博文
【语义计算沙龙:知识图谱无需动用太多知识 负重而行】
|||
w:
@wei 现在做知识图谱是否大多是工程性的工作了?
漆:
做知识图谱不仅仅是工程
w:
我是觉得李老师,趟过情感分析的河,现在也许只是工程上的工作了
漆:
看你怎么理解工程
w:
同意,虽然没上手这个领域,但是感觉上不是简单工程上的
漆:
知识图谱本质上就是知识工程的一个分支而已,但是里面涉及到的技术还是蛮多的。至少现在深度神经网络,本体推理都用得上,还是有很多理论问题需要解决。
w:
那么,现在受制于那些主要问题呢
漆:
现在还有很多问题没解决,主要是特定领域的知识挖掘很难,特别是中文,很多资源都是缺乏的。而且现在的信息抽取算法精度不是很高,离实用还有一段距离,需要做很多dirty work 召回就更不要说了
w:
恩,觉得现阶段 准确率,胜过召回率 扎实做稳,逐步积累
雷:
对的
w:
就是中文标注的文本源太少
漆:
特别是事件抽取,好像没有谁可以做得很好 各种论文都是没用的 semantic parsing也没几个真正做得好的
w:
反过来说,还是Parser,质量不高的 李老师@wei 没有用上 语义parser,那是啊
漆:
我觉得不仅仅是一个parser的问题了,parser怎么可能做到完美呢 人类的自然语言就是含糊的 所以还是需要各种推理
w:
syntax parser 和semantic parser ,.应该不是严格分离的
漆:
数据清洗
w:
尽管李老师是主张parser 纯点
漆:。而且需要是context-dependent
w:
谈到推理,摊子就大了
漆:
还有常识知识
w:
我觉得专业领域的文本,是否使用推理情况少点,但是标注语料难求。
我:
唉 怎么说呢 让你们这么一议,知识图谱需要这个知识,那个推理,甚至常识,岂不寸步难行 遥遥无期了?照我说,其实没那么玄,有了靠谱的 deep parser,知识图谱的基础就打扎实了。知识图谱无需动用太多知识 负重而行。
漆:
专业领域会有很多业务规则的推理
我:
说了你可以不信
mei:
我也认为parser不够,还需要更powerful knowledge representation,再加推理,knowledge graph @漆
我:
不过还是可以说:中文事实抽取有啥难的 关系抽取有啥难的?
w:
哈!一个知识图谱,常识,推理,都来了,这掀起了NLP中的所有的锅盖啊
我:
这些基本事实的抽取就是小菜,如果与我们所做的 sentiment 做比较的话。客观语言的抽取工作 比起主观语言的抽取就是难度低了一个量级。
漆:
这个倒是 主观的更难
我:
如果因为论文中看到的抽取不靠谱 就断定抽取难的话 那是还没见到而已,不是不存在。
漆:
关系抽取还是可解的
我:
事件比关系的难度是一个水平级的 有了 deep parsing 就是一个玩儿。什么样的 deep parsing 可以让抽取成为玩儿呢? 就是我每天秀的这个 parser 就可以。它不完美 但足以支持抽取。
w:
相信@wei 几十载个功力,是可以处理相当的问题的
mei:
从抽取到推理都有一大步
我:
当然 秀出来的 parsing 结果仅仅是树结构,隐去了节点信息 抽取是在 arc+节点 两条腿上做的。推理另说。但没有必要把推理作为抽取的核心基础。倒是在知识图谱层面 有时需要一点推理。在抽取层面 无需严格意义的推理。最多是暗度陈仓引进一些零星的 ontology 的 taxonomy。
漆:
您现在的parsing还是单句的,如果是段落,有关系依存的句子,难道也是一样?
我:
parsing 都是单句的 抽取也是 一码归一码。
w:
在想,各种需求,如何结合得更好。一方面说现在没有好句法,另一方面,现在的句法好得很。这又都同时出现在本群中,如何衔接空隙呢?
