博文
EM算法(期望最大化算法)简介
|||
和HMM简介一样(有关HMM,隐马尔科夫模型的简介,请参见我的另一篇博文http://blog.sciencenet.cn/blog-2970729-1188964.html),我们还是通过一个例子引入EM算法(Expectation Maximization Algorithm)
1. 一个经典例子
我们有两枚硬币(coin A & coin B),这两枚硬币是用特殊材质做的,硬币A抛出正面 (Head)和反面(Tail)的概率为θA和1-θA,硬币B抛出正面和反面的概率为θB 和1-θB。我们不知道θA和θB,因此想通过不断的抛硬币来推测出θA和θB,为了方便,写成向量形式:
因为有两枚硬币,我们随机地在硬币A和硬币B中挑一个(概率相等,各为50%),然后再用选中的硬币独立地抛10次,为了使整个事件更具说服力,我们选硬币抛硬币的整个过程重复做了5次。因此,总的来说选了5次硬币,抛了5×10=50次。
选了5次硬币,每次记为zi∈{A, B},5次合到一起记为z=(z1, z2, z3, z4, z5);每选1次硬币(抛10次),我们记录其中正面出现的次数xi∈{0,1,...,10},5次合到一起记为x=(x1, x2, x3, x4, x5)。于是,很容易我们就可以评估出θA:

这种通过观测来评估模型参数的方法称为极大似然评估(Maximum likelihood estimation)。
上面这个例子比较简单,是一个完备问题(complete data case)。如果上面这个例子中,已知x向量,但是不知道z向量,这时再来评估θA和θB。这类问题属于不完备问题(incomplete data case),我们称未知的z向量为隐变量(hidden variables)或者潜在因素(latent factors)。
注:我们可以想象一下,开篇的例子中,我们挑一枚硬币且记录下挑了什么硬币,再抛这枚硬币且记录下硬币的正反面。现在由于意外发生,挑硬币的那部分记录不幸遗失,只有硬币正反向次数的记录,让我们求解两枚硬币抛出正面的概率分别是多少。仔细一想,这个问题其实还是挺难的!聪明的人们想出了一个很直觉的解决办法——EM算法。
首先我们随便给定θA和θB,如果有先验知识也可以用先验知识。
![]()
基于这两个参数,计算这5次硬币A/B最可能的出现情况。再固定这5次硬币A/B抽取情况,估计θ,此时记为
![]()
再不断重复这一过程直到收敛。
总之,EM算法轮流执行两个步骤:其一,在当前模型的前提下,猜测最可能的概率分布,例如推测硬币A/B的抽取概率和期望,这一步称为E-step;其二,在推测的结果基础上重新评估模型的参数,推测θA和θB,这一步称为M-step。
之所以称为E-step,是因为通常不需要在绝对完整的前提下来生成概率分布,而是在当前完整的情况下,计算"期望的(Expected)"的充分统计量。与此类似,之所以称为M-step,是因为模型的重新评估可以认为是使期望的log值"最大化(Maximization)"。
2. 数学推导
在推导之前我们需要一点数学知识:
> Jensen’s inequality
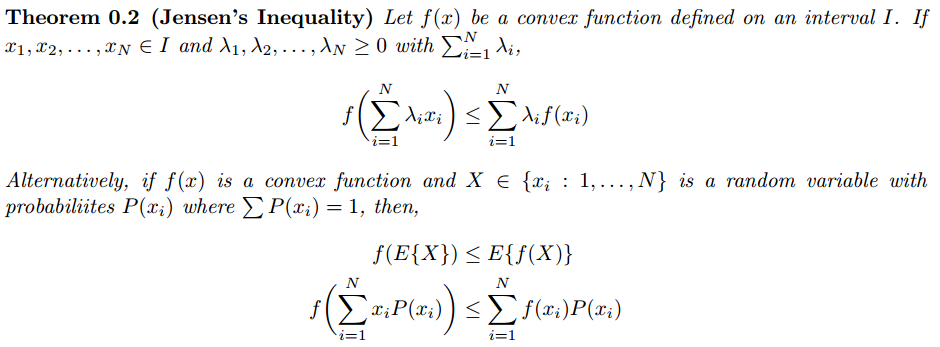
对应的图形如下:

问题:已知一组独立的样本x={x1, x2, x3, ..., xm},求模型p(x, z)的参数θ,使p(x, z)最大,其中z是隐变量。
开始推导:
因为log函数是单调递增的,所以求p(x, z)的最大值,即求log(p(x, z))的最大值。完整的写出似然函数如下,即求L(θ)最大时参数θ的值:

