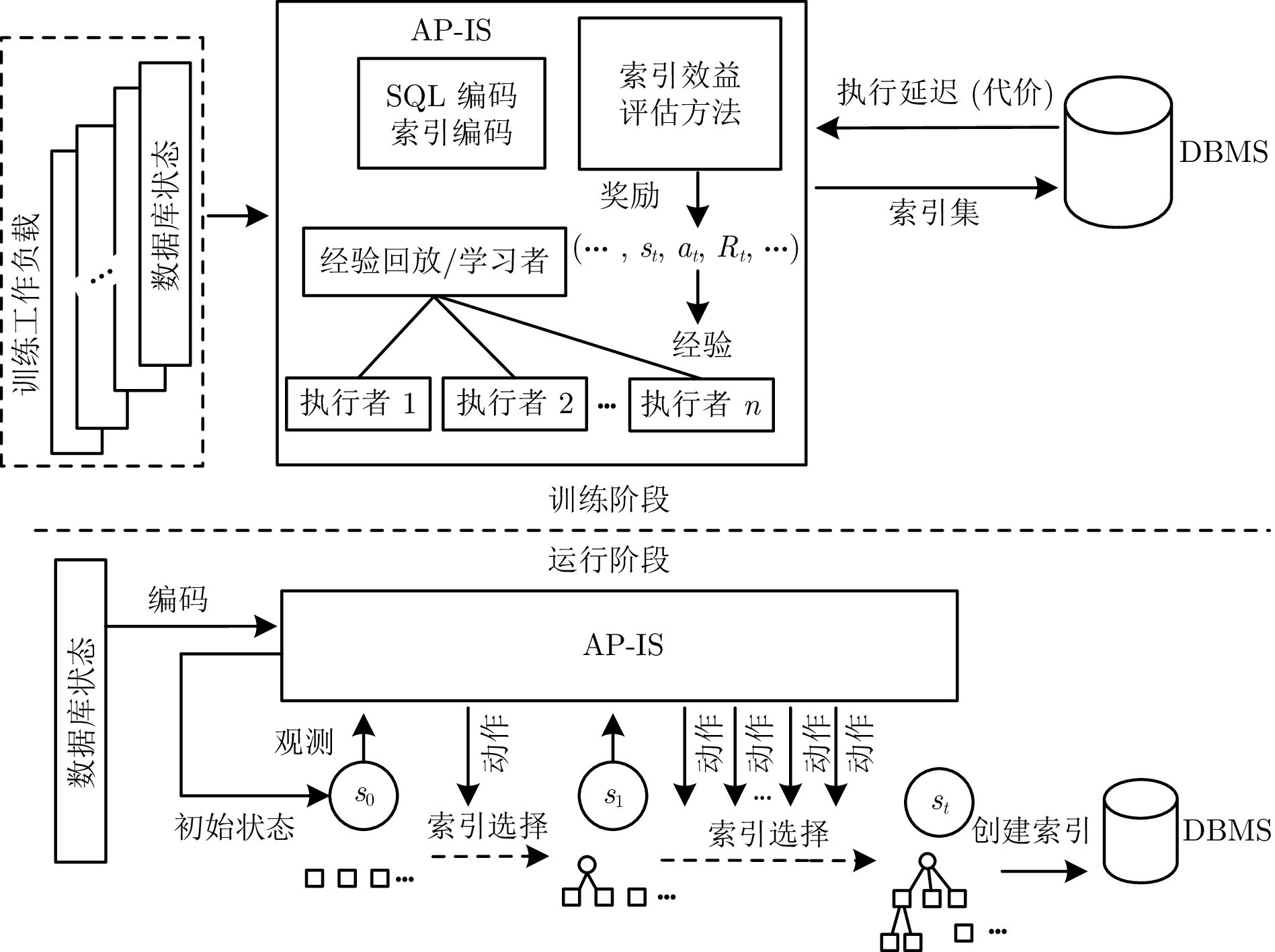
图 3 AP-IS模型的工作机制
本文提出一种新型索引选择框架, 支持多种索引类型的选择, 显著提高了数据库执行效率. 通过异步更新和优先经验回放机制, 优化多模态数据场景下智能体的探索策略和与环境交互能力. 提出一种新型的SQL语句和索引集编码方法, 能够感知数据模态, 定位索引候选属性, 精确表达索引集和索引类型, 避免索引冗余或缺失. 此外, 提出一种索引效益评估方法, 综合多种指标, 使AP-IS适时更新索引集, 保持索引的优化效果. 最后, 在TPC-DS数据集和真实多模态数据集上, 证明了AP-IS的有效性.
现有索引选择方法仍然存在一些不足, 例如: 需考虑到更多的索引参数, 在算法中实现更严谨的状态表示方法、搜索策略以及更复杂的动作集, 以进一步增加索引推荐的质量; 其次, AP-IS当前无法支持动态更新的表结构, 模型训练时已对数据库中的索引字段进行编码, 无法在后续增量训练或索引选择执行过程中动态改变字段编码, 若某个数据表添加新的字段, 已完成训练的模型将无法对其进行索引优化, 需重新对数据库进行状态表达并训练新的模型进而优化变更的字段.
为改进上述不足之处, 未来工作应考虑更多的索引参数、解决动态的表结构问题、优化学习型索引结构以及结合学习型连接优化器.
作者简介
乔少杰
成都信息工程大学软件工程学院教授. 主要研究方向为人工智能数据库和时空数据库. E-mail: sjqiao@cuit.edu.cn
刘晨旭
成都信息工程大学软件工程学院硕士研究生. 主要研究方向为人工智能数据库. E-mail: liuchenxv@foxmail.com
韩楠
成都信息工程大学管理学院副教授. 主要研究方向为数据库和数据挖掘. 本文通信作者. E-mail: hannan@cuit.edu.cn
徐康镭
成都信息工程大学软件工程学院硕士研究生. 主要研究方向为人工智能数据库. E-mail: xukanglei@126.com
蒋宇河
成都信息工程大学软件工程学院硕士研究生. 主要研究方向为人工智能数据库. E-mail: 13258665280@163.com
元昌安
南宁师范大学广西人机交互与智能决策重点实验室教授. 主要研究方向为数据库. E-mail: yuanchangan@126.com
吴涛
重庆邮电大学网络空间安全与信息法学院副教授. 主要研究方向为数据库和隐私保护. E-mail: wutao@cqupt.edu.cn
袁冠
中国矿业大学计算机科学与技术学院教授. 主要研究方向为数据库. E-mail: yuanguan@cumt.edu.cn
https://blog.sciencenet.cn/blog-3291369-1480080.html
上一篇:基于视觉属性的多模态可解释图像分类方法
下一篇:【目录】IEEE/CAA JAS第12卷第2期