mei:
单调的static predicate,knowledge graph之上加推理有很大一步。ontology也可以做成知识图谱的一部分,可离story understanding还差远
我:
到了做融合(fusion)的时候,需要跨句、跨段落、跨文章。
漆:
有些关系是跨句抽取的,如果只是单句抽取倒还好
w:
如果单句复杂得很话,也相当复句,或小段落了@wei 的大长句parsing 结果
漆:
是的
w:
同意@mei 可离story understanding还差远。我觉得现在篇章理解的初级阶段都不是,不能看论文的发表情况,看实用效果和市场产品,更为真实
我:
这里的问题是 story understanding 是一个什么任务?为什么产品或应用服务?如果抽象地说,understanding 很难,这是宇宙真理。如果具体到支持某一个应用,问题往往简化。譬如 如果知识图谱用来支持 entity 展示其中关系以及牵扯到的事件(所谓顺藤摸瓜),那么 understanding 与否 其实不会根本影响。
w:
story understanding,当然不一定是story,就我而言,我认为很重要,有产品需求。可以自动提取人类知识的规则,建立常识知识库,而不是手工CYC啊。
我:
CYC 也是如此,要 CYC 干什么用?抽象的说,常识及其常识推理是人类调动的知识手段,那么机器模拟人的话,自然也需要这个手段。但是具体到一个应用,问题不是这样的 因为很多应用无需常识就可以。
w:
来让机器认识我们周围的世界,有点常识,不要太机器
我:
CYC 叠床架屋一直得不到大用 根子就是只有它能做的事儿并不多。很多是,语言分析就可以做,常识也可以做,为什么要舍近求远呢?
漆:
CYC确实是用处不大
w:
当初研究 自然语言的目的,就是为了让机器思考,思考需要知识,知识来源于书籍(不限于),书籍需要表达,表达需要语言,---转了一个大圈,原来是卡在语言理解这块
漆:
不过常识知识还是很重要的,比如说,我们现在做地理知识问答,就需要很多地理常识知识 特别是空间知识
我:
QUOTE 三位语义巨人中探索知识最深入和纯粹的是 Lenat 教授,他带领团队手工开发的 cyc 知识系统,试图从常识的形式化入手,利用常识推理帮助解决语言理解等人工智能核心问题。可惜这套庞大的系统太过复杂和逻辑,在实际应用上有点像大炮打蚊子,使不上劲。 (《语义三巨人》)
mei:
CYC 都是手写的,很难实用。
漆:
挺有意思的一个博客
w:
常识是针对问题的常识,不是无边际的
我:
QUOTE cyc 是属于未来世界的。他的 cyc 探索必然在历史上留下足迹,未来的某一天,他会被人纪念。生不逢时吧,虎落平川。(【一个人对抗一个世界,理性主义大师 Lenat 教授】)
w:
@mei 所以要自动提取。篇章理解好了,提取也就成了
mei:
所以很多实用是针对一个一个vertical的。同意。要也能自动。
w:
不赞同CYC手工,也不是长远事。语法是骨架,但是要真实世界的话,光语法是不够的
我: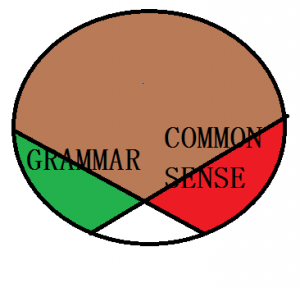
(【立委科普:自然语言理解当然是文法为主,常识为辅】)
此图是要说明,只有 common sense 才能做的工作其实是很小的圈儿,而常识本身的形式化很难 很大 也很脆弱。
漆:
同意
我:
所以理论上万能的常识 实践中意义有限。
漆:
不过没有这个很多任务也不好完成
mei:
所以我说要knowledge representation 和推理
w:
同意常识很脆弱,不排除甚至走走就会自相矛盾。
我认为“常识本身的形式化”的最好形式就是自然语言。哪怕简洁自然语言,人人可懂,人人可修。自然滚雪球越走越大。否则,形式化这关就毙了。其他的三元组,都是不周全的。
我:
QUOTE 在自然语言处理的空间里,多年的实践使我们可以做一个宏观估计,大体说来,文法可以搞定大约80%的自然语言现象和问题,表现在图中就是绿色和棕色的区域。常识呢,因为常识系统很难建成,其应用尝试就更加艰难(这一点后面谈可操作性还要重提),我们其实不知道单单用常识、不用文法到底能解决多少语言问题。我们暂先给一个乐观的估计,假设它也可以解决约80%的问题,在图中用红色和棕色表示。绿色区域和红色区域所要说的是,语言中有少数现象文法可以搞定但常识搞不定,也有少数现象常识搞定但文法搞不定。
上面图示要传达的关键信息是,即便文法和常识都能搞定很多语言问题,二者必然具有相当大的重复面或论据冗余度(棕色区域)。这个推测应该是有道理的,因为文法可以搞定多数现象是可以证实的,笔者也多次经历过。那么常识如果可以大部搞定同样的问题领域,就必然与其大面积相交。
结论: 综上所述,规则系统中,文法为主的路子比起常识为主的路子要靠谱得多。无论规则系统还是机器学习,常识成为自然语言核心技术,既无必要,更无可能,后学谨记。作为科学家,你可以进军这一领域,但不要指望它在现实中开花结果。如果你要做工程,请绕开常识这个monster,你可以零星地收编一些常识,切忌陷入深不见底的常识(推理)系统的泥坑。
w:
@wei 这句话还是有印象。但是,发展的话,这是如何绕不过去的 就看谁来为,怎么为了
漆:
同意
w:
各位先聊,我这边忙,谢谢各位
白:
在投资领域,还是必须把常识进行到底的,哪怕手工做,只要价值在,时间够,就要往前推。没有常识的舆情都是耍流氓。
梁:
@w 赞成用“简洁的自然语言”,或受限语言,表达常识。
而且是 Domain Specific, 金融领域,明显可做。 另比如,tester 的语言是: Given-When-Then, 我很喜欢 Cucumber 语言。
w:
谢谢!