因为z通常观测不到,这使得问题比较复杂,无法直接求L(θ)的最大值。我们采用EM算法,构建L(θ)的下界(E-step),再优化下界(M-step),并不断重复这一过程。
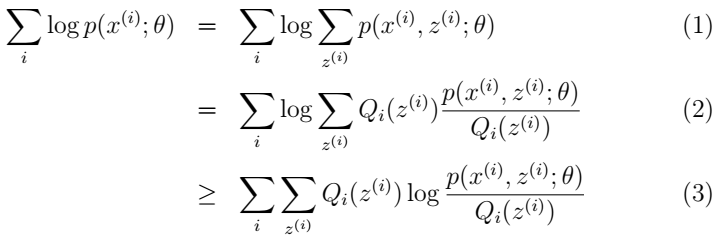
(1)式是上述所求的。上述公式来自Andrew Ng[3],Andrew Ng喜欢用上标表示index,可能和我们的习惯写法有点不一致,在此不展开,大家可以简单地将x(i)看成xi
(2)式是分子分母同乘了一个Qi(z(i))它是一种分布,而且
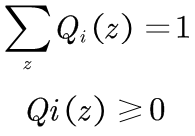
(3)由第2个式子到第3个式子的推导如下:
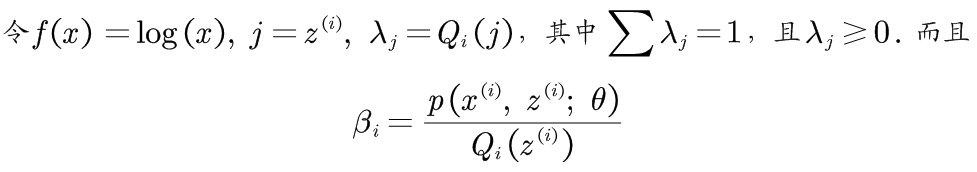
那么第2个式子到第3个式子推导如下:
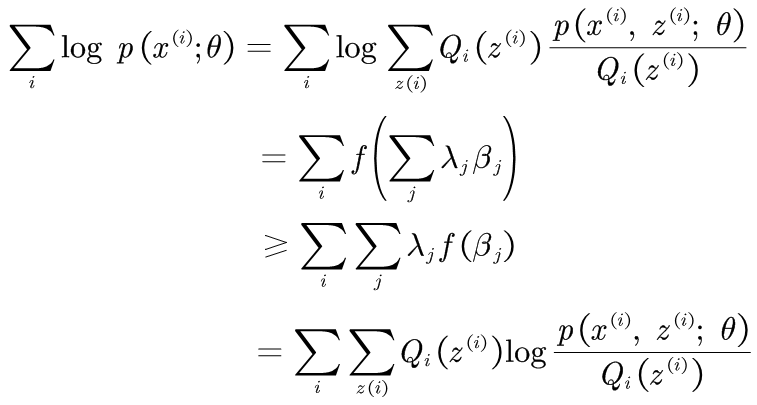
当且仅当以下等式成立时,L(θ)取得极大值:

其中c表示常数。也即
![]()
又因为Qi(z(i))是概率分布,按照定义
![]()
所以有
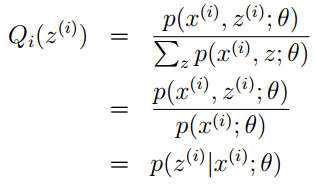
综上,不断重复以下两个步骤,直到收敛:

