博文
数据驱动的科学预测
 精选
精选
|
说明:本博客与微信公众号《林墨》同步更新,所有内容均为原创,可授权转载。请扫码关注《林墨》公众号。

当科学发现的过程变得可以预测,科技资源将更有效地被分配到更有价值的地方中去。但需警惕的是,一些预测工具的开发使用可能会导致创新潜力的受挫和现有不平等的拉大。构建健康的“科技生态圈”才是根本。
中文文稿:闵超 / 南京大学 论文推荐人:于琦 / 山西医科大学
图文编辑:李东 / 浙江大学 素材来源:Science
科学是一个社会化的过程。科学家会把更多精力花在更有趣、更有影响力、更能得到资助的研究问题上。出版商与资助机构会根据论文稿件、项目申请书的未来影响力评估其价值。科研机构的雇佣委员会会预估候选人能否在其职业生涯做出重要的科学贡献而做出聘用决策。“科学学(Science of Science)”正是研究这样一个过程的学科。
如果未来某一天,科学发现的过程变得可以预测,那么无疑,科技资源将更有效地被分配到更有价值的地方中去。基于数据驱动的科学预测正在成为科学学的一个重要话题。
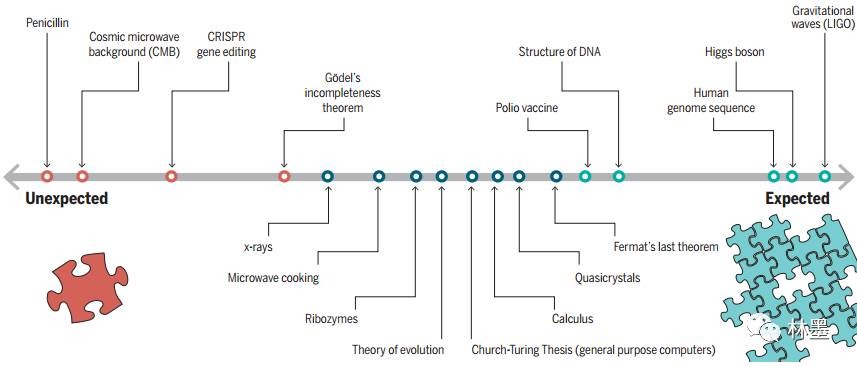
注:图1科学发现可以预测的程度,来源于Clauset, Larremore&Sinatra, 2017
用数据来预测科学发现
如果说150年前的哲学家Boleslaw Prus (1847–1912)与社会学家Florian Znaniecki (1882–1958)对“预测科学发现”的探索由于可用数据太少而进展迟缓,那么今天的科学共同体已经发展成为一个庞大而复杂的生态系统,为科学之科学的研究提供了丰富的实践场景。文献数据库与网络平台如Google Scholar,PubMed,Web of Science, JSTOR, ORCID, EasyChair以及“补充计量学(Altmetrics)”使得新一代的科学家更有能力深刻洞见科学发现的社会化过程。
我们或许现在还无法预测谁将在何时取得重要的科学发现,例如,大隅良典的诺奖成果——动物细胞的自我吞噬机制,不过对这一答案的追寻将极大地提高我们对此问题的理解。例如,一些科学发现实际并不难以预测(图1),因为随着科学理论的不断积累,某个发现也将呼之欲出,如同拼图游戏中间缺失的一块版图。人类基因序列的测定与引力波的观测都是这类的例子。另一方面,某些科学发现确实很难预知,因为它们所表示的那块拼图将会改变我们对于版图结构的认知,例如可编辑基因的编辑以及第一个抗生素盘尼西林的发现。
对于现代科学出版数据与科学家职业生涯数据的挖掘,已经开始识别出在很多研究领域都适用的定量模式。在此,有三个例子可以佐证。
第一,科学发现的引文。早在50多年前,普赖斯(de Solla Price,1922–1983)就发现了驱动引文增长的一个基本模式:论文当前的可见度增大了它在未来的可见程度,形成一个正反馈循环(普赖斯)。这也被称作“优先连接”。当把即时性与内在价值两个因素也考虑进来时,科学发现的长期影响力变得更加可以预测。当然,也有一些例外并不符合这样的规则,例如那些沉寂多年之后慢慢苏醒的“科学睡美人”。
第二,科学雇佣的模式。科学发现部分受影响于哪些人在做研究以及他们又是如何被训练成为科学家的。研究表明,少部分声望卓著的研究机构培养了绝大多数职业研究人员,对整个系统中的科学劳动力构成产生深刻影响。尽管数据显示85%的博士毕业生都会在“等级”稍低的研究机构某得第一份职位,不过研究人员最终“安定”的处所仍有很大的不可预测性。
第三,科学生产力与重要发现的时间。科学家个人在职业生涯中的表现是否可以预测同样受到关注。以往的观念认为,科学生产力会在科学家职业生涯的早期阶段达到高峰,随后经历平缓而持久的下滑。最近一项针对2300位计算机科学家的研究(Way , Morgan & Clauset et al,2016)则发现科学家间的生产力呈现出巨大的差异性。有研究认为科学家更可能在其生涯早期与中期取得“最佳发现”(Jones & Weinberg,2011) ,不过一项对逾万名科学家的分析则证明科学发现的影响力与科学家所处的职业生涯阶段并无必然联系(Sinatra, Wang& Devilleet al., 2016)。
从以上的案例中可以发现,从某些角度来看,科学发现的时机及其产生的影响非常难以预测,但是在另一些角度上却是容易预测得多。我们同样还需看到,引文、论文数量、职业流动以及学术获奖等指标都是滞后于科学发现的,它们对于崭新领域或者全新发现的预测能力实际还很低。
培育健康的“科学生态圈”
针对预测指标迟滞性的问题,我们可以做一些努力。例如,论文的详细内容、预印本数据库(arXive.org等)、学术研讨会、通信记录、被拒稿件与项目申请书、同行评议记录甚至社交媒体,都可以成为更加即时、详细的数据来源。不过,一个更为根本的问题是,这些大型数据库中所观测到的模式与科学发现之间存在怎样的因果关系。不仅如此,某些指标,尤其是引文与论文数量,更多是对以往成功的度量,并会产生“富者愈富”的正向反馈循环。对这些指标的过渡依赖不但会造成极大的不平等,而且也将限制科学创新原本的范畴,最终阻碍科学的发展。未来应该有更多的研究来开发避免反馈循环的测度方法与评价系统。