谢谢梁老师肯定,关于选用简洁语言做常识表示,当初也是基于知识库的长远发展性考虑的。
梁:
对呀,只要未来的小读者喜欢读它,愿意扩展它,这种语言可以 evolve. 它就活了。
w:
它也不是仅限于常识性的知识,对定义性知识,过程性知识,都可以。只要愿意参与,容易参与,多人来参与,确实就走活了。现在很多知识库为知识库而知识库,没用起来,再大也是静态的死库。
比如说有一个做一道菜的过程知识。描述语言先不多说,肯定人能懂也好改,机器明白几何不论,但能照做并做出菜来。那么后人看加点这个,加点那个,菜味有改善。又有人觉得一某个过程火候调一下更好,这样不断众人拾菜火焰高,这道菜就越发有发展了,发展到极佳。当然这共享知识,做菜机下载能用,参与“流通”,那么这做这道菜知识,就是活知识,当然也可能这知识发展饱合了,也是好事一桩,那说明这菜己炉火纯青了,人们可以考虑别的菜了。
知识块就这样一个点,一个小区域慢延展开来,随后形成某一个知识体系,可被调用的活知识。
梁:
对呀,a piece of knowledge, 人人可以参与,改它,更新它,微调它,download 它,使用它。
我:
难道 wiki 不就是如此而且成功了吗?连那么尊贵的大英百科 也不得不退让。
梁:
yeah, wikipedia 模式,但它的 business model, 它怎么赚钱?
w:
wiki的知识更多是面向人类的而非机器。机器理解不了,就消化不了,转化不成力量
我:
受限语言践行最久大概算波音了 但那是需要接受培训。
w:
接受培训这样的语言能传播多远?
我:
辅之以机器检查才能成事 天生就不是wiki一样开放给社区
w:
那种培训语言也就真只是“受限”语言
我:
不受限 那就采 wiki 模式 靠的是人编辑确保质量和一致性
w:
我认为是不自觉地参与进来,不觉累,没有义务,都有收益的编辑模式,就自然成风。中文的wiki规模就寒酸了。另外这种wiKi编辑模式,也有待改进之处。
@wei 李老师的规则描述可否走向普通人可编辑的方向?这样大家共建,走向查缺补漏的新天地
梁:
对呀,大家共建,共享,当然还要李老师培训把关。
w:
今天我和梁老师很有共鸣,是非常高兴的事。这边很晚了,再见!
梁:
原来在陈肇雄黄河燕老师的公司里做汉英系统,调句子,十几个女孩子一起干,调规则和字典。干得挺开心的。collaboration is great。:)
Good night
我:
最好是男女搭配 那就更开心。最后还是要一个掌舵人的指引和宏观保障,否则可能成为 over done 的系统 负载太重难以前行。微软前 nlp 组由着一帮语言学家做 系统庞大 如今基本废弃不用了吧 可惜了里面那么多语言学总结 不见天日。
【相关】
https://blog.sciencenet.cn/blog-362400-988312.html
上一篇:【语义计算沙龙:sentiment 中的讽刺和正话反说】
下一篇:【语言学小品:送老婆后面的语言学】