其中:=表示当前等于,也即覆盖之前的值
3. 用Chuong[1]文章中的实例详细计算一下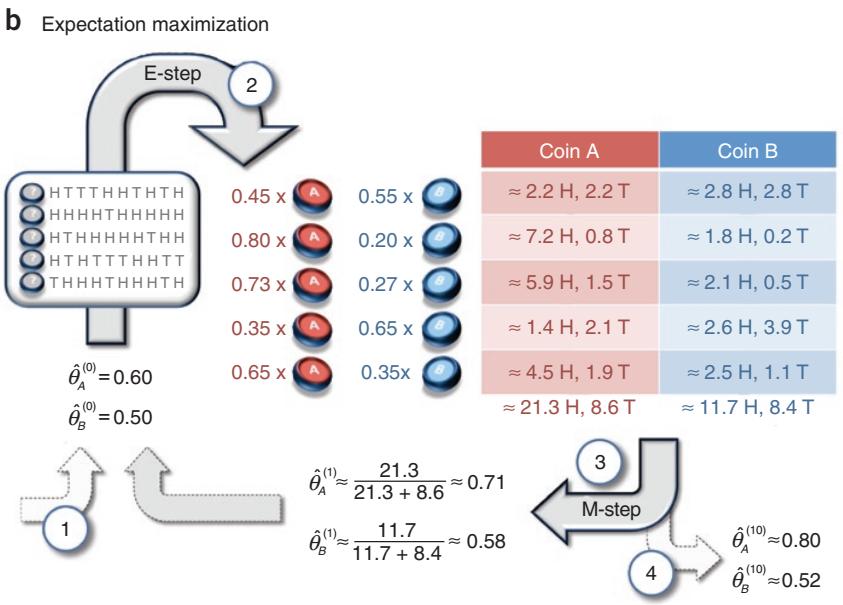
> i=0时,令
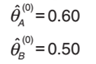
E-Step:
(1) 计算第一次选硬币,且投出的结果为H-T-T-T-H-H-T-H-T-H时,选的是硬币A的概率
根据二项分布定义,如果第一次选的是A硬币,投10次有5次为正面的概率为:
![]()
同理,可计算出如果第一次选的是B硬币,投10次有5次为正面的概率:
![]()
再由贝叶斯定律可计算出,投币结果为H-T-T-T-H-H-T-H-T-H,且这一结果是硬币A投出的概率为:
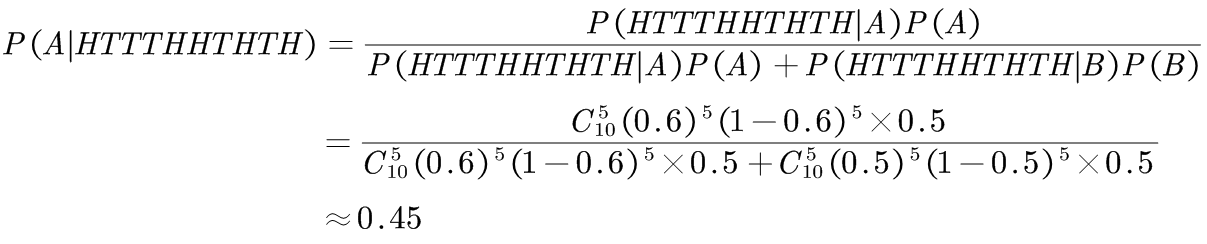
注意:其中P(A)和P(B)都为0.5,因为抽取A硬币和抽取B硬币是等可能的。
同理,投币结果为H-T-T-T-H-H-T-H-T-H,且这一结果是硬币B投出的概率为:
![]()
(2) 再依次计算第二到第五次选硬币时,抽取到A/B硬币的概率。所有结果汇总如下表:

其中,Coin A列表示投出该行硬币正反面情况下,推测是用A硬币来投的概率。
Total行是计算的5次试验的总和,而Score行的计算如下:
Score = (0.45×5) + (0.8×9) + (0.73×8) + (0.35×4) + (0.65×7)=21.24
仔细回想,这里的Score其实就是5次选币(50次投币)事件的期望值(Expectation)!以上整个过程也正是在计算P(z(i) | x(i);θ),即
每次观测(Observation)索引 => i
当前θ参数条件 => (θA,θB)
每次观测,如H-T-T-T-H-H-T-H-T-H => x(i)
挑选的硬币(Coin A, Coin B) => z(i)
的概率P(z(i) | x(i);θ)
另外,我们可以在文中看到如下表格,计算的也是一样的,以第二行为例Coin A列的2.2H表示第一次选硬币,再抛10次时硬币为H的总和0.45×5;Coin B列的2.8H表示0.55×5

同理,我们也可以算出观测到是HTTTHHTHTH时Coin A抛出反面的概率得分2.2T
M-Step:
再计算当前假设下,硬币A投正面的概率,以及硬币B投正面的概率,即
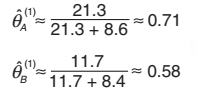
从θ(i)到θ(i+1)的过程为什么叫做极大化(Maximization)?其实这里有个认证:每次迭代的过程(从θ(i)到θ(i+1)),都会使P(z(i) | x(i);θ)增大,越来越接近或者达到局部极值
>再将θ(i+1)作为参数,不断重复上述步骤,直到结果收敛。
经过10次重复之后,算出如下结果:
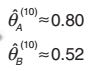
最后,需要强调的是EM也有自身的缺陷:
(1) 最终的结果与初始值的选取有关,不同的初始值可能得到不同的参数估计值
(2) 很可能会陷入局部最优解,而无法达到全局最优解
总结:
本文简约地介绍了EM算法,旨在深入浅出,面向的对象是算法小白(如我一般)。留下两个问题,有兴趣的读者可以继续探索,如果有时间后续我也会整理出来:
(1) EM算法的收敛性:E-Step和M-Step不断重复,最后是否会收敛?
(2) EM算法的应用,例如高斯混合模型、HMM中的第三个问题 (这个问题我会尽快整理到博文中,敬请期待)等。
参考材料:
[1] Chuong B Do, Serafim Batzoglou. What is the expectation maximization algorithm?
[2] Konstantinos G. Derpanis . Jensen’s Inequality
[3] Andrew Ng. CS229 Lecture notes
[4] https://ynorm.com/blog/expectation-maximization/
https://blog.sciencenet.cn/blog-2970729-1191928.html
上一篇:隐马尔科夫模型简介(三)
下一篇:隐马尔科夫模型简介(四)