图2 科学知识的交流
一种存在的危险倾向是,资助者、出版商、大学等会利用大型的文献数据库开发能够自动评估“未来影响”的新系统,对项目提案、论文手稿以至年轻学者进行评价。这种努力并非不可,但是需要我们慎之又慎,否则将导致科技体系中的创新潜力受挫、现有的不平等扩大。我们有责任确保预测工具的使用不会阻碍未来的科学发现,忽视特殊群体,排除创新的想法,乃至抑制跨学科的研究与全新领域的发展。
同生态系统一样,科学系统本身会根据环境的变化进行自我调整。因此,我们大有可能借鉴生态学与进化论的观点来更好地理解与预测“科学生态系统”的整体发展。由此可见,多样性的缺失也将导致创新力的削弱。我们应该制定政策来培育起“科学生态圈”的多样性。在新的数据来源、新的实验设计与新的科学想法的驱动下,科学学的研究将会为我们对“科学”这一社会化进程的理解提供更多洞见。对科学发现的预测毕竟只是基于我们对科学知识的已有认知,为科学家构建并维护好一个健康的“生态系统”或许才是推动科学不断产生重大发现的源源动力。

Clauset,A.,Larremore, D. B., & Sinatra, R. (2017). Data-driven predictions inthescience of science. Science, 355(6324), 477-480.
Jones,B. F., &Weinberg, B. A. (2011). Age dynamics in scientific creativity.Proceedings ofthe National Academy of Sciences, 108(47), 18910-18914.
Sinatra,R., Wang,D., Deville, P., Song, C., & Barabási, A. L. (2016). Quantifyingtheevolution of individual scientific impact. Science, 354(6312), aaf5239.
Way,S. F., Morgan,A. C., Clauset, A., & Larremore, D. B. (2016). The misleadingnarrative ofthe canonical faculty productivity trajectory. arXiv preprintarXiv:1612.08228.

https://blog.sciencenet.cn/blog-1792012-1039371.html
上一篇:39所985高校的130校区,你去过几个
下一篇:中国科技体制改革面临的挑战